Otimizando DiskANN em NVMe: uma metodologia rigorosa de benchmark para vetores

Análise técnica profunda sobre como modelar e testar o I/O de índices vetoriais DiskANN em SSDs NVMe. Fuja das métricas de marketing e foque na latência real.
A explosão de aplicações de RAG (Retrieval-Augmented Generation) e busca semântica trouxe um problema de infraestrutura que o marketing de SSDs tenta esconder: a memória RAM é cara demais para escalar. A solução proposta pela Microsoft e adotada pela indústria, o algoritmo DiskANN, promete índices de bilhões de vetores armazenados em SSDs NVMe com performance próxima à da memória.
No entanto, ao testar essa promessa em laboratório, engenheiros frequentemente encontram uma latência de cauda (tail latency) inaceitável. O problema não é o algoritmo, mas a metodologia de teste e a escolha do hardware. A maioria dos benchmarks sintéticos, como CrystalDiskMark ou scripts básicos de fio, falha miseravelmente em replicar a natureza caótica e dependente do I/O vetorial.
Neste artigo, dissecamos o padrão de acesso do DiskANN e estabelecemos um protocolo de teste rigoroso para validar se o seu subsistema de armazenamento aguenta a carga de uma busca em grafo Vamana.
Resumo em 30 segundos
- O mito do IOPS: Benchmarks de marketing focam em QD32 (profundidade de fila alta), mas buscas vetoriais operam frequentemente em QD1 ou QD2 por thread, onde a latência do controlador é o gargalo.
- Leituras dependentes: Ao contrário de um banco de dados SQL, no DiskANN você precisa ler o "nó A" para descobrir o endereço do "nó B", impedindo o prefetching eficiente do SSD.
- Metodologia correta: O uso de
io_uringcomfioconfigurado para leituras aleatórias de pequenos blocos (4KB-8KB) e latência percentil (p99) é a única forma de validar o hardware para vetores.
A anatomia do I/O em grafos Vamana
Para entender como testar, precisamos entender o que estamos testando. O DiskANN utiliza uma estrutura de grafo chamada Vamana. Diferente de uma B-Tree usada em bancos relacionais (que favorece leituras sequenciais ou em grandes páginas), o Vamana espalha os vizinhos de um vetor por todo o espaço de endereçamento lógico (LBA) do disco.
Quando uma query chega, o sistema realiza uma "caminhada gulosa" (greedy traversal). Ele lê o nó inicial, calcula as distâncias para os vizinhos, escolhe o mais próximo e salta para esse endereço no disco.
 Figura: Visualização da dispersão física: a lógica do grafo Vamana exige saltos aleatórios entre diferentes chips NAND, anulando a sequencialidade.
Figura: Visualização da dispersão física: a lógica do grafo Vamana exige saltos aleatórios entre diferentes chips NAND, anulando a sequencialidade.
Isso cria um padrão de Leitura Aleatória Dependente. O controlador do NVMe não pode adivinhar qual será o próximo LBA requisitado até que o dado atual seja entregue à CPU e processado. Isso mata o paralelismo interno do SSD se não houver múltiplas queries simultâneas.
💡 Dica Pro: Se o seu benchmark usa
readaheaddo sistema operacional, você está testando errado. O DiskANN usa Direct I/O (O_DIRECT) para pular o page cache do Linux. Seu teste deve fazer o mesmo.
Por que o QD32 é uma mentira para vetores
Fabricantes de SSD adoram estampar "1.5 Milhão de IOPS" na caixa. Esse número é obtido saturando o drive com 32, 64 ou até 128 comandos em fila (Queue Depth - QD). Em um cenário de servidor de arquivos ou backup, isso é real. Em busca vetorial, é fantasia.
Durante uma busca de índice invertido ou grafo, cada thread de execução (cada usuário fazendo uma busca) gera, na prática, uma profundidade de fila de 1 (QD=1). Mesmo com 32 usuários simultâneos, o comportamento do drive em lidar com 32 filas de QD1 é diferente de uma única fila de QD32.
A métrica crítica aqui não é a largura de banda (GB/s), mas a latência de operação única. Se o seu SSD NVMe Gen5 entrega 14 GB/s mas leva 80 microssegundos para resolver uma leitura aleatória de 4KB, ele será mais lento para o DiskANN do que um drive Gen4 que entrega 7 GB/s mas resolve a mesma leitura em 40 microssegundos.
