Otimizando ZFS no Proxmox: O Guia Definitivo de Tuning para NVMe

Seu NVMe de 7000MB/s está lento na VM? Descubra como alinhar volblocksize, ashift e filas VirtIO para eliminar a latência no Proxmox VE.
Você comprou aquele servidor com NVMe Gen4, instalou o Proxmox VE, configurou o ZFS e, ao rodar a primeira VM, a performance pareceu... medíocre. Se você já passou por isso, bem-vindo ao clube. É um cenário clássico que vejo repetidamente em implementações de infraestrutura hiperconvergente: hardware de ponta sendo estrangulado por uma configuração de software padrão.
O ZFS é, sem dúvida, o sistema de arquivos mais robusto para integridade de dados, mas ele não foi desenhado nativamente para a latência ultrabaixa que dispositivos NVMe modernos oferecem. Quando colocamos uma camada de virtualização (KVM) em cima disso, criamos um "sanduíche de complexidade" onde cada desalinhamento custa IOPS (Input/Output Operations Per Second).
Neste artigo, vamos dissecar o caminho do dado (datapath), do sistema operacional convidado até a célula NAND, e transformar seu Proxmox em uma plataforma de armazenamento de alta performance.
Resumo em 30 segundos
- Alinhamento é tudo: O maior vilão da performance é o desalinhamento entre o tamanho do bloco da VM, o
volblocksizedo ZFS e o setor físico do SSD.- IOthread é obrigatório: Sem ativar o IOthread e usar o controlador correto (VirtIO-SCSI Single), o storage compete por CPU com a aplicação da VM.
- Cuidado com o Sync: Desativar
sync(sync=disabled) mascara problemas de hardware ruim (SSDs sem PLP) ao custo de risco severo de perda de dados. Não faça isso em produção.
O paradoxo da alta latência em drives NVMe Gen4
É comum ver administradores frustrados porque um drive capaz de 7.000 MB/s de leitura sequencial entrega apenas uma fração disso dentro de uma VM Windows ou Linux. O problema aqui não é a largura de banda (throughput), é a latência.
Em um ambiente virtualizado, cada operação de escrita passa por múltiplas traduções. O Guest OS escreve no disco virtual, o KVM intercepta essa chamada, o QEMU a processa, passa para o kernel do host, que entrega ao ZFS. O ZFS então calcula checksums, decide onde alocar o bloco (Copy-On-Write) e finalmente comita no hardware.
Se o seu armazenamento não responder em microssegundos, a fila de I/O do sistema operacional convidado cresce. O resultado? Aquele banco de dados SQL Server ou PostgreSQL começa a apresentar "wait times" altos, mesmo que o disco não esteja saturado em MB/s.
A anatomia oculta: Amplificação de escrita e o 'Block Size Mismatch'
Aqui reside a causa raiz de 80% dos problemas de performance em storage ZFS com máquinas virtuais. O ZFS opera com um conceito chamado volblocksize para Zvols (os volumes de bloco que servem como discos virtuais). O padrão do Proxmox muitas vezes é 8k.
Imagine que sua VM Windows formata o disco com NTFS usando clusters de 4k. Quando a VM tenta escrever 4k de dados:
O ZFS recebe o pedido de 4k.
O
volblocksizeé 8k. O ZFS não pode escrever apenas metade de um bloco.Ele precisa ler o bloco de 8k existente, modificar os 4k novos e escrever os 8k inteiros de volta.
Isso é o clássico Read-Modify-Write. Você acabou de dobrar a latência e o desgaste do seu SSD.
