Snapshots Não São Backup: O Checklist de Sobrevivência Contra Ransomware Moderno

Descubra por que confiar apenas em snapshots é fatal. Aplique a regra 3-2-1, entenda RPO vs. RTO e blinde sua infraestrutura com este checklist de recuperação.
Se você dorme tranquilo porque o seu storage array tira snapshots de hora em hora, eu tenho uma notícia urgente: você não tem um backup, você tem uma conveniência. E no mundo da recuperação de desastres (DR), conveniência e segurança raramente andam de mãos dadas.
Como operador focado em continuidade de negócios, aprendi uma verdade dura: o backup não existe. O que existe é o Restore. O backup é apenas o meio para um fim; se o restore falhar, todo o investimento, tempo e hardware são irrelevantes. E é aqui que a confusão entre snapshot e backup se torna fatal. Em um ataque de ransomware moderno, confiar em snapshots como sua única linha de defesa é o equivalente digital a trancar a porta da frente e deixar a chave embaixo do tapete.
Neste artigo, vamos desmantelar a ilusão de segurança do storage primário e estabelecer um checklist de sobrevivência baseado na única lei que importa: a regra 3-2-1.
O Cenário de Perda: A Ilusão da Segurança no Storage Primário
Imagine o cenário: são 03:00 da manhã de um sábado. O monitoramento dispara. Seus volumes principais estão criptografados. Sua primeira reação? "Sem problemas, vou reverter para o snapshot das 02:00". Você loga no console do storage e descobre o horror: os snapshots também sumiram ou estão criptografados.
Por que isso acontece? Tecnicamente, um snapshot não é uma cópia independente dos dados. Seja via Copy-on-Write (CoW) ou Redirect-on-Write (RoW), o snapshot é dependente da estrutura de blocos do disco original. Ele é um mapa de ponteiros, não um bunker de dados.
