Otimizando NVMe-oF sobre TCP: Modelagem de Capacidade e a Lei da Escalabilidade
Análise de planejador: como modelar a curva de crescimento do NVMe/TCP, mitigar o overhead de CPU com tuning de Kernel e quando migrar para DPUs para evitar o 'cliff' de performance.
A ilusão mais perigosa na arquitetura de armazenamento moderna é a crença de que a largura de banda resolve problemas de latência. Ao transportarmos o protocolo NVMe — projetado para acesso direto à memória e paralelismo massivo — sobre o TCP, introduzimos uma variável de atrito que muitos arquitetos ignoram até atingirem o "muro" de performance. Não se trata apenas de configurar MTUs ou Jumbo Frames; trata-se de física computacional.
Para entender o comportamento do NVMe over Fabrics (NVMe-oF) via TCP, precisamos abandonar a visão linear de crescimento. O rendimento (throughput) não escala indefinidamente com a adição de núcleos de CPU ou largura de banda de rede. Ele obedece à Lei Universal da Escalabilidade (USL). Se você não modelar o coeficiente de coerência ($\beta$) da sua infraestrutura, seu cluster de storage All-Flash se tornará um aquecedor de data center muito caro.
Resumo em 30 segundos
- A Falácia Linear: Adicionar mais núcleos de CPU para processar I/O via TCP pode reduzir a performance total devido à latência de coerência (crosstalk entre núcleos).
- O Fator $\beta$: Em NVMe/TCP, o gargalo raramente é o fio (wire speed), mas sim a sobrecarga de interrupções e trocas de contexto no Kernel Linux.
- A Solução Matemática: O ajuste de afinidade de IRQ e batching adia a saturação, mas apenas o offload via DPU/SmartNIC elimina a curva de escalabilidade retrógrada.
A Física do Protocolo: A Lei Universal da Escalabilidade (USL)
A maioria dos planejadores de capacidade utiliza a Lei de Amdahl para prever o ganho de performance. Amdahl é otimista demais para sistemas distribuídos de armazenamento. Ela assume que a contenção ($\alpha$) é o único inibidor. No mundo real do NVMe/TCP, enfrentamos algo pior: a coerência ($\beta$).
A equação da USL define a capacidade relativa $C(N)$ com base na carga $N$:
$$ C(N) = \frac{N}{1 + \alpha(N-1) + \beta N(N-1)} $$
No contexto de NVMe-oF/TCP:
$\alpha$ (Contenção): É o enfileiramento. Recursos que não podem ser compartilhados simultaneamente (ex: locks em estruturas de dados do kernel, acesso a filas de submissão NVMe). Isso limita a escalabilidade a uma assíntota.
$\beta$ (Coerência): É o custo de manter o estado consistente entre múltiplos processadores. Quando pacotes TCP chegam a 100Gbps, o thrashing de cache L3 e a comunicação entre núcleos para processar a pilha de rede criam uma penalidade quadrática.
