SLO para storage: definindo, medindo e garantindo disponibilidade real
Esqueça os 100% de uptime. Aprenda a definir SLOs e SLIs para armazenamento de dados, calcular Error Budgets e priorizar a latência de cauda (p99) como um verdadeiro SRE.
A esperança não é uma estratégia de engenharia. Em sistemas de armazenamento distribuído ou mesmo em arrays locais de alta performance, a busca pela disponibilidade de 100% não é apenas matematicamente improvável. É financeiramente irresponsável e tecnicamente contraproducente.
Como SREs (Site Reliability Engineers), aceitamos que falhas são inevitáveis. Discos rígidos falham, células NAND degradam, controladoras entram em pânico e cabos DAC oxidam. O nosso trabalho não é eliminar a falha, mas gerenciá-la dentro de limites aceitáveis para o negócio.
Resumo em 30 segundos
- Perfeição é Custo: Tentar atingir 100% de disponibilidade impede atualizações de firmware, patches de segurança e inibe a inovação no seu cluster de storage.
- SLI vs. SLO: SLI é o que o disco está fazendo agora (latência, erros de I/O); SLO é o alvo que você prometeu (ex: 99.9% das leituras abaixo de 10ms).
- Durabilidade ≠ Disponibilidade: Em storage, perder dados (durabilidade) é inaceitável, mas não conseguir acessá-los por 5 minutos (disponibilidade) pode ser tolerável.
A falácia dos 100%
Muitos administradores de sistemas e entusiastas de Home Labs caem na armadilha de desenhar arquiteturas para "zero downtime". Isso ignora a física básica dos dispositivos de bloco.
Um sistema que promete 100% de disponibilidade não pode sofrer manutenção. Você não pode atualizar o ZFS, não pode trocar um switch Top-of-Rack e não pode aplicar patches de mitigação de espectro em CPUs. O resultado é um sistema frágil, obsoleto e aterrorizante de operar.
Ao definirmos um SLO (Service Level Objective) menor que 100% — digamos, 99,95% — estamos explicitamente autorizando o sistema a falhar por cerca de 21 minutos por mês. Esse é o nosso Orçamento de Erro. É esse tempo que usamos para rodar scrubs agressivos, rebalancear dados no Ceph ou atualizar o firmware dos SSDs NVMe.
Taxonomia da falha (SLIs)
Para gerenciar a confiabilidade, precisamos medi-la. Os SLIs (Service Level Indicators) são as métricas brutas do sistema. No universo de storage, focar apenas em "Uptime" é amadorismo. Precisamos de granularidade.
Disponibilidade vs. durabilidade
Esta é a distinção mais crítica em engenharia de dados.
Disponibilidade é a resposta à pergunta: "Posso ler este arquivo agora?". Durabilidade é a resposta à pergunta: "Este arquivo ainda existe?".
Podemos ter baixa disponibilidade e alta durabilidade. Se o seu NAS TrueNAS desligar por falta de energia, a disponibilidade é 0%, mas a durabilidade (provavelmente) segue intacta nos discos. O inverso é catastrófico: um sistema que responde "200 OK" instantaneamente (alta disponibilidade), mas entrega dados corrompidos (baixa durabilidade).
⚠️ Perigo: Nunca confunda erros de rede com corrupção de dados. Um timeout de iSCSI é um problema de disponibilidade. Um checksum error no ZFS é um problema de durabilidade. Seus alertas devem tratar esses eventos com urgências drasticamente diferentes.
Latência de cauda (Tail Latency)
Médias mentem. Se você monitora a latência média do seu pool de armazenamento, você está cego para a experiência do usuário.
Em um array de SSDs, a latência média pode ser 200µs. Mas devido ao Garbage Collection interno do SSD ou contenção de locks, 1% das requisições podem levar 50ms. Para um banco de dados transacional, isso é inaceitável.
Como SREs, focamos nos percentis de cauda: p95, p99 e p99.9.
SLI Ruim: Latência média de leitura é 5ms.
SLI Bom: Latência p99 de leitura é < 10ms (avaliado em janelas de 5 minutos).
