Storage no S&P 500 em 2025: A Vingança do Gargalo de I/O

Análise técnica do boom das ações de storage em 2025. Entenda como a IA, RAG e Checkpointing transformaram o armazenamento de 'bucket passivo' em 'gargalo crítico' de performance.
Durante a última década, o armazenamento de dados (Storage) foi tratado como uma commodity enfadonha. A ordem dos CFOs era clara: "Encontre o $/TB mais barato e não deixe os dados sumirem". Se o disco era lento, adicionávamos cache. Se o cache falhava, culpávamos a rede.
Mas em 2025, o jogo virou violentamente. Com a ascensão massiva de clusters de treinamento de IA e inferência de LLMs (Large Language Models), o storage deixou de ser o armário dos fundos para se tornar o gargalo que estrangula o ativo mais caro da empresa: as GPUs.
Não estamos mais falando apenas de guardar arquivos de Excel. Estamos falando de alimentar processadores que custam dezenas de milhares de dólares e que, se ficarem ociosos esperando por dados (I/O Wait), queimam o orçamento de capital da empresa sem produzir inteligência.
O Gargalo de I/O em 2025 é a discrepância de latência entre a capacidade de consumo de dados dos aceleradores de IA (GPUs/TPUs) e a capacidade do subsistema de armazenamento de entregar esses dados. Em cenários de treinamento, isso se manifesta criticamente durante o Checkpointing (escrita massiva síncrona) e no Dataloading (leitura aleatória massiva), onde milissegundos de atraso resultam em horas de ociosidade computacional acumulada.
O Fim da Era "Storage é Commodity" no Mercado Financeiro
Por anos, o S&P 500 tratou infraestrutura como custo fixo. Em 2025, a métrica mudou. A latência de storage agora é diretamente correlacionada ao ROI (Retorno sobre Investimento) de projetos de IA.
A física aqui é impiedosa. Um cluster com 1.000 GPUs H100 (ou equivalentes mais modernos) possui uma fome de dados que excede a capacidade de protocolos legados como NFS sobre TCP padrão. Quando um analista financeiro olha para o custo de um cluster de IA, ele vê o CAPEX do hardware. Um Engenheiro de Performance vê o "GPU Idle Time".
Se o seu storage não consegue saturar o barramento PCIe 5.0 ou 6.0 das máquinas de computação, você comprou uma Ferrari e colocou gasolina adulterada. O mercado financeiro entendeu que economizar 20% em storage pode custar 40% de eficiência no tempo de treinamento do modelo.
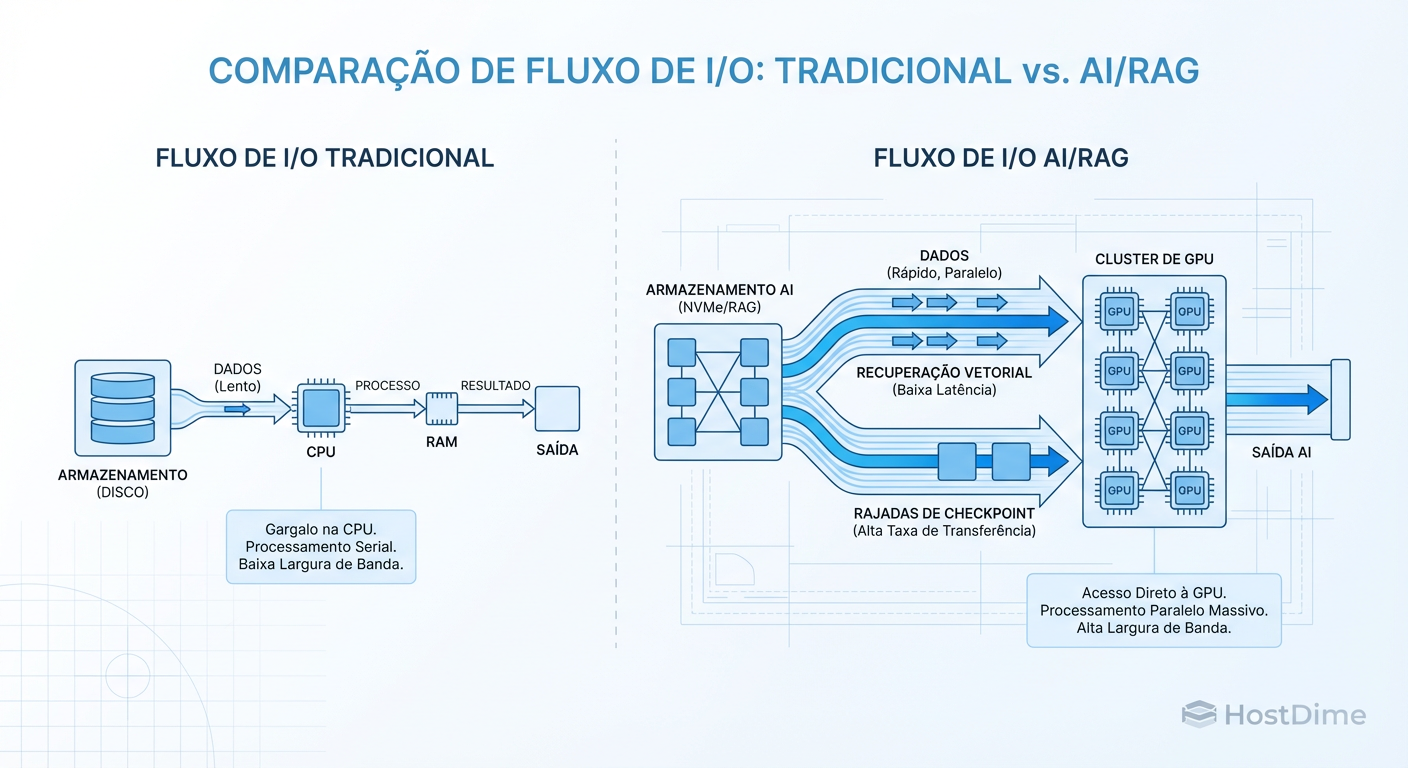 Figura: O Novo Fluxo de Dados: Diferença entre servir arquivos para usuários (esquerda) e alimentar clusters de IA (direita). Note os picos de Checkpointing.
