RAID Stripe Size: Otimizando para Workloads Sequenciais e Randômicos

Descubra como o Stripe Size define a performance do seu storage. Uma análise técnica sobre alinhamento, penalidade de Read-Modify-Write e o trade-off entre IOPS e Throughput.
Configurar um array de armazenamento aceitando o tamanho de stripe (Stripe Size) padrão do controlador é um dos erros mais sutis e devastadores na engenharia de infraestrutura. Muitas vezes, o padrão de 64KB ou 128KB é um "meio-termo infeliz": grande demais para bancos de dados transacionais rápidos e pequeno demais para streaming de throughput massivo.
Na engenharia de performance, não aceitamos "mágica". O armazenamento é física (discos girando) ou física de estado sólido (células NAND e voltagem). Se você não alinhar a geometria lógica do seu RAID com a geometria física dos discos e o padrão de acesso da sua aplicação, você está convertendo ciclos de CPU e latência de I/O em calor, não em dados úteis.
O RAID Stripe Size (ou Stripe Unit Size) é o tamanho do bloco de dados contíguos gravados em um único disco físico antes que o controlador RAID passe para o próximo disco do array. Ele define a granularidade da distribuição de dados e determina se uma solicitação de I/O será atendida por um único disco (isolamento) ou por múltiplos discos simultaneamente (paralelismo), impactando diretamente a latência, o IOPS e a penalidade de Read-Modify-Write.
A Anatomia do Stripe Unit e a Ilusão de Paralelismo
A confusão começa na terminologia. Engenheiros frequentemente confundem o tamanho do bloco no disco individual com o tamanho da faixa que atravessa todo o array. Para otimizar, precisamos dissecar essa geometria.
Existem duas métricas fundamentais aqui:
Stripe Unit (Chunk Size): A quantidade de dados em um disco.
Stripe Width: A quantidade de dados gravados em todos os discos de dados em uma única passada.