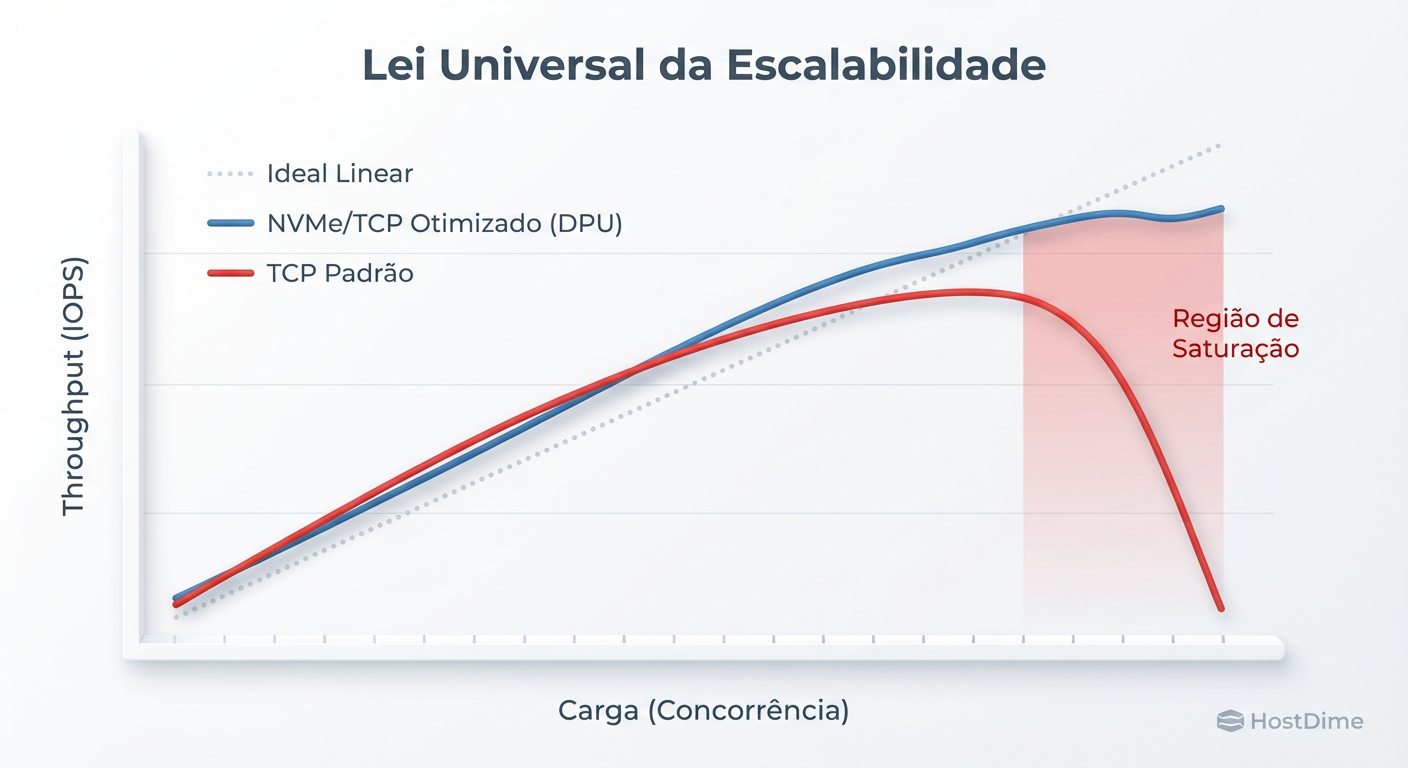 Fig. 1: A Lei Universal da Escalabilidade aplicada ao Storage. O 'Standard TCP' sofre de latência de coerência (β) severa, causando retrocesso de performance sob alta carga.
Fig. 1: A Lei Universal da Escalabilidade aplicada ao Storage. O 'Standard TCP' sofre de latência de coerência (β) severa, causando retrocesso de performance sob alta carga.
Se o seu $\beta$ for maior que zero (e no TCP padrão via software, ele sempre é), existe um ponto de inflexão matemático. Após esse ponto, adicionar mais carga ou mais núcleos de processamento causa escalabilidade retrógrada. A performance não apenas para de crescer; ela cai.
⚠️ Perigo: Em testes de carga sintéticos (fio), é comum ver latências de 4KB subirem de 80µs para 500µs repentinamente. Isso não é congestionamento de rede; é a CPU gastando mais tempo gerenciando a coerência dos dados do que movendo os dados em si.
O "Imposto" do TCP: Identificando o Cliff de CPU
O protocolo NVMe foi desenhado para eliminar a CPU do caminho de dados (via PCIe e DMA). O TCP, por outro lado, foi desenhado nos anos 70 para garantir a entrega em redes não confiáveis. Casar os dois exige que a CPU volte a participar de cada transação.
A "taxa" ou imposto do TCP se manifesta em ciclos de CPU por Byte. Em redes de 100GbE ou 200GbE, um servidor x86 moderno pode precisar dedicar de 30% a 50% de seus núcleos apenas para processar o tráfego de rede (encapsulamento, checksums, reordenamento de pacotes e acks).
