Storage Definido por Software (SDS): Onde o Marketing Morre e a Física Manda

Esqueça a promessa de 'storage infinito'. Entenda a latência, o custo da abstração e por que o hardware ainda dita as regras no Storage Definido por Software. Guia técnico sem filtros.
A cena do crime é quase sempre a mesma. O dashboard está verde, o vendedor prometeu "escalabilidade infinita" e "hardware de commodity", mas o banco de dados principal está sofrendo timeouts aleatórios de 500ms. A equipe de operações culpar a rede, a equipe de rede culpa os discos, e o CFO pergunta por que o cluster de storage novo, que custou uma fortuna em licenças, é mais lento que o array SAN de cinco anos atrás.
Como investigador forense de sistemas, aprendi que o Software-Defined Storage (SDS) — seja Ceph, vSAN, GlusterFS ou soluções hiperconvergentes — não é mágica. É engenharia de compromissos. O SDS pega a lógica que costumava viver em chips ASIC dedicados e caros (dentro de controladoras de storage) e a joga no colo da sua CPU de uso geral, atravessando pilhas de rede TCP/IP.
O marketing vende a flexibilidade. A física cobra o imposto. Vamos dissecar essa autopsia.
O Que é Storage Definido por Software (SDS)?
Storage Definido por Software (SDS) é uma arquitetura que desacopla o software de gerenciamento de dados do hardware subjacente. Em vez de depender de controladoras proprietárias (ASICs), o SDS utiliza processadores padrão (x86) para executar tarefas de virtualização, deduplicação, compressão e proteção de dados, transformando discos locais em um pool de armazenamento compartilhado via rede. O custo dessa abstração é pago em ciclos de CPU e latência de I/O.
A Ilusão da Abstração: O "Imposto" de Metadados no SDS
Quando você grava um bloco de dados em um storage tradicional (DAS ou SAN física), o caminho é curto. O sistema operacional fala com a controladora, que mapeia o endereço lógico para o físico e grava. Fim.
No SDS, cada operação de I/O é um pedido complexo de roteamento. O sistema precisa consultar um algoritmo de distribuição (como o CRUSH map no Ceph ou o hash ring no Swift) para descobrir onde aquele dado deve viver. Isso não é gratuito.
O sintoma: CPUs com alto System Time (sy) ou Wait I/O (wa), mesmo quando a taxa de transferência (throughput) parece baixa.
Isso acontece porque o SDS transforma I/O em um problema de computação. Para cada 4KB que você grava, o software precisa:
Calcular o hash do objeto/bloco.
Consultar a tabela de metadados (que pode estar em outro nó).
Serializar o dado para a rede.
Gerenciar travas (locks) distribuídas.
Seus dados não estão apenas sendo gravados; eles estão sendo calculados. Se a sua CPU está ocupada processando pacotes de rede ou calculando paridade, a latência do disco é irrelevante. O gargalo subiu para o processador.
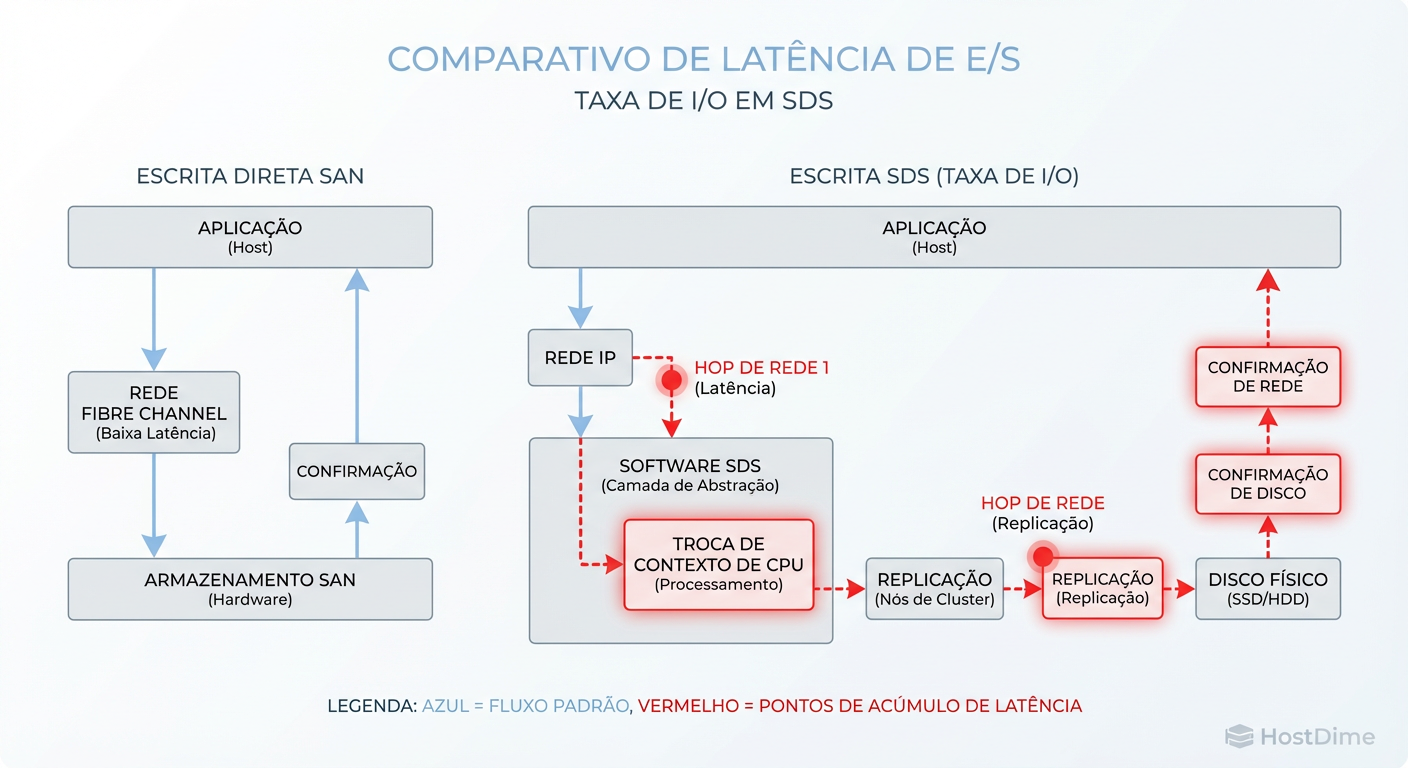 Figura: O Caminho do I/O no SDS: Cada salto de rede e ciclo de CPU adiciona latência que nenhum software pode eliminar.
