QLC vs HDD: O Ponto de Inflexão no Planejamento de Capacidade

Análise matemática do TCO entre QLC NAND e HDDs Nearline. Descubra como a densidade de 61TB+ e a eficiência energética estão redefinindo o armazenamento enterprise em 2025.
A Lei de Moore para o armazenamento magnético encontrou uma barreira física formidável, enquanto a demanda por capacidade segue uma curva exponencial implacável. Como planejadores de capacidade, não podemos mais confiar na extrapolação linear histórica da densidade de área dos HDDs para sustentar os requisitos de dataspheres modernos. Estamos observando um desvio fundamental entre a capacidade mecânica de entregar dados e a necessidade computacional de consumi-los.
A transição do HDD para o SSD QLC (Quad-Level Cell) não é apenas uma atualização de mídia; é uma mudança na topologia de desempenho e na equação de custo total de propriedade (TCO). Onde antes modelávamos o custo por gigabyte como a métrica primária, hoje devemos resolver um sistema de equações que inclui IOPS por Terabyte, Watts por Terabyte e a latência de cauda (tail latency) em percentis elevados.
Resumo em 30 segundos
- A Muralha dos IOPS/TB: À medida que os HDDs aumentam de capacidade (20TB+), o desempenho por TB cai drasticamente, criando um gargalo de acesso em data lakes massivos.
- Densidade Energética: O QLC atingiu um ponto de inflexão onde a economia em refrigeração e espaço de rack (OpEx) supera o custo inicial mais alto da mídia (CapEx) em escalas de Petabyte.
- O Papel da IA: Modelos de treinamento de Inteligência Artificial exigem larguras de banda de leitura que arranjos mecânicos não conseguem fornecer sem um paralelismo proibitivo.
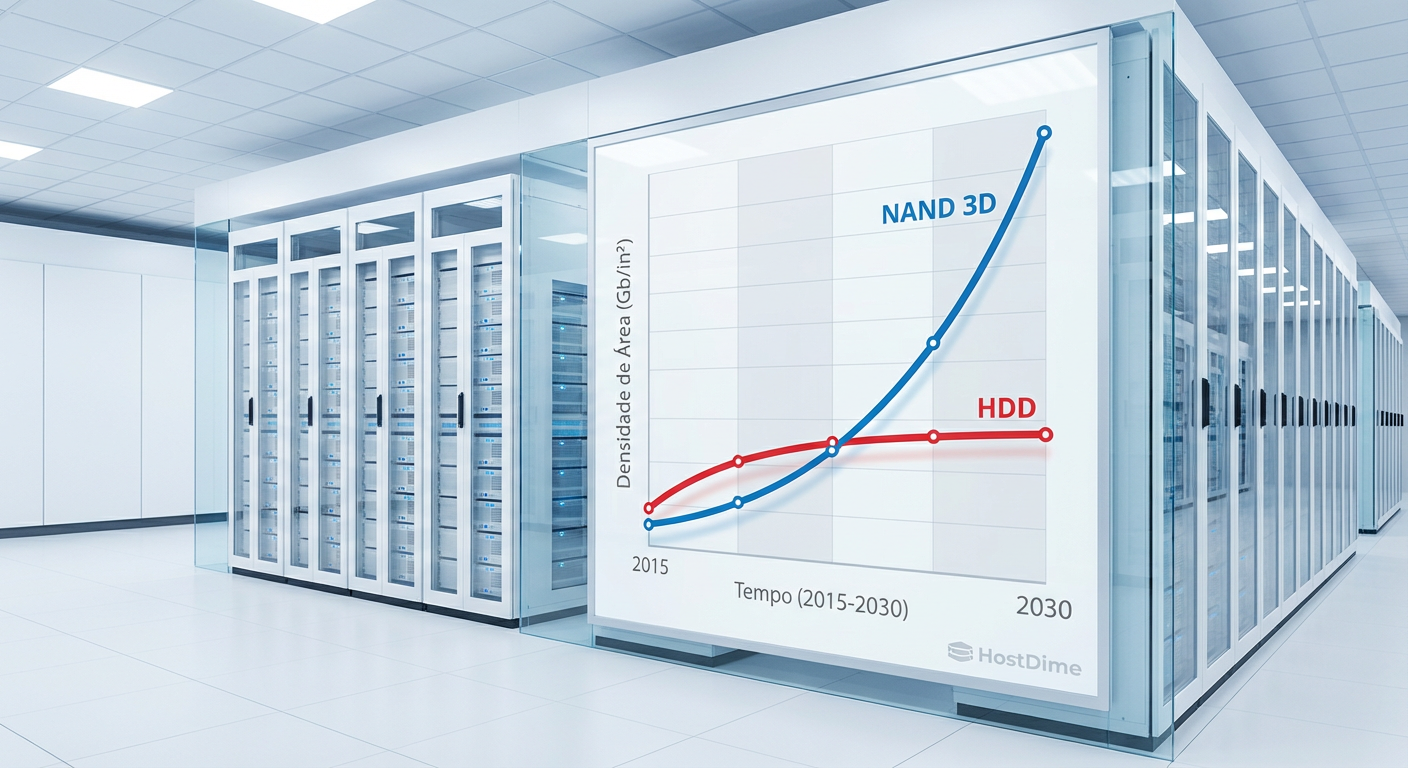 Figura: Divergência de Densidade: Enquanto a tecnologia magnética luta contra o limite superparamagnético, a NAND escala verticalmente.
