Quando Ceph Falha: Latência, Escala Mínima e o Custo da Complexidade
Ceph não é para todos. Entenda os trade-offs de latência, os perigos de clusters pequenos e quando ZFS ou SAN tradicional são opções tecnicamente superiores.
O Ceph é, indiscutivelmente, o "canivete suíço" do armazenamento definido por software (SDS). Ele escala para exabytes, fala múltiplos protocolos (Objeto, Bloco, Arquivo) e roda em hardware commodity. No papel, é a arquitetura dos sonhos para qualquer CTO.
No entanto, como Arquiteto de Soluções, já vi mais projetos de Ceph falharem não por bugs no código, mas por erros de design arquitetural. Há uma dissonância cognitiva comum: tratar o Ceph como um substituto mágico 1:1 para uma SAN tradicional ou um array All-Flash, ignorando a física de como ele distribui dados.
O Ceph não é gratuito; ele cobra um imposto. Esse imposto é pago em latência e complexidade operacional. Se o seu use case não pode pagar essa taxa, o projeto vai falhar. Vamos desmontar o hype e olhar para a engenharia.
O que faz o Ceph falhar em produção?
Resumo Executivo: O Ceph falha quando aplicado a cargas de trabalho sensíveis à latência (como bancos de dados transacionais) sem o hardware ou a escala massiva necessária para diluir o custo da replicação. A falha mais comum ocorre em "micro-clusters" (3 a 5 nós), onde a sobrecarga do algoritmo de distribuição (CRUSH) e a latência de rede superam os benefícios da resiliência, resultando em um TCO (Custo Total de Propriedade) superior ao de storage tradicional ou local.
A Anatomia da Latência no Ceph e o Custo do CRUSH
Para entender por que o Ceph pode parecer "lento" comparado a um disco local ou um array NVMe dedicado, precisamos dissecar o caminho de uma operação de escrita (Write I/O).
Em um sistema de arquivos local (como ZFS ou EXT4), a CPU fala com o controlador de disco via barramento PCIe. É uma conversa quase íntima. No Ceph, essa conversa vira uma conferência barulhenta em uma sala lotada.
O Ceph não usa tabelas de alocação centralizadas (o que é genial para escala infinita). Ele usa o algoritmo CRUSH (Controlled Replication Under Scalable Hashing). O cliente calcula onde o dado deve ir. Mas aqui está o "imposto" da latência:
Cálculo: O cliente calcula o placement group (PG).
Rede Pública: O dado viaja pela rede até o OSD Primário.
Replicação Síncrona: O OSD Primário calcula quem são os OSDs Secundários e envia o dado para eles (geralmente via uma rede de cluster separada).
Commit no Journal/WAL: Todos os OSDs (Primário e Secundários) devem escrever o dado em seus journals (BlueStore WAL) e confirmar a gravação.