Figura: O Caminho do I/O no SDS: Cada salto de rede e ciclo de CPU adiciona latência que nenhum software pode eliminar.
A Física da Rede em Clusters SDS: O Inimigo Silencioso
A latência de rede é onde a maioria das implementações de SDS morre. O marketing diz "funciona sobre Ethernet 10GbE". A física diz "cada salto conta".
Em um array tradicional, o backplane conecta os discos à controladora via PCIe ou SAS — estamos falando de nanossegundos ou microssegundos baixos. No SDS, transformamos esse backplane em cabos Ethernet, switches e a pilha TCP/IP do kernel Linux.
O Problema do Tráfego Leste-Oeste
Num ambiente SDS, uma escrita de 1MB não é apenas 1MB trafegando do cliente para o servidor. É uma tempestade de tráfego de replicação (East-West traffic). Se você tem fator de replicação 3 (RF3):
O cliente envia o dado para o Nó Primário (1x tráfego).
O Nó Primário replica para o Nó Secundário A (2x tráfego).
O Nó Primário replica para o Nó Secundário B (3x tráfego).
Os Nós Secundários confirmam o recebimento (ACKs).
Se a sua rede de storage compartilha os mesmos switches ou, pior, as mesmas interfaces físicas que o tráfego de produção, você criou um cenário de contenção garantida. O "Jitter" (variação na latência) na rede mata a performance de storage mais rápido do que a largura de banda insuficiente.
Consistência de Dados e Teorema CAP: O Custo da Replicação Síncrona
Aqui entramos na causa raiz de muitos hangs de aplicação. A maioria dos sistemas SDS corporativos promete consistência forte (o "C" do teorema CAP). Isso significa que uma gravação só é confirmada para a aplicação quando todas as réplicas confirmaram a gravação segura.
Pense no impacto disso. A velocidade da sua escrita não é a média da velocidade dos seus discos. A velocidade da sua escrita é igual à velocidade do disco mais lento, no nó mais sobrecarregado, através do link de rede mais congestionado.
Se um disco em um nó remoto engasgar por 200ms para fazer uma coleta de lixo (Garbage Collection) interna, todo o cluster SDS espera esses 200ms para liberar a operação de escrita. Isso é a "latência de cauda" (tail latency). Em sistemas distribuídos, a cauda abana o cachorro.
O Mito do "Commodity Hardware": Discos Baratos Destroem Clusters
A mentira mais perigosa do SDS é: "Use qualquer disco barato, o software resolve as falhas".
O software resolve a perda de dados, não a performance ruim. Se você mistura SSDs de consumo (Consumer Grade) em um cluster SDS com cargas de escrita intensiva, você está construindo uma bomba-relógio. SSDs de consumo não possuem capacitores de proteção contra perda de energia (PLP) e dependem de buffers DRAM voláteis.
Quando você força escritas síncronas (O_DIRECT / fsync), como bancos de dados e SDS fazem, o SSD de consumo desabilita seu cache DRAM para garantir segurança, e sua performance cai de 50.000 IOPS para 500 IOPS.