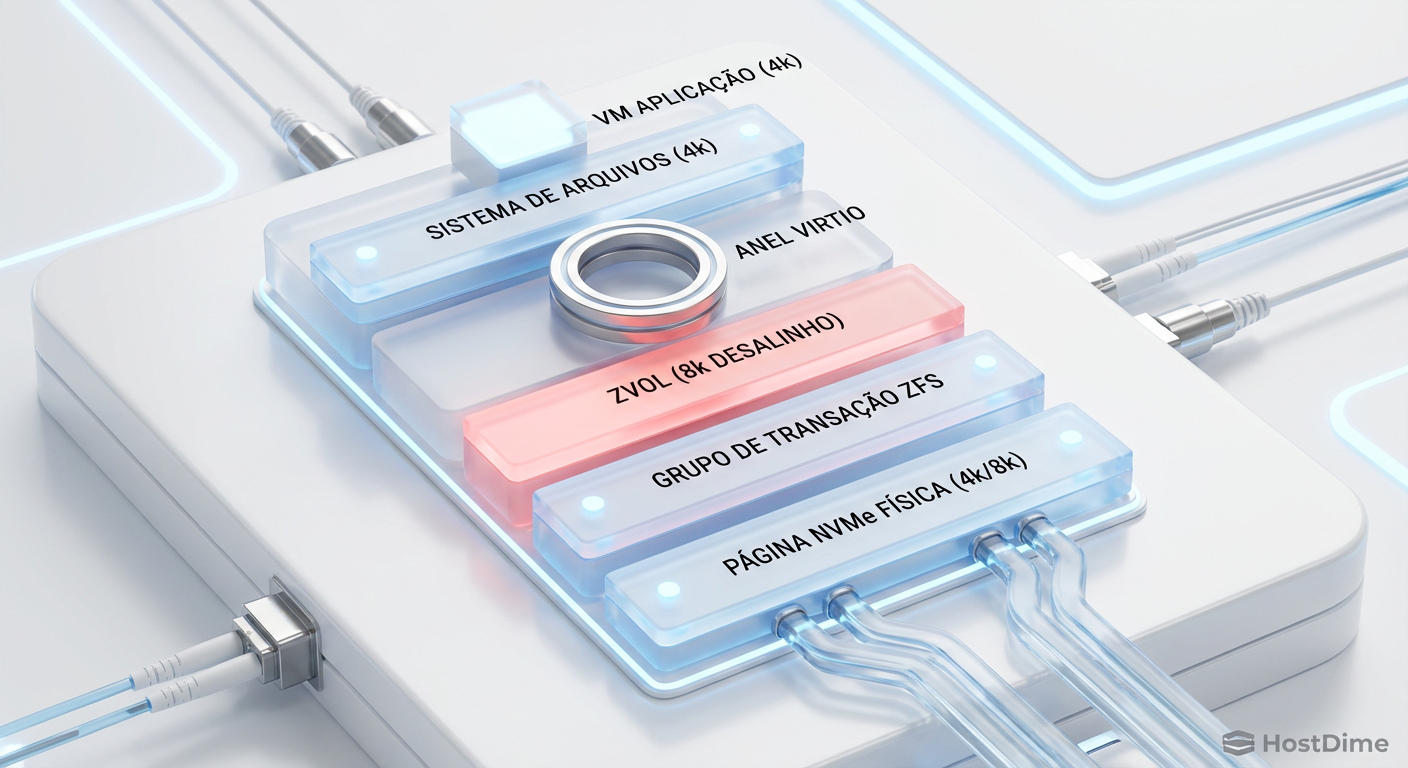 Fig 1. O 'Block Size Mismatch': Onde a performance morre silenciosamente.
Fig 1. O 'Block Size Mismatch': Onde a performance morre silenciosamente.
💡 Dica Pro: Para bancos de dados como PostgreSQL (página de 8k) ou MySQL/InnoDB (página de 16k), ajuste o
volblocksizedo Zvol para casar exatamente com o tamanho da página do banco. Isso elimina a sobrecarga de processamento e alinha a escrita perfeitamente.
A engenharia correta: Alinhando o stack do Guest ao Silício
Para mitigar a amplificação de escrita e latência, precisamos alinhar três camadas:
Ashfit (Hardware): Define o tamanho do setor físico. Para 99% dos SSDs NVMe modernos, use
ashift=12(4k). Se você usarashift=9(512 bytes) em um SSD moderno, a performance de escrita cairá drasticamente devido à amplificação interna do firmware do disco.Volblocksize (ZFS): Deve ser um múltiplo do
ashift.Cluster Size (Guest OS): Deve ser igual ou múltiplo do
volblocksize.