A fórmula é simples, mas crítica:
Stripe Width = Stripe Unit × (Número de Discos - Discos de Paridade)
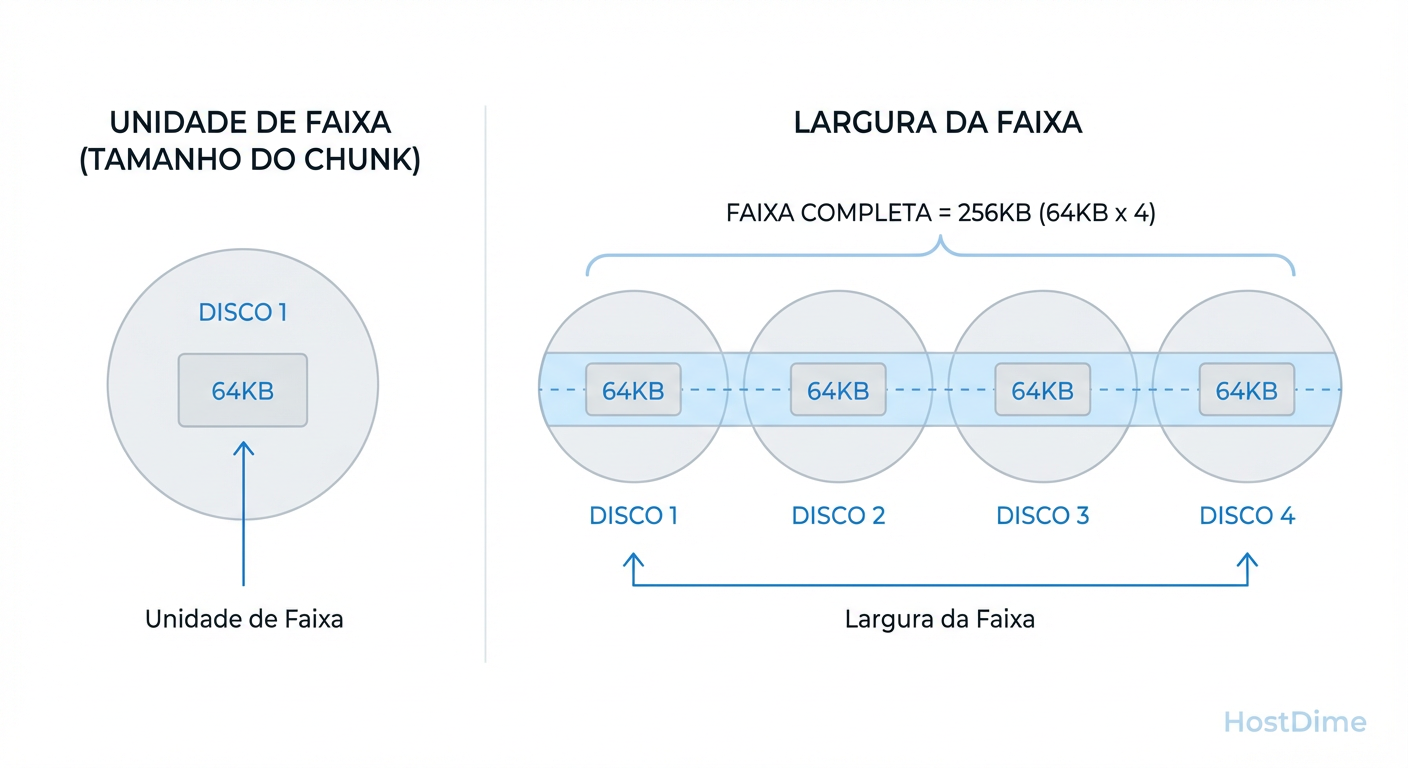 Figura: Diferença crítica: Stripe Unit (tamanho no disco individual) vs. Stripe Width (tamanho total da faixa no array).
Figura: Diferença crítica: Stripe Unit (tamanho no disco individual) vs. Stripe Width (tamanho total da faixa no array).
Se você tem um RAID 5 de 4 discos (3 dados + 1 paridade) e um Stripe Unit de 64KB, seu Stripe Width é 192KB. Por que isso importa? Porque o sistema operacional não "vê" os discos individuais; ele vê um volume lógico. Se o sistema de arquivos enviar um bloco de 128KB, ele será "quebrado" e espalhado.
O objetivo da otimização é controlar essa quebra. Em alguns casos, você quer quebrar o dado para somar a velocidade de vários discos (Throughput). Em outros, você quer evitar a quebra para não ocupar múltiplos atuadores mecânicos ou canais NAND para uma operação minúscula (IOPS).
O Pesadelo do Alinhamento e a Penalidade Read-Modify-Write (RMW)
A penalidade de escrita em RAID 5 e RAID 6 (parity-based RAIDs) é o gargalo mais comum em storages mal configurados. Isso ocorre devido ao desalinhamento entre o tamanho da escrita da aplicação e o Stripe Width.
Quando você realiza uma Full Stripe Write (Escrita de Faixa Completa), o controlador calcula a paridade em memória e grava dados e paridade de uma vez. É limpo e rápido.
No entanto, se você realizar uma Partial Stripe Write (Escrita Parcial) — digamos, gravar 4KB em um stripe de 64KB — o controlador não pode simplesmente "sobrescrever" aquele pedaço. A paridade antiga não serve mais. O controlador é forçado a entrar em um ciclo destrutivo de latência:
Read: Ler os dados antigos e a paridade antiga do disco.
Modify: Calcular a nova paridade com base na diferença.
Write: Gravar os novos dados e a nova paridade.