Tabela: O Custo Real do "Commodity"
| Característica | SSD Consumer (Desktop) | SSD Enterprise (Data Center) | Impacto no SDS |
|---|---|---|---|
| Proteção de Energia (PLP) | Inexistente | Capacitores dedicados | Sem PLP, o SDS força flush constante, matando a performance. |
| Latência de Escrita (99%) | Imprevisível (>10ms sob carga) | Consistente (<1ms) | Um disco lento trava a fila de replicação inteira. |
| Endurance (DWPD) | 0.3 - 0.6 | 1.0 - 10.0 | SSDs consumer morrem em meses sob rebalanceamento de SDS. |
| Performance Estável | Cai drasticamente quando cheio | Mantida via Over-provisioning | Clusters cheios com discos consumer tornam-se inoperáveis. |
Matemática do Desastre: Erasure Coding vs. Performance de Escrita
Para economizar espaço, muitos administradores ativam o Erasure Coding (EC) — o equivalente distribuído do RAID 5 ou 6. Em vez de ter 3 cópias completas (300% de capacidade bruta para 100% útil), você usa um esquema 4+2 (150% de capacidade bruta).
Parece ótimo na planilha de custos. Na operação, é brutal.
O EC sofre da penalidade de "Read-Modify-Write". Para alterar um pequeno bloco de dados, o sistema precisa:
Ler o dado antigo.
Ler a paridade antiga.
Calcular a nova paridade na CPU.
Gravar o novo dado e a nova paridade.
Isso amplifica o I/O e a latência massivamente. EC é excelente para arquivos imutáveis (backups, vídeos, logs), mas é veneno para bancos de dados transacionais ou máquinas virtuais de alto desempenho.
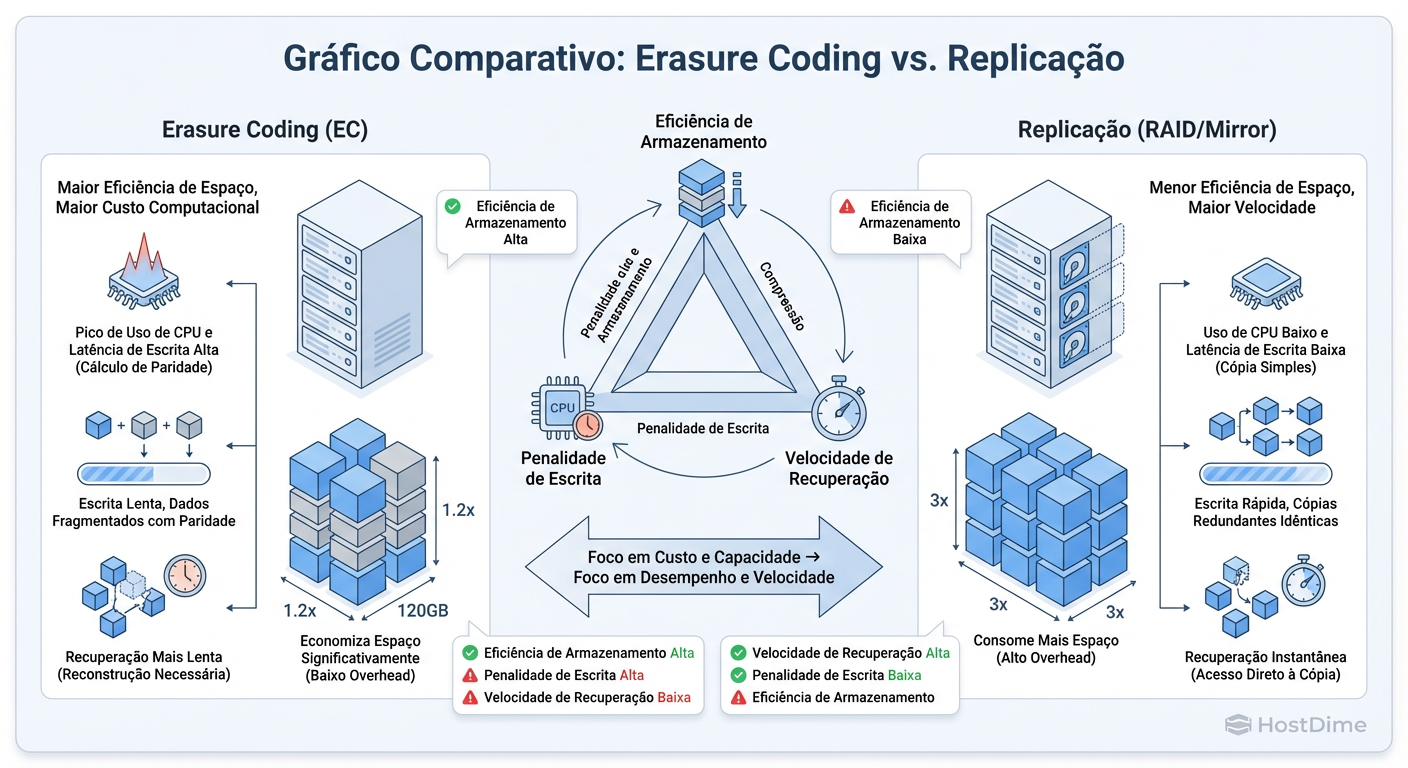 Figura: Trade-offs de Proteção de Dados: Erasure Coding economiza disco, mas cobra o preço em CPU e latência de escrita.
