RAID Hardware vs Software (mdadm) em 2025: O Fim da Era das Controladoras?
Descubra por que o debate RAID Hardware vs Software mudou. Análise técnica de performance (NVMe vs SAS), segurança de dados e o risco do 'Vendor Lock-in' com mdadm no Linux moderno.
Há uma década, a presença de uma controladora RAID dedicada (PERC, SmartArray, MegaRAID) era o sinal de um servidor "Enterprise". Hoje, em 2025, ela é frequentemente o maior gargalo de performance e o ponto único de falha mais frustrante do seu data center.
A evolução das CPUs e a revolução do NVMe mudaram fundamentalmente a matemática do armazenamento. Como Arquiteto de Soluções, meu trabalho não é vender hardware, mas garantir a integridade dos dados e a eficiência do TCO (Custo Total de Propriedade). A resposta padrão "compre uma controladora RAID com 2GB de cache" tornou-se uma prática preguiçosa e, muitas vezes, perigosa.
Vamos dissecar essa arquitetura, medir os gargalos e entender por que o software venceu a guerra do silício.
O que é a escolha entre RAID Hardware e Software hoje? Em 2025, a decisão entre RAID Hardware e Software (mdadm/ZFS) deixou de ser sobre "aliviar a CPU" para se tornar uma questão de arquitetura de fluxo de dados. Enquanto o RAID Hardware centraliza o I/O em um chip proprietário (gargalo para NVMe), o RAID Software utiliza o paralelismo massivo das CPUs modernas e acesso direto ao barramento PCIe, oferecendo maior escalabilidade, portabilidade universal de dados e visibilidade diagnóstica completa.
