Planejamento de capacidade em 2026: a transição para modelos baseados em restrições

Em 2026, planilhas lineares falham. Descubra como usar a Lei Universal da Escalabilidade (USL) e o padrão EDSFF para superar restrições de energia e espaço em storage.
A era da abundância de recursos baseada em suposições lineares acabou. Em 2026, o planejamento de capacidade de armazenamento deixou de ser um exercício de planilha de compras para se tornar um problema de física aplicada e teoria das filas. Durante a última década, a indústria operou sob a ilusão da escalabilidade infinita: se o desempenho do array de armazenamento caísse, bastava adicionar mais spindles (discos) ou mais nós ao cluster Ceph. Hoje, essa abordagem não apenas falha, como frequentemente resulta em escalabilidade retrógrada — o ponto onde adicionar hardware torna o sistema mais lento.
Resumo em 30 segundos
- Fim da Linearidade: Modelos de previsão baseados em regressão linear são inúteis para cargas de trabalho modernas; a Lei Universal da Escalabilidade (USL) é o único modelo preditivo seguro.
- Restrição Térmica: O formato físico dos drives (EDSFF) agora dita a capacidade máxima do rack antes mesmo do orçamento, devido às exigências de resfriamento do PCIe 6.0.
- Custo da Coerência: Em sistemas distribuídos e all-flash, o custo de manter a consistência dos dados ($\beta$) cresce quadraticamente, criando um teto rígido de IOPS que mais hardware não resolve.
O fim da elasticidade infinita: quando a física vence o orçamento
O conceito de "nuvem elástica" nos treinou mal. Criou-se a expectativa de que a latência de armazenamento permaneceria constante independentemente da carga, desde que o cartão de crédito tivesse limite. A realidade física de 2026 impõe barreiras rígidas. Não estamos mais limitados apenas pelo espaço em disco (TB), mas pela densidade de energia (Watts/TB) e pela capacidade de dissipação térmica dos controladores NVMe.
No contexto de datacenters e até home labs avançados, atingimos o que chamo de "ponto de inflexão da densidade". Discos rígidos de 30TB+ e SSDs de 60TB concentram uma quantidade massiva de dados em um espaço físico ínfimo. O risco de blast radius (impacto de falha) aumentou, mas o gargalo real é a largura de banda por terabyte.
Se você preenche um chassi 2U com 24 SSDs NVMe Gen5, você não está limitado pela capacidade de armazenamento. Você está limitado pela capacidade do barramento PCIe e, crucialmente, pela capacidade da CPU de processar interrupções e trocas de contexto. O planejamento de capacidade moderno exige identificar onde a curva de rendimento achata antes de gastar o orçamento.
 Fig. 3: Mapa de calor identificando 'capacidade encalhada' onde a energia acaba antes do espaço em disco.
Fig. 3: Mapa de calor identificando 'capacidade encalhada' onde a energia acaba antes do espaço em disco.
⚠️ Perigo: Ignorar a "capacidade encalhada" (stranded capacity) é o erro número um. Isso ocorre quando você tem terabytes livres no array, mas não tem IOPS ou energia térmica restante para acessá-los sem violar o SLA de latência.
A falácia da extrapolação linear em workloads de IA generativa
A maior armadilha para o planejador de capacidade em 2026 é o uso de regressão linear simples para prever necessidades de armazenamento em ambientes de IA. Cargas de trabalho de inferência e treinamento, especialmente aquelas envolvendo RAG (Retrieval-Augmented Generation) e checkpointing de modelos, não crescem linearmente.
Em um cenário clássico de banco de dados transacional, se 100 usuários geram 1000 IOPS, assumimos que 200 usuários gerarão 2000 IOPS. Em storage para IA, o padrão de acesso é caracterizado por rajadas massivas e simultâneas de gravação (durante checkpoints) ou leituras aleatórias intensas (durante o carregamento de vetores).
Quando tentamos escalar sistemas de arquivos paralelos (como Lustre, GPFS ou implementações modernas de ZFS em escala) para atender a essa demanda, a extrapolação linear falha porque ignora a contenda. A fila de espera no controlador de armazenamento não cresce de forma aritmética; ela cresce exponencialmente conforme a utilização se aproxima de 100%, de acordo com a Lei de Little e a fórmula de utilização de filas $U / (1 - U)$.
Modelando a penalidade de coerência com a Lei Universal da Escalabilidade
Para evitar o desastre financeiro de comprar hardware que não entrega performance, devemos abandonar a intuição e adotar a Lei Universal da Escalabilidade (USL). A USL define a capacidade relativa $C(N)$ em função da carga $N$ (usuários ou processos concorrentes) com dois parâmetros de degradação:
Contenda ($\alpha$): A parte serializável do trabalho. Em storage, isso é o tempo esperando por um lock de metadados ou a fila de um único disco.
Coerência ($\beta$): O custo de manter os dados consistentes entre múltiplos nós ou discos.
