RFP de storage: como desmontar o marketing e exigir especificações reais

Pare de comprar folhetos. Aprenda a estruturar uma RFP de armazenamento que exponha gargalos de IOPS, custos ocultos de licenciamento e a verdade sobre a capacidade útil.
Se você está prestes a lançar uma RFP (Request for Proposal) de armazenamento e o documento foi montado copiando e colando requisitos de uma compra feita há três anos, pare agora. Você está prestes a cair na armadilha clássica dos grandes fabricantes: comprar números de marketing inflados em vez de desempenho sustentável.
O vendedor vai te levar para almoçar, falar sobre "sinergia" e "transformação digital", mas o papel dele é mover caixas com margens altas, não garantir que seu banco de dados Oracle pare de travar nas sextas-feiras. A realidade do silício é fria e indiferente aos slides de PowerPoint. Vamos dissecar como escrever uma RFP que afasta os oportunistas e obriga os fornecedores a serem honestos sobre o que estão vendendo.
Resumo em 30 segundos
- IOPS de Marketing são inúteis: Números de "1 milhão de IOPS" são geralmente medidos em cenários irreais (cache hit 100%). Exija latência de cauda (P99) sob carga.
- A mentira da "Capacidade Efetiva": Nunca aceite garantias baseadas em deduplicação mágica. Exija capacidade útil garantida sem compressão.
- O pesadelo da reconstrução: Drives de 22TB+ em RAID tradicional são uma bomba-relógio. Pergunte sobre a queda de performance durante o rebuild.
Por que copiar modelos antigos garante o fracasso
A preguiça é a melhor amiga do vendedor de storage legado. Quando você usa um template de RFP de 2020, você está essencialmente pedindo arquiteturas desenhadas para HDDs mecânicos, mesmo que esteja comprando All-Flash.
O problema é que os controladores de storage (as CPUs que gerenciam os dados) não evoluíram na mesma velocidade que a mídia NAND Flash. Se sua RFP pede "conectividade SAS" ou foca excessivamente em "cache de controlador", você está limitando sua infraestrutura a gargalos que o protocolo NVMe já resolveu. Especificações antigas permitem que fabricantes empurrem arquiteturas de duplo controlador (active-passive ou active-active legado) que engasgam muito antes de saturar os SSDs.
A falácia dos milhões de IOPS e a latência de cauda
Se existe um número que deveria ser banido de qualquer discussão técnica séria, é o "IOPS Máximo". Dizer que um array faz "1 milhão de IOPS" é como dizer que um carro chega a 300 km/h, mas omitir que ele só faz isso em queda livre de um penhasco.
Fabricantes adoram testar IOPS com blocos minúsculos (4K), 100% de leitura e, crucialmente, servindo dados direto do cache DRAM, não da mídia persistente. No mundo real, quando o cache enche, o desempenho despenca.
O que você deve exigir na RFP: Latência de Cauda (Tail Latency) ou P99.
💡 Dica Pro: Especifique o teste assim: "O sistema deve manter latência abaixo de 500µs (microssegundos) no percentil 99.9 (P99.9) sob 80% de carga de IOPS sustentada por 4 horas".
Isso elimina os arrays que são rápidos apenas nos primeiros 5 minutos. A latência média esconde os picos que derrubam aplicações sensíveis. Se 1% das suas requisições demoram 200ms, seu usuário final vai sentir que o sistema travou, não importa se a média é 1ms.
Capacidade bruta versus útil: a matemática do overhead
Aqui é onde a "contabilidade criativa" brilha. O fabricante promete "1 Petabyte Efetivo" em um chassi 2U. Quando você lê as letras miúdas, descobre que isso depende de uma taxa de redução de dados (deduplicação + compressão) de 5:1.
Seus dados são vídeos, imagens médicas (DICOM) ou bancos de dados criptografados? Parabéns, sua taxa de redução será próxima de 1:1. Aquele array "barato" de repente ficou 5 vezes mais caro porque você precisará comprar gavetas de expansão no mês seguinte à instalação.
⚠️ Perigo: Nunca aceite "Capacidade Efetiva" como métrica contratual principal. Exija "Capacidade Útil Garantida" (Usable Capacity) após a formatação RAID/Erasure Coding e overhead do sistema de arquivos, considerando taxa de redução de dados de 1:1. Se a deduplicação funcionar, encare como bônus, não como requisito para o sistema ligar.
O teste de fogo da resiliência: reconstrução sob carga
Discos rígidos de 22TB e SSDs de 30TB são ótimos para densidade, mas aterrorizantes para disponibilidade em arquiteturas legadas. Em um RAID 6 tradicional, a reconstrução de um drive desses pode levar dias. Durante esse tempo, o desempenho do array inteiro sofre porque a CPU do controlador está ocupada calculando paridade.