Entendendo a Arquitetura de Storage: Caixa Preta vs. Visibilidade do SO
Para tomar a decisão correta, precisamos ajustar nosso modelo mental sobre como os dados trafegam.
No modelo de RAID via Hardware, você insere uma "caixa preta" entre o Sistema Operacional e os discos. O SO vê apenas um volume lógico (/dev/sda). Ele não sabe se há um disco falhando, se a latência de um SSD específico aumentou ou se o cache da controladora está saturado. Você terceiriza a inteligência para um firmware proprietário, muitas vezes mal documentado e raramente atualizado.
No modelo de RAID via Software (mdadm), o SO tem visibilidade total e acesso direto (Direct Attach). O Kernel Linux gerencia a lógica de paridade e distribuição. Isso não é apenas sobre "ver os discos"; é sobre a capacidade do sistema de arquivos e do agendador de I/O (IO Scheduler) tomarem decisões inteligentes baseadas na topologia real do hardware.
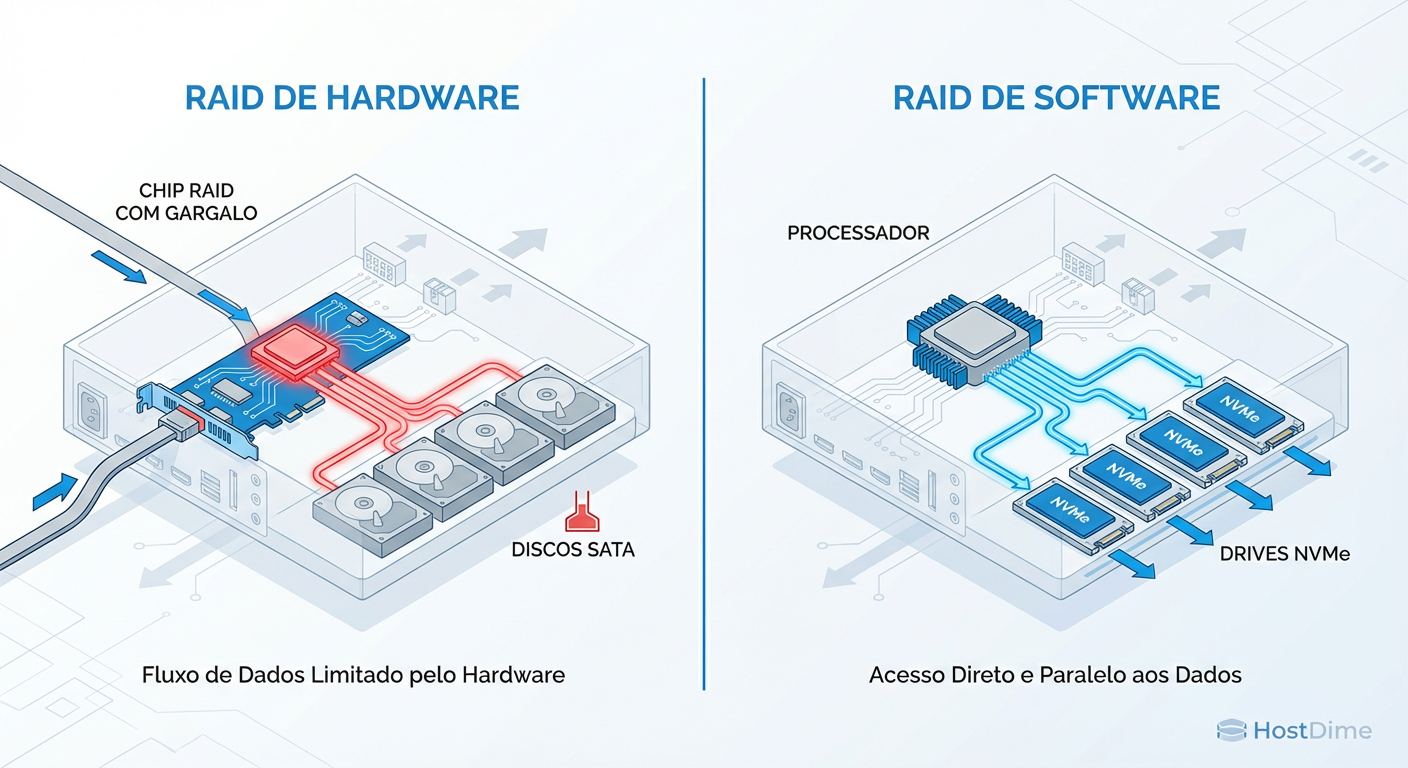
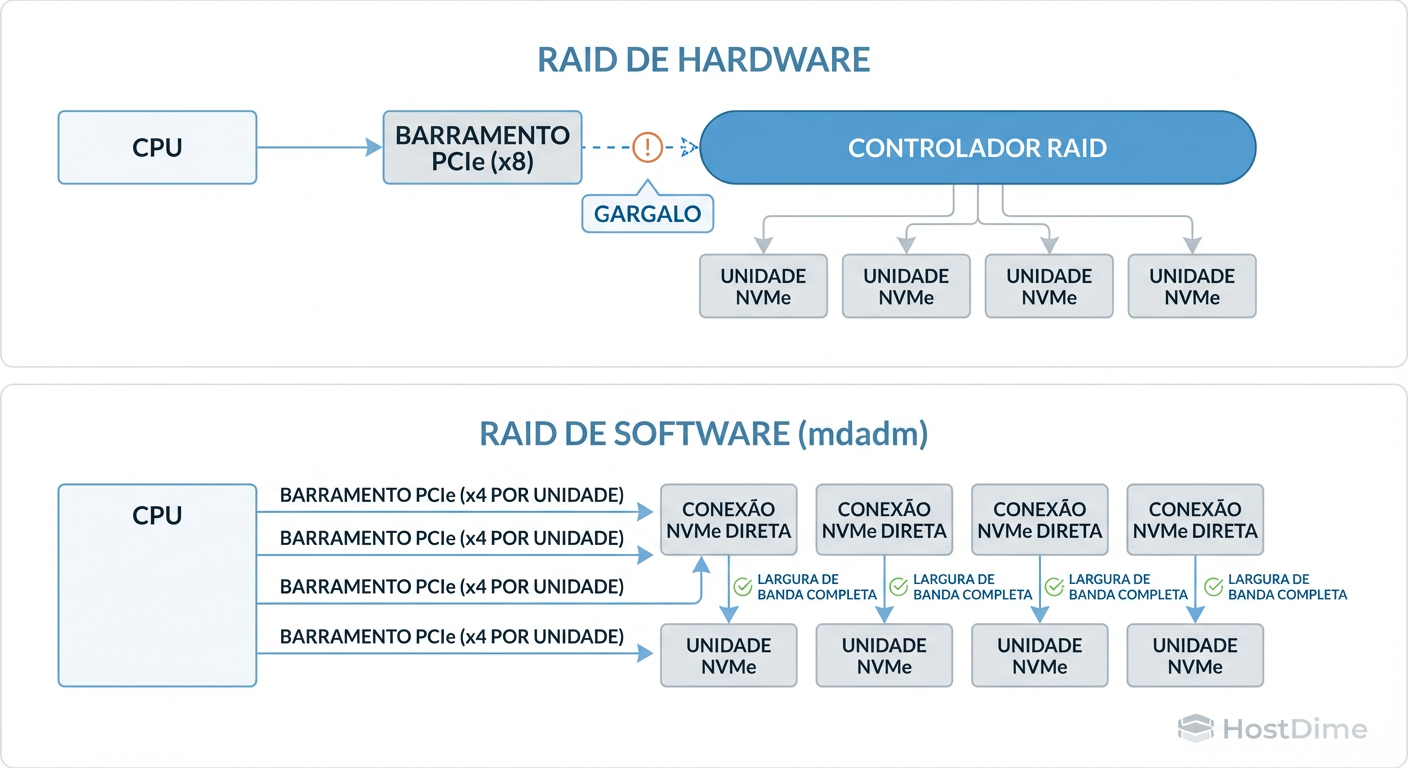 Figura: Diagrama de Fluxo de Dados: O Gargalo da Controladora vs. Acesso Direto (Direct Attach) em arquiteturas NVMe.
Figura: Diagrama de Fluxo de Dados: O Gargalo da Controladora vs. Acesso Direto (Direct Attach) em arquiteturas NVMe.
