Split-brain e Quorum: A Arte de Matar Servidores para Salvar Dados

Alta disponibilidade sem fencing é suicídio de dados. Entenda a mecânica do split-brain em storage e como usar STONITH e Chaos Engineering para provar sua resiliência.
A estabilidade é uma mentira confortável que contamos a nós mesmos para dormir à noite. No mundo do armazenamento distribuído, a única verdade absoluta é a entropia. Quando projetamos sistemas de storage, seja um cluster Ceph de petabytes ou um par de TrueNAS em HA (Alta Disponibilidade) no seu rack doméstico, tendemos a focar na redundância dos dados. "Tenho três réplicas, estou seguro", você diz. Errado.
A redundância sem um mecanismo de arbitragem brutal e impiedoso não é segurança; é um convite para a corrupção de dados automatizada. O maior inimigo dos seus dados não é o disco que falha e solta fumaça. O inimigo é o servidor que pensa que está vivo, mas está isolado, escrevendo loucamente em um disco compartilhado como um zumbi digital.
Bem-vindo ao mundo do Split-brain. Aqui, a benevolência destrói dados. A única salvação é a agressividade calculada.
Resumo em 30 segundos
- Disponibilidade vs. Integridade: Em um evento de partição de rede, você deve escolher matar um servidor (perder disponibilidade momentânea) ou permitir escritas divergentes (perder integridade permanentemente).
- A Falácia do Heartbeat: Pulsos de rede apenas informam que a comunicação cessou, não que o outro nó morreu. Um nó "silencioso" pode estar vivo e escrevendo dados.
- STONITH é Amor: "Shoot The Other Node In The Head" não é sadismo; é a única maneira de garantir que um nó isolado não corrompa o pool de armazenamento compartilhado.
O Paradoxo do Observador em Clusters de Armazenamento
Imagine dois servidores de storage, Nó A e Nó B, espelhando dados em tempo real. Eles conversam constantemente via rede. De repente, o silêncio. O Nó A deixa de receber sinais do Nó B.
Aqui reside o paradoxo fundamental da infraestrutura distribuída. Do ponto de vista do Nó A, existem duas possibilidades quânticas sobrepostas:
O Nó B sofreu uma falha catastrófica de hardware e desligou.
O Nó B está perfeitamente saudável, processando dados, mas o cabo de rede entre eles foi cortado (partição de rede).
Se o Nó A assumir a opção 1, mas a realidade for a opção 2, acabamos de entrar em um cenário de Split-brain. Ambos os nós acreditam ser o "Mestre" (Master/Primary). Ambos acreditam ter a autoridade exclusiva para gravar no subsistema de discos (seja um JBOD SAS compartilhado ou um alvo iSCSI).
Em sistemas de arquivos clusterizados como VMFS, OCFS2 ou em orquestradores de ZFS, isso é catastrófico. Se dois controladores montam o mesmo pool ZFS como Read-Write simultaneamente sem saberem um do outro, eles sobrescreverão metadados concorrentes. O resultado não é apenas perda de dados; é a destruição completa da estrutura do sistema de arquivos. O pool vira uma sopa de bits aleatórios.
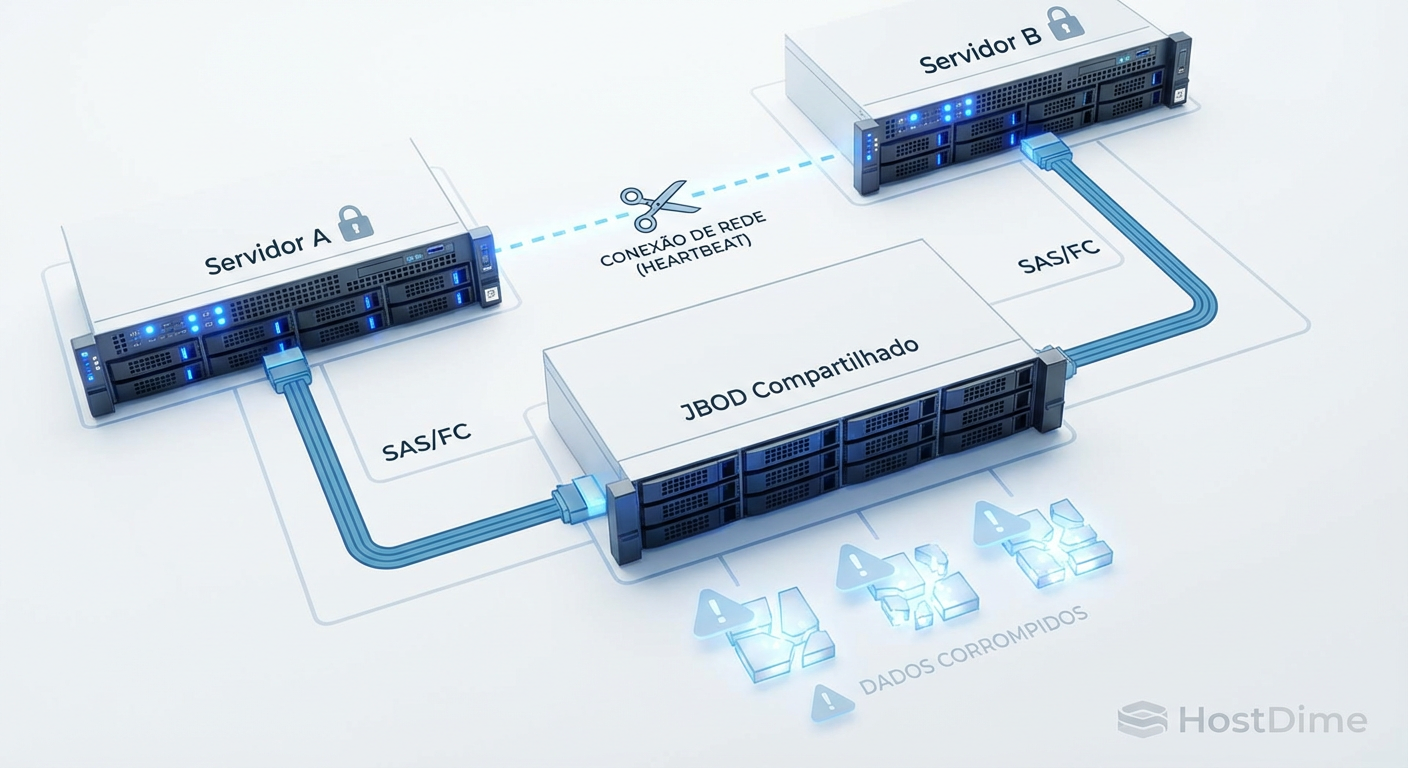 Figura: Anatomia de um desastre: Quando a rede morre, mas o acesso ao disco permanece, a integridade dos dados é a primeira vítima.
