Otimizando a performance de I/O no Proxmox Ceph para substituir o VMware vSAN

Guia de engenharia para eliminar latência em migrações vSAN para Proxmox Ceph. Tuning de BlueStore, ajustes de rede 25GbE e configurações seguras de cache RBD.
A migração de infraestruturas baseadas em VMware vSAN para Proxmox VE com Ceph tem sido um dos movimentos mais agressivos no datacenter moderno. No entanto, administradores acostumados com a integração kernel-level do vSAN frequentemente se deparam com um obstáculo frustrante logo na primeira semana: a performance de I/O, especificamente a latência em bancos de dados transacionais.
O Ceph é um sistema de armazenamento distribuído incrivelmente resiliente e escalável, mas, diferentemente do vSAN que vive dentro do kernel do ESXi, o Ceph no Proxmox opera majoritariamente em userspace. Isso introduz camadas que, se não forem ajustadas, transformam seus SSDs NVMe em dispositivos com performance de SATA mecânico.
Não se trata apenas de "jogar hardware" no problema. A otimização de I/O no Proxmox Ceph exige uma compreensão cirúrgica de como o dado trafega da VM até o disco físico. Vamos abrir o capô dessa arquitetura.
Resumo em 30 segundos
- O caminho do I/O é mais longo: O Ceph usa
librbdem userspace, o que gera mais trocas de contexto (context switches) que o vSAN.- Rede é gargalo de CPU: Sem Jumbo Frames (MTU 9000) e placas de 25GbE+, a CPU do host gasta ciclos demais processando pacotes de rede em vez de I/O de disco.
- Cuidado com o Cache: O modo
writebackoferece performance "mágica", mas pode corromper sistemas de arquivos inteiros em caso de falha elétrica no host.
A anatomia da latência: vSAN vs Ceph/RBD
Para resolver problemas de performance, precisamos entender onde os ciclos de CPU estão sendo gastos. No mundo VMware, o vSAN é altamente otimizado para encurtar o caminho entre a VM e o dispositivo de armazenamento. No Proxmox, a arquitetura é diferente.
Quando uma VM (KVM) grava um bloco de dados, esse pedido passa pelo QEMU, que utiliza a biblioteca librbd para conversar com o cluster Ceph. O dado é então fragmentado, replicado e enviado pela rede para os OSDs (Object Storage Daemons).
O problema crítico aqui é a latência de cauda (tail latency). Em benchmarks sintéticos de throughput, o Ceph brilha. Mas em cargas de trabalho síncronas, como logs de transação do SQL Server ou WAL do PostgreSQL, cada milissegundo gasto em context switching ou na pilha de rede conta.
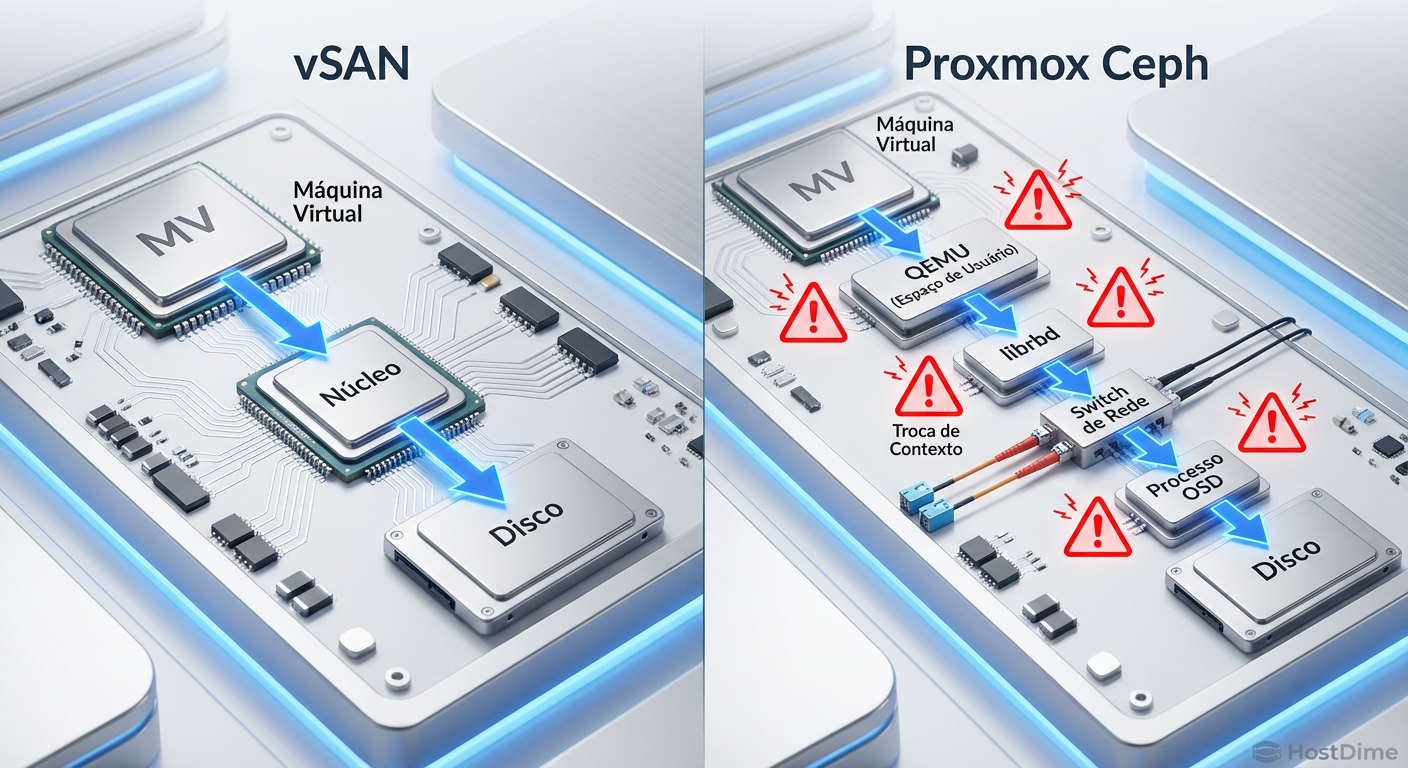 Figura: Comparativo do caminho de I/O: A integração direta do Kernel no vSAN versus o caminho via Userspace/librbd no Proxmox Ceph.
Figura: Comparativo do caminho de I/O: A integração direta do Kernel no vSAN versus o caminho via Userspace/librbd no Proxmox Ceph.