Figura: O Novo Fluxo de Dados: Diferença entre servir arquivos para usuários (esquerda) e alimentar clusters de IA (direita). Note os picos de Checkpointing.
A imagem acima ilustra a mudança fundamental no padrão de tráfego. À esquerda, o tráfego tradicional: leitura/escrita assíncrona, previsível. À direita, o "eletrocardiograma" de um treino de IA: longos períodos de leitura intensa seguidos por picos violentos de escrita (Checkpointing). Se o seu storage não aguenta esse pico, todo o cluster para.
A Física do Gargalo: Checkpointing e a "Manada Estourada"
Vamos dissecar o problema técnico. O treinamento de LLMs não é linear; ele é iterativo e propenso a falhas. Para mitigar crashes, o sistema salva o estado de todos os parâmetros do modelo periodicamente (Checkpointing).
Imagine um modelo com trilhões de parâmetros. Isso se traduz em Terabytes de dados que precisam ser despejados da VRAM da GPU para o disco simultaneamente por todos os nós do cluster. É o clássico problema do "Thundering Herd" (Manada Estourada), mas em escala de Petabytes.
Se você usa um storage baseado em discos rotacionais (HDD) ou mesmo SSDs mal arquitetados para essa camada, a latência de escrita dispara. O protocolo TCP engasga com retransmissões. As GPUs ficam paradas (Stall).
Como medir o impacto do Checkpointing
Não confie no throughput médio fornecido pelo vendor. Para validar se seu storage aguenta IA, você deve simular o pior cenário: escritas sequenciais massivas e simultâneas.
Use o fio para simular um checkpoint. O comando abaixo não é um "hello world", é um teste de estresse para simular 4 nós despejando dados:
fio --name=ai-checkpoint-sim \
--ioengine=libaio \
--rw=write \
--bs=4M \
--direct=1 \
--numjobs=4 \
--size=50G \
--iodepth=64 \
--group_reporting \
--runtime=60 \
--time_based
O que observar nos resultados:
Latência de cauda (p99): Se o p99 subir de 2ms para 200ms durante o teste, seu storage causará stalls nas GPUs.
Throughput Sustentado: O storage consegue manter a velocidade após encher o cache de escrita (SLC Cache)? Muitos SSDs "gamer" ou enterprise de entrada caem para velocidades de HDD depois de alguns segundos de escrita contínua.
A Matemática do ROI: GPUs Ociosas vs. Storage Premium
Aqui entra o pragmatismo financeiro. Um rack de storage All-Flash NVMe de alta performance é caro. Mas compare isso com o custo de não tê-lo.
 Figura: A Matemática do ROI em 2025: Por que gastar milhões em storage (verde) foi barato comparado ao custo de GPUs ociosas (vermelho).
Figura: A Matemática do ROI em 2025: Por que gastar milhões em storage (verde) foi barato comparado ao custo de GPUs ociosas (vermelho).
Como a imagem demonstra, o custo do storage (verde) é uma fração do custo total do ambiente. No entanto, a ineficiência do storage causa a área vermelha (GPU Ociosa). Em 2025, a decisão inteligente não é comprar o storage mais barato, mas sim aquele que minimiza a área vermelha.
Se o seu ciclo de treinamento dura 30 dias e 10% desse tempo é gasto esperando I/O (Checkpoints lentos ou carregamento de dados ineficiente), você perdeu 3 dias de um cluster milionário. Esse custo recupera o investimento em storage premium em questão de meses.
Flash vs. Rust: A Bifurcação do Armazenamento
Antigamente, tínhamos uma pirâmide suave de storage: RAM -> SSD Rápido -> SSD Lento -> HDD Rápido -> HDD Lento -> Fita.