Tabela de alinhamento recomendado
| Carga de Trabalho | Guest FS | Volblocksize (ZFS) | Compressão |
|---|---|---|---|
| Windows Geral | NTFS (4k) | 4k ou 8k | LZ4 (Padrão) |
| Linux Geral | EXT4/XFS (4k) | 4k ou 8k | LZ4 (Padrão) |
| PostgreSQL | EXT4 (4k) | 8k (Page Size) | LZ4 ou ZSTD |
| MySQL/MariaDB | XFS (4k) | 16k (Page Size) | LZ4 ou ZSTD |
| Arquivos Grandes | NTFS/XFS | 128k | ZSTD-3 |
Ao configurar volblocksize=4k para uso geral, você perde um pouco de eficiência na compressão (o metadata overhead aumenta), mas ganha performance bruta em IOPS aleatórios, pois elimina o Read-Modify-Write para a maioria das operações do sistema operacional.
O papel crítico do VirtIO-SCSI Single e IOthread
No mundo VMware, discutimos muito sobre controladores paravirtualizados (PVSCSI). No mundo KVM/Proxmox, o rei é o VirtIO-SCSI. No entanto, a configuração padrão muitas vezes não é a ideal para alta performance.
O KVM possui um "Global Lock" legado que pode limitar o I/O. Para contornar isso, usamos IOthreads. Isso permite que o processamento de armazenamento seja descarregado da vCPU principal da VM e tratado por threads dedicadas no host.
Para que isso funcione efetivamente, você deve selecionar o controlador VirtIO-SCSI Single.
- Por que "Single"? Esta opção cria um controlador SCSI virtual dedicado para cada disco virtual. Isso permite que cada disco tenha sua própria fila de processamento e sua própria IOthread mapeada.
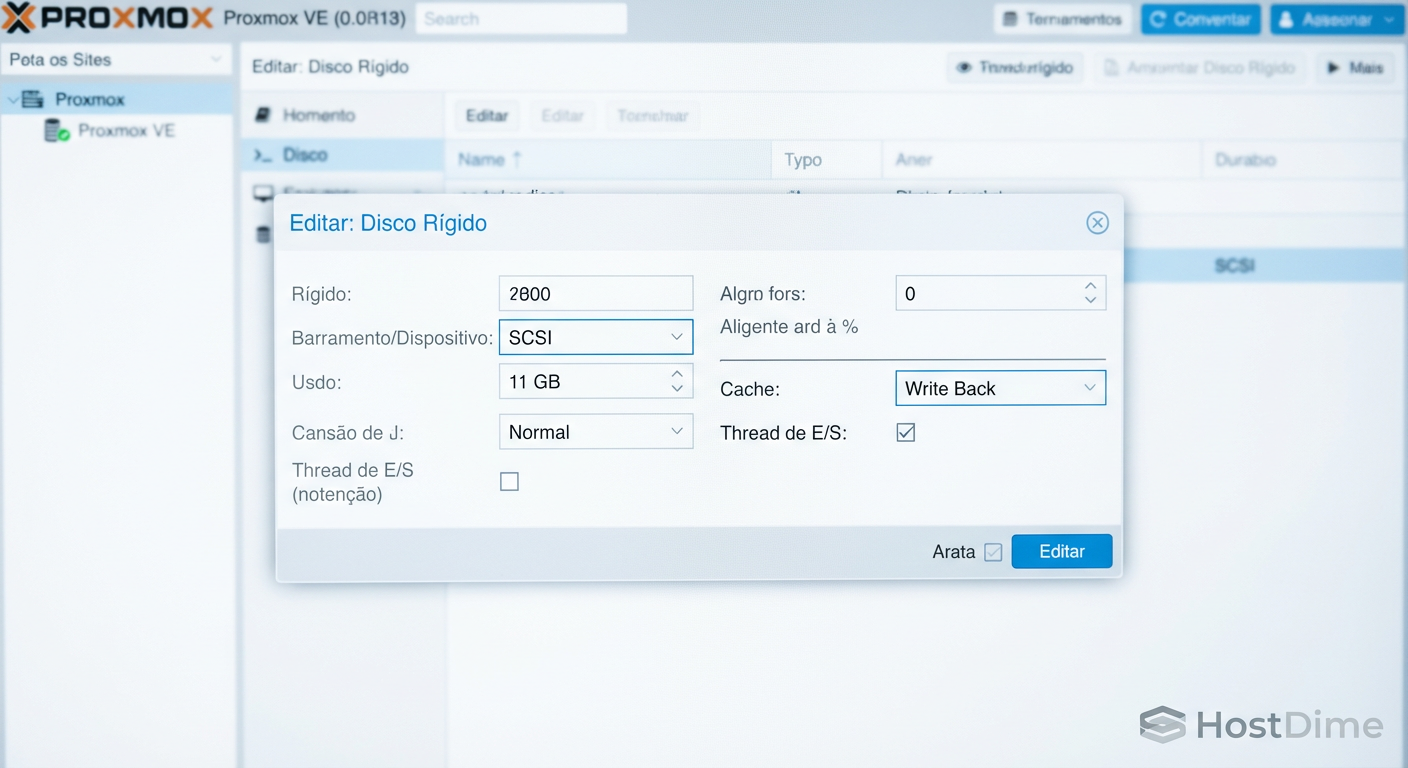 Fig 2. A trindade da performance de virtualização: SCSI, Write Back e IO Thread.
Fig 2. A trindade da performance de virtualização: SCSI, Write Back e IO Thread.
