SLOs de latência em storage NVMe: blindando contratos e garantindo performance

Guia definitivo para Gerentes de Nível de Serviço: como definir SLOs de latência em NVMe, evitar a armadilha da média e calcular o ROI real da infraestrutura.
A latência é o assassino silencioso da infraestrutura moderna. Enquanto a disponibilidade (uptime) recebe toda a glória nos painéis executivos, é a latência que dita a experiência do usuário e a viabilidade transacional. Em um ambiente de armazenamento NVMe, onde o hardware promete respostas na casa dos microssegundos, aceitar métricas genéricas é um ato de negligência administrativa.
Como Gerente de Nível de Serviço, afirmo: um contrato que garante "alta performance" sem definir numericamente o que isso significa é apenas um pedaço de papel caro. Não estamos mais na era dos discos mecânicos onde 10ms era aceitável. Estamos na era do NVMe, onde qualquer desvio acima de 1ms deve ser tratado como um incidente crítico.
Resumo em 30 segundos
- A média mente: Monitorar latência média em discos NVMe mascara picos de lentidão que travam bancos de dados e frustram usuários.
- Foco na cauda: A única métrica que reflete a realidade da dor do usuário é a latência de cauda (P99 e P99.9).
- Contratos blindados: SLAs sem penalidades atreladas a SLOs de latência específicos são inúteis para garantir performance de I/O.
A correlação direta entre latência e receita
Existe uma linha tênue entre um sistema funcional e um prejuízo financeiro, e essa linha é medida em milissegundos. Em cenários de High-Frequency Trading (HFT) ou grandes plataformas de e-commerce, o armazenamento é o gargalo final. Se o seu array All-Flash NVMe engasga, o banco de dados entra em lock, a aplicação na ponta aguarda e o cliente abandona o carrinho.
O custo do I/O Wait não é apenas técnico; é orçamentário. Servidores de computação de última geração, com CPUs de 64 núcleos e terabytes de RAM, tornam-se pesos de papel caríssimos enquanto aguardam o subsistema de disco confirmar a gravação de um bloco de dados.
💡 Dica Pro: Ao desenhar sua arquitetura, calcule o "Custo de Espera". Se seus núcleos de CPU passam 20% do tempo em iowait devido a um storage lento, você está jogando fora 20% do seu investimento em licenciamento de software (como Oracle ou SQL Server) e hardware de computação.
A ilusão estatística da latência média
A métrica mais perigosa em um relatório de performance de storage é a "Latência Média". Ela é uma ferramenta de ofuscação usada por fornecedores para esconder a instabilidade de seus produtos.
Imagine um disco NVMe que processa 99 requisições a 0.1ms (excelente) e 1 requisição a 100ms (catastrófico). A média seria aproximadamente 1.1ms. O relatório dirá que o sistema está "saudável". No entanto, para a aplicação que pegou aquela requisição de 100ms, o sistema travou.
Em ambientes NVMe, a variação é o inimigo. Dispositivos de estado sólido sofrem com processos internos como Garbage Collection e Wear Leveling. Se o controlador do SSD não for de classe empresarial e não tiver poder de processamento suficiente para gerenciar essas tarefas em segundo plano sem impactar o I/O de frente, você terá picos de latência. A média esconderá esses picos; o usuário final não.