Se o array de armazenamento falhar (falha de controladora, corrupção de firmware ou desastre físico), o snapshot morre junto com o volume de produção. Mas o cenário de ransomware é ainda mais insidioso. Os atacantes modernos não apenas criptografam arquivos; eles buscam credenciais administrativas. Uma vez dentro da rede de gerenciamento, a primeira ação do script de ataque é enviar comandos de deleção de snapshots ou criptografar o próprio volume em nível de bloco, inutilizando a tabela de alocação que sustenta os snapshots.
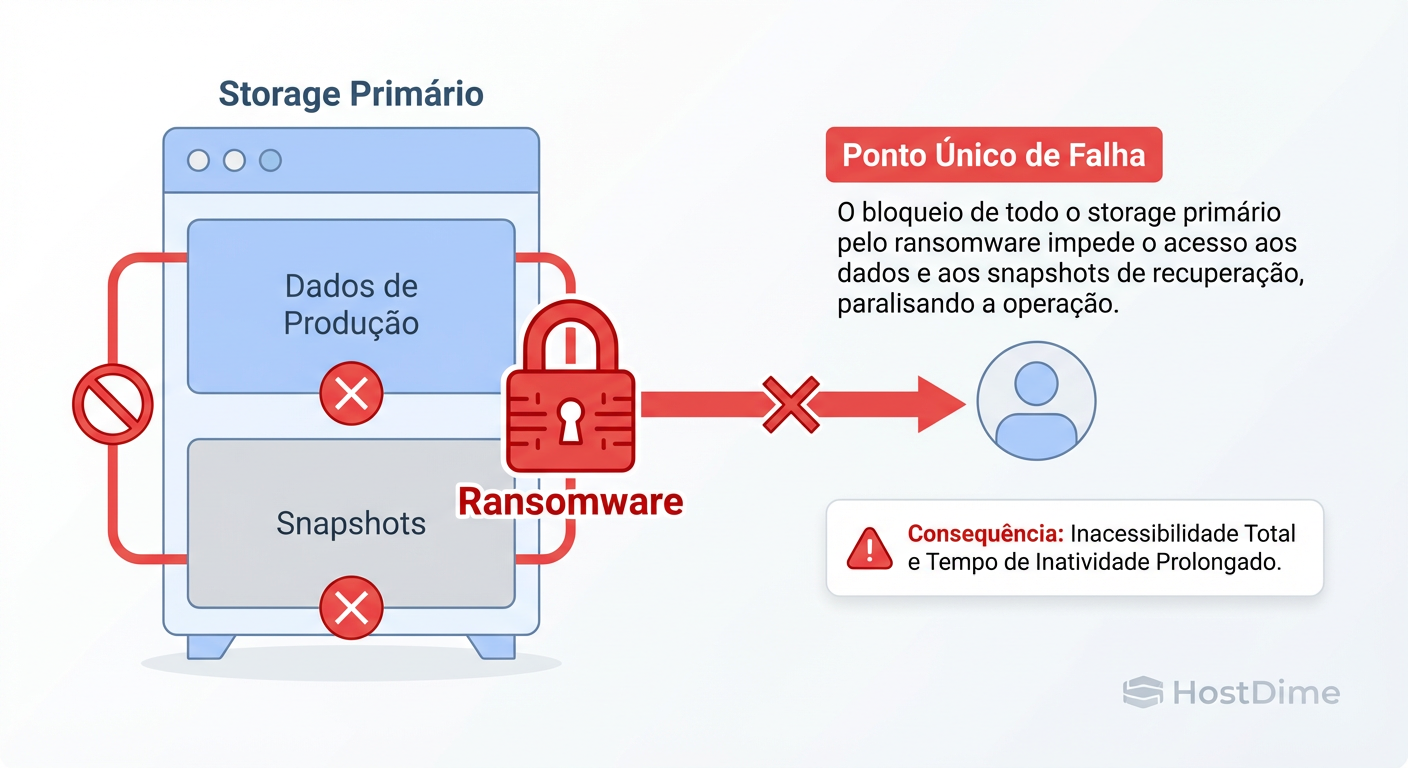 Figura: Fig. 1: O Ciclo da Falha - Quando o ransomware ataca o volume, o snapshot local é criptografado junto.
Figura: Fig. 1: O Ciclo da Falha - Quando o ransomware ataca o volume, o snapshot local é criptografado junto.
A Figura 1 acima ilustra este ciclo da falha. O snapshot reside no mesmo "domínio de falha" que o dado original. Se o dado original é comprometido estruturalmente, o snapshot perde sua referência. Segurança real exige isolamento, algo que o snapshot, por design, não possui.
Estratégia 3-2-1: Por que Snapshots Falham na Matemática da Recuperação
A regra de ouro, repetida à exaustão por mentores como W. Curtis Preston e evangelistas da Veeam, é a Regra 3-2-1. Ela não é uma sugestão; é uma necessidade matemática para garantir a recuperabilidade. Vamos revisitar a regra e ver onde os snapshots falham:
3 Cópias dos Dados: Você deve ter o dado primário e duas cópias adicionais.
2 Mídias Diferentes: As cópias devem residir em tipos de mídia ou sistemas de armazenamento distintos para evitar falhas de hardware comuns.
1 Cópia Offsite: Uma cópia deve estar fora do local físico principal (nuvem, fita, ou DR site).
Onde o Snapshot se Encaixa (ou falha)
Quando você confia apenas em snapshots, sua pontuação na regra 3-2-1 é perigosa:
Cópias: Você tem, tecnicamente, apenas variações da mesma cópia física (os blocos no disco).
Mídia: Tudo está no mesmo array de discos (mesmo firmware, mesma alimentação elétrica).
Offsite: Zero. Se o datacenter pegar fogo, seus dados e seus snapshots viram cinzas juntos.
Para visualizar a diferença crítica, observe a comparação abaixo:
| Característica | Snapshot de Storage | Backup Real |