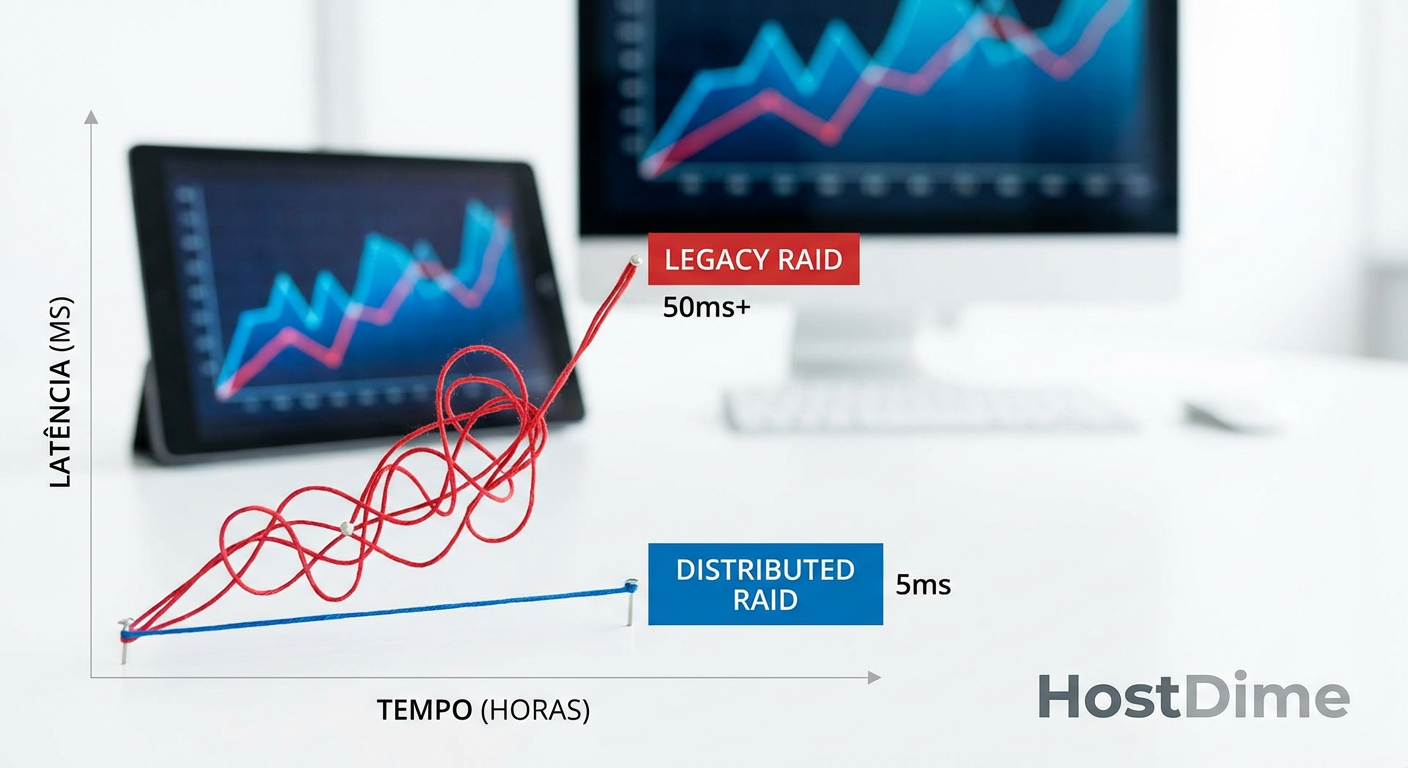 Figura: Legenda: O impacto devastador de uma reconstrução RAID tradicional na latência versus arquiteturas modernas distribuídas.
Figura: Legenda: O impacto devastador de uma reconstrução RAID tradicional na latência versus arquiteturas modernas distribuídas.
Como vemos na projeção acima, a estabilidade da latência é o que separa o hardware enterprise de brinquedos caros. Se sua RFP não exige "Manutenção de 90% da performance nominal durante reconstrução de drive", você está comprando uma janela de indisponibilidade futura.
Pergunte especificamente:
O rebuild é feito por um disco de hot-spare dedicado (lento) ou distribuído por todo o espaço livre do cluster (rápido)?
Qual é o impacto na latência de gravação durante o rebuild?
Armadilhas de licenciamento e renovação
O hardware é barato; o software é onde eles te pegam. Muitos fabricantes modernos adotaram o modelo de "licenciamento por capacidade". Você compra um SSD de 15TB na Amazon por um preço X, mas o fabricante cobra 3X para "autorizar" esse SSD no array.
Pior ainda é a renovação de suporte no ano 4. É comum ver o custo de manutenção (OPEX) superar o custo de comprar um array novo (CAPEX) após o fim da garantia inicial.
Na RFP, exija uma tabela de TCO (Total Cost of Ownership) de 5 a 7 anos, com tetos de reajuste de suporte fixados em contrato. Se o fornecedor se recusar a travar o preço do suporte do ano 5 hoje, é porque ele planeja te extorquir lá na frente.
Preparando o terreno para NVMe-oF e CXL
Se você está comprando storage hoje para durar 5 anos, falar apenas de Fibre Channel ou iSCSI é olhar para o retrovisor. O protocolo NVMe over Fabrics (NVMe-oF) já é realidade e remove a latência imposta pelo controlador SCSI legado.
Mas a verdadeira revolução que deve estar no seu radar (e na sua RFP como diferencial técnico) é o suporte ou roadmap para CXL (Compute Express Link). O CXL permite que o storage se comporte como memória, acessível diretamente pela CPU via barramento PCIe, com latência de nanossegundos, não microssegundos.
Não compre backplanes SAS que não suportam NVMe nativo. Você estará investindo em sucata futura. Certifique-se de que a infraestrutura de rede (switches) solicitada na RFP suporte RoCE v2 ou TCP offload para viabilizar o NVMe-oF sem precisar trocar todo o cabeamento daqui a dois anos.
O veredito técnico
Não deixe que o departamento de compras decida as especificações técnicas baseadas no menor preço por TB bruto. O custo real do storage está na latência que atrasa seus processos e nas horas extras pagas à equipe de TI quando um rebuild falha.
Se você não desafiar os números de marketing na fase de RFP, você não é um arquiteto, é apenas um assinante de cheques. Force os fornecedores a saírem da zona de conforto dos datasheets padronizados e provem como o hardware deles lida com o pior dia do seu data center, não com o melhor dia do laboratório deles.

Marcus Duarte
Tradutor de Press Release
"Ignoro buzzwords e promessas de marketing para focar no que realmente importa: especificações técnicas, benchmarks reais e as letras miúdas que os fabricantes tentam esconder."