OpenZFS na Era do NVMe: Expansão RAID-Z e Performance Extrema

Análise técnica profunda sobre o OpenZFS 2.3: como funciona o reflow na expansão RAID-Z e o impacto do DirectIO na latência de drives NVMe.
Se você trabalha com armazenamento há tempo suficiente, sabe que o ZFS não é apenas um sistema de arquivos; é uma religião baseada em matemática rígida. Nascido nos laboratórios da Sun Microsystems, ele foi projetado em uma época onde os discos giravam a 7200 RPM e as CPUs eram, comparativamente, monstros de velocidade. O gargalo sempre foi o prato magnético.
Avançamos para o presente. Com o advento do NVMe PCIe Gen5 e memórias NAND de latência ultrabaixa, o cenário inverteu. O disco agora espera pela CPU. O ZFS, com sua arquitetura robusta de Copy-on-Write (CoW) e checksums end-to-end, enfrentou um dilema existencial: como manter a integridade paranoica sem se tornar o gargalo de um drive capaz de 14 GB/s?
A resposta chegou com o OpenZFS 2.3 e as inovações recentes no pipeline de I/O. Estamos falando de RAID-Z Expansion e DirectIO. Vamos dissecar como essas tecnologias alteram a topologia do seu pool.
Resumo em 30 segundos
- Expansão Granular: O recurso de RAID-Z Expansion (OpenZFS 2.3+) finalmente permite adicionar um único disco a um vdev existente, eliminando a rigidez histórica de ter que adicionar vdevs inteiros.
- Gargalo de Memória: Em velocidades de NVMe, o ARC (cache de RAM) pode atrapalhar mais do que ajudar. O novo suporte a DirectIO permite bypassar o cache para manter o throughput máximo.
- Reflow de Dados: A expansão não reescreve dados antigos magicamente; ela redistribui o espaço livre. A eficiência de paridade total só é atingida conforme os dados são reescritos.
O Paradoxo da Latência em Barramentos PCIe
Historicamente, o ZFS operava sob a premissa de que a RAM é ordens de magnitude mais rápida que o armazenamento. O ARC (Adaptive Replacement Cache) é lendário por isso. Ele armazena os blocos mais usados e mais recentes na RAM para evitar que as cabeças de leitura do HDD tenham que se mover.
No entanto, quando você introduz um array de NVMe Enterprise (como os drives E1.S ou U.2 Gen4/5), a latência do disco cai para a casa dos microssegundos. O custo de copiar dados da memória do kernel para o userspace, gerenciar locks de memória e calcular checksums complexos (como SHA-256) começa a competir com a própria velocidade do barramento.
 Figura: O impacto do DirectIO no pipeline de dados: eliminando cópias de memória redundantes em velocidades NVMe.
Figura: O impacto do DirectIO no pipeline de dados: eliminando cópias de memória redundantes em velocidades NVMe.
A Solução DirectIO
Para cargas de trabalho sequenciais massivas (como ingestão de vídeo 8K ou backups de banco de dados), o cache é inútil; você vai ler os dados apenas uma vez. O OpenZFS introduziu o suporte a DirectIO (similar ao que bancos de dados como Oracle e PostgreSQL sempre desejaram).
Isso permite que o ZFS diga ao kernel: "Não coloque isso no ARC. Mova direto do controlador NVMe para o buffer da aplicação". O resultado é uma redução drástica na utilização de CPU e um aumento no throughput linear, essencial para saturar links de 100GbE ou 400GbE em SANs modernas.
💡 Dica Pro: Use DirectIO com cautela. Para cargas de trabalho aleatórias (VMs, bancos de dados transacionais), o ARC ainda é o rei. O DirectIO brilha em streaming e backup targets.
A Matemática Rígida dos Vdevs e o Bloqueio Histórico
Durante 15 anos, a regra de ouro do ZFS foi: Vdevs são imutáveis em largura. Se você criou um RAID-Z2 com 6 discos, ele teria 6 discos para sempre. Para expandir o pool, você precisava adicionar outro vdev de 6 discos (stripe de vdevs) ou substituir todos os 6 discos por maiores, um por um (resilvering a cada troca).
Isso era inaceitável para o usuário doméstico e custoso para o Enterprise. O bloqueio não era teimosia dos desenvolvedores; era uma questão de alocação de blocos. O ZFS calcula o endereço físico dos dados baseando-se na largura do vdev no momento da escrita. Mudar a largura quebraria a aritmética de ponteiros.
A Chegada do RAID-Z Expansion
Graças ao trabalho hercúleo da Fundação OpenZFS (liderado por Matt Ahrens), o recurso de RAID-Z Expansion aterrissou. Agora é possível transformar um RAID-Z1 de 3 discos em 4, ou um RAID-Z2 de 6 discos em 7.
