Storage Distribuído: Por que a Arquitetura Mata seu Cluster (Não o Hardware)

Discos morrem em silêncio; arquiteturas ruins morrem gritando. Entenda por que latência, consenso e tempestades de rebalanceamento são os verdadeiros assassinos do storage distribuído.
A cena do crime é sempre a mesma. O pager toca às 3 da manhã. O cluster de storage — aquele projetado para ter "99,999% de disponibilidade" e sobreviver a um apocalipse nuclear — está travado. A latência de gravação subiu para 500ms, as VMs estão congelando e o telefone do diretor de TI não para de tocar.
A primeira reação do sysadmin é culpar o disco. "Deve ser um SSD que morreu". Mas ao olhar os logs, você vê que um disco realmente falhou. O problema é que o sistema, desenhado para ser resiliente, reagiu a essa falha simples cometendo suicídio. Como investigador forense de sistemas, afirmo: discos morrem o tempo todo; clusters morrem porque a arquitetura não respeitou a física.
Falha Arquitetural em Storage Distribuído é o colapso sistêmico causado não pela perda de um componente físico, mas pela incapacidade do software de gerenciar a recuperação (rebalanceamento) sem exaurir os recursos (CPU, RAM, Rede) necessários para a operação normal. É quando a cura mata o paciente.
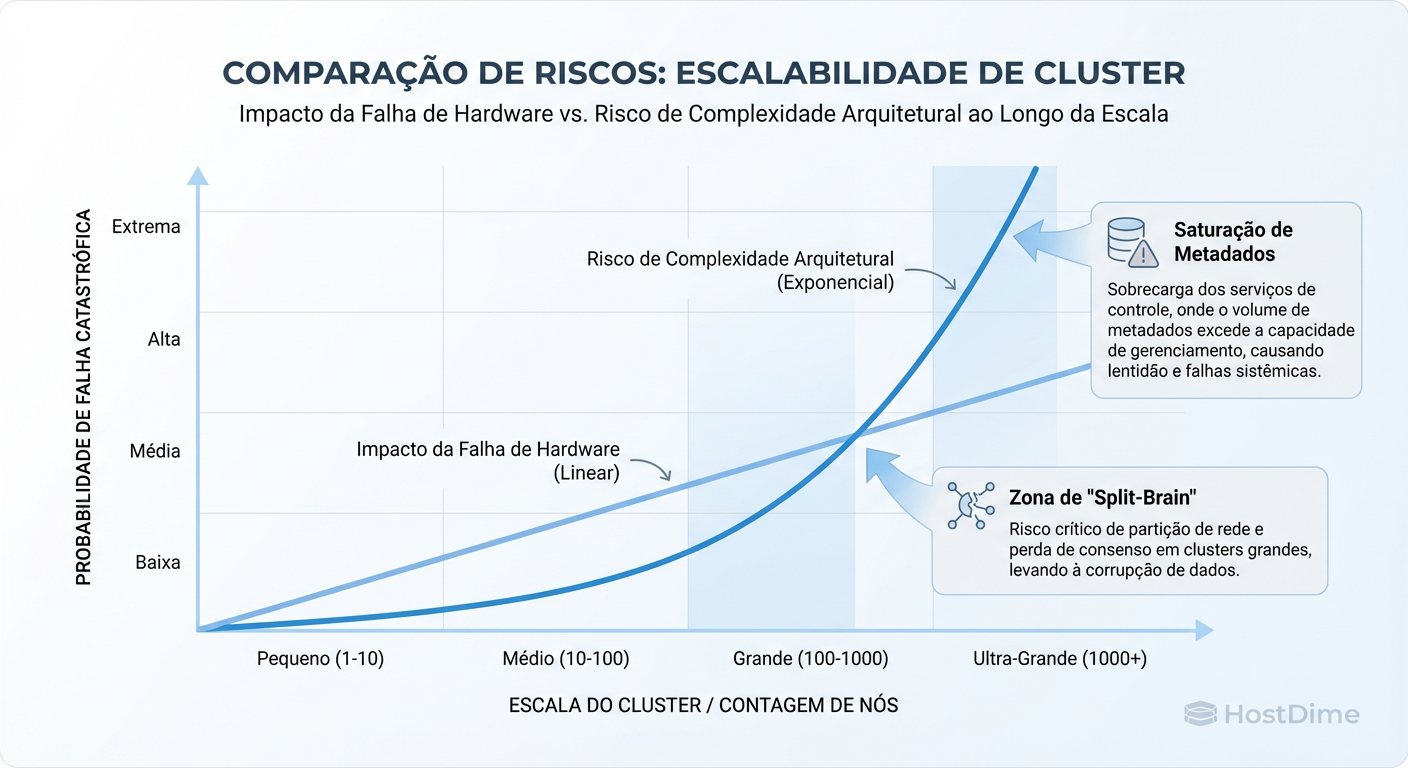 Figura: Gráfico de Risco: A relação entre escala do cluster e a probabilidade de falhas lógicas complexas versus falhas físicas simples.