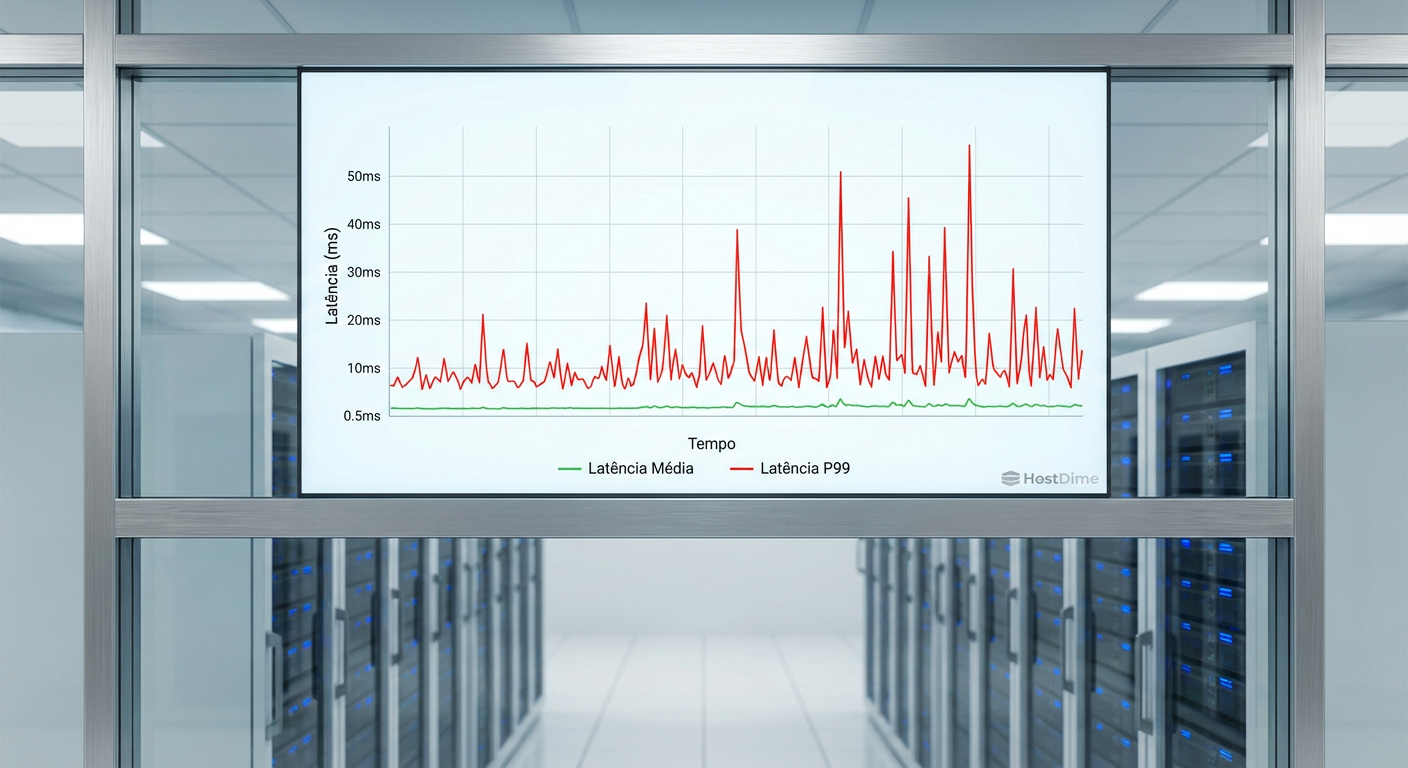 Figura: Gráfico comparativo demonstrando como a latência média (linha verde estável) mascara os picos críticos de latência de cauda P99 (linha vermelha instável) que afetam a operação.
Figura: Gráfico comparativo demonstrando como a latência média (linha verde estável) mascara os picos críticos de latência de cauda P99 (linha vermelha instável) que afetam a operação.
O desperdício de CAPEX em hardware subutilizado
Adquirir um storage array NVMe ou NVMe-oF (over Fabrics) é um investimento massivo de capital (CAPEX). A promessa é eliminar gargalos. Contudo, sem um Gerenciamento de Nível de Serviço rigoroso, esse hardware opera frequentemente muito abaixo de sua capacidade nominal, ou pior, entrega performance inconsistente.
O problema reside na falta de alinhamento entre a configuração do host e a capacidade do storage. Filas de comando (Queue Depth) mal configuradas no sistema operacional podem sufocar um disco NVMe capaz de centenas de milhares de IOPS.
Se você paga por um hardware capaz de entregar 100µs (microssegundos) de latência, mas sua rede de armazenamento (SAN) ou seus drivers introduzem 2ms de atraso, você transformou um investimento em NVMe em uma experiência de SSD SATA, pagando o triplo do preço. O SLO deve cobrir a latência end-to-end, do iniciador ao alvo.
Implementação de SLOs baseados em percentis P99
Para garantir a integridade transacional e a satisfação real, devemos abandonar as médias e adotar os percentis. O SLO (Service Level Objective) deve ser definido com base na "Latência de Cauda" (Tail Latency).
O que é P99?
O percentil 99 (P99) significa que 99% das suas requisições são mais rápidas que determinado valor. Ele foca no 1% mais lento. É nesse 1% que residem os timeouts, os erros de aplicação e as reclamações de usuários.
Exemplo de SLO Robusto para NVMe:
Métrica: Latência de Leitura Aleatória 4K.
Alvo P50 (Mediana): < 0.2ms (Indicador de saúde geral).
Alvo P99 (Cauda): < 1.0ms (Indicador de estabilidade).
Janela de Medição: 5 minutos.
Se o seu P99 subir para 5ms, você tem um problema grave, mesmo que a média permaneça em 0.2ms. Monitorar o P99 obriga a equipe técnica a investigar micro-gargalos, saturação de portas ou contenção de controladores que passariam despercebidos.