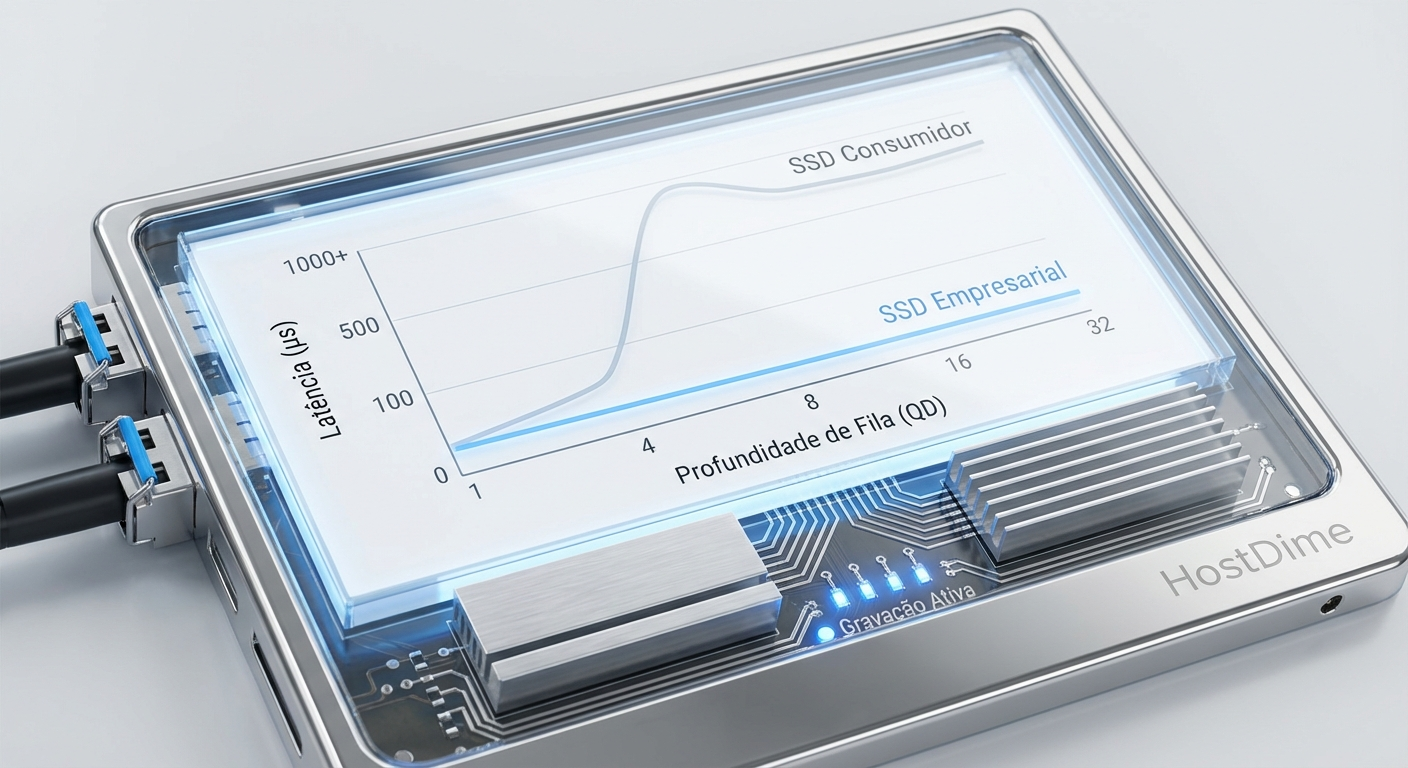 Figura: Comparativo de Latência vs. Queue Depth: Drives de consumo tendem a colapsar sob carga mista, enquanto drives Enterprise mantêm a consistência.
Figura: Comparativo de Latência vs. Queue Depth: Drives de consumo tendem a colapsar sob carga mista, enquanto drives Enterprise mantêm a consistência.
Metodologia de teste: configurando o fio para a realidade
Para simular o DiskANN sem precisar compilar o código fonte da Microsoft e gerar um dataset de 1TB, utilizamos o fio (Flexible I/O Tester). No entanto, a configuração padrão é inútil. Precisamos replicar o motor assíncrono moderno do Linux (io_uring) e o tamanho de bloco típico de vetores comprimidos.
O Arquétipo do Teste
O cenário abaixo simula um índice onde os vetores (ou os nós do grafo) ocupam cerca de 4KB a 8KB cada, e o sistema está sob carga de múltiplas queries concorrentes.