A imagem acima ilustra o problema fundamental de arquitetura em 2025. Note como a controladora atua como um funil restritivo em ambientes de alta performance, enquanto o acesso direto permite que cada drive negocie velocidade máxima com a CPU.
O Mito da Performance do RAID Hardware e a Morte do Offload XOR
O argumento clássico de vendas para controladoras RAID é: "Você precisa de hardware dedicado para calcular a paridade (XOR) do RAID 5/6, senão sua CPU vai morrer."
Isso era verdade em 2005. Em 2025, é uma falácia.
A Matemática da Evidência
Os processadores modernos possuem conjuntos de instruções (como AVX-512) que trituram cálculos de paridade XOR e Reed-Solomon (para RAID 6) em velocidades ordens de magnitude superiores à capacidade de gravação dos discos.
O teste de realidade: Em um servidor moderno com uma CPU EPYC ou Xeon Scalable, o custo de CPU para manter um RAID 6 de 8 discos NVMe a 10GB/s é frequentemente menor que 5% de um único núcleo.
O gargalo mudou de lugar. Antigamente, a CPU era lenta e os discos (HDDs) eram lentos, mas o barramento era suficiente. Hoje, a CPU é rápida, os discos (NVMe) são absurdamente rápidos, e a Controladora RAID é lenta.
Gargalos Físicos em 2025: O Problema das Lanes PCIe em Controladoras NVMe
Aqui é onde o desenho da solução Enterprise falha se você seguir o "jeito antigo".