⚠️ Perigo: Se você ativar "IOthread" mas usar o controlador "VirtIO-SCSI" (sem ser o Single) com múltiplos discos, todos eles compartilharão a mesma thread de I/O, criando um gargalo artificial. Sempre use "VirtIO-SCSI Single" se tiver mais de um vDisk.
A armadilha do 'Sync=Disabled' e o mito do ARC infinito
Navegando por fóruns e Reddit, você encontrará a "solução mágica": zfs set sync=disabled.
Ao fazer isso, você diz ao ZFS para mentir para a VM. A VM pergunta "os dados foram gravados no disco de forma segura?", e o ZFS responde "Sim!" instantaneamente, enquanto os dados ainda estão apenas na memória RAM (ARC).
A performance voa. Mas se a energia cair ou o host travar (Kernel Panic), você perde os últimos 5 a 30 segundos de dados. Em um banco de dados, isso significa corrupção total e necessidade de restore de backup.
A solução real: SLOG e Hardware Adequado
Se a latência de escrita síncrona (Sync Write) é ruim, o problema geralmente é o hardware. SSDs de consumo (como Samsung 980/990 Pro ou WD Black) não possuem capacitores de proteção contra perda de energia (PLP). Eles são lentos para fazer o "flush" do cache volátil para a NAND.
Para resolver isso sem arriscar seus dados:
Use SSDs Enterprise (com PLP): Modelos como Micron 7450, Intel/Solidigm D7 ou Samsung PM9A3. Eles "comitam" dados síncronos ordens de magnitude mais rápido.
Dispositivo SLOG Dedicado: Se você tem um pool de HDDs ou SSDs SATA lentos, adicione um par de Optane ou NVMe de alta resistência como dispositivo de Log (ZIL). Isso absorve as escritas síncronas instantaneamente.
Validação: Como medir IOPS sustentado e latência de cauda
Não use dd para testar performance de disco. O dd mede throughput sequencial, o que é irrelevante para 90% das cargas de virtualização. Você precisa medir IOPS aleatórios e, mais importante, a latência de cauda (o pior 1% das suas requisições).
