Otimizando I/O no KVM: De virtio-blk ao multi-queue em NVMe

Descubra como eliminar gargalos de storage em VMs KVM. Guia avançado sobre virtio-blk, multi-queue, iothreads e io_uring para máxima performance em NVMe.
Você investiu pesado em armazenamento. Comprou SSDs NVMe Enterprise, configurou um array ZFS ou RAID robusto no host, e as métricas de disco local são impressionantes: milhões de IOPS e latência na casa dos microssegundos. Mas, ao subir uma VM no KVM (seja via Proxmox, oVirt ou QEMU puro), a performance cai drasticamente. O throughput é aceitável, mas a latência de I/O dispara e a CPU do host parece engasgar.
Esse cenário é o pesadelo clássico de "overhead de virtualização". A boa notícia é que, na maioria dos casos modernos, o problema não é o hardware, mas sim como o caminho de dados (dataplane) foi arquitetado dentro do hypervisor.
O armazenamento em virtualização não é apenas sobre onde os bits vivem; é sobre como eles viajam do sistema operacional convidado (Guest) até o controlador físico. Se você ainda está usando configurações padrão de 5 anos atrás, sua VM está operando com um freio de mão puxado.
Resumo em 30 segundos
- O Gargalo: O padrão de fila única (single-queue) no KVM cria um funil onde todas as solicitações de I/O disputam a atenção de uma única vCPU, causando latência alta em discos NVMe rápidos.
- A Solução: Habilitar
multi-queueno driver virtio-blk permite que cada vCPU tenha seu próprio canal de I/O, paralelizando interrupções e eliminando bloqueios.- O Backend: Substituir o antigo AIO nativo pelo moderno
io_uringno Linux reduz drasticamente as chamadas de sistema (syscalls), aproximando a performance da VM da velocidade nativa do hardware.
Quando o storage NVMe parece lento dentro da VM
Para entender a lentidão, precisamos dissecar o caminho do I/O. Em uma configuração padrão (legacy), quando uma aplicação dentro da VM solicita a gravação de um bloco no disco, ocorre uma "dança" complexa e custosa.
O Guest OS envia o comando para o driver de disco virtual. Esse driver precisa notificar o hypervisor (QEMU/KVM) de que há trabalho a ser feito. Isso gera um VM Exit — a CPU para de executar o código da VM e passa o controle para o host. O QEMU, que roda no userspace do host, pega essa requisição, processa e faz uma chamada de sistema (syscall) para o kernel do Linux gravar no disco físico.
O problema não é o disco. O problema é a burocracia.
Em discos rotacionais (HDD) ou SSDs SATA antigos, a latência do hardware (ms) era tão alta que esse overhead de software (µs) era irrelevante. Com NVMe, onde o hardware responde em microssegundos, o tempo gasto trocando de contexto entre Guest, Hypervisor e Kernel torna-se maior que o tempo de gravação do dado em si.