Mas não se engane: isso não é mágica, é engenharia de sistemas de arquivos.
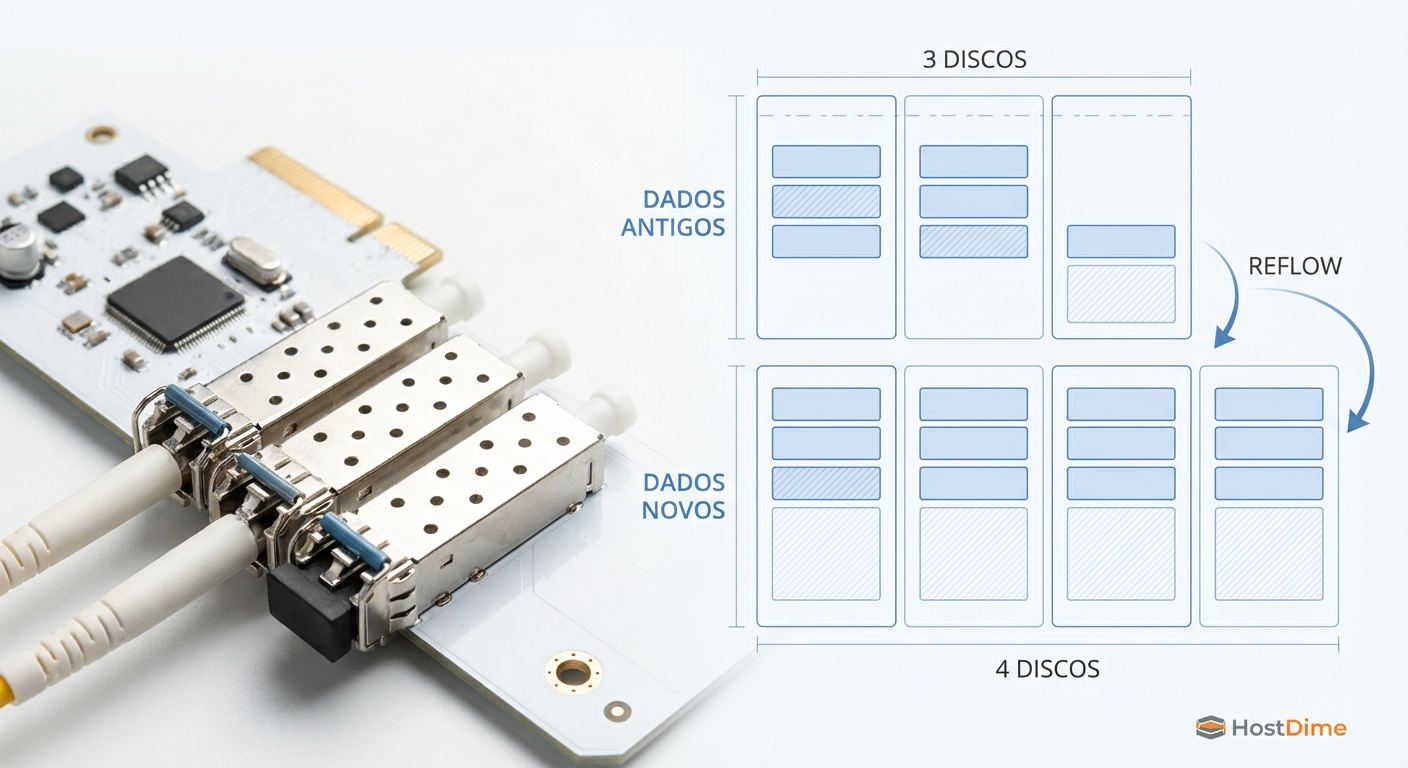 Figura: Visualização do layout híbrido: dados antigos mantêm a largura original, enquanto novos dados aproveitam o novo disco.
Figura: Visualização do layout híbrido: dados antigos mantêm a largura original, enquanto novos dados aproveitam o novo disco.
A Mecânica de Reflow: O Que Acontece nos Bastidores
Quando você executa o comando para anexar um novo disco a um grupo RAID-Z, o ZFS não reescreve todos os seus dados imediatamente (o que levaria dias e degradaria a performance). Em vez disso, ele realiza um Reflow do mapa de alocação.
O Estado Híbrido
Aqui está a nuance técnica que separa os gurus dos amadores:
Dados Antigos: Permanecem com a "largura" antiga e a proporção de paridade antiga. Se você tinha 3 discos de dados + 1 de paridade (4 total), seus dados antigos continuam ocupando espaço nessa proporção.