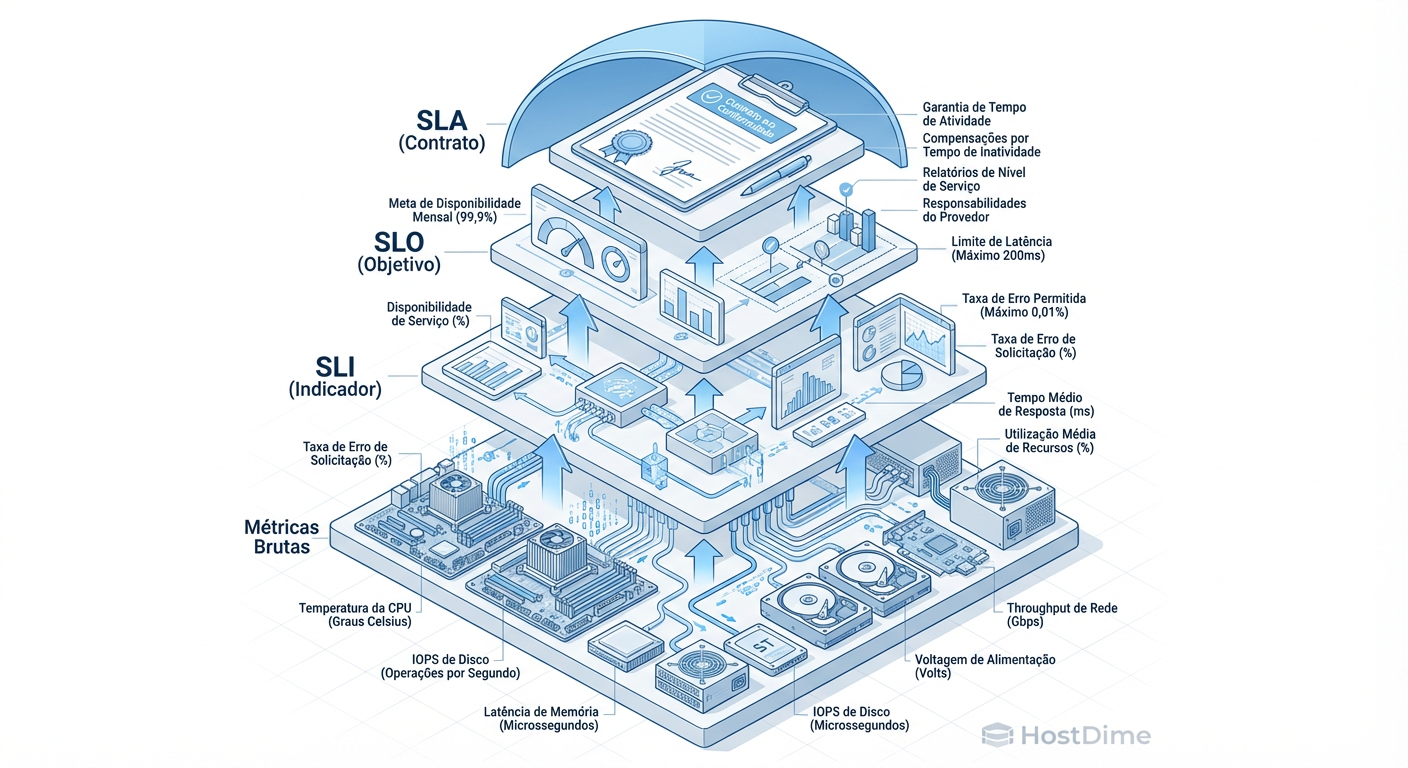 Fig 1. A hierarquia da confiabilidade: transformando sinais elétricos brutos em contratos de negócios.
Fig 1. A hierarquia da confiabilidade: transformando sinais elétricos brutos em contratos de negócios.
A matemática da confiança (SLOs)
O SLO é o alvo numérico para o SLI. É aqui que a física dos componentes encontra a necessidade do negócio. Não faz sentido definir um SLO de latência de NVMe para um pool de HDDs mecânicos de 7200 RPM.
O objetivo deve ser defensável. Se você define um SLO de 99,99% de disponibilidade, você precisa de redundância geográfica e failover automático. Se o seu hardware é um único servidor em um rack doméstico, seu SLO real é, no máximo, 99,5% (considerando falhas de energia e hardware).
Definindo tiers de serviço
Para evitar a fadiga de alertas e custos desnecessários, segmente seus dados. O armazenamento de "Tier 0" (bancos de dados, VMs de produção) exige SLOs rigorosos. O "Tier 2" (backups, arquivos mortos) pode tolerar latências maiores.