A fórmula $C(N) = \frac{N}{1 + \alpha(N-1) + \beta N(N-1)}$ nos mostra uma verdade desconfortável. Enquanto a contenda ($\alpha$) impede o crescimento linear, a coerência ($\beta$) causa escalabilidade retrógrada.
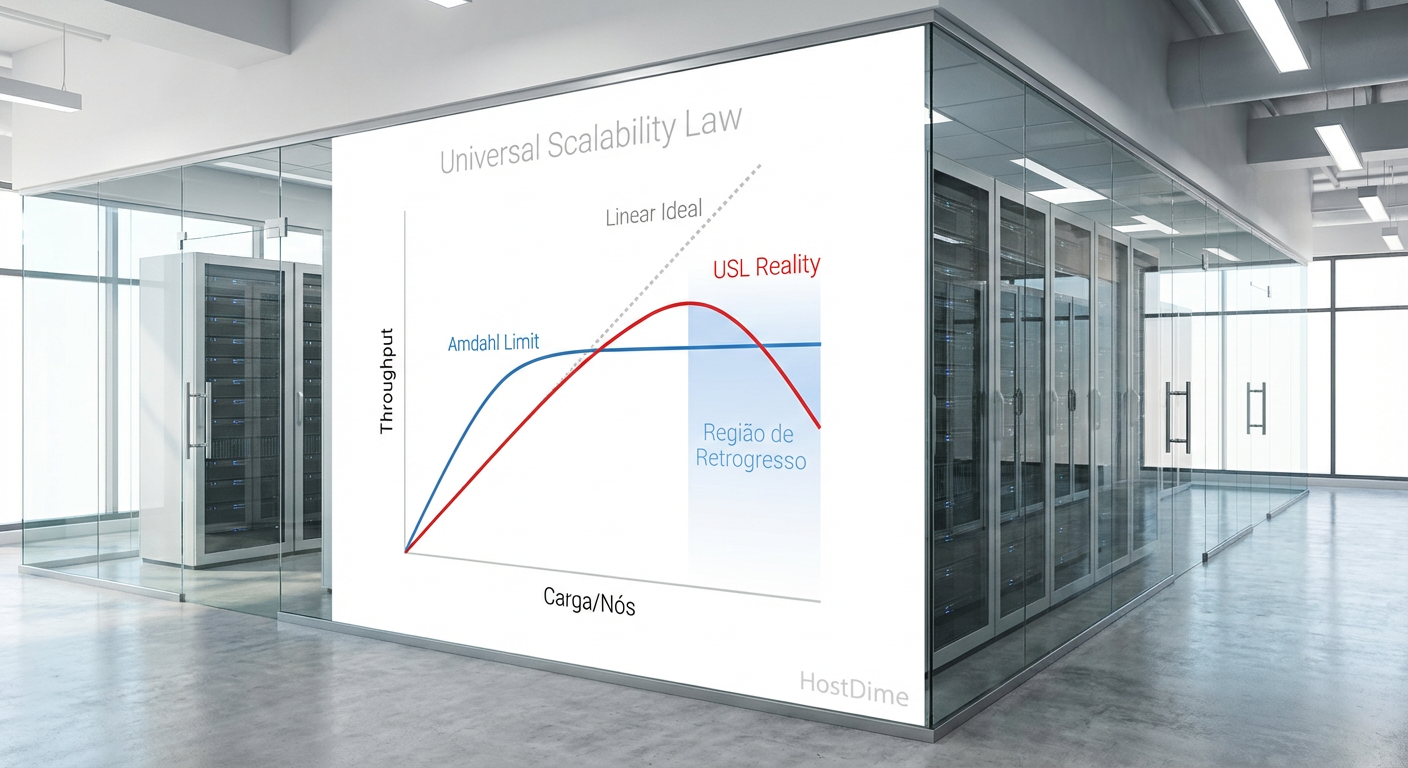 Fig. 1: A Lei Universal da Escalabilidade (USL) demonstra onde a adição de hardware degrada a performance devido à coerência.
Fig. 1: A Lei Universal da Escalabilidade (USL) demonstra onde a adição de hardware degrada a performance devido à coerência.
Em sistemas de armazenamento distribuído (como vSAN, Ceph ou TrueNAS Scale em cluster), à medida que adicionamos nós para ganhar capacidade, aumentamos o tráfego de "fofoca" (gossip) entre os nós para manter a coerência dos dados. Chega-se a um ponto matemático onde adicionar mais um nó de armazenamento reduz o IOPS total do cluster.
💡 Dica Pro: Ao planejar um cluster de armazenamento, meça a latência de commit síncrono. Se a latência dobrar ao aumentar os nós em 50%, seu $\beta$ (penalidade de coerência) é alto. Pare de escalar horizontalmente e comece a escalar verticalmente (nós mais densos) ou fragmente o cluster.