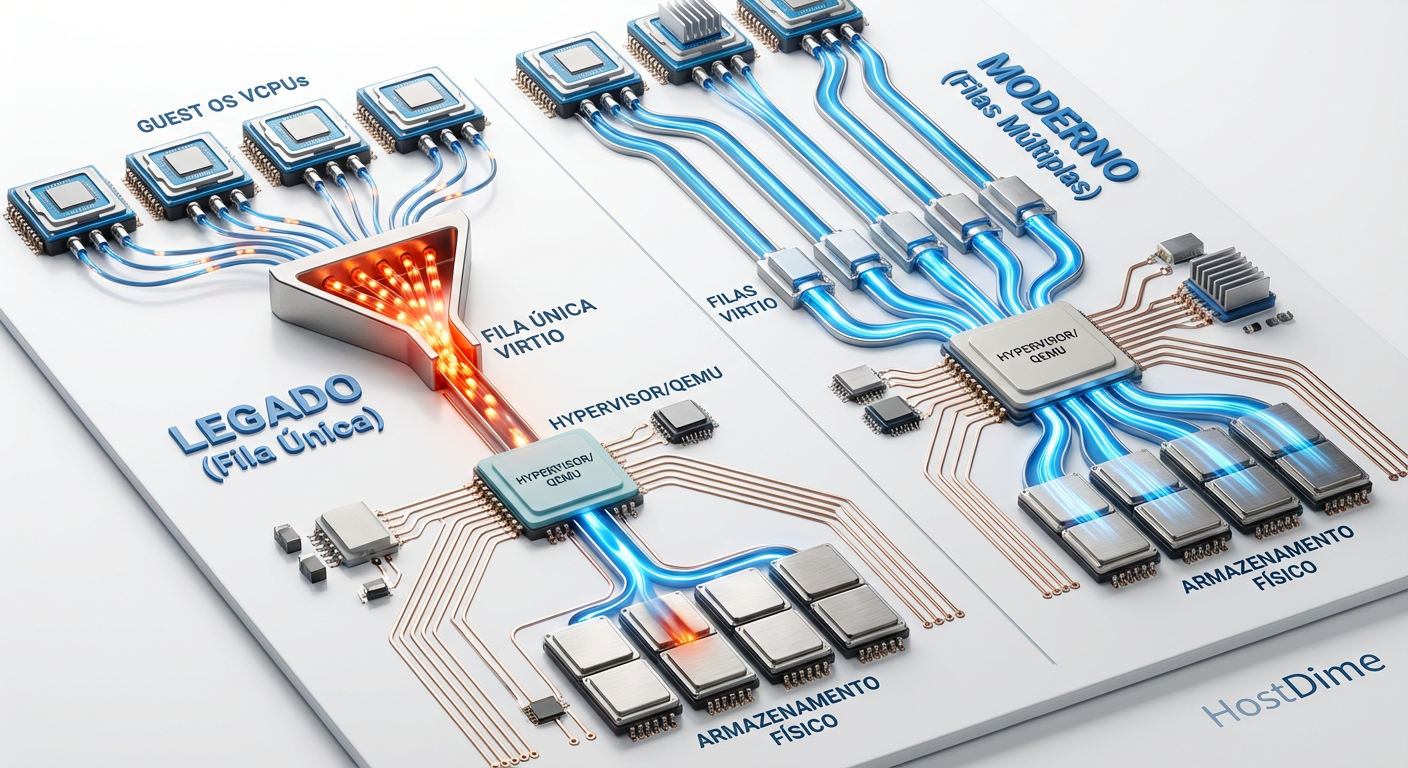 Figura: Comparativo visual do fluxo de dados: O gargalo da fila única versus o paralelismo do multi-queue no KVM.
Figura: Comparativo visual do fluxo de dados: O gargalo da fila única versus o paralelismo do multi-queue no KVM.
O custo oculto do context switching e o loop do QEMU
O maior vilão aqui é o Global Mutex ou o loop de eventos principal do QEMU. Em configurações básicas, o processamento do I/O compete com outras tarefas de emulação da VM. Se o thread principal do QEMU estiver ocupado lidando com tráfego de rede ou interrupções de timer, seu pedido de gravação no disco NVMe entra em uma fila de espera.
Isso gera o que chamamos de "latência de cauda" (tail latency). A média de velocidade pode parecer boa, mas de tempos em tempos, uma operação leva 10x mais tempo que o normal porque ficou presa no engarrafamento do processador.
⚠️ Perigo: Monitorar apenas o throughput (MB/s) é uma armadilha. Em bancos de dados e aplicações transacionais, a latência (ms) e o I/O Wait são os verdadeiros indicadores de saúde do storage. Uma VM pode estar transferindo 2GB/s e ainda assim estar lenta para o usuário final devido ao tempo de resposta.
A falácia de aumentar vCPUs para resolver gargalos de I/O
Quando um administrador vê o iowait alto dentro da VM, o instinto natural é adicionar mais vCPUs. "Se a CPU está esperando, vamos dar mais processadores para ela dividir a carga", certo?