A Anatomia da Latência $\beta$
Quando um initiator envia uma solicitação de leitura:
O pacote chega na NIC.
A NIC gera uma interrupção de hardware.
A CPU interrompe o que está fazendo (context switch) para tratar a interrupção.
O Kernel copia os dados do buffer da NIC para o espaço do kernel e depois para o espaço do usuário (embora o Zero Copy tente mitigar isso, a sobrecarga de metadados persiste).
Esse ciclo destrói a linearidade. O "Cliff" de recursos ocorre quando a frequência de interrupções excede a capacidade da CPU de processá-las sem gerar cache misses massivos.
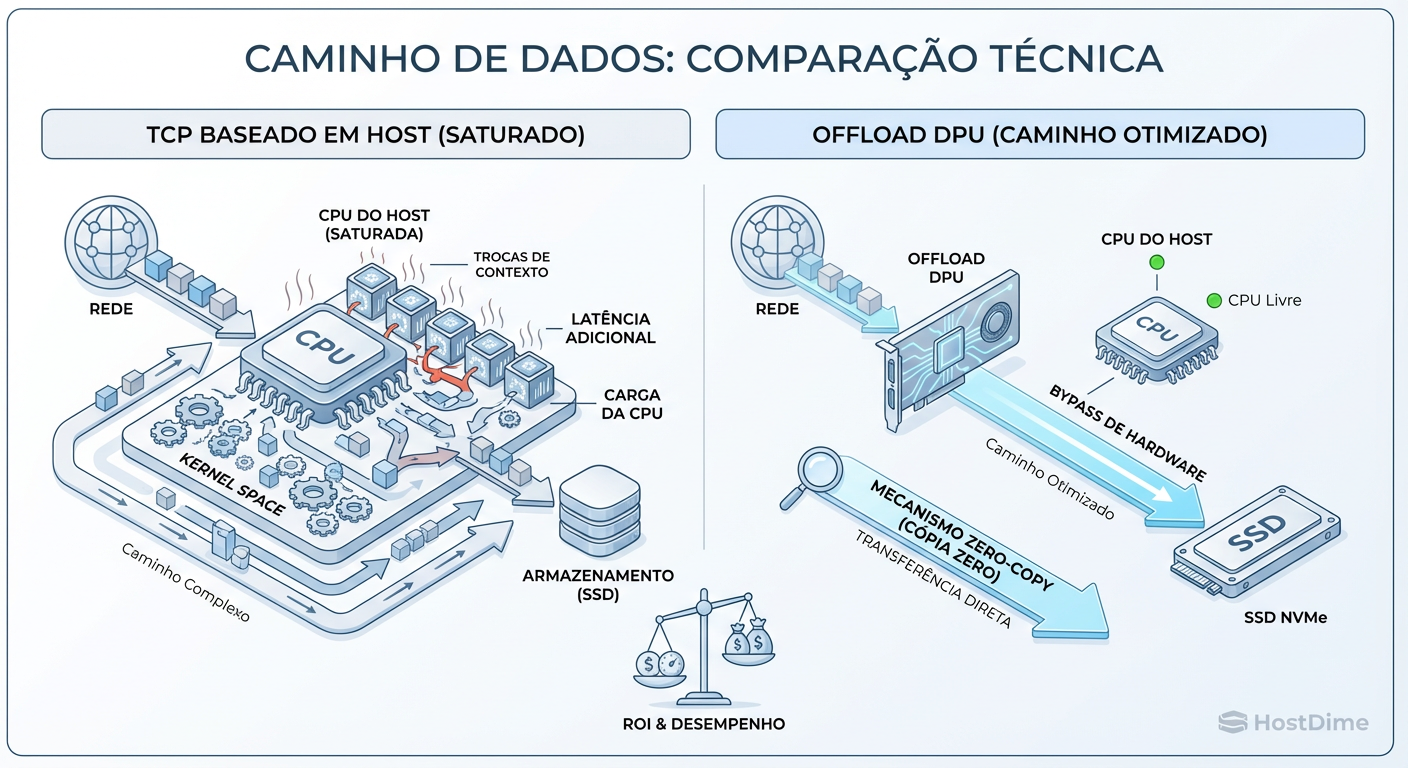 Fig. 2: A anatomia do 'Overhead'. À esquerda, o ciclo custoso de interrupções do kernel. À direita, o offload completo da pilha de rede.