Espaço Livre: O ZFS recalcula o espaço livre disponível considerando o novo disco.
Novos Dados: Qualquer dado escrito após a expansão utilizará a nova largura do stripe, ganhando a eficiência de espaço do novo layout.
⚠️ Perigo: A expansão é uma operação intensiva de I/O. Embora seja segura, recomenda-se fortemente ter um backup atualizado e realizar um
zpool scrubantes de iniciar o processo para garantir que não existam erros latentes nos discos originais.
Para converter os dados antigos para a nova taxa de eficiência, você precisa reescrevê-los. Uma técnica comum é usar o zfs send | zfs recv para si mesmo ou ferramentas de rebalanceamento, embora o simples uso do sistema ao longo do tempo faça essa transição organicamente.
Métricas de Integridade e Verificação de Throughput
Em um ambiente NVMe, a corrupção silenciosa de dados é estatisticamente inevitável devido ao volume colossal de bits transferidos. O ZFS utiliza a Árvore de Merkle para garantir que cada bloco lido corresponda ao checksum gravado no bloco pai.
O Custo do Checksum em Alta Velocidade
Calcular SHA-256 a 7 GB/s por disco consome ciclos de CPU preciosos.
Fletcher4: O padrão. Extremamente rápido, excelente para detecção de erros aleatórios de hardware.
SHA-256 / Edon-R: Criptograficamente fortes, mas pesados.
Em sistemas modernos, o ZFS utiliza instruções vetoriais AVX-512 (em CPUs Intel/AMD recentes) para acelerar esses cálculos. Se você está montando um servidor de armazenamento NVMe, a escolha da CPU deve levar em conta o suporte a instruções AVX-512 para não gargalar o throughput na verificação de integridade.
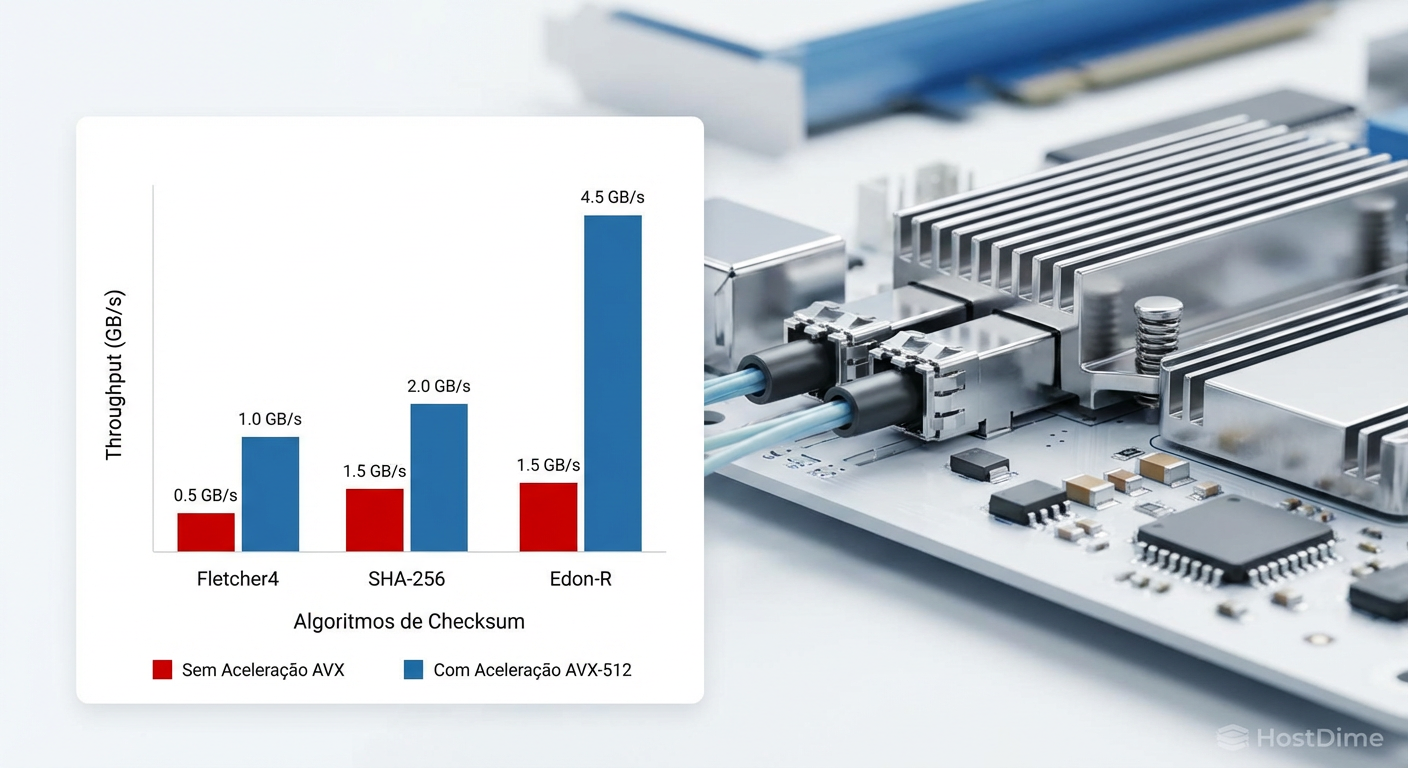 Figura: Impacto das instruções AVX-512 no cálculo de checksums em alta velocidade.