|---|---|---|
| Dependência | Depende do volume original para existir. | Autossuficiente e independente da fonte. |
| Localização | Mesmo hardware (geralmente). | Hardware separado ou Nuvem. |
| Portabilidade | Proprietário do vendor do storage. | Agnóstico (pode ser restaurado em outro hardware). |
| Objetivo | RPO/RTO baixo (Curto Prazo). | Retenção, Compliance e DR (Longo Prazo). |
| Resiliência | Ponto Único de Falha (SPoF). | Redundante por natureza. |
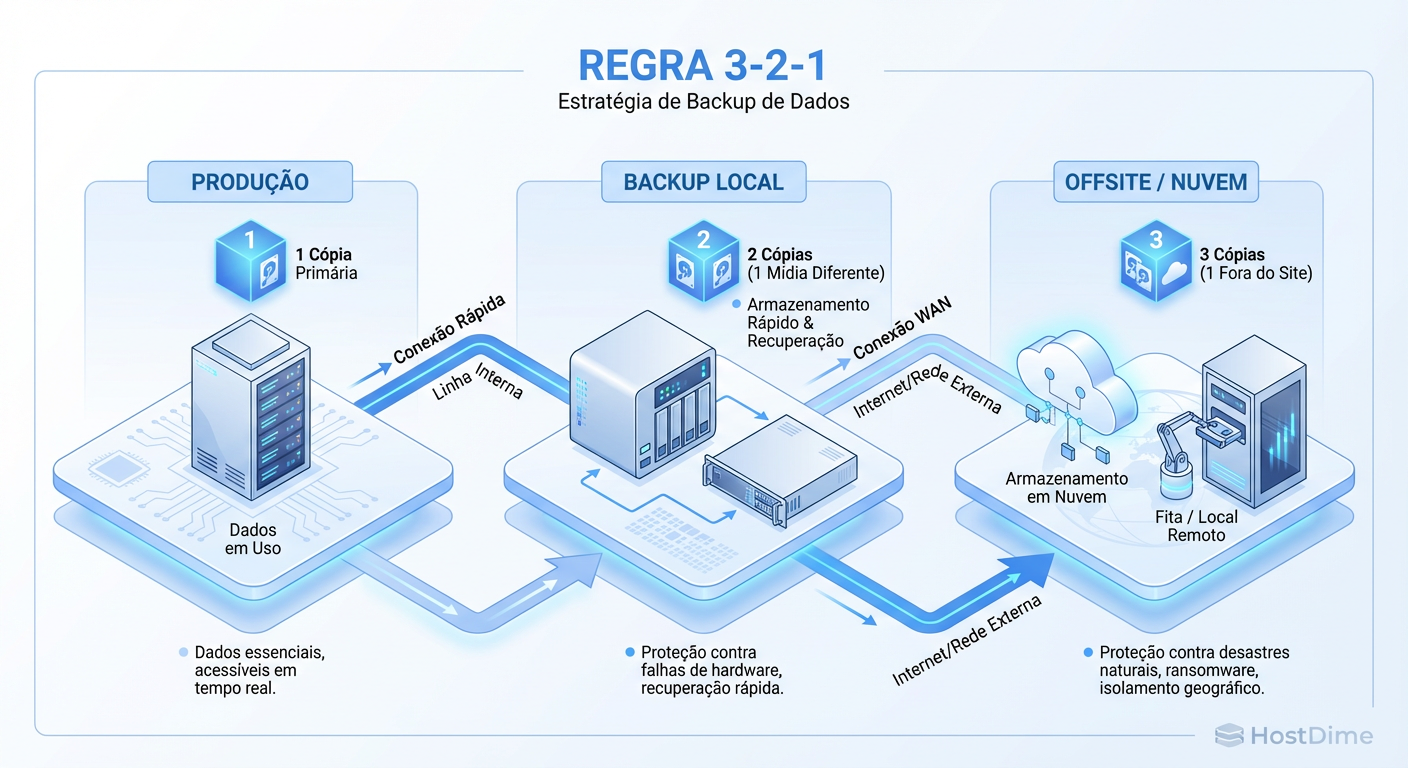 Figura: Fig. 2: A Arquitetura 3-2-1 - A única topologia que garante a sobrevivência dos dados.
Figura: Fig. 2: A Arquitetura 3-2-1 - A única topologia que garante a sobrevivência dos dados.
A Figura 2 demonstra a arquitetura correta. O snapshot é excelente para reverter um arquivo deletado acidentalmente por um usuário às 14:00, mas ele é incapaz de salvar a empresa de um desastre real. O Backup, movendo dados para um repositório secundário e terciário, garante a sobrevivência.
Janela de Backup vs RPO: A Diferença entre Disponibilidade e Retenção
Não me entenda mal: eu adoro snapshots. Eles são ferramentas vitais para Disponibilidade Operacional, mas não para Retenção de Dados.
Aqui precisamos distinguir dois conceitos que confundem muitos gestores de TI:
Janela de Backup: O tempo necessário para mover os dados da produção para o repositório de proteção.
RPO (Recovery Point Objective): O máximo de dados que a empresa aceita perder (medido em tempo).
Snapshots são reis no RPO. Você pode tirar snapshots a cada 15 minutos com impacto quase zero na performance. Tentar fazer um backup full ou mesmo incremental a cada 15 minutos em grandes volumes de dados pode saturar a rede e degradar a performance do servidor (o famoso "stun" da VM).
A estratégia vencedora é a integração. Utilize snapshots para cobrir o RPO de curto prazo (últimas 24 horas) e utilize o software de backup para extrair esses dados para um repositório seguro (backup from storage snapshot), sem estressar a VM de produção.