Um SSD NVMe Enterprise típico utiliza 4 lanes PCIe (x4). Se você tem um backplane com 8 SSDs NVMe, você tem um potencial de largura de banda de 32 lanes PCIe.
A maioria das controladoras RAID "Top de Linha" (Tri-Mode) conecta-se à placa-mãe usando um slot PCIe x8 ou x16.
A Matemática do Gargalo (Oversubscription)
Demanda dos Discos: 8 drives * PCIe Gen4 x4 = Largura de banda massiva.
Oferta da Controladora: 1 slot PCIe Gen4 x16.
Ao usar uma controladora, você está introduzindo um fator de oversubscription de 2:1 ou pior. Você pagou por performance de NVMe, mas a controladora está fisicamente impedindo que os dados cheguem à CPU rápido o suficiente.
Para verificar se você está sofrendo com isso, use o lspci para ver a largura do link da sua controladora versus a soma dos seus drives:
# Verifique a largura do link da controladora (LnkSta: Width)
lspci -vv | grep -P "RAID|Non-Volatile" -A 20 | grep "LnkSta"
Se a sua controladora está em Width x8 e você tem 4 drives NVMe pendurados nela, você acabou de transformar seus SSDs caríssimos em drives SATA glorificados em termos de throughput sequencial máximo.
O Fator BBWC (Battery Backed Write Cache): A Única Vantagem Real Restante?
Se o mdadm é tão superior, por que ainda vendemos controladoras? A resposta reside em um único componente: A Bateria (BBU) e o Cache de Escrita.
Em bancos de dados transacionais legados, a latência de fsync é crítica. O RAID Hardware mente para o SO: ele diz "gravei no disco" assim que o dado atinge a memória RAM da controladora (protegida por bateria). Isso torna escritas aleatórias pequenas muito rápidas e seguras contra queda de energia.
O Contraponto do Arquiteto: SSDs Enterprise modernos possuem PLP (Power Loss Protection) — capacitores físicos no próprio drive que garantem que dados no cache DRAM do SSD sejam gravados na NAND em caso de corte de energia.
Cenário A (HDD Mecânico): A controladora com BBWC ainda oferece vantagem significativa em performance de escrita aleatória.
Cenário B (SSD Enterprise com PLP): A vantagem da controladora é negligenciável e, muitas vezes, a latência adicionada pelo firmware da controladora é maior que o ganho do cache.
Cenários de Desastre: Portabilidade do mdadm vs. Vendor Lock-in de Hardware
O pior dia da vida de um SysAdmin não é quando um disco falha. É quando a controladora RAID falha.
O Pesadelo do Vendor Lock-in
Se sua controladora MegaRAID de 2018 morrer, você não pode simplesmente plugar os discos na porta SATA da placa-mãe ou em uma controladora de outro fabricante. O formato dos metadados no disco (DDF ou formato proprietário) exige uma controladora similar, muitas vezes com firmware compatível, para importar o "Foreign Config".
Se você não tiver uma peça de reposição idêntica na prateleira, seus dados estão reféns do eBay.
A Universalidade do mdadm
O Linux Software RAID (mdadm) grava metadados padronizados no início ou fim do disco.
O Teste de Portabilidade:
Tire os discos de um servidor Dell R740.
Plugue-os via USB, HBA ou SATA em um Desktop genérico ou um servidor HP.
O Linux detectará a assinatura RAID automaticamente.
# O comando de resgate universal
mdadm --assemble --scan
Não importa o hardware. Se o Linux consegue ler os blocos, ele recupera o array.