Use o fio (Flexible I/O Tester). Aqui está um exemplo de comando para simular uma carga de banco de dados (70% leitura, 30% escrita, blocos de 8k):
fio --name=random-write --ioengine=libaio --rw=randrw --rwmixread=70 --bs=8k --numjobs=1 --size=4G --iodepth=32 --runtime=60 --time_based --end_fsync=1
Analise a saída focando no clat (completion latency) percentil 99.00 (p99). Se o seu p99 estiver acima de 10ms em um storage All-Flash, você tem um gargalo, provavelmente causado por contenção de bloqueio ou volblocksize incorreto.
 Fig 3. Impacto do ajuste de volblocksize na vida útil (TBW) e latência do SSD.
Fig 3. Impacto do ajuste de volblocksize na vida útil (TBW) e latência do SSD.
Perspectiva futura: Block Cloning e o ZFS 2.2+
Com a chegada do OpenZFS 2.2 (já presente nas versões mais recentes do Proxmox VE 8), temos um recurso transformador: Block Cloning.
Historicamente, clonar uma VM ou fazer um "move" de storage envolvia ler e reescrever dados. Com o Block Cloning, o ZFS pode simplesmente criar ponteiros (reflinks) para os blocos de dados existentes.
A clonagem de VMs torna-se instantânea.
O uso de espaço é drasticamente reduzido.
O desgaste do SSD diminui, pois não há nova escrita física.
Certifique-se de que seu pool esteja atualizado (zpool upgrade) para aproveitar essas funcionalidades que aproximam o ZFS das capacidades nativas de SANs corporativas.
Recomendação Final
Otimizar ZFS para NVMe não é sobre encontrar um comando mágico, mas sim sobre remover barreiras. O hardware moderno é incrivelmente rápido; nosso trabalho é garantir que o software saia da frente.
Antes de colocar seu cluster em produção:
Verifique o alinhamento do
ashiftevolblocksize.Habilite
iothreade useVirtIO-SCSI Singleem todas as VMs.Jamais use SSDs de consumo para armazenar VMs críticas sem entender os riscos de latência de sincronização.
O armazenamento é a fundação da sua infraestrutura virtual. Se a fundação for instável ou lenta, não importa quão rápidas sejam suas CPUs, a experiência final será ruim. Invista tempo no tuning inicial; ele pagará dividendos em estabilidade e performance por anos.
Referências & Leitura Complementar
OpenZFS Documentation - Performance Tuning: Documentação oficial sobre parâmetros de tuning para cargas de trabalho específicas.
Proxmox VE Admin Guide - Storage: Seção oficial sobre integração ZFS e KVM.
RFC 3720 (iSCSI) & VirtIO Spec: Para os curiosos sobre como o protocolo SCSI é encapsulado em ambientes virtualizados.
Perguntas Frequentes (FAQ)
1. O ZFS usa muita memória RAM. Devo limitar o ARC?
Sim e não. O ZFS usa RAM livre para cache de leitura (ARC), o que acelera muito a performance. No entanto, em um hipervisor, a RAM é necessária para as VMs. É uma boa prática definir um zfs_arc_max fixo (ex: 4GB a 8GB + 1GB por TB de dados "quentes") para evitar que o host mate processos por falta de memória (OOM) sob pressão extrema.
2. Devo usar Deduplicação no ZFS para economizar espaço em SSDs?
Na maioria dos casos, não. A deduplicação no ZFS consome quantidades massivas de RAM (tabela de deduplicação) e CPU. Para economizar espaço em SSDs NVMe, prefira usar compressão transparente ZSTD (nível 1 ou 3), que oferece excelente taxa de redução com impacto mínimo ou até positivo na performance.
3. Posso usar SSDs SATA e NVMe no mesmo pool? Tecnicamente sim, mas não é recomendado misturar tipos de mídia no mesmo VDEV. O ZFS será limitado pela velocidade do dispositivo mais lento. Você pode, no entanto, criar pools separados (um "Fast" com NVMe e um "Slow" com SATA) ou usar os SSDs rápidos como Cache/Log para o pool lento.

Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."