Ack Final: Somente após todos os OSDs confirmarem, o OSD Primário envia o
ACKao cliente.
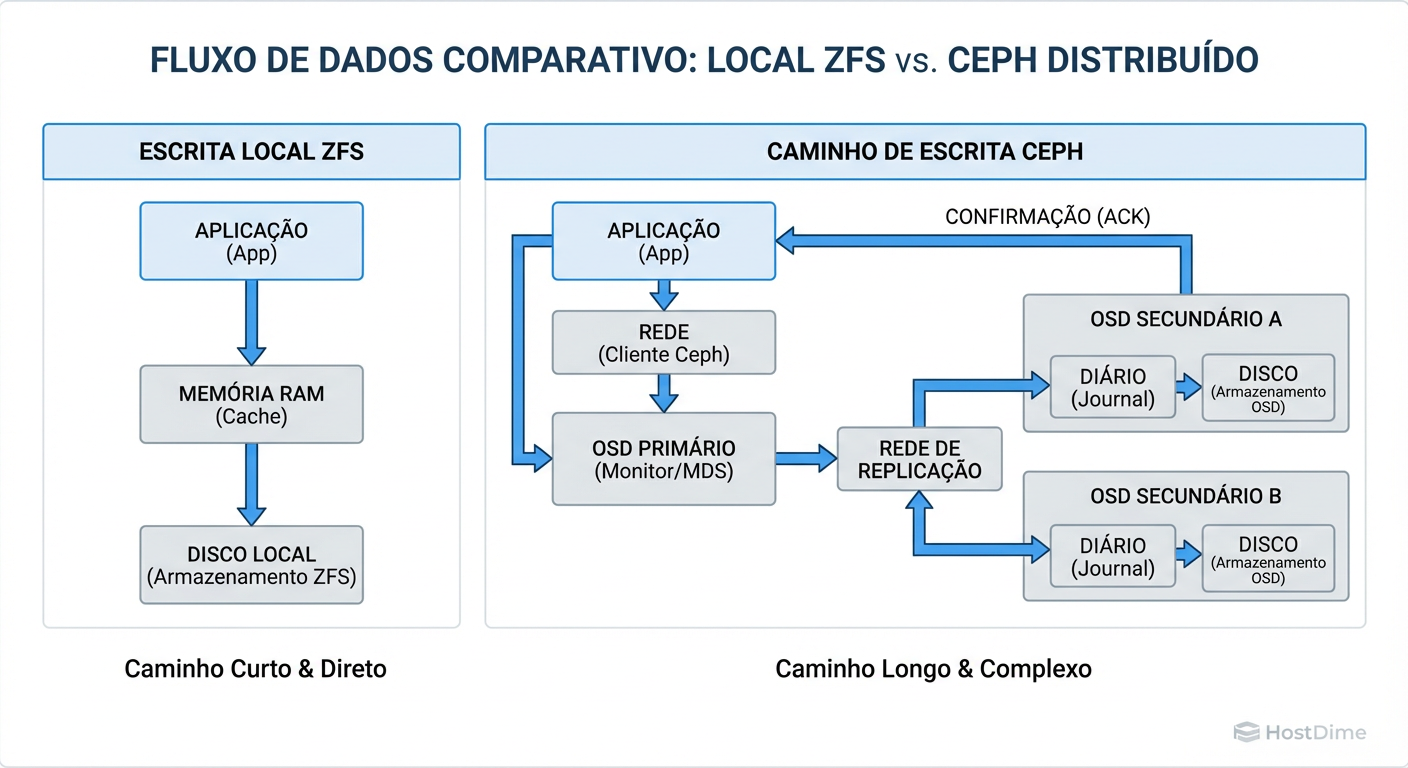 Figura: O Caminho da Escrita: Visualizando por que a latência de rede e a replicação síncrona tornam o Ceph inerentemente mais lento que o armazenamento local.
Figura: O Caminho da Escrita: Visualizando por que a latência de rede e a replicação síncrona tornam o Ceph inerentemente mais lento que o armazenamento local.
A latência de escrita no Ceph é ditada pelo disco mais lento e pelo link de rede mais congestionado no grupo de replicação. Se você tem replicação 3x (padrão de mercado), sua escrita é, no mínimo, 3x mais custosa em termos de I/O de backend, somada a múltiplos round-trips de rede.
O que medir para comprovar:
Não olhe apenas para IOPS. IOPS é vaidade; latência é sanidade. Use o fio para medir o percentil 99 (p99) da latência de escrita com iodepth=1.
fio --name=latency-test --ioengine=rbd --pool=rbd --rbdname=test-image \
--rw=randwrite --bs=4k --iodepth=1 --numjobs=1 --runtime=60 --time_based
Se o seu clat (completion latency) p99 estiver acima de 2ms-5ms em um cluster All-Flash, suas aplicações de banco de dados vão reclamar, independentemente de quantos milhões de IOPS o cluster suporta em paralelo.
A Armadilha dos "3 Nós": Por que Clusters Pequenos de Ceph são Instáveis
Vendedores de hardware adoram vender "Kits de Hiperconvergência" com 3 nós rodando Ceph. Como arquiteto, meu conselho padrão é: Evite.
Matematicamente, 3 nós com replicação 3x funcionam. Operacionalmente, é um pesadelo esperando para acontecer. O Ceph é desenhado para ser probabilístico e resiliente em escala. Em escalas pequenas, a probabilidade joga contra você.
O Problema do Domínio de Falha
Em um cluster de 3 nós, se você perde um nó (manutenção ou falha), você perdeu 33% da sua capacidade e 33% da sua redundância.
Se o cluster estiver configurado com
min_size = 2(o padrão para evitar perda de dados), você ainda consegue escrever.Se outro disco falhar no nó remanescente durante a recuperação (o que é comum devido ao estresse de leitura na reconstrução), você tem perda de dados ou indisponibilidade total.
A Tempestade de Rebalanceamento
Quando um nó volta online, o Ceph tenta "curar" o cluster movendo dados de volta. Em um cluster de 3 nós, essa movimentação satura a rede e a CPU dos nós sobreviventes, que já estão servindo as cargas de trabalho de produção. O resultado é uma degradação severa de performance que pode derrubar aplicações sensíveis.