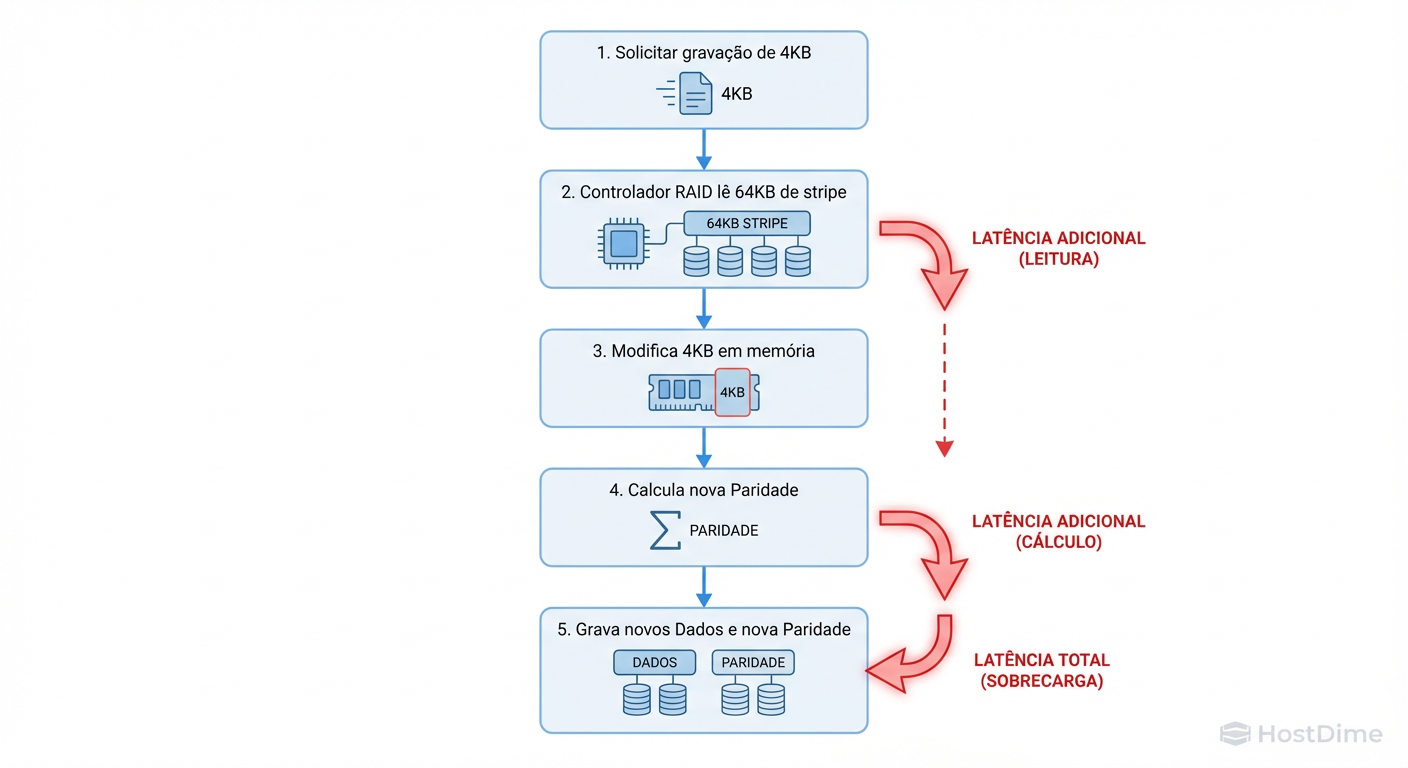 Figura: O ciclo da morte de performance: Como escritas parciais (Sub-Stripe Writes) geram latência excessiva via Read-Modify-Write.
Figura: O ciclo da morte de performance: Como escritas parciais (Sub-Stripe Writes) geram latência excessiva via Read-Modify-Write.
Isso transforma uma operação de escrita lógica em duas leituras e duas escritas físicas (no RAID 5) ou três leituras e três escritas (no RAID 6). O resultado é uma latência de escrita que pode ser 4x a 6x maior do que o esperado. Otimizar o Stripe Size é, fundamentalmente, uma estratégia para mitigar o RMW.