Figura: Gráfico de Risco: A relação entre escala do cluster e a probabilidade de falhas lógicas complexas versus falhas físicas simples.
A Ilusão da Segurança no Storage Distribuído
Existe uma mentira confortável que vendemos a nós mesmos: "Se eu adicionar mais nós, meu risco diminui". Isso é matematicamente falso em termos de probabilidade de incidentes.
Em um RAID tradicional com hardware dedicado, o controlador é um chip ASIC focado. Em sistemas distribuídos (Ceph, Gluster, vSAN, MinIO), o "controlador" é uma mistura caótica de:
A CPU do servidor (que também roda aplicações).
O Kernel do Linux (scheduler, stack TCP/IP).
A rede (switches, cabos, buffers).
Quando você escala de 3 para 300 nós, a probabilidade de um componente de hardware falhar sobe para 100%. O que mata o cluster não é essa falha, é a complexidade da orquestração necessária para lidar com ela. O gráfico de risco acima ilustra exatamente isso: quanto maior o cluster, menor o risco de perda total de dados por falha física, mas maior o risco de indisponibilidade por "bugs lógicos" ou tempestades de tráfego.
O Gargalo da Rede: Quando o Switch vira Controlador de Disco
Em storage distribuído, a rede é o backplane. Se você trata sua rede Ethernet como um tubo passivo, você já falhou na arquitetura.
O erro mais comum que vejo em autópsias de clusters é o subdimensionamento de latência, não de largura de banda. Você pode ter links de 100Gbps, mas se o seu switch tiver buffers pequenos (shallow buffers) e ocorrer um micro-burst de tráfego de replicação, pacotes serão descartados.
Sintoma Forense: Retransmissão TCP
Quando um pacote de storage é descartado, o protocolo TCP precisa retransmitir. Isso introduz uma latência de espera (RTO). Para um banco de dados esperando um ack de gravação, isso é uma eternidade.
Se você suspeita que sua rede está matando a performance do storage, não use apenas o ping. Use o ss para verificar a saúde do TCP nos nós de storage:
# Verifique estatísticas de TCP, filtrando por retransmissões e RTT (Round Trip Time)
# Procure por valores altos em 'retrans' ou RTTs instáveis
watch -n 1 "ss -ti | grep -e 'rtt:' -e 'retrans'"
Se você vê contadores de retransmissão subindo durante operações de escrita, sua rede é o gargalo, não os discos. O storage está "gritando" para gravar, mas a rede está tapando a boca dele.
Tabela Comparativa: O Custo da Topologia
| Característica | RAID Local (Hardware) | SAN Tradicional (Fibre Channel) | Storage Distribuído (Ethernet) |
|---|---|---|---|
| Latência Base | Baixíssima (Microsegundos) | Baixa (Dedicada/Lossless) | Variável (Depende de Jitter/Congestionamento) |
| Mecanismo de Falha | Falha de Disco ou Controladora | Falha de HBA ou Switch FC | Partição de Rede, OOM Killer, CPU Wait |
| Impacto de Rebuild | Isolado no chassi | Isolado no Array | Sistêmico (Consome rede de produção) |
| Complexidade de Debug | Baixa (Troca peça) | Média (Logs do Switch/Array) | Extrema (Tracing distribuído necessário) |
Consenso e Quorum: Onde a Lógica Falha na Prática
Sistemas distribuídos dependem de algoritmos de consenso (Paxos, Raft) para garantir que todos concordem sobre a verdade. O problema é o cenário de "Split-Brain" ou partição de rede.