Figura: Trade-offs de Proteção de Dados: Erasure Coding economiza disco, mas cobra o preço em CPU e latência de escrita.
Como Medir o Overhead Real: Comandos e Métricas que Não Mentem
Não confie no dashboard do fornecedor. Ele mostra médias, e médias mentem. Para provar que o SDS é o gargalo, precisamos descer ao nível do bloco e da rede.
1. Testando a "Mentira" da Rede (iperf3 não basta)
Precisamos saber se a rede está descartando pacotes ou sofrendo latência sob carga. Use ping com flood controlado ou métricas de interface.
Mas para storage, o iostat é o rei. Em um nó Linux que serve SDS, observe as filas:
# Observe a coluna d_await (latência de disco) e %util
iostat -xnz 1
Se o d_await (tempo que o disco físico leva) for 2ms, mas a latência percebida pela sua VM for 20ms, os 18ms perdidos são o "Imposto SDS" (software + rede).
2. O Teste da Verdade com FIO
Para validar se o seu SDS aguenta o tranco de um banco de dados, não teste throughput sequencial (streaming). Teste latência de escrita síncrona aleatória.
# Simulação de DB: Random Write, Sync, Blocksize 4k
fio --name=db_latency_test \
--ioengine=libaio --direct=1 --sync=1 \
--rw=randwrite --bs=4k --numjobs=1 \
--iodepth=1 --size=1G --runtime=60 \
--time_based --group_reporting
O que olhar: Ignore o BW (Bandwidth). Olhe para o clat (completion latency) nos percentis 99.00th e 99.90th. Se o 99.90th for maior que 10ms-20ms, seu banco de dados vai reclamar.
3. Rastreando Latência de Rede Específica
Se você suspeita da rede, verifique retransmissões TCP, que são fatais para performance de storage:
netstat -s | grep -i retrans
Em um cluster saudável, esse número deve ser estático ou crescer muito lentamente. Se estiver subindo rápido, você tem perda de pacotes, cabos ruins ou saturação de buffer no switch.
Veredito Operacional: Quando o SDS é a Ferramenta Errada
O SDS não é "ruim". Ele é uma ferramenta com trade-offs claros. O erro é tratá-lo como um substituto universal para SANs All-Flash dedicadas.
O SDS é a ferramenta certa quando:
A escalabilidade (Petabytes) é mais importante que a latência (microsegundos).
Você precisa de armazenamento de objetos (S3) ou arquivos (NFS) em escala massiva.
Você tem controle total sobre o hardware (HCL rigorosa) e rede (10/25/100GbE dedicados).
O SDS é a ferramenta errada (ou exige cuidado extremo) quando:
Você tem pouca tolerância a latência (ex: High-Frequency Trading, Oracle Exadata workloads).
Você tenta reciclar hardware antigo e heterogêneo esperando milagres.
Sua equipe não tem profundidade em Linux/Redes para debugar quando o cluster degrada.
No final, a gravidade da física sempre vence. O software pode adicionar inteligência, mas nunca pode subtrair a distância que um pacote precisa viajar ou o tempo que uma CPU leva para calcular um hash. Projete seu storage respeitando esses limites, e não as brochuras de marketing.
Referências & Leitura Complementar
Ceph: A Scalable, High-Performance Distributed File System (Weil et al.) – O paper original que define os conceitos de CRUSH map e distribuição pseudo-aleatória.
RFC 3720 (iSCSI) – Fundamental para entender como o SCSI é encapsulado sobre TCP/IP e os overheads inerentes.
The CAP Theorem (Brewer) – Essencial para entender por que você não pode ter Consistência e Disponibilidade totais simultaneamente em presença de Partição de rede.
Intel Whitepaper: SSD Endurance and Power Loss Protection – Documentação técnica sobre a diferença física entre drives de Data Center e drives Client.

Marcos Lopes
Operador Open Source (Self-Hosted)
"Troco licenças proprietárias por soluções open source robustas, ciente de que a economia financeira custa suor na manutenção. Defensor da soberania de dados e da força da comunidade."