Planejamento de Capacidade Ceph: A Matemática Oculta e o Erro dos 85%

Descubra por que clusters Ceph param antes dos 100%, como calcular a capacidade real (Replica vs. EC) e o impacto crítico do dimensionamento de metadados (DB/WAL).
A promessa do armazenamento definido por software (SDS) é sedutora: adicione discos e nós conforme a necessidade, escale ao infinito e esqueça as migrações de dados traumáticas. No entanto, como Arquiteto de Soluções, já vi mais clusters Ceph "travarem" (entrarem em modo read-only) por má gestão de capacidade do que por falhas catastróficas de hardware.
O erro mais comum não é técnico, é aritmético. Existe uma diferença brutal entre o que o departamento de compras adquire (Raw Capacity) e o que a aplicação pode realmente consumir (Usable Capacity). Ignorar a sobrecarga de metadados, a reserva de recuperação e os limites de segurança do algoritmo CRUSH não é apenas otimismo; é negligência arquitetural.
O Ceph não é mágica, é matemática distribuída. E a matemática é implacável.
Definição de Planejamento de Capacidade Ceph O planejamento de capacidade no Ceph é o cálculo da Capacidade Efetiva Segura, que subtrai da capacidade bruta (Raw) o custo da redundância (Réplica ou Erasure Coding), a reserva para falhas de domínio (nós/racks), a sobrecarga do sistema de arquivos BlueStore e as margens de segurança operacional (
full_ratio). O objetivo é evitar o bloqueio de I/O (IO Freeze) durante operações de recuperação (rebalance).
A Ilusão da Capacidade Bruta: Por que 1PB não é 1PB
Quando você compra 1 Petabyte de discos, você não tem 1 Petabyte de armazenamento. O primeiro corte acontece antes mesmo de instalar o software: a conversão de unidades de marketing (TB - base 10) para unidades computacionais (TiB - base 2).
1 PB (1.000 TB) é aproximadamente 909 TiB. Só aqui, 9% da sua capacidade "sumiu" na tradução. Mas isso é irrelevante perto do que o Ceph fará com seus discos. O Ceph opera sobre o conceito de resiliência via redundância. Diferente de um RAID tradicional de hardware, o Ceph distribui o risco através da rede.
A pergunta que define o seu TCO (Total Cost of Ownership) não é "quanto custa o disco?", mas sim "quantos discos eu preciso para gravar 1 TB de dados reais?".
Matemática de Proteção: Custo de Réplica vs. Erasure Coding (EC)
A escolha entre Replicação e Erasure Coding (EC) é o maior "dial" que você pode girar no planejamento de capacidade.
Replicação (O Padrão Seguro e Caro)
O padrão do Ceph é size=3, min_size=2. Isso significa que cada objeto é copiado três vezes em locais diferentes.
Eficiência: 33%.
Custo: Para cada 1 TB de dados, você gasta 3 TB de disco bruto.
Erasure Coding (A Eficiência com Custo de CPU)
O EC fragmenta os dados em pedaços de dados (K) e pedaços de paridade (M). Um perfil 4+2 significa que dividimos o objeto em 4 partes e calculamos 2 paridades.
Eficiência: K / (K+M). No caso de 4+2, é 66%.
Trade-off: Escritas são mais lentas (latência de cálculo de paridade) e operações de recuperação (recovery) são intensivas em CPU. Além disso, EC geralmente não suporta partial writes tão bem quanto réplicas, exigindo o uso de BlueStore deferred writes que consomem WAL (Write Ahead Log).