A teoria diz que o sistema deve parar para preservar a consistência (CP no Teorema CAP). Na prática, o que acontece é o "flapping". Um link de rede instável faz um nó aparecer e desaparecer rapidamente. O cluster gasta ciclos preciosos de CPU elegendo novos líderes repetidamente, em vez de servir dados.
O Perigo do "Witness" Mal Posicionado: Muitas arquiteturas usam um nó "testemunha" para desempatar quóruns. Se a latência para essa testemunha for alta (ex: em outro datacenter) e a rede principal oscilar, você terá um cluster que congela todas as operações de I/O enquanto aguarda um voto que demora 50ms para chegar. Em storage, 50ms é "downtime".
Tempestades de Rebalanceamento e Auto-Ataque (DDoS)
Aqui está a causa mortis mais frequente em grandes incidentes: o Efeito Cascata.
Um nó falha ou um disco morre.
O sistema detecta a perda de redundância.
O sistema inicia automaticamente a "cura" (rebalanceamento/resync) para restaurar a redundância.
Esse tráfego de cópia inunda a rede.
Se não houver QoS (Quality of Service) rigoroso limitando o tráfego de backfill, o tráfego de recuperação compete com o tráfego de produção. A latência da produção sobe. Os timeouts das aplicações estouram. As aplicações tentam reconectar (retries), gerando mais carga.
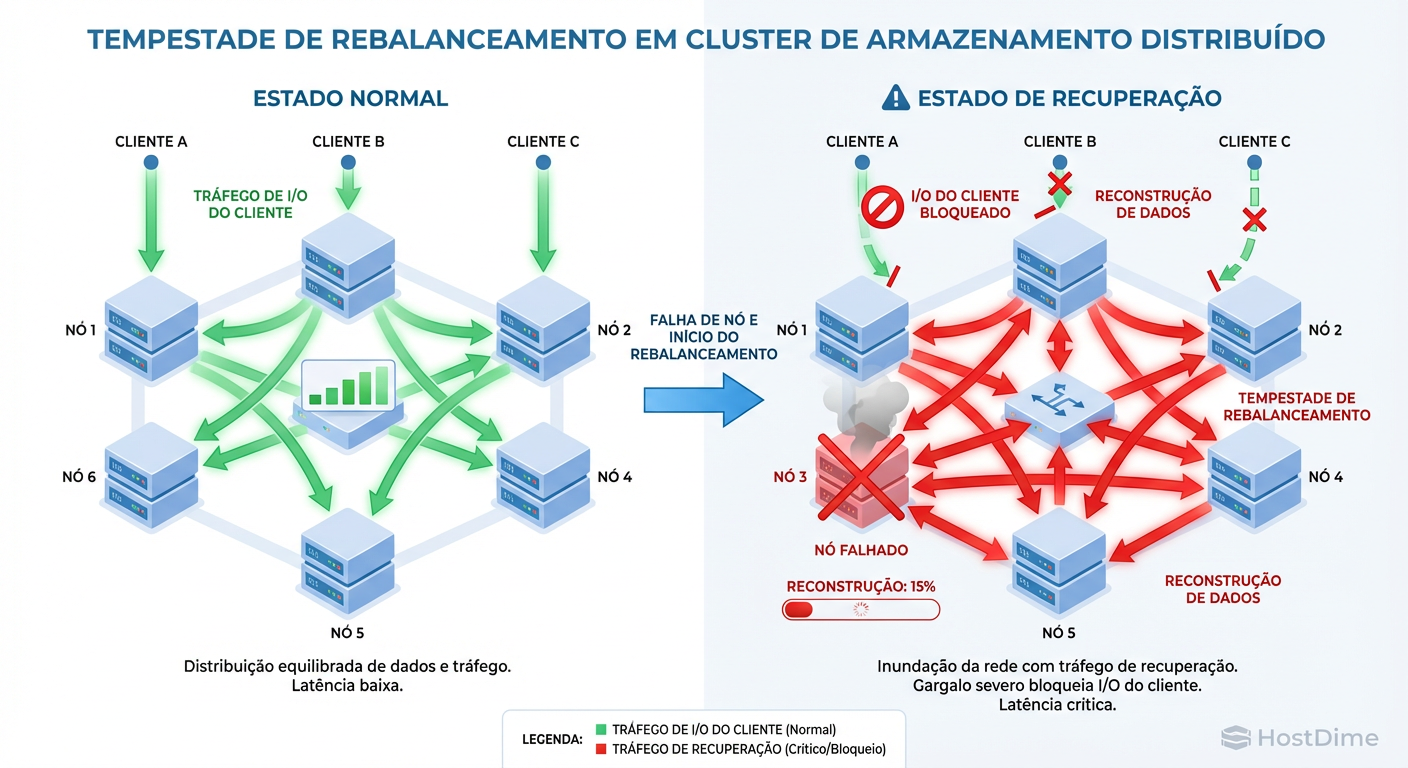 Figura: Diagrama de Fluxo: Como o tráfego de recuperação (Rebalance) pode sufocar o tráfego de produção em arquiteturas mal planejadas.