Adoção do padrão EDSFF para mitigar o teto térmico e de densidade
A física térmica tornou-se um componente inseparável do planejamento de capacidade. Os formatos legados, como M.2 e o tradicional 2.5 polegadas (U.2), atingiram seus limites práticos com a chegada do PCIe 5.0 e 6.0. A densidade de sinal e o calor gerado pelos controladores NVMe de alta performance exigem um novo paradigma.
É aqui que o EDSFF (Enterprise & Data Center SSD Form Factor) se torna obrigatório para qualquer planejamento de longo prazo em 2026. Especificamente, os formatos E1.S (para densidade de 1U) e E3.S (para substituição de 2.5" em 2U) foram desenhados com a termodinâmica como prioridade, não como um pensamento secundário.
O formato E3.S, por exemplo, permite dissipadores de calor maiores e fluxo de ar mais eficiente. Para o planejador de capacidade, isso significa que podemos colocar mais petabytes em um rack sem que os drives entrem em thermal throttling (redução de velocidade por temperatura).
 Fig. 2: A evolução física: o formato E3.S permite maior densidade térmica necessária para PCIe 6.0.
Fig. 2: A evolução física: o formato E3.S permite maior densidade térmica necessária para PCIe 6.0.
A transição para EDSFF não é apenas estética; é uma questão de viabilidade operacional. Tentar manter formatos antigos em densidades modernas resulta em ventiladores operando a 100% do ciclo (desperdiçando energia) e falhas prematuras de componentes. O planejamento de capacidade agora deve incluir a métrica de "CFM por TB" (Pés cúbicos de ar por minuto por Terabyte).
O novo ROI: latência determinística como vantagem competitiva
Historicamente, o Retorno sobre Investimento (ROI) em armazenamento era calculado em "Custo por GB". Em 2026, essa métrica é secundária para cargas de trabalho de alta performance. O novo ROI é a latência determinística.
A variação da latência (jitter) é o inimigo da performance percebida. Um array all-flash que entrega 1 milhão de IOPS com latência média de 200µs, mas com picos de 50ms (latência de cauda) no percentil 99.9 (p99.9), é inferior a um sistema que entrega 500k IOPS com latência estável de 300µs.
A latência de cauda destrói a performance de aplicações distribuídas. Se uma requisição precisa consultar 50 microserviços, e cada um faz uma leitura no disco, a latência total será ditada pela leitura mais lenta.
O planejamento de capacidade deve focar em garantir que o sistema opere na "zona de conforto" da curva de latência, bem antes do "joelho" da curva exponencial. Isso significa, paradoxalmente, provisionar capacidade extra não para armazenar dados, mas para diluir a profundidade da fila (Queue Depth) por dispositivo.
💡 Dica Pro: Em SSDs NVMe modernos, o isolamento de namespaces e o uso de QoS (Qualidade de Serviço) via hardware são vitais. Configure limites rígidos. É melhor rejeitar uma gravação (backpressure) do que aceitá-la e causar latência alta para todas as outras operações.
Previsão Matemática
A tendência para o final da década é clara: a complexidade se moverá do software para o planejamento físico e topológico. Organizações que continuarem a tratar armazenamento como uma commodity elástica infinita colidirão violentamente com o muro da coerência ($\beta > 0$). A previsão matemática indica que os vencedores não serão aqueles com mais petabytes, mas aqueles que conseguirem modelar suas restrições físicas e lógicas para manter a latência determinística sob carga máxima. O planejador de capacidade de 2026 não é um comprador de discos; é um arquiteto de restrições.
Perguntas Frequentes
1. A Lei Universal da Escalabilidade (USL) se aplica a um Home Lab com TrueNAS? Sim. Mesmo em pequena escala, a coerência afeta o desempenho. Por exemplo, adicionar mais vDevs em um pool ZFS aumenta a complexidade de alocação e metadados. Se você usa deduplicação, o custo de coerência (verificar a tabela de hash na RAM/disco) pode fazer com que adicionar um SSD torne a gravação mais lenta do que antes.
2. Devo migrar tudo para EDSFF (E1.S/E3.S) imediatamente? Não imediatamente, mas pare de comprar infraestrutura nova baseada em M.2 ou U.2 para core storage. Se você está planejando um ciclo de renovação de hardware para os próximos 3 a 5 anos, o EDSFF é a única escolha lógica para garantir compatibilidade com as demandas térmicas do PCIe 6.0 e densidades futuras.
3. Como calculo a "capacidade encalhada" no meu ambiente? Analise seus relatórios de monitoramento. Identifique volumes que estão cheios (espaço), mas com baixa utilização de IOPS/Throughput. Em seguida, identifique volumes com baixo uso de espaço, mas que saturam a latência ou o controlador. A capacidade encalhada é a diferença entre o recurso limitante (ex: energia ou IOPS) e o recurso abundante (ex: TBs) que não pode ser usado sem violar as restrições do sistema.

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."