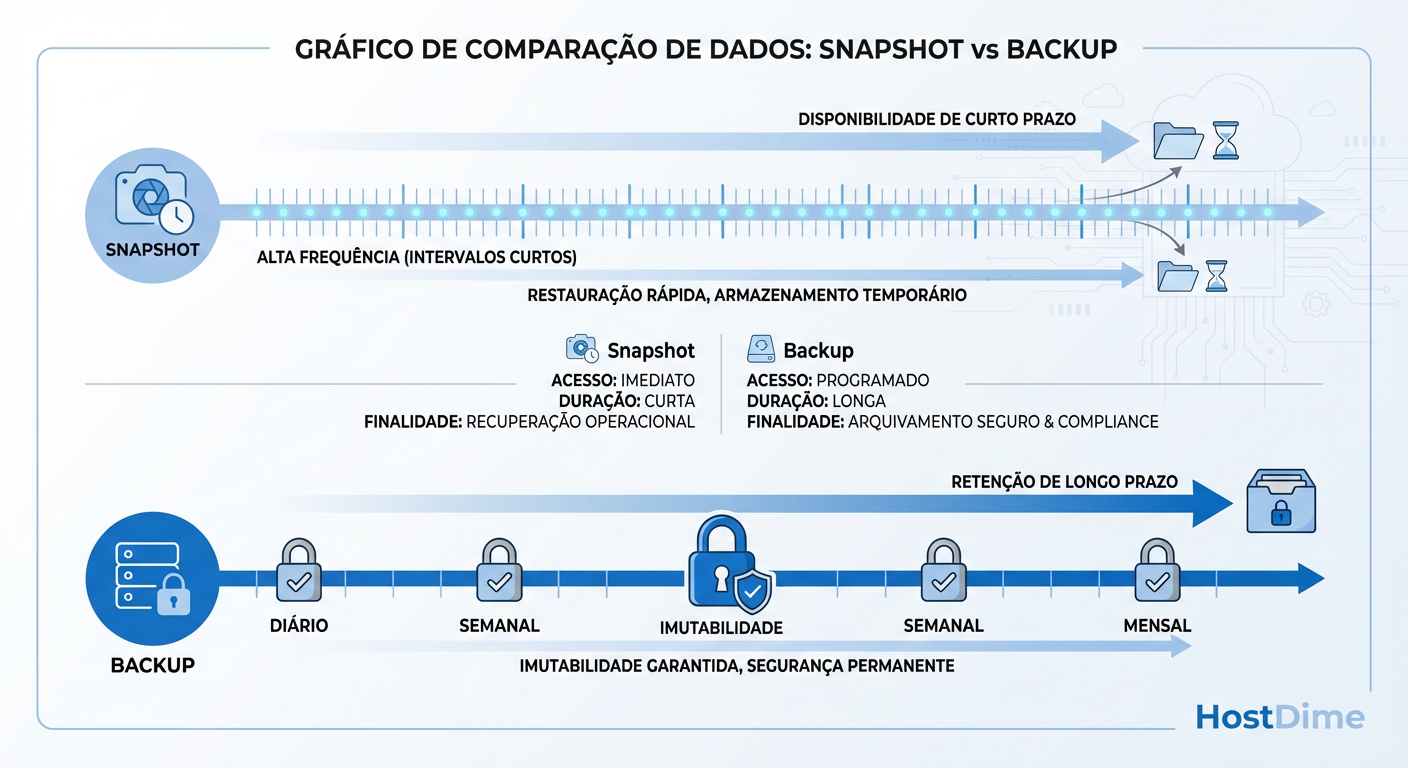 Figura: Fig. 3: Disponibilidade vs. Recuperabilidade - O papel de cada tecnologia na linha do tempo.
Figura: Fig. 3: Disponibilidade vs. Recuperabilidade - O papel de cada tecnologia na linha do tempo.
Como mostra a Figura 3, o snapshot preenche a lacuna imediata, mas perde utilidade e segurança conforme o tempo passa. O backup assume a responsabilidade pela retenção histórica e pela segurança contra desastres. Se você está guardando snapshots por 30, 60 dias no storage primário, você está transformando seu array de alta performance em um arquivo morto caro e arriscado.
Teste de Restore: O 'Backup de Schrödinger' e a Validação Obrigatória
Existe um fenômeno que eu chamo de Backup de Schrödinger: até que você tente restaurar, o backup está simultaneamente em um estado de sucesso e de falha. A maioria das empresas só descobre que o backup estava corrompido no momento da crise.
Um print de tela do console de backup mostrando "Job Successful" com um ícone verde não é prova de recuperabilidade. Ele apenas prova que o software leu os bits e os escreveu em outro lugar. Ele não prova que o sistema operacional vai bootar, que o banco de dados vai montar ou que a aplicação está íntegra.