Tabela Comparativa: Métricas de Monitoramento
| Métrica | O que mede | Utilidade para NVMe | Risco de Mascaramento |
|---|---|---|---|
| Média (Avg) | Soma das latências / total de I/O | Baixa. Útil apenas para tendências de longo prazo. | Extremo. Esconde todos os problemas transientes. |
| P50 (Mediana) | O valor central da distribuição | Média. Melhor que a média aritmética, mas ignora extremos. | Alto. Ignora a metade mais lenta das requisições. |
| P95 | O limite dos 5% mais lentos | Alta. Padrão da indústria para a maioria das aplicações. | Moderado. Ainda permite 5% de degradação. |
| P99 / P99.9 | O limite do 1% ou 0.1% mais lento | Crítica. Essencial para bancos de dados e aplicações real-time. | Baixo. Revela a verdadeira estabilidade do storage. |
| Pico (Max) | A única requisição mais lenta | Diagnóstica. Útil para root cause analysis. | N/A. Pode ser um outlier isolado sem impacto sistêmico. |
Blindagem contratual e penalidades
Como especialista em ITIL, minha função é traduzir a necessidade técnica em garantia jurídica. Um SLA (Service Level Agreement) de armazenamento que promete apenas "Disponibilidade de 99.999%" é insuficiente. O storage pode estar "disponível" (respondendo a pings), mas com uma latência de 500ms, tornando-o inútil para a operação.
Cláusulas Obrigatórias
Seus contratos com provedores de nuvem (IaaS) ou fornecedores de datacenter devem incluir:
Definição de Latência Máxima Aceitável: Especifique o valor em milissegundos para o percentil P99.
Janela de Apuração: Evite médias mensais. A latência deve ser apurada em janelas curtas (ex: 5 ou 15 minutos). Se o storage ficar lento por 2 horas durante a Black Friday, a média mensal não será afetada, mas seu negócio será destruído.
Penalidades Progressivas: O descumprimento do SLO de latência deve gerar créditos de serviço ou multas financeiras tão agressivas quanto as de indisponibilidade total.
⚠️ Perigo: Muitos provedores de nuvem oferecem discos "Burst". Eles garantem performance apenas por curtos períodos. Para cargas de trabalho críticas, exija discos com IOPS provisionados (Provisioned IOPS) e latência garantida em contrato, sem mecanismos de burst que se esgotam.
Veredito Técnico
Não gerencie sua infraestrutura de armazenamento baseando-se em esperança ou em métricas de vaidade. A latência média é uma mentira estatística que conforta gerentes, mas não resolve problemas de produção.
A adoção de SLOs baseados em P99 e P99.9 é o único caminho para extrair o valor real do investimento em NVMe. Se o seu contrato não prevê penalidades por violação de latência de cauda, você não tem um acordo de nível de serviço; você tem apenas uma declaração de boas intenções. E no mundo corporativo, boas intenções não garantem a integridade dos dados nem a satisfação do cliente. Audite, meça os extremos e blinde seus contratos.
Perguntas Frequentes (FAQ)
Qual a diferença técnica e jurídica entre SLA e SLO em contratos de storage?
O SLO (Service Level Objective) é a meta técnica interna e precisa (ex: latência de gravação < 1ms em 99.9% das requisições). Já o SLA (Service Level Agreement) é o instrumento contratual externo que formaliza o compromisso com o cliente, definindo as penalidades financeiras e jurídicas caso o SLO não seja atingido. Sem um SLO claro, o SLA é inaplicável.Por que a latência média é considerada uma métrica enganosa para discos NVMe?
A média aritmética suaviza e esconde os picos de latência (outliers). Em um disco NVMe, uma média "bonita" de 0.5ms pode ocultar milhares de requisições lentas de 50ms ou mais. Esses picos são invisíveis na média, mas são exatamente eles que causam travamentos em bancos de dados e derrubam aplicações críticas.O que é latência de cauda (Tail Latency) e qual sua relevância crítica?
Latência de cauda refere-se ao comportamento das requisições mais lentas do seu sistema (o 1% ou 0.1% pior, medido estatisticamente como P99 ou P99.9). Em sistemas de alta escala, controlar a cauda é vital, pois ela dita a experiência do usuário final nos momentos de maior carga. Se a cauda é longa, a percepção de lentidão é generalizada, mesmo que a maioria das requisições seja rápida.
Arthur Sales
Gerente de Nível de Serviço
"Vivo na linha tênue entre a conformidade e a violação contratual. Para mim, 99,9% não é disponibilidade; é prejuízo. Exijo garantias absolutas e aplicação rigorosa de penalidades."