Segregando o tráfego e o impacto do MTU 9000
Muitos administradores falham ao tratar a rede de storage como uma rede comum. Em uma infraestrutura hiperconvergente (HCI), a rede é o backplane do seu storage.
Se você está rodando tráfego de cluster (Corosync), tráfego público do Ceph (VMs acessando discos) e tráfego de replicação (OSD para OSD) na mesma interface física ou VLAN sem QoS estrito, você terá "jitter" no I/O.
O papel vital dos Jumbo Frames
O padrão Ethernet tem um MTU de 1500 bytes. Para mover 1GB de dados, a CPU precisa processar centenas de milhares de pacotes e interrupções. Ao habilitar Jumbo Frames (MTU 9000), você reduz drasticamente o número de pacotes para a mesma quantidade de dados.
💡 Dica Pro: A configuração de MTU 9000 deve ser ponta a ponta. Se você configurar no Proxmox mas esquecer no switch físico, os pacotes serão fragmentados ou descartados, destruindo a performance. Teste sempre com
ping -M do -s 8972 <ip-destino>.
Para ambientes All-Flash ou NVMe, interfaces de 10GbE já são consideradas gargalo durante operações de rebalance ou recovery. O padrão atual para garantir baixa latência sob estresse é 25GbE ou superior, preferencialmente com suporte a RDMA (embora a implementação de RDMA no Ceph ainda exija validação cuidadosa).
O perigo silencioso do cache writeback
No Proxmox, ao configurar o disco de uma VM, você tem opções de cache: none, write through, writeback, entre outros.
Muitos tutoriais na internet sugerem cegamente usar writeback para "consertar" a performance lenta. Isso funciona porque o KVM reporta à VM que o dado foi gravado assim que ele atinge a RAM do host, antes mesmo de chegar ao Ceph.
O risco: Se o host Proxmox sofrer um kernel panic ou perda súbita de energia, os dados que estavam na RAM e não foram para o Ceph são perdidos. Para um banco de dados, isso significa corrupção.
 Figura: O risco do Cache Writeback: Dados retidos na RAM do host durante uma falha de energia resultam em perda de dados antes da confirmação no storage.
Figura: O risco do Cache Writeback: Dados retidos na RAM do host durante uma falha de energia resultam em perda de dados antes da confirmação no storage.
A recomendação para produção crítica é utilizar cache=none ou direct sync e resolver a performance na camada do Ceph (discos mais rápidos, rede melhor), e não trapaceando com cache inseguro, a menos que você tenha proteção de bateria (UPS) redundante e esteja ciente dos riscos.
Ajustando o OSD memory target para NVMe
O Ceph BlueStore (o backend de armazenamento atual) precisa de memória RAM para cache de metadados. Por padrão, o Proxmox pode definir um valor conservador para o osd_memory_target (geralmente 4GB).