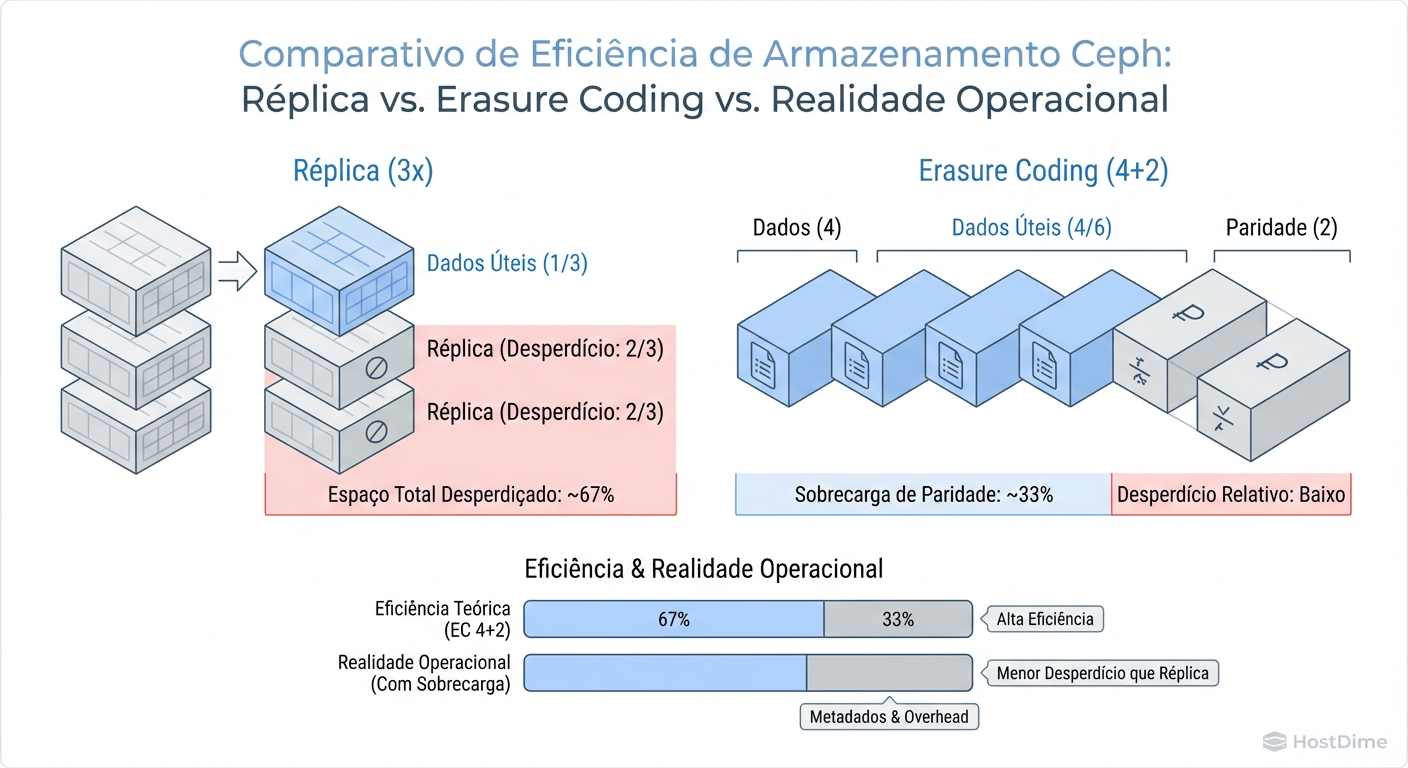 Figura: Comparativo de Eficiência de Armazenamento Ceph: Réplica vs. Erasure Coding vs. Realidade Operacional
Figura: Comparativo de Eficiência de Armazenamento Ceph: Réplica vs. Erasure Coding vs. Realidade Operacional
Tabela Comparativa: Impacto no Planejamento
| Estratégia | Configuração Típica | Eficiência de Armazenamento | Custo Raw para 100TB Úteis | Risco de Recuperação | Caso de Uso Ideal |
|---|---|---|---|---|---|
| Réplica 3x | size=3 |
~33% | 300 TB | Baixo (Cópia direta) | VM Images (RBD), Hot Data, Bancos de Dados |
| Réplica 2x | size=2 |
~50% | 200 TB | Crítico (1 falha = perda de redundância) | Ambientes de Dev/Test (Nunca em Prod) |
| Erasure Coding | 4+2 (K=4, M=2) |
~66% | 150 TB | Médio (Cálculo de paridade) | Object Storage (RGW), Backups, Cold Data |
| Erasure Coding | 8+3 (K=8, M=3) |
~72% | 137 TB | Alto (Latência e CPU altos) | Arquivamento profundo (Deep Archive) |
O "Imposto" de Recuperação: Dimensionando para Falha de Nós
Aqui é onde a maioria dos planejamentos falha. Se você tem um cluster com 10 nós e enche todos eles a 80%, o que acontece se um nó falhar?