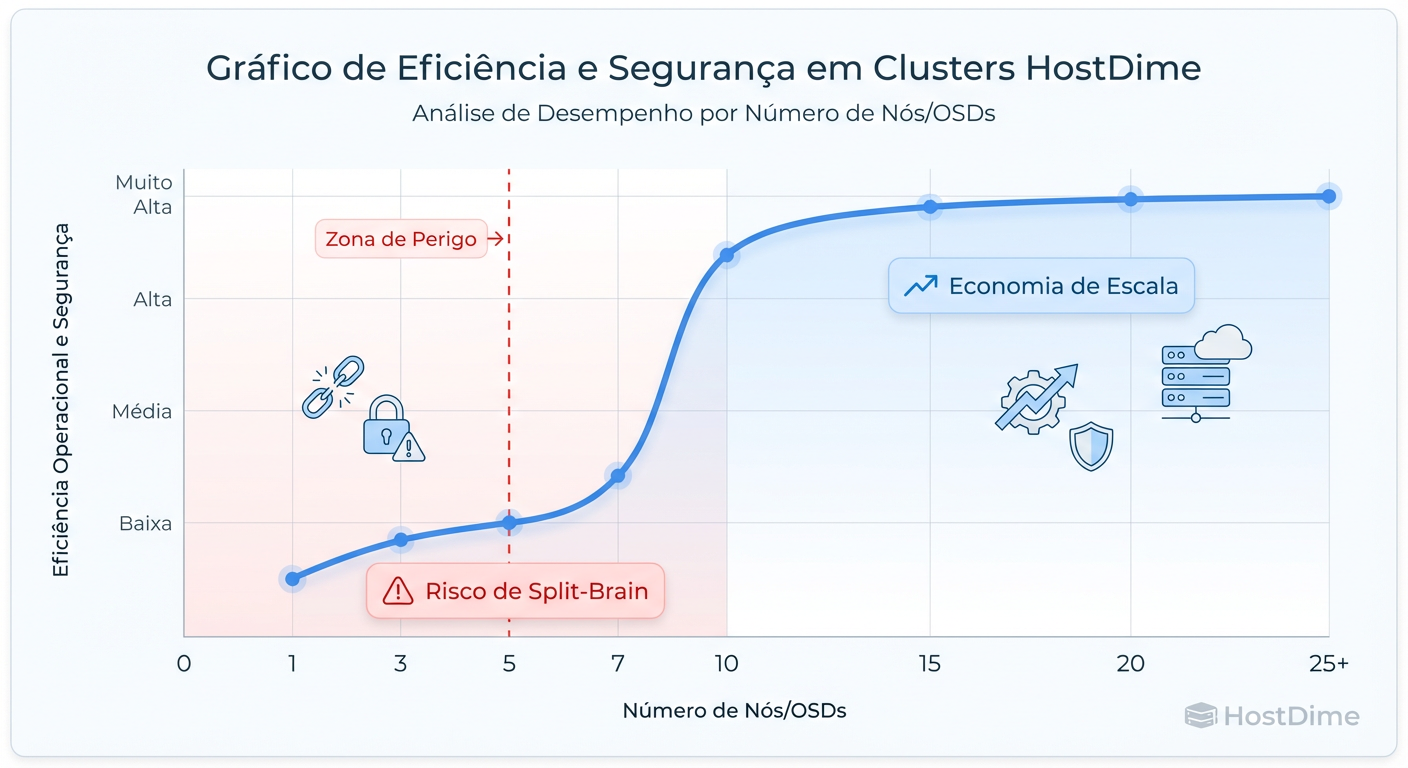 Figura: A Curva de Eficiência do Ceph: Clusters pequenos pagam todo o imposto de complexidade sem colher os benefícios de resiliência e performance.
Figura: A Curva de Eficiência do Ceph: Clusters pequenos pagam todo o imposto de complexidade sem colher os benefícios de resiliência e performance.
Para produção séria, o "número mágico" de nós onde o Ceph começa a fazer sentido econômico e operacional é geralmente acima de 7 a 10 nós. Abaixo disso, o custo da complexidade supera o benefício da distribuição.
IOPS vs. Latência: O Sofrimento dos Bancos de Dados Transacionais
Existe uma diferença fundamental entre "Streaming" (YouTube) e "Transacional" (PostgreSQL/MySQL). O Ceph é excelente para o primeiro e desafiador para o segundo.
Bancos de dados relacionais dependem de gravações sequenciais síncronas em seus logs de transação (WAL/Redo Log). O banco de dados para a operação até que o disco diga "gravei". Como vimos na anatomia da latência, o "gravei" do Ceph demora.