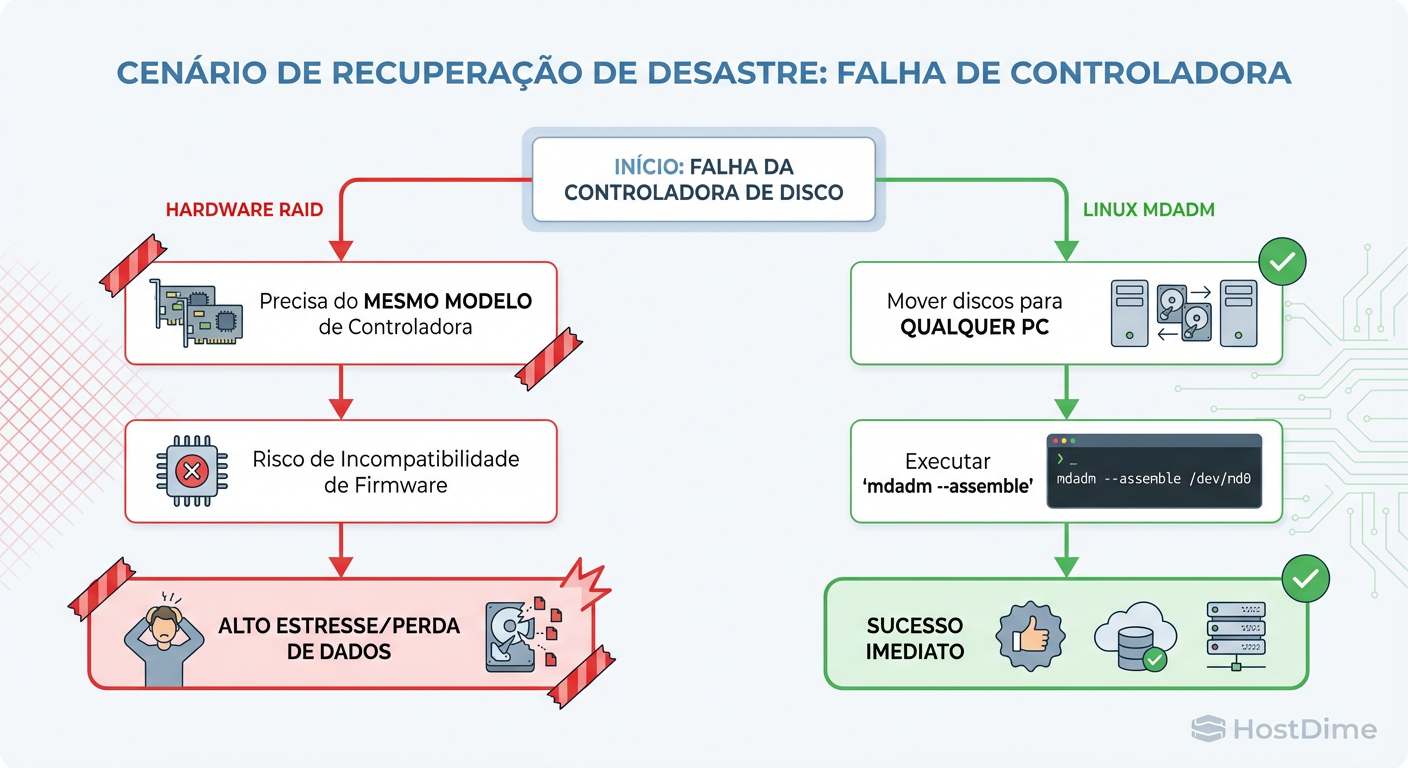 Figura: Árvore de Decisão de Recuperação de Desastres: A complexidade da dependência de hardware proprietário vs. a universalidade do Linux mdadm.
Figura: Árvore de Decisão de Recuperação de Desastres: A complexidade da dependência de hardware proprietário vs. a universalidade do Linux mdadm.
A árvore de decisão acima deixa claro: a dependência de hardware proprietário adiciona camadas de risco logístico (RTO - Recovery Time Objective) que o software elimina completamente.
Monitoramento e Manutenção: O que o SMART não vê atrás da Controladora
Um princípio básico de observabilidade é: não monitore médias, monitore outliers.