Figura: Divergência de Densidade: Enquanto a tecnologia magnética luta contra o limite superparamagnético, a NAND escala verticalmente.
A Assimetria entre Dados Não Estruturados e Densidade Magnética
O problema fundamental do HDD moderno é geométrico. A tecnologia de Gravação Magnética Assistida por Calor (HAMR) e a Gravação Magnética Assistida por Micro-ondas (MAMR) permitiram que os fabricantes espremessem mais bits no mesmo prato de 3,5 polegadas. No entanto, a velocidade do atuador mecânico permaneceu estagnada.
Quando dobramos a capacidade de um disco de 10TB para 20TB, mas mantemos o mesmo desempenho de busca (seek time) de ~8ms e a mesma taxa de transferência sequencial de ~250MB/s, efetivamente cortamos o desempenho por TB pela metade. Em um cenário de Object Storage massivo, isso resulta em dados "presos": eles estão armazenados, mas a largura de banda para recuperá-los em tempo hábil não existe sem a adição de mais spindles (eixos) do que a capacidade requer.
O QLC, ao armazenar 4 bits por célula, oferece uma densidade que permite drives de 30TB, 60TB ou até 100TB no formato E1.S ou U.2, sem a penalidade mecânica. A escalabilidade da NAND 3D (atualmente ultrapassando 200 camadas) permite que a curva de oferta de capacidade acompanhe a demanda de ingestão de dados, algo que a física magnética não consegue mais garantir sem custos proibitivos de engenharia.
O Impacto da Amplificação de Escrita no Ciclo de Vida
A resistência à adoção do QLC em ambientes corporativos historicamente girou em torno da durabilidade (Endurance). Escrever em uma célula QLC requer uma precisão de voltagem extrema para distinguir entre 16 estados de carga diferentes. Isso degrada o óxido do túnel da célula mais rapidamente do que em SLC ou MLC.
No entanto, o planejador de capacidade deve modelar a Amplificação de Escrita (Write Amplification - WA) com base na carga de trabalho real, não na teórica.
A fórmula básica para o desgaste é governada pela relação entre os dados solicitados pelo host e os dados realmente escritos na flash:
$$WA = \frac{\text{Dados Escritos na Flash}}{\text{Dados Escritos pelo Host}}$$
Em cargas de trabalho de Big Data, Analytics e AI Training, o padrão de acesso é predominantemente "Write Once, Read Many" (WORM). Nesses cenários, o fator de WA é baixo e previsível. O medo do "burnout" das células QLC é frequentemente infundado para cargas de trabalho que não sejam bancos de dados transacionais pesados (OLTP).
⚠️ Perigo: Evite QLC para logs de alta frequência ou caches de escrita intensiva sem uma camada de absorção. Se o workload for randômico e pequeno (4K writes), a Amplificação de Escrita aumentará drasticamente, consumindo os ciclos P/E (Program/Erase) prematuramente devido à necessidade de reescrever blocos inteiros para modificar pequenas páginas.
Cálculo de Densidade Energética: Watts por Terabyte
Ao projetar um datacenter ou um home lab de alta densidade, a restrição final raramente é o dinheiro, mas sim a energia e a dissipação térmica. É aqui que a modelagem matemática favorece o QLC de forma agressiva.