O Ceph tentará "curar" o cluster (self-healing). Ele perceberá que as cópias que estavam no nó falho sumiram e começará a recriá-las nos 9 nós restantes para restaurar a redundância (size=3).
O problema: Se os 9 nós restantes não tiverem espaço livre suficiente para absorver os dados do nó morto, o cluster atingirá o full_ratio e travará as escritas.
A Regra do Domínio de Falha
Você deve sempre reservar espaço livre equivalente a um domínio de falha completo.
Se seu domínio de falha é o Host (padrão) e você tem 5 servidores: Você deve manter, no máximo, 80% de uso real. Se perder 1 servidor (20% da capacidade), os dados dele precisam caber nos 4 restantes.
Se você operar a 90% em um cluster de 5 nós e perder um, o rebalanceamento falhará.
Cálculo Rápido:
Capacidade Máxima Segura = (Total Raw * Eficiência) * ((N - 1) / N)Onde N é o número de nós/domínios de falha.
As Barreiras Invisíveis: Entendendo nearfull, backfillfull e full_ratio
O Ceph possui "freios de emergência" para impedir que o sistema de arquivos subjacente fique completamente cheio (o que corromperia o RocksDB e causaria caos). Você precisa respeitar esses limites no seu planejamento.
mon_osd_nearfull_ratio(Padrão: 0.85 ou 85%): Apenas um aviso. O cluster muda para HEALTH_WARN. A operação continua, mas é o sinal para comprar discos ontem.mon_osd_backfillfull_ratio(Padrão: 0.90 ou 90%): Crítico. O Ceph para de permitir que dados sejam movidos para este OSD durante o rebalanceamento. Se muitos discos atingirem isso, a recuperação de falhas para.mon_osd_full_ratio(Padrão: 0.95 ou 95%): Fatal. O cluster entra em modo read-only para evitar corrupção. Todas as aplicações param. Sair desse estado é doloroso e arriscado.
O Erro dos 85%
Muitos administradores veem o full_ratio de 95% e pensam: "Posso usar até 90% tranquilo". Errado.
Devido à distribuição pseudo-aleatória do algoritmo CRUSH, os discos não enchem de forma perfeitamente igual. É comum ter um desvio (variance) de 10-15% entre o disco mais cheio e o mais vazio.
Se a média do seu cluster é 85%, é matematicamente provável que pelo menos um OSD já esteja batendo em 95%, bloqueando escritas naquele grupo de colocação (PG).
Para verificar essa distribuição desigual na prática:
# Verifique a variância (VAR) na coluna de utilização
ceph osd df tree
Se o VAR for maior que 1.1 ou 1.2, seu planejamento de capacidade precisa ser mais conservador até que você rode um reweight-by-utilization.
A Falácia dos Arquivos Pequenos e o Overhead do BlueStore
O BlueStore (backend de armazenamento do Ceph) é muito mais eficiente que o antigo FileStore, mas não é isento de "impostos".
O Gargalo de Metadados (RocksDB + WAL)
O BlueStore armazena dados brutos no disco, mas gerencia metadados (quem é dono do quê, onde está o objeto) no RocksDB. Se você usa HDDs para dados (Data) e SSDs/NVMe para DB/WAL, o dimensionamento do SSD é vital.