Errado.
Em um cenário de armazenamento single-queue (fila única), adicionar vCPUs pode na verdade piorar a performance. Imagine que você tem apenas um guichê de atendimento (a fila de I/O do disco) e você aumenta o número de pessoas (vCPUs) tentando passar por esse guichê ao mesmo tempo. O resultado é mais contenção de bloqueio (lock contention).
As vCPUs adicionais gastam ciclos brigando para acessar a fila de disco, gerando overhead de sincronização sem processar dados reais. O segredo não é adicionar processadores, mas sim abrir mais guichês.
Arquitetando a performance com multi-queue e iothreads
A virada de chave para performance de NVMe em virtualização reside em duas tecnologias complementares: Virtio-blk Multi-Queue e IOThreads.
O poder do Multi-Queue (blk-mq)
O protocolo virtio moderno suporta múltiplas filas de requisição. A ideia é alinhar a topologia de armazenamento com a topologia de CPU. Se você tem uma VM com 8 vCPUs, você deve configurar o disco virtual para ter 8 filas (queues).
Isso permite que cada vCPU envie requisições de I/O para o disco sem precisar bloquear ou esperar pelas outras vCPUs. O driver virtio-blk-pci expõe múltiplos vetores de interrupção (MSI-X), permitindo que a resposta do disco (a confirmação de que o dado foi gravado) seja entregue diretamente na vCPU que solicitou a operação.
Isso elimina o gargalo do "guichê único" e permite que a performance escale linearmente com o número de núcleos.
IOThreads: Isolando o ruído
Mesmo com multi-queue, o processamento ainda pode ocorrer no thread principal do QEMU. Para isolar completamente o armazenamento, utilizamos IOThreads.