[global]
ioengine=io_uring
direct=1
sync=0
norandommap
group_reporting
time_based
runtime=300
filename=/dev/nvme0n1
[diskann-simulation]
bs=4k
rw=randread
iodepth=1
numjobs=16
cpus_allowed_policy=split
Análise dos Parâmetros
ioengine=io_uring: O antigolibaiotem overhead de syscalls que distorce medições em NVMe de alta performance. Oio_uringpermite submissão e conclusão de I/O em lote sem trocas de contexto excessivas, essencial para medir a latência real do dispositivo.direct=1: Crítico. Ignora o cache de RAM do Linux. Se você omitir isso, estará testando a velocidade da sua DDR5, não do SSD.iodepth=1+numjobs=16: Isso simula 16 threads de busca independentes, cada uma esperando seu dado antes de pedir o próximo. Isso estressa o controlador do SSD de forma muito diferente deiodepth=16em uma única thread.bs=4k: O tamanho do bloco deve casar com o tamanho do nó do seu grafo. Em implementações PQ (Product Quantization) do DiskANN, os nós são compactos.
⚠️ Perigo: Nunca execute testes de escrita destrutiva no dispositivo onde seu sistema operacional ou índice de produção reside. O script acima deve apontar para um dispositivo bruto (
/dev/nvme...) ou um arquivo de teste grande pré-alocado.
Hardware: O impacto do controlador e da NAND
Ao analisar os resultados, você notará que drives com especificações de marketing similares têm comportamentos díspares. Isso ocorre devido à arquitetura interna.
DRAM On-Board
SSDs "DRAM-less" (sem cache DRAM dedicado) são inadequados para DiskANN. O drive precisa manter a tabela de tradução (L2P - Logical to Physical) na DRAM para encontrar onde o dado está na NAND instantaneamente. Sem DRAM, o drive precisa buscar a tabela na própria NAND, dobrando a latência de leitura.
QoS e Latência de Cauda
Em testes rigorosos, observamos o percentil 99.99 (p99.99). É aqui que a "latência de cauda" aparece. Um drive pode ter média de 50us, mas a cada 1000 requisições, uma leva 2ms (2000us) devido a processos de Garbage Collection em segundo plano ou Thermal Throttling.