Regra de Ouro: Aloque pelo menos 4% da capacidade bruta do HDD para o RocksDB no SSD.
O Risco: Se o SSD encher, o RocksDB "transborda" (spillover) para o HDD lento. A performance cai de um penhasco instantaneamente.
Overhead de Alocação (min_alloc_size)
Em HDDs, o bluestore_min_alloc_size_hdd padrão costumava ser 64KB (em versões recentes como Quincy/Reef mudou para 4KB em alguns perfis, mas verifique).
Se você grava milhões de objetos de 1KB (ex: e-mails, thumbnails) em um sistema com alocação mínima de 64KB, você está desperdiçando 63KB por objeto. Isso é Amplificação de Espaço.
Dica de Arquiteto: Se o seu workload é Small Files, use pools SSD com
min_alloc_sizemenor ou ajuste a configuração. Caso contrário, seu "1PB" pode armazenar apenas 100TB de dados reais.
Estratégia de Monitoramento: O que medir para evitar o 'Read-Only'
Não espere o Nagios/Zabbix gritar quando o disco estiver a 90%. Nesse ponto, o rebalanceamento já está comprometido.
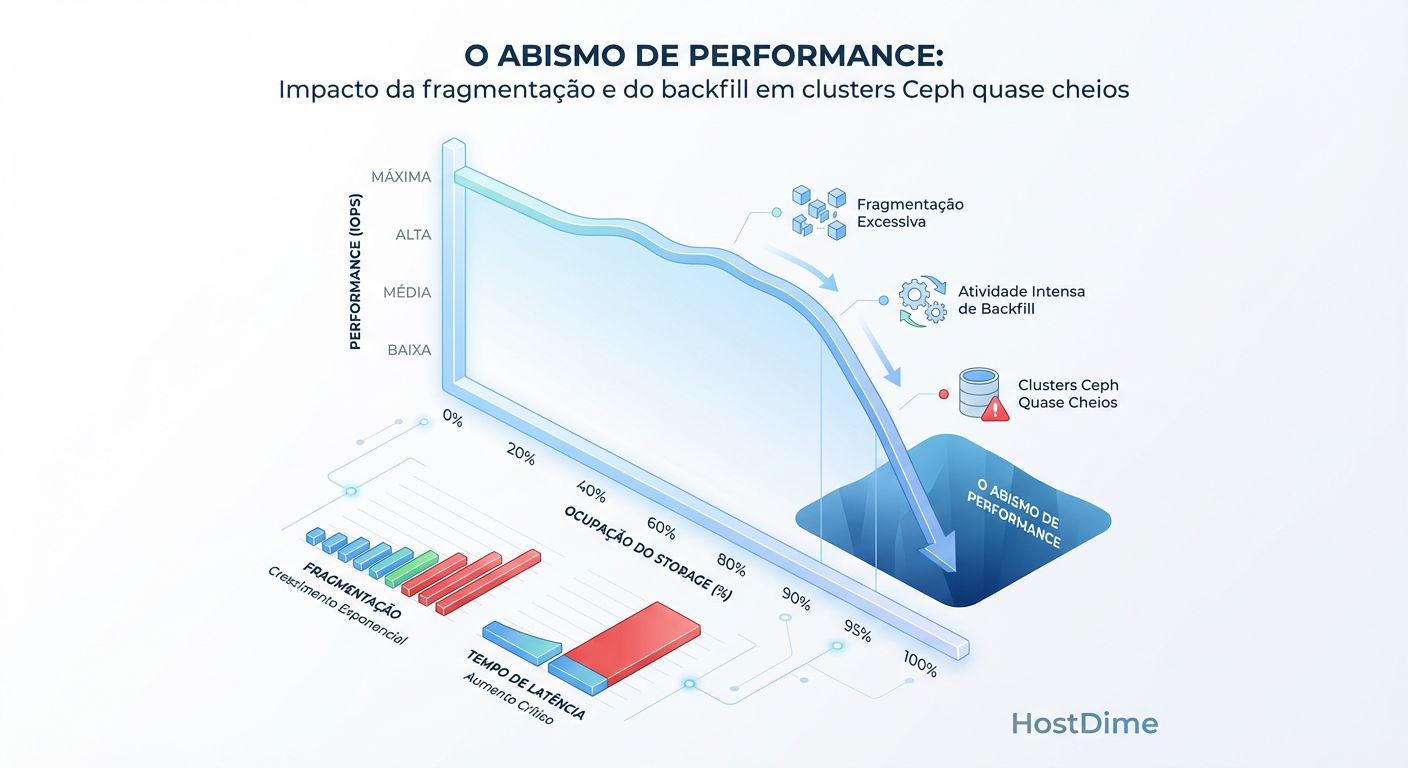 Figura: O Abismo de Performance: Impacto da fragmentação e do backfill em clusters Ceph quase cheios
Figura: O Abismo de Performance: Impacto da fragmentação e do backfill em clusters Ceph quase cheios
O Abismo de Performance
Como mostra a imagem acima, discos cheios são discos lentos. Em HDDs, a fragmentação aumenta drasticamente acima de 80% de ocupação, transformando I/O sequencial em I/O aleatório (seek hell). O planejamento de capacidade também é um planejamento de performance.
Checklist de Monitoramento Ativo
Projeção de Crescimento (Trend Analysis): Não olhe o snapshot atual. Olhe a derivada (taxa de mudança). Se você cresce 1 TB/dia e tem 30 TB livres, você tem 30 dias até o colapso, não "muito espaço".
Desvio Padrão dos OSDs: Monitore a diferença entre o OSD mais cheio e a média do cluster.