Considere um cluster de armazenamento de 1 Petabyte (PB):
Cenário HDD: Utilizando discos de 20TB, seriam necessários 50 drives. Considerando um consumo médio de operação de 7W por disco (mais a sobrecarga de vibração e resfriamento dos chassis densos), temos um consumo base elevado apenas para manter os pratos girando.
Cenário QLC: Utilizando SSDs de 30.72TB, seriam necessários aproximadamente 33 drives. O consumo em idle de um SSD é uma fração do HDD, e o consumo de pico é breve.
A métrica crítica é Watts/TB. Em sistemas de alta densidade, HDDs lutam para baixar de 0.3 W/TB em operação. Arrays All-Flash QLC de alta densidade podem atingir eficiências significativamente melhores, especialmente quando consideramos que a remoção de calor (BTU/h) é linearmente proporcional ao consumo em Watts.
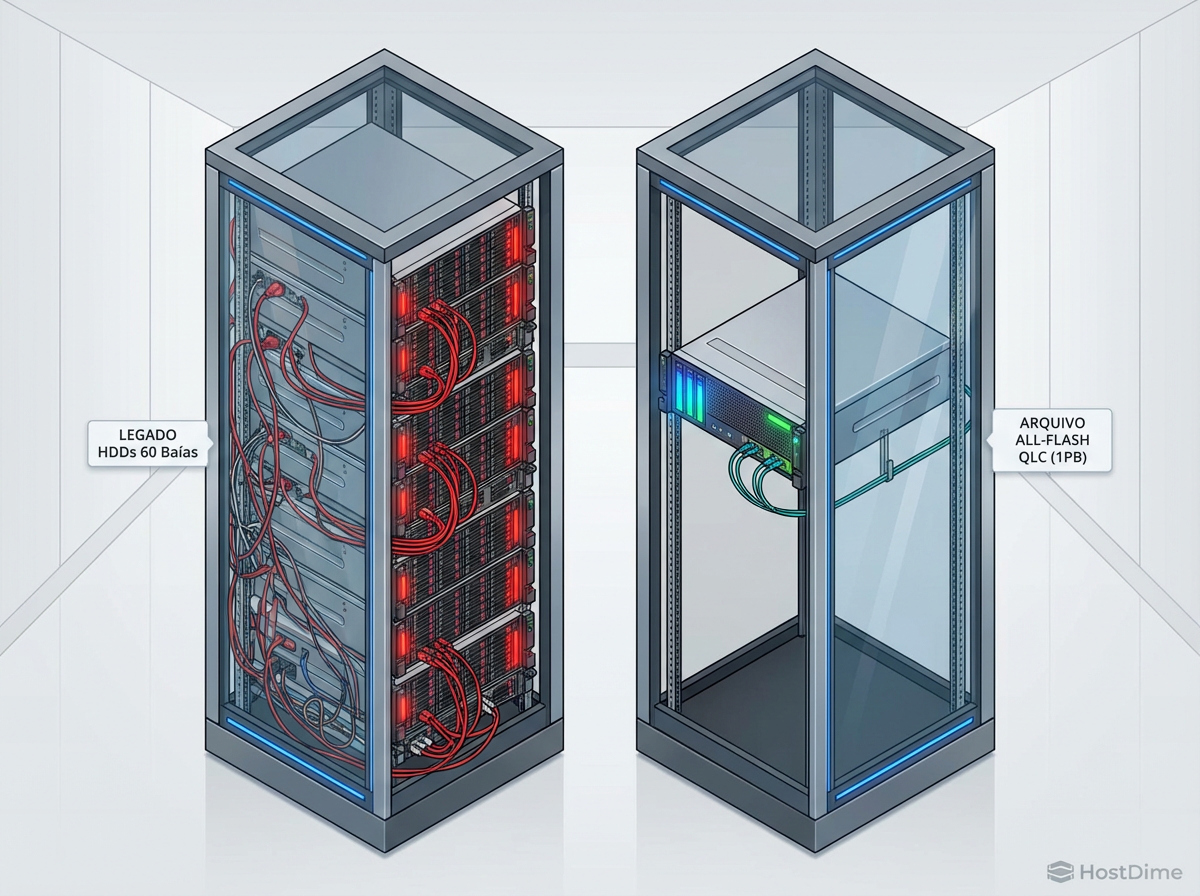 Figura: Eficiência Volumétrica: A consolidação de 1PB de dados magnéticos vs. 1PB de dados em flash QLC altera drasticamente a pegada térmica e espacial.