Fig. 2: A anatomia do 'Overhead'. À esquerda, o ciclo custoso de interrupções do kernel. À direita, o offload completo da pilha de rede.
Ajuste Fino no Kernel Linux: Adicionando a Saturação
Antes de investir em novo hardware, podemos manipular os parâmetros do Linux para reduzir $\alpha$ e $\beta$, "achatando" a curva da USL. O objetivo não é eliminar o imposto, mas torná-lo previsível.
1. Afinidade de Interrupção (IRQ Affinity)
O padrão do Linux (irqbalance) é frequentemente subótimo para NVMe de alto desempenho. Ele tende a espalhar interrupções por todos os núcleos, maximizando $\beta$ (custo de coerência). A estratégia correta é o pinning: fixar filas de NVMe e filas de RX/TX da NIC aos mesmos núcleos físicos (evitando cruzar fronteiras NUMA).
💡 Dica Pro: Utilize scripts como
set_irq_affinitypara alinhar as filas da NIC com os núcleos que processam o armazenamento. Se a NIC está no socket 0, garanta que apenas núcleos do socket 0 tratem suas interrupções. Atravessar o barramento QPI/UPI para acessar a memória do outro socket é um assassino de latência.
2. Batching e Coalescência (Gerenciando $\alpha$)
Podemos reduzir a frequência de interrupções (reduzindo o overhead de CPU) ao custo de um ligeiro aumento na latência base.
Adaptive-rx: Configure
ethtool -C <interface> adaptive-rx on. Isso permite que a NIC agrupe pacotes antes de interromper a CPU.Queue Depth: Aumentar a profundidade da fila NVMe nem sempre é benéfico. Pela Lei de Little ($L = \lambda W$), se o sistema de processamento (CPU) está saturado, aumentar a fila ($L$) apenas aumenta o tempo de espera ($W$), sem melhorar o throughput ($\lambda$). Mantenha filas curtas em cenários de latência sensível.
3. Busy Polling
Para cenários onde a latência é crítica e o consumo de energia é secundário, o Busy Polling (/sys/block/<device>/queue/io_poll) instrui a CPU a verificar ativamente a conclusão de I/O em vez de esperar por uma interrupção e dormir. Isso reduz drasticamente o context switch, diminuindo $\beta$ localmente, mas consome 100% do ciclo daquele núcleo.
A Fronteira do Hardware: DPUs e a Quebra da Linearidade
Há um limite termodinâmico para o quanto podemos otimizar o TCP em software (x86). Quando a modelagem indica que o custo de CPU para sustentar a rede excede o valor do armazenamento entregue, a matemática exige uma mudança de arquitetura.
É aqui que entram as DPUs (Data Processing Units) e SmartNICs. Elas não são apenas placas de rede rápidas; são computadores dedicados a rodar a pilha de rede e armazenamento.
O Modelo de Offload
Ao mover o protocolo NVMe/TCP para a DPU:
Eliminação de $\beta$ no Host: O processador x86 principal não vê mais pacotes TCP. Ele vê apenas transações NVMe (via PCIe) ou, em casos de full offload, o storage é apresentado como um dispositivo de bloco local, sem overhead de rede visível ao OS.
Isolamento de Falhas: O "ruído" da rede não polui o cache L3 da CPU principal.
 Fig. 3: O cálculo de ROI no planejamento de capacidade. Em redes >100GbE, queimar ciclos de CPU x86 para processar TCP torna-se financeiramente insustentável.
Fig. 3: O cálculo de ROI no planejamento de capacidade. Em redes >100GbE, queimar ciclos de CPU x86 para processar TCP torna-se financeiramente insustentável.