Em 2025, o meio-termo morreu. O mercado bifurcou para dois extremos:
Hot Tier (O "Cérebro"): Deve ser NVMe, preferencialmente usando tecnologias como DirectFlash (onde o software gerencia a NAND diretamente, pulando o controlador do SSD para reduzir latência). Aqui vivem os dados de treinamento ativo e índices vetoriais.
Cold Archive (A "Memória Profunda"): HDDs com tecnologia HAMR (Heat-Assisted Magnetic Recording) atingindo 40TB+ por disco. Aqui vivem os datasets brutos e checkpoints antigos.
Tabela Comparativa: O Fim do Meio-Termo
| Característica | Hot Tier (NVMe/DirectFlash) | Cold Archive (HAMR HDD/Tape) | Storage "Morno" (SATA SSD/SAS HDD) |
|---|---|---|---|
| Função Principal | Alimentar GPUs, Checkpointing Rápido | Data Lake, Compliance, Backup | Terra de Ninguém (Obsoleto) |
| Custo ($/GB) | Alto ($$$) | Baixo ($) | Médio ($$) |
| Latência (p99) | < 300 µs | > 10 ms | 1-5 ms |
| Throughput | Massivo (GB/s por drive) | Moderado (MB/s) | Limitado por interface |
| Uso em IA | Obrigatório para Treino | Obrigatório para Retenção | Ineficiente para ambos |
O Risco: Tentar usar storage "morno" (ex: arrays híbridos antigos) para IA. Eles são caros demais para arquivamento e lentos demais para treinamento.
Eficiência Energética como KPI de Storage
Em 2025, os datacenters atingiram o limite de fornecimento de energia. Você não pode simplesmente adicionar mais racks; você precisa respeitar o orçamento de energia (Power Budget).
A métrica Watts/TB tornou-se tão crucial quanto $/TB.
Flash: Embora consuma energia, a densidade (QLC de 60TB em um drive de 2.5") permite consolidar petabytes em poucas Unidades de Rack (U), reduzindo o consumo total de ar condicionado e energia por PB armazenado.
HDD: Discos modernos HAMR oferecem densidade incrível, mas a mecânica de girar pratos consome energia. O segredo aqui é o gerenciamento de energia agressivo (MAID - Massive Array of Idle Disks) para dados frios.
Decisão Operacional: Ao renovar hardware, exija do vendor a métrica de IOPS por Watt. Se o vendor esconder esse número, assuma que o equipamento é ineficiente.
O Software Comeu o Hardware: Compressão e DirectFlash
Hardware rápido é inútil com software lento. O caminho tradicional de I/O no Linux (interrupções, trocas de contexto de kernel, sistemas de arquivos com locks globais) não escala para as velocidades de 2025.
Os vencedores do mercado (empresas como Pure Storage, VAST Data, e soluções customizadas baseadas em SPDK) entenderam que:
Bypass de Kernel: O caminho de dados (Data Path) deve evitar o kernel do SO sempre que possível (RDMA, GPU Direct Storage).
Compressão em Linha: Com CPUs dedicadas (DPUs) nos arrays de storage, a compressão não serve apenas para economizar espaço. Ela aumenta a largura de banda efetiva. Se você comprime 2:1, você efetivamente dobrou a velocidade do link de rede e do disco, pois trafega metade dos bits físicos.
Trade-offs Reais: Nuvem Híbrida e a Repatriação
Finalmente, o custo de nuvem. Armazenar Petabytes na nuvem pública é barato (S3 Glacier). O problema é usar esses dados. As taxas de Egress (saída de dados) e as taxas de API (GET requests) podem quebrar o orçamento de um projeto de IA.
Muitas empresas do S&P 500 iniciaram em 2025 um movimento de Repatriação de Dados de Treinamento. A estratégia comum agora é:
Nuvem Pública: Para experimentação rápida e burst de computação.
On-Prem / Colocation: Para o "Data Gravity". Onde está o dado pesado (Petabytes), ali deve estar a computação. Mover o dado é caro e lento; mover a computação (containers) é mais fácil, mas a física exige proximidade.
A regra de ouro: Se você vai ler o mesmo dataset 100 vezes (épocas de treinamento), tê-lo em nuvem pública pagando por leitura/acesso é suicídio financeiro. O armazenamento local de alta performance torna-se a opção econômica.
Referências & Leitura Complementar
Para aprofundar sua metodologia de teste e entendimento da física dos dispositivos, consulte:
NVMe™ Base Specification 2.0+: Entenda as filas de comando (Queues) e como o paralelismo funciona no nível do protocolo.
SNIA (Storage Networking Industry Association) Emerald™ Program: Padrões para eficiência energética em storage.
"Systems Performance" (Brendan Gregg): A bíblia para entender latência, IOPS e metodologias de análise de gargalos.
OCP (Open Compute Project) Storage Specifications: Veja como os hyperscalers (Meta, Google) desenham seus servidores de storage para maximizar fluxo de ar e densidade.

Viktor Kovac
Investigador de Incidentes de Segurança
"Não busco apenas o invasor, mas a falha silenciosa. Rastreio vetores de ataque, preservo a cadeia de custódia e disseco logs até que a verdade digital emerja das sombras."