Sobrevivendo ao Custo da NAND: Arquitetura de Storage Eficiente para Workloads de IA

Com a alta dos preços de SSDs em 2025, escalar infraestrutura de IA exige engenharia, não apenas compras. Descubra como Zoned Namespaces (ZNS) e GPUDirect Storage salvam seu TCO.
A corrida pelo ouro da Inteligência Artificial criou uma distorção perigosa no mercado de infraestrutura. Enquanto CIOs e arquitetos brigam por alocações de GPUs H100 ou Blackwell, um componente crítico é frequentemente tratado como commodity secundária: o subsistema de armazenamento.
A realidade brutal de um cluster de treinamento de IA é que a GPU é um processador faminto que não tolera espera. Se o seu storage não consegue entregar batches de dados na velocidade do clock da GPU, você não está economizando em disco; você está desperdiçando o recurso mais caro do seu data center. O custo real do storage em IA não é o preço por Terabyte, mas o custo da ociosidade da GPU causada pela latência de I/O.
Resumo em 30 segundos
- Ociosidade Custa Caro: Uma infraestrutura de storage subdimensionada pode deixar GPUs de $30.000 ociosas por até 30% do tempo de treinamento, destruindo o ROI.
- O Perigo do Checkpoint: O padrão de escrita massiva e síncrona dos checkpoints de LLMs (Large Language Models) pulveriza a durabilidade (DWPD) de SSDs de consumo ou QLC mal arquitetados.
- Protocolos Importam: Apenas adicionar mais discos não resolve. Tecnologias como GPUDirect Storage e Zoned Namespaces (ZNS) são essenciais para remover a CPU do caminho crítico de dados.
O gargalo silencioso que deixa GPUs ociosas
Em arquiteturas tradicionais, o fluxo de dados do disco para a GPU é uma via crucis de cópias de memória. O dado sai do NVMe, vai para a memória do sistema (RAM) via CPU, sofre trocas de contexto e só então é copiado para a VRAM da GPU.
Para cargas de trabalho convencionais, como bancos de dados transacionais, isso é aceitável. Para o treinamento de modelos com trilhões de parâmetros, é catastrófico. O fenômeno conhecido como GPU Starvation ocorre quando a unidade de processamento gráfico termina um cálculo e precisa esperar milissegundos — uma eternidade em tempo de silício — pelo próximo lote de dados.
 Figura: O caminho crítico dos dados: a eliminação do "bounce buffer" da CPU é vital para manter a saturação da GPU.
Figura: O caminho crítico dos dados: a eliminação do "bounce buffer" da CPU é vital para manter a saturação da GPU.
💡 Dica Pro: Monitore a métrica
GPU-Utilem correlação comIOWait. Se você vê serrilhados no gráfico de uso da GPU (picos de 100% seguidos de vales de 0%) sincronizados com picos de leitura de disco, seu storage é o gargalo, não o código CUDA.
A física do desgaste: Checkpointing e a morte da célula flash
O treinamento de IA não é apenas leitura intensiva. É aqui que muitos projetos falham ao especificar drives QLC (Quad-Level Cell) focados apenas em densidade de leitura para Data Lakes.
Durante o treinamento de um LLM, o sistema realiza checkpoints periódicos — salvando o estado completo dos pesos do modelo para evitar a perda de semanas de processamento em caso de falha. Isso gera uma rajada de escrita sequencial massiva e simultânea em todos os nós do cluster.
O problema da Amplificação de Escrita (WAF)
Em SSDs convencionais, o Garbage Collection (GC) luta para organizar esses dados. Se o drive estiver cheio, o controlador precisa mover dados existentes para liberar blocos antes de escrever os novos. Isso aumenta o Write Amplification Factor (WAF). Um WAF alto significa que para cada 1GB de dados que você envia, o SSD escreve internamente 3GB ou 4GB, desgastando a camada de óxido da célula NAND prematuramente.
⚠️ Perigo: Utilizar SSDs com baixo DWPD (Drive Writes Per Day) para a camada de scratch ou checkpoint é suicídio financeiro. Vi projetos queimarem arrays inteiros de SSDs "Read Intensive" em menos de 6 meses devido à carga de escrita dos checkpoints.
A armadilha de combater latência com hardware de consumo
É tentador olhar para um SSD NVMe Gen5 de consumo, como os topos de linha da Samsung ou Western Digital, e ver números como "14.000 MB/s" por uma fração do preço de um drive Enterprise U.2 ou E1.S.
No entanto, esses números são sustentados por caches SLC (Single-Level Cell) dinâmicos. O drive trata uma pequena porção da sua capacidade como memória rápida. Assim que esse cache enche — o que acontece em segundos durante um checkpoint de 500GB — a performance cai de um penhasco, muitas vezes para velocidades inferiores a de um HDD SATA antigo.
Além disso, drives de consumo carecem de capacitores de proteção contra perda de energia (PLP) e têm latências de cauda (tail latency) imprevisíveis. Em um cluster distribuído, se um único drive engasgar, todo o treinamento (que é síncrono entre as GPUs) para e espera.