Ao definir um IOThread dedicado para um disco virtual, você cria um thread separado no host Linux cuja única função é processar I/O para aquele disco. Isso tira a carga do loop principal do QEMU. O resultado é uma latência muito mais previsível e estável, pois o processamento do disco não compete mais com a emulação de vídeo, mouse ou rede.
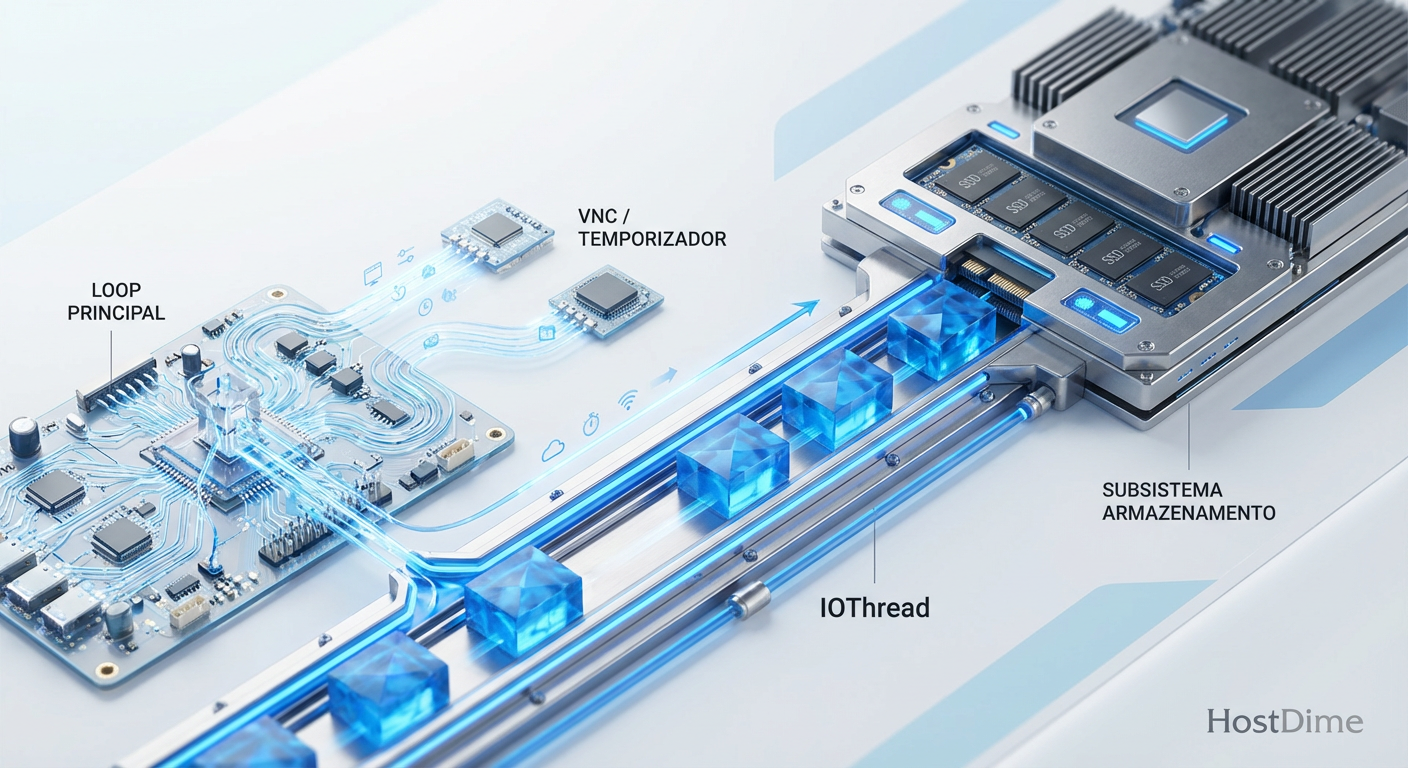 Figura: Arquitetura de IOThreads: Segregando o tráfego pesado de armazenamento do loop principal de emulação para garantir consistência.
Figura: Arquitetura de IOThreads: Segregando o tráfego pesado de armazenamento do loop principal de emulação para garantir consistência.
Modernizando o backend com io_uring e drivers NVMe
Até agora falamos do frontend (dentro da VM e QEMU). Mas como o QEMU fala com o kernel do host? Durante anos, o padrão ouro foi o native AIO (Asynchronous I/O) do Linux. Ele era bom, mas tinha falhas de design que exigiam muitas chamadas de sistema (syscalls) e cópias de memória desnecessárias.
Entra em cena o io_uring.
Introduzido em kernels Linux mais recentes (5.1+), o io_uring muda fundamentalmente como o userspace (QEMU) fala com o kernel. Ele utiliza dois anéis de buffer compartilhados (Submission Queue e Completion Queue) na memória.
O QEMU coloca um pedido de I/O na fila de submissão.
O Kernel pega o pedido, executa e coloca o resultado na fila de conclusão.
O QEMU lê o resultado.
Tudo isso acontece sem a necessidade de emitir uma syscall para cada operação individual. Em cargas de trabalho intensas de NVMe, onde temos milhares de IOPS, a redução de overhead de CPU no host é massiva.
💡 Dica Pro: Para usar io_uring, certifique-se de que seu host (Hypervisor) esteja rodando um Kernel 5.10 ou superior para estabilidade, e que o QEMU esteja configurado com
aio=io_uring. Em testes de laboratório com SSDs NVMe Gen4, a troca denativeparaio_uringresultou em uma redução de 20% no uso de CPU do host para a mesma carga de I/O.