Figura: Impacto das instruções AVX-512 no cálculo de checksums em alta velocidade.
Comparativo: Expansão Tradicional vs. RAID-Z Expansion
Para situar sua decisão de arquitetura, analise as diferenças fundamentais entre os métodos de crescimento de pool.
| Característica | Adicionar Novo VDEV (Tradicional) | Expandir VDEV Existente (Novo) |
|---|---|---|
| Granularidade | Baixa (Requer múltiplos discos) | Alta (1 disco por vez) |
| IOPS | Aumenta (Mais vdevs = mais IOPS) | Mantém-se similar (Mesmo vdev) |
| Eficiência de Espaço | Mantém a proporção atual | Aumenta (Menos % dedicado à paridade) |
| Custo Inicial | Alto (Compra em lote) | Baixo (Compra unitária) |
| Tempo de Rebalanceamento | Instantâneo (Apenas novos dados usam o novo vdev) | Longo (Processo de Reflow em background) |
O Futuro é All-Flash e Flexível
A era de tratar o armazenamento como um repositório estático acabou. Com o OpenZFS abraçando o NVMe através do DirectIO e flexibilizando a geometria com a Expansão RAID-Z, removemos as últimas barreiras que mantinham administradores presos a controladores RAID de hardware proprietários.
Minha recomendação técnica é clara: para novos deployments de alta performance, projete seus pools pensando na largura de banda do barramento PCIe, não apenas na capacidade. Use a expansão para crescer organicamente, mas nunca negligencie a CPU — em um mundo NVMe, o processador é o novo controlador de disco. O ZFS continuará sendo a última linha de defesa contra a entropia dos seus dados, não importa a velocidade em que eles viajem.
Referências & Leitura Complementar
OpenZFS GitHub Pull Request #15022: "RAID-Z Expansion" - A documentação técnica primária da implementação do recurso de reflow.
NVMe™ Base Specification 2.0: Detalhes sobre o gerenciamento de filas e latência em dispositivos de memória não volátil.
FreeBSD Man Pages (zpool-attach): Documentação oficial atualizada com os parâmetros de expansão de vdevs.
JEDEC SSD Specifications: Padrões de integridade de sinal para interfaces de alta velocidade.
Perguntas Frequentes (FAQ)
Posso adicionar apenas um disco ao meu array RAID-Z2 existente?
Sim, com o OpenZFS 2.3+ isso é possível através do recurso de RAID-Z Expansion. O sistema realiza um 'reflow' do espaço livre, permitindo o crescimento granular do array. No entanto, é crucial entender que os dados antigos mantêm a proporção de paridade original até serem reescritos, criando um pool com geometria híbrida temporária.Por que meu NVMe de 7000MB/s só entrega 2GB/s no ZFS?
Isso geralmente ocorre devido ao overhead do ARC (cache) e contenção de locks na memória RAM. O ZFS foi desenhado quando a CPU era muito mais rápida que o disco. Em drives NVMe modernos, o recurso de DirectIO (introduzido no OpenZFS 2.3) ajuda a mitigar isso, permitindo bypassar o cache para cargas de trabalho sequenciais específicas, liberando a CPU.O que acontece com a paridade dos dados antigos após expandir um RAID-Z?
Eles permanecem com o layout antigo. Se você tinha um RAID-Z1 de 3 discos e expandiu para 4, os dados pré-existentes continuam ocupando o espaço físico e lógico como se estivessem em 3 discos. Apenas novos dados (ou dados antigos que forem reescritos/movidos) aproveitarão a eficiência de paridade da nova largura de 4 discos.
Roberto Holanda
Guru de Sistemas de Arquivos (ZFS/Btrfs)
"Dedico minha carreira à integridade dos dados. Para mim, o bit rot é o inimigo e o Copy-on-Write é a salvação. Exploro a fundo ZFS, Btrfs e a beleza dos checksums."