Tabela Comparativa: Enterprise vs. Consumo em IA
| Característica | SSD NVMe Consumo (High-End) | SSD NVMe Enterprise (Data Center) | Impacto na IA |
|---|---|---|---|
| Performance Sustentada | Cai drasticamente após cache SLC encher | Consistente até encher o drive | Checkpoints rápidos vs. travamento do cluster |
| Latência de Cauda (99.9%) | Imprevisível (>10ms sob carga) | Determinística (<200µs) | Evita que uma GPU lenta atrase todas as outras |
| Endurance (DWPD) | Geralmente 0.3 a 0.6 | 1 a 3 (ou mais) | Longevidade do hardware sob escrita intensa |
| Form Factor | M.2 (Térmica ruim) | U.2 / E1.S / E3 (Dissipação superior) | Evita thermal throttling em servidores densos |
Engenharia de precisão: ZNS e GPUDirect
Para mitigar esses problemas sem explodir o orçamento comprando apenas memória Optane ou SLC nativa, precisamos de inteligência no software e no protocolo.
GPUDirect Storage (GDS)
Desenvolvido pela NVIDIA, o GDS permite que a placa de rede e o storage conversem diretamente via PCIe (DMA - Direct Memory Access), ignorando a CPU. Isso não apenas reduz a latência, mas libera a CPU para tarefas de pré-processamento de dados e orquestração, que são vitais em pipelines complexos.
Zoned Namespaces (ZNS)
O ZNS é uma mudança de paradigma padronizada pela organização NVMe. Em vez de deixar o SSD adivinhar onde colocar os dados (o que causa o WAF mencionado anteriormente), o host (sistema operacional/aplicação) escreve dados sequencialmente em "zonas" pré-alocadas.
Isso elimina a necessidade de Garbage Collection agressivo no drive, reduzindo a amplificação de escrita para quase 1:1. O resultado é um aumento na vida útil do SSD e, crucialmente, uma latência de escrita muito mais previsível, pois o drive não "congela" para arrumar a casa no meio de um checkpoint.
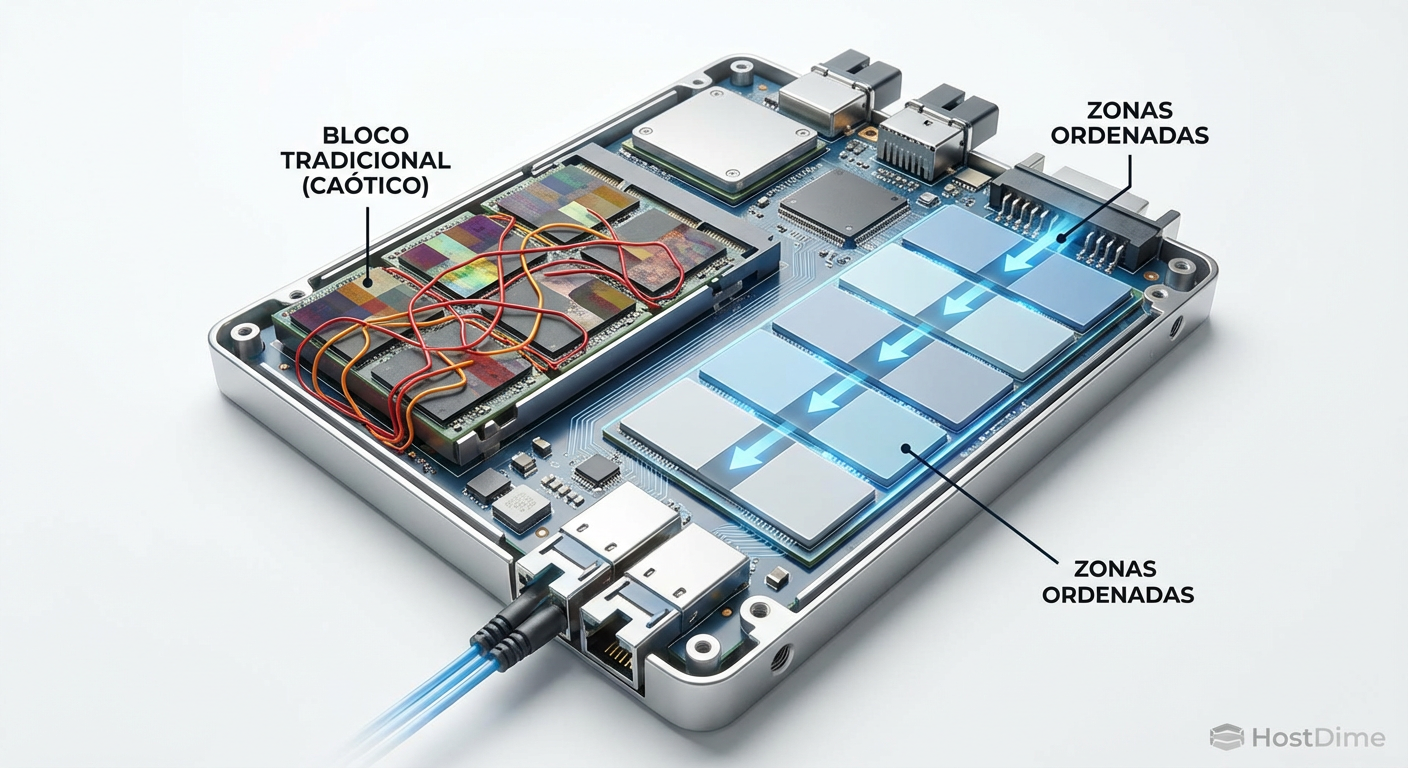 Figura: Zoned Namespaces (ZNS): Organizando a escrita física para eliminar a imprevisibilidade do Garbage Collection.