Controladoras RAID ofuscam os dados SMART brutos. Para monitorar a saúde real de um disco atrás de uma controladora, você precisa de utilitários proprietários (perccli, ssacli, storcli) que muitas vezes exigem drivers específicos e kernels compatíveis.
Com mdadm (ou ZFS) em modo HBA/Passthrough, o smartctl tem acesso direto:
# Diagnóstico direto e real
smartctl -a /dev/nvme0n1
Você consegue ver erros de CRC, desgaste de SSD (wear leveling) e logs de erro do dispositivo sem uma camada de tradução que pode estar mascarando falhas iminentes.
Comparativo Técnico: Hardware vs. Software (mdadm)
| Característica | RAID Hardware (Controladora) | RAID Software (mdadm/Linux) |
|---|---|---|
| Custo Inicial | Alto ($500 - $2000+) | Zero (Usa CPU existente) |
| Throughput NVMe | Limitado por PCIe da Controladora | Escalável (Limitado apenas pela CPU/Bus) |
| Portabilidade | Baixa (Vendor Lock-in) | Alta (Qualquer Linux lê) |
| Proteção Power-Loss | Excelente (com Bateria/Flash) | Depende do SSD (Requer SSD com PLP) |
| Uso de CPU | Quase Zero | Baixo (Desprezível em CPUs modernas) |
| Substituição de Peça | Crítica (Requer modelo idêntico) | Flexível (Qualquer porta/controladora HBA) |
| Diagnóstico | Opaco (Ferramentas proprietárias) | Transparente (Ferramentas nativas do OS) |
Veredito Operacional: Quando (não) usar Hardware RAID hoje
Como Arquiteto, a resposta é "Depende", mas o "Depende" tem regras claras em 2025.
Quando NÃO usar Hardware RAID (Use mdadm/ZFS):
Storage NVMe/SSD: O gargalo da controladora é inaceitável. Use modo HBA (Passthrough) e deixe o software gerenciar.
Virtualização (Proxmox/KVM) e Containers: O software RAID oferece flexibilidade para expandir arrays e migrar dados que o hardware não acompanha.
Soluções de Software-Defined Storage (Ceph, MinIO): Estes sistemas exigem acesso direto aos discos para gerenciar a integridade dos dados. Colocar RAID HW abaixo do Ceph é um erro de arquitetura grave.
Orçamento Apertado: Não gaste dinheiro em uma controladora barata (sem cache/bateria). É pior que software RAID.
Quando AINDA usar Hardware RAID:
Boot Volumes (OS): Um par de SSDs pequenos em RAID 1 via hardware para o SO simplifica o bootloader e a substituição de discos do sistema, isolando o SO dos dados da aplicação.
Sistemas Legados (Windows Server antigo): Onde o suporte a RAID via software é inferior ou a compatibilidade de drivers é questionável.
HDDs Mecânicos Rotacionais sem SSD Cache: Se você tem um array de 16 HDDs lentos e precisa de performance de escrita aleatória, o cache de 4GB/8GB de uma controladora High-End ainda faz milagres que o cache de página do Linux nem sempre consegue replicar com a mesma segurança (embora ZFS com SLOG resolva isso melhor).
Conclusão: A era da controladora como "cérebro" do storage acabou. Ela foi rebaixada a um mero adaptador de portas (HBA). Para arquiteturas resilientes e de alto desempenho em 2025, confie no código aberto auditável (mdadm/ZFS) e na força bruta das suas CPUs, não em silício proprietário de caixa preta.
Referências & Leitura Complementar
Linux Kernel Documentation: Raid/mdadm administration and internal structures.
NVM Express Base Specification 2.0: Understanding PCIe Lane scalability and NVMe throughput.
Intel Application Note: CPU Utilization of Intel® Xeon® Processors with Software RAID vs Hardware RAID.
Gregg, Brendan: Systems Performance: Enterprise and the Cloud, 2nd Edition (Capítulo sobre Disks & File Systems).

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."