Tabela Comparativa: Padrões de SLO por Tier de Armazenamento
| Tier | Tecnologia Típica | SLI Crítico | SLO Alvo (Exemplo) | Caso de Uso |
|---|---|---|---|---|
| Hot (Tier 0) | NVMe (RAID 10/ZFS Mirror) | Latência p99 | < 2ms | OLTP, VMs Críticas |
| Warm (Tier 1) | SSD SATA / SAS | Latência p95 | < 10ms | File Servers, Apps Web |
| Cold (Tier 2) | HDD (RAIDZ2 / Erasure Coding) | Throughput | > 100 MB/s | Backups, Mídia, Logs |
| Frozen (Tier 3) | Tape / Object Storage (S3 Glacier) | Durabilidade | 99.999999999% | Arquivamento Legal |
💡 Dica Pro: Ao adotar novas tecnologias como CXL (Compute Express Link — interconexão de alta velocidade para memória e storage), seus SLOs de latência para o Tier 0 precisarão ser revisados. O CXL promete latências próximas à DRAM, tornando os alvos atuais de NVMe obsoletos.
Orçamento de erro (Error Budget)
O Orçamento de Erro é a métrica mais poderosa para negociar com gerentes de produto ou consigo mesmo (no caso de homelabbers).
Se o seu SLO é 99,9% de disponibilidade, você tem 43 minutos de inatividade permitida a cada 30 dias.
Se o sistema cair por 10 minutos, você "gastou" 23% do seu orçamento.
Se o sistema estiver lento (violando o SLO de latência) por 1 hora, você queimou orçamento.
Consumo do orçamento
O monitoramento não deve ser binário (funciona/não funciona). Devemos medir a taxa de queima (burn rate). Se você queimar seu orçamento muito rápido nas primeiras 24 horas do mês, algo está sistemicamente errado.
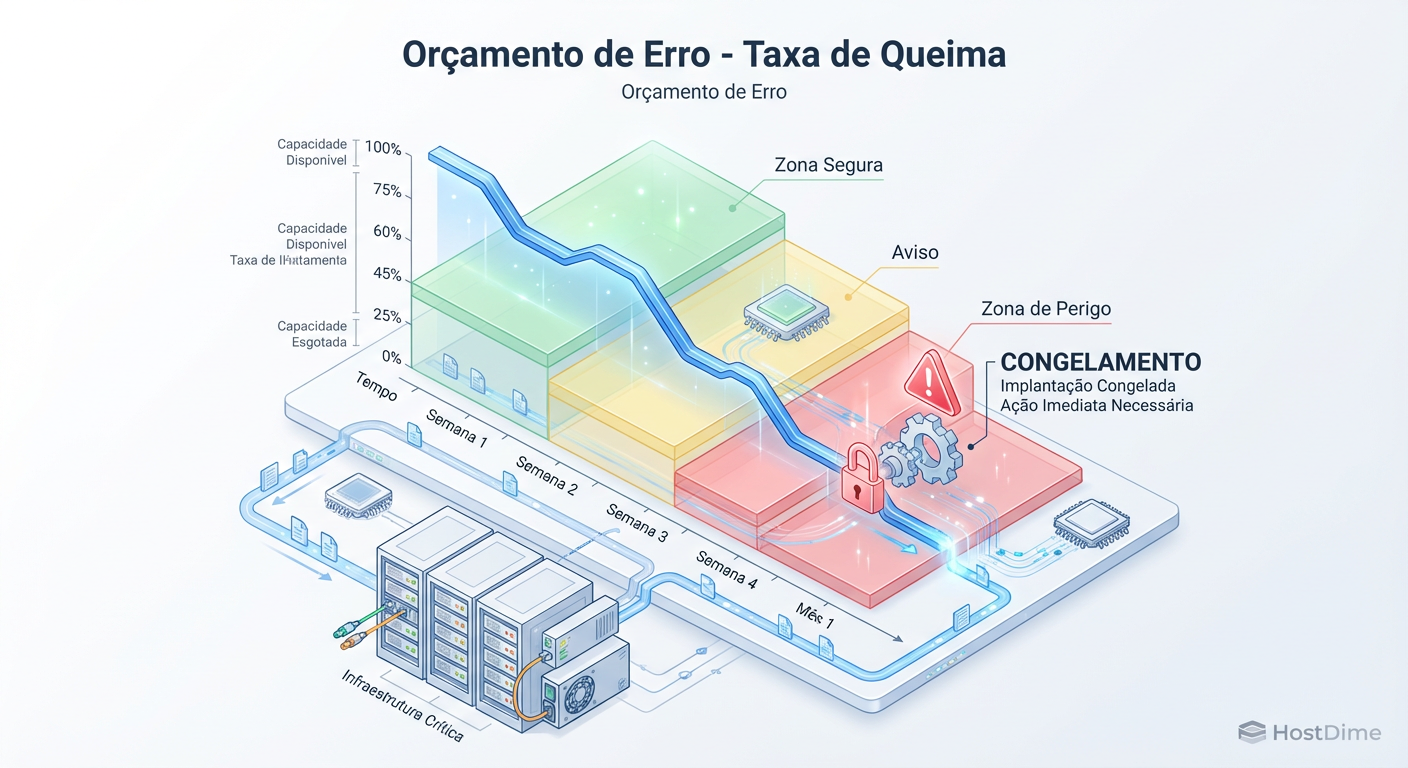 Fig 2. O consumo do Orçamento de Erro. Quando a linha cruza a zona vermelha, a estabilidade torna-se a única prioridade.