Para drives NVMe rápidos, o gargalo muitas vezes se torna a leitura de metadados do disco. Se você tem RAM sobrando no host, aumentar esse alvo permite que o Ceph mantenha mais metadados "quentes" na memória, reduzindo a latência de leitura drasticamente.
Para ajustar dinamicamente:
ceph config set osd osd_memory_target 8589934592
Este comando define o alvo para 8GB. Monitore o uso de memória do host; se o sistema entrar em swap, a performance do Ceph degradará catastroficamente.
Comparativo: Padrão vs Otimizado
Abaixo, comparamos o comportamento esperado entre uma implementação padrão e uma otimizada para alta performance.
| Característica | Ceph Padrão (Out-of-the-box) | Ceph Otimizado (NVMe/Tuned) | VMware vSAN (Referência) |
|---|---|---|---|
| MTU de Rede | 1500 (Padrão) | 9000 (Jumbo Frames) | 9000 (Recomendado) |
| Latência de Escrita | Média/Alta (overhead de software) | Baixa (com CPU pinning/tuning) | Muito Baixa (Kernel) |
| Segurança de Cache | Variável (depende da config da VM) | Alta (Direct I/O + NVMe rápido) | Alta (Cache Tier dedicado) |
| Uso de CPU | Moderado | Alto (devido ao throughput) | Moderado |
| Throughput de Recovery | Limitado pela rede/CPU | Limitado pelo disco (se 25GbE+) | Controlado por política |
Validando a consistência: fio vs rados bench
Não confie em testes de cópia de arquivos (CP ou DD). Eles não refletem a realidade de IOPS aleatórios.
Teste de Infraestrutura (rados bench): Testa a velocidade bruta do cluster Ceph, sem a camada de virtualização (KVM/QEMU). Ideal para validar se a rede e os discos entregam o prometido.
Teste de Aplicação (fio): Deve ser rodado dentro da VM. É aqui que você sentirá o impacto do
librbde das configurações de cache.
⚠️ Perigo: Rodar benchmarks de escrita intensiva em um cluster de produção pode saturar os links de replicação e causar lentidão nas VMs existentes. Execute testes apenas em janelas de manutenção ou em pools segregados.
 Figura: Validando a performance: rados bench para o cluster físico versus fio para a experiência da VM.
Figura: Validando a performance: rados bench para o cluster físico versus fio para a experiência da VM.
O futuro do storage open source
A substituição do vSAN pelo Ceph não é apenas uma troca de software; é uma mudança de filosofia. Você ganha liberdade e elimina o "imposto vTax", mas assume a responsabilidade de arquiteto de storage.
O Ceph é capaz de entregar performance estelar, sustentando cargas de trabalho de missão crítica em grandes instituições financeiras e de pesquisa. No entanto, ele não perdoa configurações de rede negligentes ou hardware subdimensionado. Se você tratar o Ceph como um "black box", ele falhará. Se você o tratar como um sistema que exige engenharia, ele será a fundação mais sólida que seu datacenter já teve.
Referências & Leitura Complementar
Proxmox VE Administration Guide: Capítulo sobre Ceph e gerenciamento de OSDs.
Ceph Documentation (BlueStore Configuration): Parâmetros avançados de tuning para dispositivos NVMe.
RFC 8724: Considerações sobre tecnologias de compressão e latência em redes de dados.
Intel Ethernet 800 Series Docs: Guia de otimização para RDMA e ADQ em ambientes de storage distribuído.
Perguntas Frequentes (FAQ)
O cache=writeback é seguro no Proxmox com Ceph?
Apenas se você tiver proteção de energia (UPS/Bateria) em todo o cluster e confiar plenamente na estabilidade do host. Caso contrário, uma falha de energia ou travamento do host pode corromper o sistema de arquivos da VM, pois os dados na RAM do host ainda não foram confirmados no Ceph (flush). Para bancos de dados, prefiranone ou write through.
Qual a rede mínima recomendada para Ceph All-Flash?
Para NVMe/SSD, 25GbE é o novo padrão mínimo. Redes de 10GbE saturam rapidamente durante a recuperação (rebalance) ou backups, causando picos de latência nas VMs. Se o orçamento permitir, 100GbE para o backbone de replicação é o ideal para extrair o máximo dos NVMes modernos.Devo usar Jumbo Frames (MTU 9000) no Ceph?
Sim, é altamente recomendado para a rede de Cluster e Pública do Ceph. Isso reduz a sobrecarga de CPU (interrupções) e melhora o throughput, mas exige que **todos** os componentes (NICs, Switches, Cabeamento) no caminho suportem e estejam configurados com o mesmo MTU. Um MTU descasado causará perda de pacotes silenciosa e problemas graves de performance.
Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."