Figura: Eficiência Volumétrica: A consolidação de 1PB de dados magnéticos vs. 1PB de dados em flash QLC altera drasticamente a pegada térmica e espacial.
Além disso, a densidade física (TB/Rack Unit) do QLC permite adiar a construção de novos datacenters. Se você pode triplicar a capacidade no mesmo footprint de energia e espaço, o custo evitado de nova infraestrutura física deve ser creditado ao TCO do armazenamento flash.
Arquitetura de Tiering para Contornar a Latência de Programação
A física do QLC impõe uma penalidade severa na escrita: a latência de programação (tPROG). Ajustar a voltagem para um dos 16 níveis exatos leva tempo. Se expusermos essa latência diretamente à aplicação, o sistema sofrerá engasgos (stalls).
Para mitigar isso, a arquitetura de armazenamento deve empregar estratégias de tiering ou caching interno. O planejador deve verificar a existência de zonas pSLC (pseudo-SLC).
Nesta configuração, uma porção da NAND QLC é tratada como SLC (1 bit por célula). As escritas atingem essa zona em velocidade máxima. Em momentos de ociosidade, o controlador do SSD move os dados da zona pSLC para a zona QLC principal (processo conhecido como folding).
💡 Dica Pro: Ao dimensionar arrays QLC (seja em TrueNAS com ZFS ou SANs Enterprise), garanta que a camada de absorção de escrita (SLOG ou Write Cache) seja dimensionada para suportar o "burst" máximo de ingestão diária. Se o buffer encher, a performance cairá para a velocidade nativa do QLC, que pode ser inferior à de um HDD mecânico (o temido "write cliff").
A Latência de Leitura como Gargalo Oculto na IA
A modelagem de capacidade para Inteligência Artificial introduziu uma nova variável: a fome de dados da GPU. GPUs modernas (como as séries H100 ou as futuras gerações) possuem memórias HBM incrivelmente rápidas, mas pequenas comparadas aos datasets de treinamento.
O ciclo de treinamento envolve leitura constante de batches de dados do armazenamento. Se o armazenamento for baseado em HDD, a latência rotacional e o tempo de busca introduzem "bolhas" no pipeline da GPU. A GPU fica ociosa esperando o disco girar até o setor correto.
O QLC brilha aqui não apenas pelo throughput (GB/s), mas pela latência determinística. Mesmo sob carga pesada, um SSD QLC entrega dados com latência na casa dos microssegundos, enquanto um HDD pode variar de 5ms a 20ms dependendo da fragmentação e da posição do braço.
Para inferência e treinamento, a capacidade de leitura paralela do NVMe QLC satura o barramento PCIe, garantindo que o gargalo permaneça na computação (onde deve estar), e não no I/O.
 Figura: O Custo da Ociosidade: A latência mecânica dos HDDs cria tempos de espera inaceitáveis para GPUs de alto desempenho.
Figura: O Custo da Ociosidade: A latência mecânica dos HDDs cria tempos de espera inaceitáveis para GPUs de alto desempenho.
O Ponto de Inflexão
Estamos observando o cruzamento das curvas. O custo por TB do HDD ainda é nominalmente menor, mas a diferença está se estreitando rapidamente. Quando aplicamos a "física do datacenter" — considerando o custo da energia, o custo do slot de rack, a refrigeração e, crucialmente, o valor do tempo de CPU/GPU desperdiçado esperando por I/O — o HDD torna-se a opção mais cara para qualquer dado que precise ser lido mais de uma vez por mês.
Minha previsão baseada nos modelos atuais de densidade de NAND é que o HDD de 3,5 polegadas será relegado exclusivamente a funções de Cold Archive e Deep Glacier até o final desta década. Para qualquer carga de trabalho ativa, warm ou hot, o planejamento de capacidade deve assumir o QLC como o novo padrão de linha de base. Continuar investindo em arrays puramente mecânicos para cargas de trabalho gerais é planejar a obsolescência da sua própria infraestrutura.

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."