Figura: Anatomia de um desastre: Quando a rede morre, mas o acesso ao disco permanece, a integridade dos dados é a primeira vítima.
A Anatomia de uma Corrupção Silenciosa
A corrupção por partição de rede é insidiosa porque, muitas vezes, ela não gera erros de I/O imediatos. O sistema operacional reporta "Sucesso" na gravação.
Vamos dissecar o que acontece em um nível baixo, digamos, em um ambiente iSCSI ou Fibre Channel (FC):
O Corte: O switch de interconexão falha. O Nó A e o Nó B perdem contato.
A Promoção: O software de cluster (ex: Pacemaker/Corosync) em ambos os lados detecta "falha do parceiro" e tenta promover seus recursos locais para Ativo.
A Escrita Divergente: Uma VM conectada ao Nó A grava um bloco no endereço LBA 1000. Uma outra aplicação, que falhou o caminho para o Nó B, grava um dado diferente no mesmo LBA 1000.
O Reencontro: Quando a rede volta, você tem duas versões da verdade. O sistema de arquivos não tem como saber qual bloco é o correto. A consistência lógica foi violada.
⚠️ Perigo: Em arrays All-Flash modernos com deduplicação global, o dano é amplificado. Uma corrupção na tabela de hash de deduplicação causada por split-brain pode invalidar dados que nem estavam sendo acessados naquele momento.
Por que Heartbeats de Rede são Mentirosos
Muitos administradores de homelab ou arquitetos júnior confiam cegamente no "heartbeat" (pulso) de rede. "Se eu não pingo, está morto". Essa é uma suposição fatal.
Um cabo de rede desconectado não desliga a CPU do outro servidor. Um travamento no processo do software de cluster não impede que o kernel continue enviando comandos SCSI para os discos.
O heartbeat responde apenas à pergunta: "Você consegue me ouvir?". Ele falha miseravelmente em responder: "Você ainda está tocando nos meus discos?". Para proteger dados, não precisamos saber se o outro nó está comunicável; precisamos garantir que ele esteja incapaz de agir.
Lei Marcial: Implementando STONITH
Para resolver o paradoxo do observador, precisamos de determinismo. Precisamos de violência sancionada pelo protocolo. Entra em cena o STONITH (Shoot The Other Node In The Head), ou, em termos mais corporativos, Fencing (Cercamento).
Quando um cluster detecta uma inconsistência, a prioridade muda de "manter o serviço no ar" para "garantir que o outro nó esteja morto". Antes de assumir os recursos, o nó sobrevivente deve confirmar o assassinato do nó problemático.
Existem dois métodos principais de aplicar essa lei marcial em storage:
1. Fencing de Energia (Power Fencing)
É o método mais bruto e eficaz. O cluster interage com a PDU (Power Distribution Unit) inteligente ou com a interface IPMI/iDRAC/ILO do servidor falho e corta a energia elétrica.
Vantagem: Funciona mesmo se o kernel do servidor estiver em kernel panic ou travado em um loop zumbi.
Desvantagem: Requer hardware externo gerenciável (PDUs comutáveis).
2. Fencing de Fabric/Storage (SCSI Persistent Reservations)
Aqui a batalha ocorre no próprio protocolo de armazenamento. Usando o padrão SCSI-3 Persistent Reservations (PR), um nó pode registrar uma chave no disco ou LUN.