Workloads Sequenciais: Otimizando Throughput com Stripes Grandes
Para cargas de trabalho como backup, streaming de vídeo, ingestão de logs ou Data Warehousing, o objetivo é Throughput (MB/s). Aqui, queremos que o array funcione como uma mangueira de incêndio.
A lógica convencional sugere aumentar o Stripe Size. Se você usar um Stripe Unit de 512KB ou 1MB, você reduz a frequência de comandos de posicionamento de cabeça (em HDDs) e permite transferências de DMA maiores.
No entanto, o segredo está no paralelismo de spindles. Para um workload puramente sequencial single-threaded (ex: um dd ou uma cópia de arquivo única), você quer que o tamanho da sua I/O seja igual ou múltiplo do Stripe Width.
Se o seu Stripe Unit é muito grande (ex: 1MB em um array de 8 discos), uma escrita de 512KB atingirá apenas um disco. Os outros 7 discos ficam ociosos. Para maximizar throughput sequencial, você quer que todos os discos leiam/gravem juntos.
Regra de Ouro Sequencial: Configure o Stripe Unit de forma que a I/O média da aplicação seja dividida entre todos os discos de dados. Mas cuidado: se o sistema tiver muitas threads sequenciais concorrentes, um stripe muito pequeno fará com que o seek time (tempo de busca) destrua a performance, pois as cabeças dos discos tentarão atender a múltiplos fluxos simultaneamente.
Workloads Randômicos: A Estratégia de Isolamento de IOPS
Bancos de dados OLTP (SQL Server, PostgreSQL, Oracle) e infraestruturas de VDI vivem de IOPS e baixa latência. O padrão de acesso é pequeno (4KB, 8KB, 16KB) e imprevisível.
Aqui, o modelo mental inverte. O objetivo não é fazer todos os discos trabalharem juntos em uma requisição, mas sim garantir que cada disco possa atender uma requisição diferente independentemente. Isso é isolamento de I/O.
Se o seu Stripe Unit for muito pequeno (ex: 4KB ou 8KB) e sua aplicação fizer uma leitura de 16KB, você forçará 2 ou mais discos a buscar dados para uma única operação minúscula. Você está desperdiçando IOPS mecânicos.
Para workloads randômicos, geralmente preferimos Stripe Units maiores (64KB, 128KB ou 256KB).
Por que? Isso garante que a maioria das leituras/escritas aleatórias de banco de dados (geralmente 8KB ou 16KB) caiba inteiramente dentro de um único disco (Stripe Unit).
Resultado: O Disco 1 atende a Requisição A, enquanto o Disco 2 está livre para atender a Requisição B. O IOPS total do array escala linearmente com o número de discos.
SSDs vs. HDDs: O Stripe Size ainda importa em Flash?
Existe um mito de que em All-Flash Arrays (AFA), o Stripe Size é irrelevante porque não existe seek time mecânico. Isso é falso. Embora a penalidade de busca tenha desaparecido, surgem novos vilões: Amplificação de Escrita e Alinhamento de Página NAND.
| Característica | HDD (Mecânico) | SSD (Flash/NVMe) |
|---|---|---|
| Gargalo Principal | Tempo de Busca (Seek Time) | CPU do Controlador / Erase Blocks |
| Impacto de Stripe Pequeno | Catastrófico (Thrashing da cabeça) | Alto overhead de interrupções na CPU |
| RMW (Read-Modify-Write) | Latência de rotação extra | Desgaste da célula (Write Endurance) |
| Recomendação Geral | Otimizar para reduzir seeks | Otimizar para alinhar com Page Size (4k/8k/16k) |
Em SSDs, um Stripe Size desalinhado ou muito pequeno pode causar um excesso de operações de metadados e RMW, o que consome os ciclos de P/E (Program/Erase) do SSD, reduzindo sua vida útil e saturando a CPU do controlador RAID. Em arrays modernos baseados em software (como ZFS ou vSAN), o "recordsize" ou tamanho do objeto deve ser alinhado com o hardware subjacente para evitar que uma escrita lógica de 4KB se transforme em 16KB físicos.