Figura: Diagrama de Fluxo: Como o tráfego de recuperação (Rebalance) pode sufocar o tráfego de produção em arquiteturas mal planejadas.
Pior: se a carga de rebalanceamento for alta demais, ela pode fazer com que outros nós, já estressados, parem de responder aos heartbeats. O cluster marca esses nós saudáveis como "falhos" e começa a tentar replicar os dados deles também. É um ataque DDoS que o cluster faz contra si mesmo.
Como Evitar o Suicídio do Cluster:
Você precisa configurar limites de largura de banda para recuperação. No Ceph, por exemplo, parâmetros como osd_recovery_max_active e osd_recovery_op_priority são a diferença entre um cluster lento e um cluster morto.
Metadados e Latência de Cauda: A Morte Silenciosa
Muitas vezes, a média de latência parece boa, mas as aplicações reclamam. Bem-vindo ao inferno da Latência de Cauda (Tail Latency).
Em storage distribuído, cada operação de escrita envolve metadados: "Onde coloco esse bloco? Quem são as réplicas? A versão está atualizada?". Esses metadados geralmente vivem em bancos de dados chave-valor rápidos (como RocksDB dentro do Ceph BlueStore).
Quando esses bancos de metadados precisam compactar dados (compaction) ou sofrem com fragmentação, uma operação que levaria 1ms leva 500ms. Se o seu request de I/O cair nesse 1% de azar (P99), a performance despenca.
Sintoma: O uso de disco é baixo, a rede está livre, mas o I/O "engasga" periodicamente. Causa: Bloqueio em estruturas de metadados ou CPU saturation em um único núcleo gerenciando interrupções.
Forense de Sistemas: O que Monitorar para Prever o Colapso
Não espere o usuário abrir chamado. Se você gerencia storage distribuído, seu dashboard precisa focar em métricas de saturação e fila, não apenas em "espaço livre".
Checklist de Monitoramento Forense
Latência de Rede entre Nós (Não para o cliente):
- Monitore a latência backend. Se os nós demoram para falar entre si, o write no cliente vai travar.
Tamanho da Fila de Disco (Avg Queue Size):
- Em SSDs, filas persistentes acima de 4 ou 5 indicam que o dispositivo não está dando conta do paralelismo.
Slow Requests (Logs):
- Configure seu storage para logar qualquer operação que leve mais de 100ms. Agrupe esses logs. Se eles correlacionam com horários de scrubbing ou rebalance, sua arquitetura está no limite.
CPU Steal / Context Switches:
- Storage distribuído é intensivo em CPU. Se a CPU está gastando tempo demais trocando de contexto, você tem threads demais para núcleos de menos.
Referências & Leitura Complementar
Para aprofundar sua investigação e validar os conceitos apresentados, consulte as fontes técnicas abaixo:
Google Site Reliability Engineering (The SRE Book): Capítulo sobre "The Chubby Lock Service" e problemas de consenso distribuído.
Ceph Documentation - CRUSH Maps: Entendimento fundamental sobre como o posicionamento de dados afeta a latência e domínios de falha.
RFC 793 (Transmission Control Protocol): Especificamente as seções sobre controle de congestionamento e retransmissão, vitais para entender gargalos de rede em storage.
"System Performance" por Brendan Gregg: Capítulos sobre análise de discos e redes.
Dynamo: Amazon’s Highly Available Key-value Store: O whitepaper original que define muitos dos trade-offs de consistência eventual vs. disponibilidade.

Rafael Barros
Arquiteto de Cloud Storage
"Desenho arquiteturas de object storage escaláveis e guiadas por API. Meu foco é performance máxima sem deixar o orçamento sangrar com taxas de egress ocultas."