Fig 2. O consumo do Orçamento de Erro. Quando a linha cruza a zona vermelha, a estabilidade torna-se a única prioridade.
Quando o orçamento acaba, a regra de ouro do SRE entra em vigor: a estabilidade supera a velocidade.
Consequências e cultura
A parte mais difícil do SRE não é configurar o Prometheus ou o Grafana, é a disciplina cultural. O que acontece quando o Orçamento de Erro se esgota?
Política de congelamento
Se o seu pool de storage violou o SLO repetidamente e o orçamento acabou:
Freeze de Deploys: Nenhuma mudança de configuração não essencial é permitida.
Foco em Confiabilidade: Todo o tempo de engenharia é desviado para investigar a causa raiz e melhorar a resiliência.
Retomada: Lançamentos só voltam quando o sistema provar estabilidade ou o novo ciclo do orçamento começar.
Em um ambiente doméstico ou de pequena empresa, isso significa: pare de tentar implementar aquele novo script de automação ou de migrar para a versão beta do TrueNAS Scale. Estabilize o que você tem.
Post-mortem sem culpa
Quando ocorre um incidente catastrófico — por exemplo, a perda de um vDev inteiro ou uma corrupção silenciosa de dados — a reação natural é procurar o culpado. "Quem rodou o comando rm -rf?".
Isso é tóxico. No modelo SRE, assumimos que as pessoas são bem-intencionadas, mas o sistema permite erros.
Errado: "O João deletou o dataset errado."
Certo (SRE): "O sistema permitiu a deleção de um dataset crítico sem autenticação multifator ou confirmação secundária, e os snapshots de proteção não estavam configurados corretamente."
O documento de Post-mortem deve focar em:
O que aconteceu? (Timeline técnica).
Por que o monitoramento não detectou antes?
Quais mecanismos de segurança falharam?
Itens de ação para evitar recorrência.
O imperativo da observabilidade
Implementar SLOs em storage não é um projeto de fim de semana; é uma mudança fundamental na forma como operamos infraestrutura. Sair do modo reativo ("o disco quebrou, preciso trocar") para o modo proativo ("a latência p99 está degradando, vamos investigar antes que o cliente note") é o que separa amadores de profissionais.
Monitore seus sinais de saturação. Entenda a diferença entre I/O wait e CPU steal. Respeite a física dos seus discos. E acima de tudo, use seu orçamento de erro para inovar, mas nunca ignore quando ele chegar a zero. A confiabilidade é a funcionalidade mais importante de qualquer sistema de armazenamento.
Perguntas Frequentes
Qual a diferença prática entre SLA e SLO?
O SLO (Objective) é o alvo técnico interno que a engenharia persegue (ex: 99,9%). O SLA (Agreement) é o contrato externo com o cliente, geralmente mais brando (ex: 99,5%), que envolve penalidades financeiras se violado. O SLO é nosso alerta de segurança antes de violarmos o SLA.
Como medir durabilidade em discos locais?
Durabilidade é difícil de medir em tempo real. Utilizamos proxies como a frequência de verificação de integridade (ZFS Scrubs), contadores de erros SMART (Reallocated Sectors) e testes periódicos de restauração de backup. Se um Scrub encontra e corrige erros, sua durabilidade foi mantida, mas seu "risco de durabilidade" aumentou.
Posso aplicar SLOs em um Home Lab com um único servidor?
Sim, mas ajuste as expectativas. Seu SLO de disponibilidade será limitado pela rede elétrica e hardware único. Foque em SLOs de latência e, principalmente, SLOs de backup (RPO/RTO). Exemplo: "99% dos backups diários devem ser concluídos com sucesso em menos de 2 horas".
Referências & Leitura Complementar
Google SRE Book: Chapter 4 - Service Level Objectives. Disponível online.
NVM Express Base Specification: Para entender os limites físicos e comandos de admin que afetam a latência.
Backblaze Drive Stats: Dados reais de falhas de HDDs para ajudar no cálculo de durabilidade teórica.
RFC 9293 (TCP): Fundamental para entender latências induzidas por retransmissões de rede em storage distribuído (iSCSI/NFS).

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."