Previsão de Backfill: Simule mentalmente: "Se o nó 3 morrer agora, tenho espaço livre = (Capacidade do Nó 3) espalhado pelos outros nós?"
Comandos Essenciais
Para entender o uso real vs. bruto e a distribuição:
# Visão geral de Raw vs. Stored (dados do cliente)
ceph df
# Identificar OSDs perigosamente cheios (Outliers)
ceph osd df | sort -nk 7 | tail -n 10
Se você encontrar OSDs próximos ao nearfull_ratio, a ação corretiva imediata é rebalancear, não apenas comprar disco:
# Apenas se souber o que está fazendo: forçar rebalanceamento por peso
ceph osd reweight-by-utilization
Veredito Técnico: O Custo do "Depende"
Planejar a capacidade do Ceph não é sobre preencher planilhas com a soma dos TBs dos HDDs. É sobre garantir que, no pior dia possível (falha de nó durante alta carga), o sistema tenha oxigênio (espaço livre) para respirar e se curar.
O "erro dos 85%" é acreditar que você pagou por 100% do disco. Você não pagou. Você pagou pela infraestrutura de autocura. Os últimos 15-20% do disco são o preço da sua tranquilidade. Se tentar usá-los, você pagará com disponibilidade.
Referências & Leitura Complementar
Ceph Documentation - Hardware Recommendations: Dimensionamento de CPU/RAM para OSDs e Monitores.
RocksDB Tuning Guide for Ceph: Detalhes sobre compactação e níveis do RocksDB no BlueStore.
Ceph Docs - CRUSH Maps: Entendendo como os Failure Domains afetam a distribuição de dados.
Red Hat Ceph Storage - Capacity Planning Guide: Metodologias oficiais para cálculo de overhead em ambientes Enterprise.

Magnus Vance
Engenheiro do Caos
"Quebro sistemas propositalmente porque a falha é inevitável. Transformo desastres simulados em vacinas para sua infraestrutura. Se não sobrevive ao meu caos, não merece estar em produção."