Análise de ROI: CPU vs. DPU
O cálculo deve ser feito da seguinte forma: $$ \text{Custo}_{\text{Oportunidade}} = (\text{Cores consumidos por TCP}) \times (\text{Valor por Core}) $$
Se um servidor de storage com 64 Cores gasta 16 Cores (25%) apenas gerenciando tráfego TCP de 200Gbps, você está desperdiçando 25% do CAPEX do servidor em "encanamento". Uma DPU que custa menos que o valor proporcional desses 16 Cores oferece um ROI positivo imediato, além de garantir uma latência de cauda (P99) estável.
Tabela Comparativa: O Salto Evolutivo
Para situar a decisão de infraestrutura, compare as abordagens:
| Característica | Standard NIC + Software TCP | Otimização Kernel (Polling/Affinity) | DPU / SmartNIC Offload |
|---|---|---|---|
| Gargalo Principal | CPU (Interrupções/Context Switch) | CPU (Ciclos de Polling) | Largura de Banda PCIe/Rede |
| Escalabilidade (USL) | Retrógrada (Alto $\beta$) | Sub-linear (Médio $\beta$) | Linear (Zero $\beta$ no Host) |
| Latência P99 | Imprevisível sob carga | Baixa, mas custosa | Baixa e Determinística |
| Uso de CPU do Host | Alto (30%+) | Máximo (100% em cores dedicados) | Quase Nulo (<1%) |
| Complexidade | Baixa | Alta (Tuning constante) | Média (Integração de Hardware) |
Previsão e Alerta
O NVMe-oF sobre TCP democratizou o acesso ao armazenamento de alta performance, libertando-nos das amarras proprietárias do Fibre Channel e da complexidade do RDMA/RoCE. No entanto, essa liberdade tem um preço computacional.
Minha projeção para os próximos 24 meses é clara: à medida que o PCIe 6.0 e o CXL começarem a saturar as pistas de dados, a abordagem de "TCP em Software" se tornará matematicamente inviável para o tier de alta performance (Tier 0/1). Se o seu modelo de capacidade mostra que você precisará de mais de 400Gbps de throughput por nó até 2026, pare de tentar otimizar sysctl.conf. O software não pode vencer a física. Comece a planejar a introdução de DPUs ou prepare-se para explicar por que seus novos processadores de última geração estão engasgados processando pacotes de rede.
Perguntas Frequentes
1. O NVMe/TCP é mais lento que o NVMe/FC (Fibre Channel)?
Em termos de latência bruta "fio a fio", o Fibre Channel ainda possui uma ligeira vantagem histórica devido ao processamento em hardware nativo. No entanto, o NVMe/TCP moderno, especialmente com DPUs, já entrega latências muito similares (diferença de 5-10µs), com a vantagem de custo e flexibilidade da infraestrutura Ethernet.
2. Posso usar Jumbo Frames (MTU 9000) para resolver o problema da CPU?
Ajuda, mas não resolve. Jumbo Frames reduzem a taxa de pacotes (PPS) para o mesmo throughput, diminuindo o número de interrupções. Isso reduz o parâmetro $\beta$ da USL, empurrando o ponto de saturação para a direita, mas não elimina a sobrecarga de cópia de memória e processamento de protocolo.
3. O que é "Head-of-Line Blocking" no contexto de TCP e como isso afeta o Storage?
No TCP, se um pacote é perdido, todos os pacotes subsequentes devem esperar pela retransmissão para garantir a ordem. Isso cria picos de latência (jitter). O NVMe/TCP mitiga isso usando múltiplas conexões TCP por sessão, mas em redes com perda de pacotes, a performance degrada muito mais agressivamente do que em protocolos como RoCE v2.
4. O RDMA (RoCE) não seria melhor que o TCP para evitar uso de CPU?
Sim, o RDMA oferece latência menor e zero uso de CPU para movimentação de dados. Porém, o RoCE exige uma rede Lossless (PFC/ECN configurados perfeitamente nos switches), o que é complexo de manter em escala (data centers grandes). O NVMe/TCP roda em qualquer rede Ethernet padrão, trocando um pouco de performance por facilidade de gestão massiva.

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."