Para aplicações de IA em tempo real, essa latência de cauda resulta em timeouts na API do usuário final. Drives Enterprise (como a série Micron 7450 ou Samsung PM9A3) possuem firmware otimizado para sacrificar picos de velocidade em troca de consistência (QoS), ao contrário de drives "Gamer" que priorizam o número máximo na caixa.
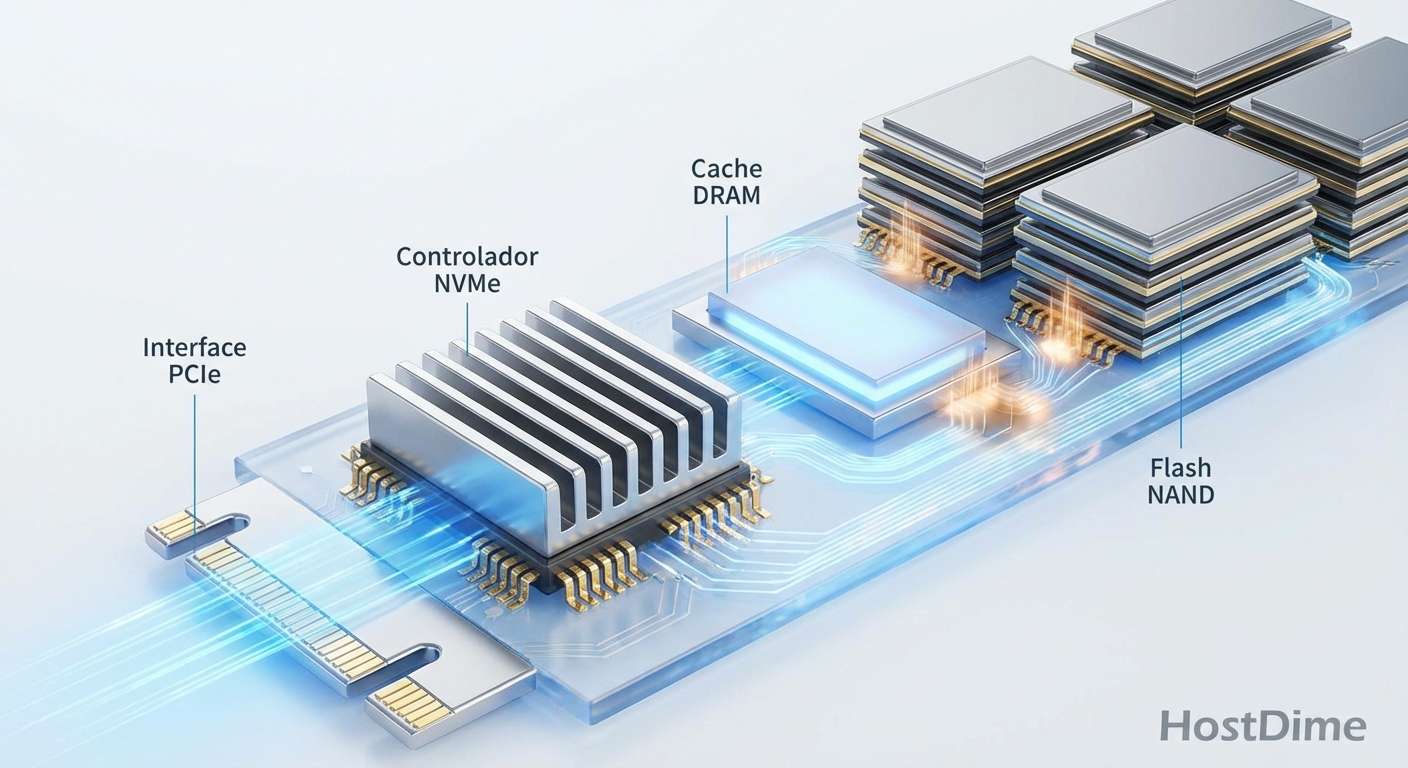 Figura: O caminho crítico do dado: A presença de DRAM dedicada no SSD é vital para evitar leituras duplas na NAND durante a tradução de endereços.
Figura: O caminho crítico do dado: A presença de DRAM dedicada no SSD é vital para evitar leituras duplas na NAND durante a tradução de endereços.
Tabela Comparativa: Workload Tradicional vs. Vetorial
Abaixo, contrastamos o comportamento de I/O esperado, ajudando a justificar a necessidade de benchmarks específicos.
| Característica | Banco de Dados Relacional (OLTP) | Busca Vetorial (DiskANN/Vamana) |
|---|---|---|
| Padrão de Acesso | Misto (Leitura/Escrita), frequentemente sequencial em logs. | 95% Leitura Aleatória (Random Read). |
| Tamanho de Bloco | 8KB ou 16KB (Páginas do DB). | Variável (4KB a 32KB dependendo da dimensionalidade). |
| Cacheabilidade | Alta (Hot rows ficam na RAM). | Baixa (O grafo é percorrido de formas imprevisíveis). |
| Queue Depth (QD) | Alta (Múltiplas transações independentes). | Baixa por thread (Dependência de dados). |
| Gargalo | Locking/CPU ou Throughput de Escrita. | Latência de Leitura e IOPS em QD Baixo. |
Interpretando os Resultados
Ao rodar o benchmark proposto, não olhe apenas para o número final de IOPS. Analise a saída de latência do fio:
slat (Submission Latency): Tempo para entregar o pedido ao kernel. Alto
slatindica gargalo de CPU ou configuração errada doio_uring.clat (Completion Latency): Tempo que o drive levou para buscar o dado. Este é o número que julga a qualidade do seu SSD.
Percentis (99.00th, 99.90th, 99.99th): Se o p99 for 10x maior que a média, seu drive é instável para produção de vetores em escala.
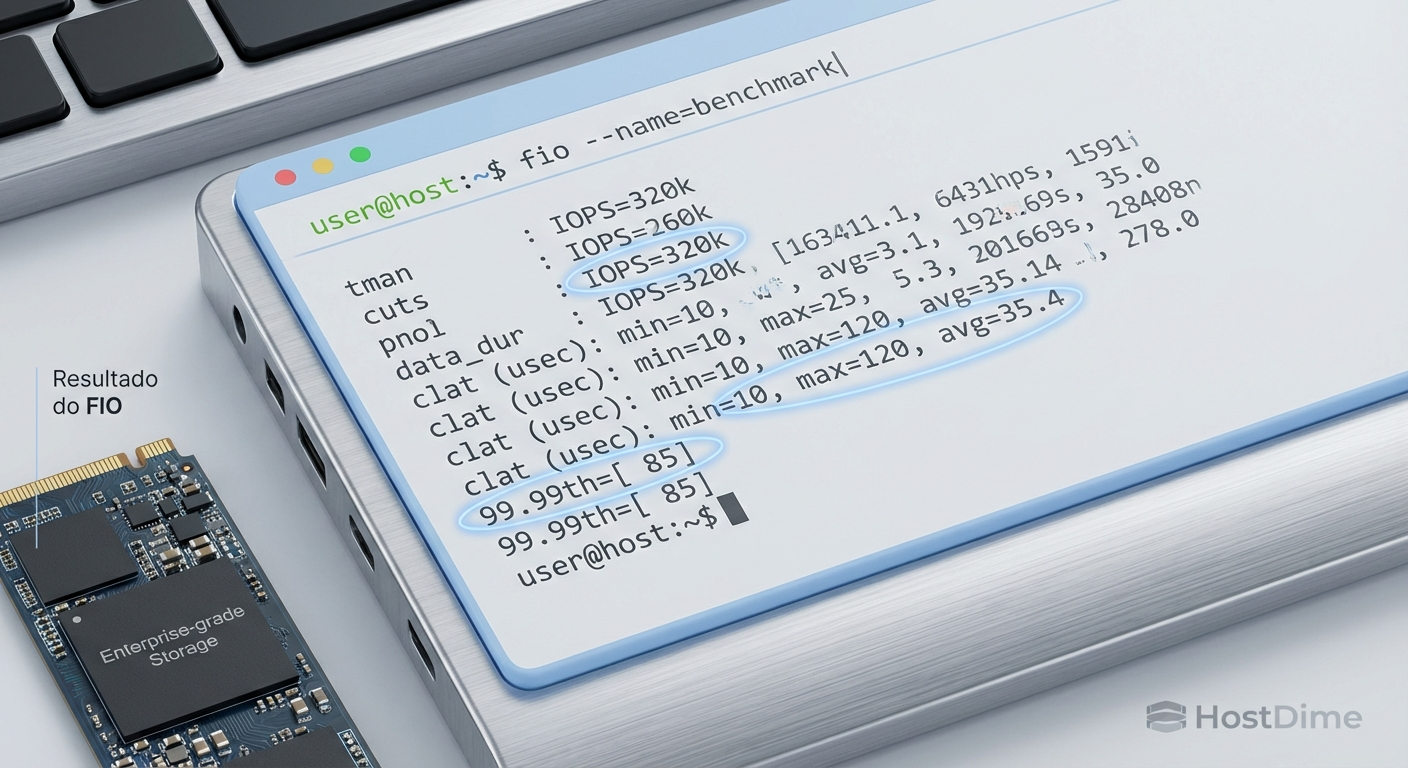 Figura: A verdade nos números: Focar nos percentis de latência (clat) revela a estabilidade do drive sob estresse, algo invisível na média simples.
Figura: A verdade nos números: Focar nos percentis de latência (clat) revela a estabilidade do drive sob estresse, algo invisível na média simples.