O Fenômeno da Penalidade de Escrita (Write Penalty)
| Característica | Local NVMe (RAID 1) | Storage SAN (iSCSI/FC) | Ceph (RBD 3x Replica) |
|---|---|---|---|
| Latência de Escrita (4k) | ~20-50 µs | ~200-500 µs | ~1 ms - 5 ms |
| Consistência | Controlador Local | Controlador Duplo + Cache | Quorum de Rede (Paxos/Raft) |
| Overhead de Rede | Zero | Baixo (1 hop) | Alto (Múltiplos hops + Replicação) |
| Custo por IOPS | Baixo | Médio/Alto | Alto (Consome muita CPU/RAM) |
| Workload Ideal | DBs High-Perf, Caches | Virtualização Geral | Object Storage, Big Data, K8s |
Callout de Risco: Se você migrar um Oracle ou SQL Server de um Storage All-Flash dedicado para um cluster Ceph mal dimensionado, prepare-se para ver os tempos de espera de log file sync explodirem. O problema não é a falta de largura de banda, é a física da rede.
O Custo Oculto do Day-2: Complexidade Operacional
Muitas organizações adotam o Ceph atraídas pelo "Custo Zero de Licença". Isso é uma falácia de TCO. O custo do software é zero, mas o custo humano é alto.
O Ceph não é "Set and Forget". Ele é um organismo vivo que requer:
Gerenciamento de Scrubbing: O Ceph lê os dados periodicamente para verificar bitrot. Isso consome IOPS. Se mal configurado, o Deep Scrub pode deixar o cluster lento em horário comercial.
Gerenciamento de Mapa CRUSH: Adicionar um novo rack ou mudar a topologia de rede exige edição cuidadosa do mapa CRUSH. Um erro aqui pode fazer o cluster mover petabytes de dados desnecessariamente.
Upgrades: Atualizar um cluster distribuído sem downtime é possível, mas é uma operação cirúrgica que exige validação passo a passo.
Se você não tem um engenheiro de storage dedicado (ou pelo menos um SysAdmin Linux sênior com tempo livre), o Ceph se tornará um passivo técnico.
Alternativas Pragmáticas: Quando NÃO usar Ceph
Como arquiteto, meu trabalho é dizer "não" para ferramentas erradas. Aqui está o guia de decisão para sair do hype:
1. ZFS Local com Replicação Assíncrona
Se você tem apenas 2 ou 3 servidores e precisa de armazenamento para VMs ou DBs:
Solução: Use ZFS local com SSDs NVMe e replique as VMs para o segundo nó a cada 5 ou 15 minutos (ex: Proxmox ZFS Replication).
Ganho: Latência nativa do NVMe, complexidade zero de cluster, integridade de dados garantida. Você perde o "Live Migration" instantâneo de storage compartilhado, mas ganha performance brutal.
2. NVMe-oF (NVMe over Fabrics)
Se você precisa de performance extrema compartilhada:
Solução: Arrays modernos ou soluções JBOF (Just a Bunch of Flash) que falam NVMe-oF.
Ganho: Latência quase idêntica ao local, sem o overhead de processamento do Ceph. O protocolo é muito mais leve que o iSCSI ou o protocolo do Ceph.
3. SAN Tradicional (ou NAS Enterprise)
Se você precisa de "simplicidade" e garantia de SLA:
Solução: Um NetApp, Pure Storage ou Dell PowerStore.
Ganho: Deduplicação e compressão via hardware (muitas vezes mais eficientes que no Ceph), suporte 24/7 e, o mais importante, culpa transferível. Se parar, o fornecedor sangra, não a sua equipe de DevOps.
Veredito Técnico: O Ceph é Ruim?
Absolutamente não. O Ceph é uma maravilha da engenharia moderna. Ele é imbatível para Object Storage (S3), para Clusters de Kubernetes em grande escala e para Provedores de Cloud que precisam vender armazenamento como commodity.
Mas para o cenário Enterprise médio, com um cluster de virtualização de 4 nós rodando ERP e Banco de Dados? O Ceph é frequentemente um canhão para matar uma mosca, onde o recuo do canhão causa mais dano que o tiro.
Dimensione pela latência, não pela capacidade. Respeite a física.
Referências & Leitura Complementar
Sage A. Weil (2007) - "Ceph: A Scalable, High-Performance Distributed File System" (O paper original que define o algoritmo CRUSH).
Ceph Documentation - "Architecture - Network Configuration & Reliability".
Brendan Gregg - "Systems Performance: Enterprise and the Cloud" (Capítulo sobre Disk e Network Latency).
RFC 3720 - "Internet Small Computer Systems Interface (iSCSI)" (Para comparação de overhead de protocolo).

Ricardo Garcia
Especialista em Virtualização (VMware/KVM)
"Vivo na camada entre o hypervisor e o disco. Ajudo administradores a entenderem como a performance do storage define a estabilidade de datastores, snapshots e migrações críticas."