Se ocorrer uma partição, o nó sobrevivente envia um comando PREEMPT AND ABORT para o dispositivo de armazenamento. Isso revoga a chave do nó falho e instrui o disco a rejeitar qualquer comando de I/O vindo daquele iniciador.
💡 Dica Pro: Se você está montando um cluster de alta disponibilidade com iSCSI ou Fibre Channel, verifique se seu target suporta SCSI-3 PR. Sem isso, seu cluster é apenas uma bomba relógio. Muitos NAS de entrada (SOHO) não implementam isso corretamente.
 Figura: O protocolo da sobrevivência: Como as Reservas Persistentes SCSI isolam um nó zumbi antes que ele cause danos.
Figura: O protocolo da sobrevivência: Como as Reservas Persistentes SCSI isolam um nó zumbi antes que ele cause danos.
O Mecanismo de Quorum: A Tirania da Maioria
Para que o STONITH funcione, precisamos saber quem deve atirar em quem. Se ambos tentarem matar um ao outro simultaneamente, temos um duelo no velho oeste onde ambos morrem e o cluster cai (o que, ironicamente, é melhor para os dados do que ambos sobreviverem).
É aqui que entra o Quorum. Em sistemas distribuídos, números ímpares são divinos.
Cluster de 2 nós: É instável por natureza. Se a rede cai, cada um tem 50% dos votos. Quem manda? Ninguém.
Cluster de 3 nós (ou 2 nós + 1 dispositivo testemunha): Se a rede se divide, um lado terá 2 votos (maioria) e o outro terá 1. O lado com 2 votos ganha o direito de executar o STONITH no lado isolado.
Em storage moderno, como vSAN ou Ceph, o uso de "Witness Nodes" (nós testemunha) ou monitores é obrigatório para desempatar essa disputa.
Injetando Falhas: Validação via Engenharia do Caos
Você configurou seu cluster, habilitou o STONITH e configurou o Quorum. Parabéns. Agora, como você sabe que funciona? Se você nunca testou, não funciona.
Como Engenheiros do Caos, não esperamos o dia ruim chegar. Nós o agendamos para terça-feira de manhã. Aqui está como validar seu mecanismo de fencing:
O Teste da Latência de Cauda: Use ferramentas como
tc(traffic control) no Linux para injetar latência massiva na interface de heartbeat, mas não na interface de dados.- Comando:
tc qdisc add dev eth1 root netem delay 5000ms - Objetivo: Fazer o cluster pensar que o nó morreu, enquanto ele ainda consegue gravar no disco. Se o STONITH não disparar e matar a máquina instantaneamente, seu teste falhou.
- Comando:
O Corte Limpo: Em um ambiente físico, arranque o cabo de rede de interconexão (crossover/switch heartbeat).
- Observação: Monitore os logs do switch SAN ou do array de discos. Você deve ver os comandos de SCSI Reservation Preempt quase instantaneamente.
O Congelamento: Envie um sinal
STOPpara o processo do cluster em um nó (kill -STOP [pid]). Isso simula um servidor que parou de responder mas não fechou as conexões TCP. O nó vizinho deve detectar a falta de atualizações e cercar (fence) o nó congelado.
O Ultimato da Resiliência
A resiliência de dados não é construída sobre a esperança de que o hardware funcione; é construída sobre a certeza de que ele falhará de maneiras bizarras. O Split-brain não é uma anomalia rara; é um estado natural de sistemas complexos que tentam desafiar a física da latência de rede.
Se o seu sistema de armazenamento não possui um mecanismo claro, testado e automatizado para isolar e desligar nós problemáticos (Fencing/STONITH), você não possui Alta Disponibilidade. Você possui apenas uma máquina complexa de corrupção de dados.
Prefira sempre um serviço indisponível (down) a um banco de dados corrompido. O primeiro custa dinheiro e paciência; o segundo custa a existência do seu negócio. Mate os servidores. Salve os dados.
Referências & Leitura Complementar
SCSI Primary Commands - 3 (SPC-3): Especificação oficial que detalha o funcionamento das Persistent Reservations (PR) e os comandos de Preempt and Abort. Essencial para entender fencing em nível de bloco.
RFC 60004 (IETF): Embora focado em IP, os conceitos de detecção de falha bidirecional (BFD) são cruciais para entender a latência de detecção em clusters.
"The Chubby lock service for loosely-coupled distributed systems" (Google, 2006): Um paper fundamental sobre o uso do algoritmo Paxos para consenso e quorum, base para sistemas modernos como etcd e Consul.
Red Hat Cluster Suite - Fencing Configuration Guide: Documentação técnica prática sobre a implementação de agentes de fencing (IPMI, SCSI, PDU) em ambientes Enterprise Linux.
Ceph Docs - Monitors and Quorum: Documentação oficial do projeto Ceph explicando como o mapa do cluster (CRUSH map) é protegido via Paxos e monitores ímpares.

Magnus Vance
Engenheiro do Caos
"Quebro sistemas propositalmente porque a falha é inevitável. Transformo desastres simulados em vacinas para sua infraestrutura. Se não sobrevive ao meu caos, não merece estar em produção."