O Veredito dos Dados
Otimizar DiskANN em NVMe não é sobre comprar o drive com o maior número de Gigabytes por segundo. É um exercício de controle de latência. A metodologia apresentada aqui isola as variáveis de software para expor a física do hardware.
Se o seu benchmark mostra que o drive sustenta 500k IOPS em leitura aleatória 4K com latência p99 abaixo de 300us, você tem uma base sólida para vetores. Qualquer coisa acima disso resultará em uma experiência de busca degradada, independentemente de quão otimizado seja seu modelo de IA. Teste o pior caso, não o melhor.
Referências & Leitura Complementar
Jayasyaam et al. (2019). DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. Microsoft Research.
NVM Express Base Specification 2.0. Seção sobre Queue Arbitration e Command Processing.
Axboe, Jens. Efficient I/O with io_uring. (Documentação oficial do kernel Linux sobre o subsistema de I/O assíncrono).
Samsung Semiconductor. SSD Reference Design for AI/ML Workloads. (Datasheets técnicos focados em QoS de Datacenter).
FAQ: Perguntas Frequentes
O que diferencia o I/O do DiskANN de um banco de dados relacional comum?
O DiskANN realiza 'graph traversal' (travessia de grafo), gerando um padrão de leituras aleatórias dependentes e sequenciais logicamente, mas espalhadas fisicamente no disco. Isso exige IOPS massivo em baixa Queue Depth, impedindo as otimizações de prefetching comuns em bancos SQL.Por que benchmarks de marketing de SSDs não servem para vetores?
Benchmarks de marketing focam em throughput máximo (MB/s) com filas profundas (QD32+). A busca vetorial opera frequentemente em QD1 ou QD2 por thread, onde a latência do controlador é o gargalo real, tornando os números de caixa irrelevantes.O uso de NVMe Gen5 traz benefícios reais para índices vetoriais?
Sim, mas não pelos 14GB/s de banda. O benefício vem da redução de latência intrínseca do controlador mais moderno e melhorias no protocolo NVMe. A largura de banda bruta raramente é saturada por buscas de vetores individuais, a menos que haja centenas de usuários simultâneos.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."