O Checklist de Validação de Restore
Para sair da zona de "fé" e entrar na zona de "certeza", você precisa de automação. Ferramentas modernas (como o Veeam DataLabs ou SureBackup) permitem ligar as VMs de backup em um ambiente isolado e rodar testes reais.
Se você é um engenheiro responsável, seu processo deve incluir scripts de validação. Abaixo, um exemplo conceitual do que uma validação automatizada deve verificar:
# Exemplo conceitual de fluxo de validação automatizada (Pseudo-código)
function Verify-BackupIntegrity {
param ($VMName, $RestorePoint)
# 1. Boot da VM em Sandbox (Rede Isolada)
Start-VMSandbox -Name $VMName -Source $RestorePoint
# 2. Teste de Heartbeat (O OS subiu?)
if (Test-VMHeartbeat -Name $VMName) {
Write-Log "OS Boot: SUCESSO"
} else {
Throw-Error "OS Boot: FALHA - Backup Corrompido"
}
# 3. Teste de Aplicação (Ex: SQL Server responde na porta 1433?)
$PortCheck = Test-NetConnection -ComputerName $VMName -Port 1433
if ($PortCheck.TcpTestSucceeded) {
# 4. Query de Teste (O banco está legível?)
Invoke-SqlCmd -Query "SELECT count(*) FROM CriticalTable"
Write-Log "Aplicação: SUCESSO"
}
# 5. Desligar e Limpar
Stop-VMSandbox -Name $VMName -Cleanup $true
}
Se você não está fazendo isso automaticamente, você deve fazer manualmente por amostragem. Um backup não testado é apenas um arquivo grande ocupando espaço.
Plano de Desastre: Imutabilidade, Air-Gap e o Checklist Final
Chegamos à defesa final. O ransomware moderno é projetado para caçar seus repositórios de backup e deletá-los antes de criptografar a produção. Se o seu servidor de backup está no mesmo domínio do Active Directory que a produção, e seus discos de backup são volumes NTFS/ReFS padrão montados nesse servidor, você já perdeu.
A Evolução para o 3-2-1-1-0
A regra 3-2-1 evoluiu. Hoje, pregamos o 3-2-1-1-0:
1 Cópia Imutável/Offline: Dados que não podem ser alterados ou deletados, nem mesmo pelo administrador (Immutability) ou que estão fisicamente desconectados (Air-Gap).
0 Erros: Verificação automatizada de recuperação (como discutido acima).
Imutabilidade (Hardened Repositories)
Utilize repositórios Linux com a flag de imutabilidade ativada (via XFS) ou Object Storage (S3) com Object Lock. Isso garante que, mesmo que um hacker obtenha credenciais de root, ele receberá um "Access Denied" ao tentar deletar os blocos de backup antes do período de retenção expirar.
Air-Gap
A fita (LTO) ainda é a rainha do Air-Gap. Uma fita em um cofre não pode ser hackeada via IP. Se fita não é uma opção, considere um "Air-Gap lógico", onde a conta que acessa o storage na nuvem não tem permissão de deleção e não está conectada à rede corporativa.
O Checklist Final de Sobrevivência
Antes de fechar este artigo e voltar para o seu console, verifique sua infraestrutura contra esta lista:
Snapshots não são sua única cópia: Você tem uma cópia secundária em mídia diferente?
Regra 3-2-1 aplicada: Você tem dados offsite?
Isolamento de Credenciais: O servidor de backup não está no domínio principal.
Imutabilidade: Pelo menos uma cópia dos dados é imutável (WORM).
Testes de Restore: Você testou um restore crítico no último mês?
Documentação: Você tem um PDF (impresso!) com os passos de recuperação caso o AD e o vCenter não existam mais.
Lembre-se: no dia do desastre, ninguém vai perguntar quão rápido eram seus snapshots. Vão perguntar se você consegue trazer a empresa de volta à vida. Seja paranoico. Teste tudo. Confie apenas no restore.
Referências
CISA (Cybersecurity and Infrastructure Security Agency). "Data Backup Options". Security Tip (ST15-001). Disponível em: cisa.gov.
NIST (National Institute of Standards and Technology). "NIST SP 800-34 Rev. 1: Contingency Planning Guide for Federal Information Systems".
Veeam Software. "The 3-2-1-1-0 Rule: The new standard for data protection". Whitepaper técnico.
SNIA (Storage Networking Industry Association). "Snapshot Technologies: An Overview". Technical Tutorial.

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."