Benchmarking Prático: Usando FIO para Encontrar o Sweet Spot
Não confie na folha de especificações. Valide. A ferramenta padrão-ouro para isso é o fio.
Para testar o impacto do Stripe Size, você deve isolar a variável. Crie volumes com diferentes tamanhos de stripe (ex: 64k, 128k, 256k) e execute testes idênticos.
Teste de "Pior Caso" (Random Write 4k)
Este teste revela a eficiência do controlador em lidar com IOPS e a penalidade de RMW.
fio --name=random_write_test \
--ioengine=libaio --direct=1 --sync=0 \
--rw=randwrite --bs=4k --numjobs=4 \
--iodepth=32 --size=4G --runtime=60 \
--time_based --group_reporting \
--filename=/mnt/raid_test/testfile
Teste de Throughput Sequencial (Large Block)
Verifica se o stripe width permite fluxo máximo de dados.
fio --name=seq_read_test \
--ioengine=libaio --direct=1 \
--rw=read --bs=1M --numjobs=1 \
--iodepth=64 --size=10G --runtime=60 \
--time_based --group_reporting \
--filename=/mnt/raid_test/testfile
O que observar nos resultados:
Latência (clat): Observe o percentil 99th (p99). Se o stripe size estiver errado, a latência de cauda explodirá devido ao RMW.
IOPS vs. Discos: Em leitura randômica, o IOPS deve ser próximo de
(IOPS de 1 disco) * (Nº de discos). Se for muito menor, seu stripe unit é muito pequeno e está causando contenção.
Matriz de Decisão: Trade-offs por Aplicação
Não existe "melhor" tamanho, existe o tamanho menos errado para o seu problema. Use esta tabela como ponto de partida para seus testes.
| Tipo de Workload | Exemplo de Aplicação | Padrão de I/O | Estratégia de Stripe | Tamanho Sugerido (Unit) |
|---|---|---|---|---|
| Randômico Puro | Banco de Dados OLTP (SQL) | Pequeno (8k-64k), Aleatório | Isolamento: Unit > I/O Médio | 64KB - 256KB |
| Sequencial Puro | Streaming de Vídeo, Backup | Grande (1MB+), Sequencial | Paralelismo: Width ≈ I/O Chunk | 256KB - 512KB |
| Misto (General Purpose) | Servidor de Arquivos, VM Boot | Variável | Equilíbrio: Evitar RMW excessivo | 64KB or 128KB (Padrão) |
| Log/Journaling | Write-Ahead Logs (WAL) | Pequeno, Sequencial, Sync | Latência: Minimizar overhead | 32KB - 64KB |
| Big Data / Analytics | Hadoop, Data Warehouse | Massivo, Scan Sequencial | Throughput: Maximizar leitura | 512KB+ |
Veredito Técnico Prática
Otimizar o RAID Stripe Size é um exercício de entender o fluxo invisível dos dados. Se você alinhar o tamanho do bloco da aplicação, o tamanho do cluster do sistema de arquivos e o Stripe Unit do array, você elimina atrito. Se ignorar isso, o atrito vence. Antes de colocar em produção, meça. A evidência sempre vence a intuição.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): "Dictionary of Storage Networking Terminology" - Definições formais de Striping e Parity.
Linux Kernel Documentation: "RAID setup and optimization guide" (mdadm documentation).
Oracle Database Performance Tuning Guide: Seção sobre "I/O Configuration and Design" (Conceitos de Stripe Width para DBs).
RFC 3720: iSCSI (Internet Small Computer Systems Interface) - Para entender encapsulamento de blocos em rede.

Roberto Uchoa
Sysadmin Veterano (Anti-Hype)
"Sobrevivente da bolha pontocom e do hype do Kubernetes. Troco qualquer arquitetura de microsserviços 'inovadora' por um script bash que funciona sem falhas há 15 anos. Uptime não é opcional."