Figura: Zoned Namespaces (ZNS): Organizando a escrita física para eliminar a imprevisibilidade do Garbage Collection.
Validando o ROI através da saturação
A métrica final de sucesso para um arquiteto de storage em IA não é "IOPS", mas "Custo por Época de Treinamento".
Se você investe em um tier de armazenamento All-Flash NVMe Gen5 de alta durabilidade, o custo inicial (CapEx) é alto. Porém, se esse storage permite que suas GPUs completem o treinamento 20% mais rápido porque não estão esperando por dados, o custo total (TCO) despenca. A energia elétrica e a depreciação das GPUs são custos muito maiores do que a diferença de preço entre um SSD SATA e um NVMe Enterprise.
Estratégia de Tiering Híbrido
A abordagem mais equilibrada que tenho visto em campo envolve:
Hot Tier (Checkpoint/Scratch): NVMe Gen4/Gen5 de Alta Resistência (3+ DWPD) ou CXL Memory. Volume menor, velocidade extrema.
Warm Tier (Dataset de Treino): NVMe QLC Enterprise (focado em leitura). Volume massivo, custo por TB menor, leitura rápida, mas escrita protegida.
Cold Tier (Arquivo/Modelos Velhos): Object Storage (S3) em HDD ou Tape.
 Figura: Arquitetura de Tiering: A alocação correta do dado no tipo de mídia certo é a chave para o equilíbrio econômico.
Figura: Arquitetura de Tiering: A alocação correta do dado no tipo de mídia certo é a chave para o equilíbrio econômico.
Veredito Técnico
Não existe "storage rápido o suficiente" quando o cliente é uma bateria de H100s. O gargalo sempre existirá; nosso trabalho é movê-lo para onde ele custe menos.
Para arquitetos desenhando infraestrutura de IA hoje, a recomendação é clara: parem de tratar storage como capacidade bruta. Priorizem a consistência de latência e a durabilidade de escrita para a camada de ingestão e checkpoint. O uso de tecnologias como ZNS e a implementação correta de GPUDirect não são mais "luxos" de HPC, mas requisitos básicos para garantir que o investimento milionário em computação não se torne um aquecedor de data center muito caro.
Seu CFO vai agradecer quando o tempo de treinamento cair de semanas para dias, mesmo que o custo unitário do drive seja 30% maior.
FAQ: Perguntas Frequentes
QLC é viável para treinamento de IA ou apenas inferência?
Depende do estágio do pipeline. QLC (Quad-Level Cell) Enterprise é excelente para armazenar os datasets de treino (Data Lakes) que sofrem leitura massiva e pouca escrita. No entanto, é catastrófico usá-lo para a área de scratch ou checkpoints, onde a escrita intensiva e a baixa durabilidade (DWPD) degradarão o drive rapidamente. A arquitetura ideal usa tiering híbrido.Qual o impacto real do GPUDirect Storage no uso de CPU?
Em testes de benchmark com cargas reais de Deep Learning, o GPUDirect Storage (GDS) pode reduzir a utilização da CPU em até 45%. Ao eliminar o "bounce buffer" na memória do sistema (RAM), ele permite que a CPU foque em orquestração e pré-processamento, em vez de gastar ciclos apenas copiando endereços de memória.Vale a pena migrar para PCIe 5.0 agora?
Para clusters de treinamento de LLMs de ponta, sim. A largura de banda dobrada (até 14GB/s por drive) é necessária para alimentar GPUs H100/Blackwell sem causar starvation. Contudo, para inferência leve, fine-tuning menor ou bancos de dados convencionais, o ecossistema PCIe 4.0 ainda oferece um custo-benefício (e disponibilidade térmica) superior.Referências & Leitura Complementar
NVIDIA GPUDirect Storage Design Guide: Documentação técnica sobre a implementação de GDS e requisitos de sistema.
NVM Express Zoned Namespace Command Set Specification: Especificação oficial da organização NVM Express detalhando o funcionamento de ZNS.
SNIA (Storage Networking Industry Association): "Real World Workloads: AI/ML Storage Performance" – White papers sobre padrões de I/O em inteligência artificial.
Micron/Samsung Enterprise SSD Datasheets: Comparativos técnicos de DWPD e latência de QoS entre linhas Data Center (ex: Micron 9400/7450) e Consumo.

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."