Tabela Comparativa: Tecnologias de Disco Virtual
Para consolidar o entendimento, vamos comparar as opções de apresentação de disco para a VM.
| Característica | Virtio-blk (Recomendado) | Virtio-SCSI | NVMe Passthrough (PCIe) |
|---|---|---|---|
| Performance Pura | Altíssima (Menor overhead) | Alta | Nativa (Máxima) |
| Latência | Baixa | Média/Baixa | Mínima (Hardware real) |
| Escalabilidade | Excelente com Multi-Queue | Boa (Muitos LUNs) | Limitada pelo Hardware |
| Complexidade | Baixa | Média | Alta |
| Live Migration | Suportado | Suportado | Não Suportado (Geralmente) |
| Caso de Uso | 95% das cargas (DBs, Web) | Legacy, Tape, centenas de discos | Latência crítica extrema |
Métricas que comprovam a eficiência do paralelismo
Como saber se suas otimizações funcionaram? Não confie na "sensação" de velocidade. Use dados.
Antes de aplicar o multi-queue e io_uring, execute um benchmark sintético (como fio) e capture o /proc/interrupts dentro da VM. Você verá provavelmente todas as interrupções de virtio0-request sendo tratadas por uma única CPU (CPU0).
Após a configuração correta (queues=N igual ao número de vCPUs), ao rodar cat /proc/interrupts, você deverá ver as interrupções de disco distribuídas uniformemente entre todos os núcleos.
Além disso, observe a métrica de "avgqu-sz" (tamanho médio da fila) no iostat -x 1. Em um sistema otimizado, esse número deve ser baixo, indicando que os dados estão fluindo e não represando. Se o throughput subiu e a latência (await) caiu, você atingiu o objetivo.
 Figura: O impacto visual da otimização: Latência estável e carga de CPU balanceada após a implementação de multi-queue.
Figura: O impacto visual da otimização: Latência estável e carga de CPU balanceada após a implementação de multi-queue.
Veredito Técnico
A era de tratar discos virtuais como caixas pretas acabou. Com a velocidade dos dispositivos NVMe atuais, o hypervisor tornou-se o principal gargalo se não for configurado corretamente.
Para qualquer carga de trabalho de produção moderna no KVM, a configuração padrão não é suficiente. Minha recomendação direta é: utilize virtio-blk como padrão (evite SATA/IDE a todo custo), habilite multi-queue igualando o número de vCPUs da VM, use IOThreads para isolar o processamento e, se seu kernel permitir, force o backend para io_uring.
Isso não é apenas "tunning" para ganhar 5% de performance. É uma mudança arquitetural que pode dobrar a capacidade de transação do seu banco de dados sem gastar um centavo a mais em hardware. O storage é rápido; o software é que precisa sair da frente.
FAQ: Perguntas Frequentes
Virtio-blk ou Virtio-scsi: qual é mais rápido?
Para performance pura e latência mínima, o virtio-blk é superior por ter menos overhead de protocolo. O virtio-scsi é recomendado apenas quando se precisa de centenas de discos por VM ou comandos SCSI específicos (como TRIM/UNMAP em versões antigas ou controle de fitas).O que é io_uring e por que usar no KVM?
O io_uring é uma interface de I/O assíncrono do Linux que elimina a necessidade de syscalls custosas para cada operação, reduzindo drasticamente a latência e o uso de CPU em comparação ao antigo 'native AIO'. Ele permite que o QEMU e o Kernel troquem dados através de anéis de memória compartilhada.Quantas filas (queues) devo configurar no virtio?
A regra de ouro é alinhar o número de filas (queues) com o número de vCPUs da VM, permitindo que cada processador virtual tenha um canal direto de interrupção, evitando congestionamento e bloqueios (locks) desnecessários.Referências & Leitura Complementar
OASIS Virtual I/O Device (VIRTIO) Version 1.1. Committee Specification 01. (Especificação técnica do protocolo virtio e filas).
Linux Kernel Organization. "Efficient IO with io_uring". (Documentação oficial do Kernel sobre a implementação de anéis de I/O).
QEMU Project Documentation. "QEMU Block Layer and IOThreads". (Detalhes sobre a arquitetura de threading do emulador).
KVM Forum. "Improving KVM I/O Performance with io_uring". (Apresentações técnicas sobre benchmarks de backend de armazenamento).

Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."