Storage para IA: Otimizando RAG e Checkpoints

Análise técnica de gargalos de armazenamento em pipelines de IA. Descubra como validar subsistemas para RAG e Checkpoints usando fio e métricas de latência de cauda.
A discussão sobre infraestrutura para Inteligência Artificial tem sido monopolizada pela capacidade de computação. Discute-se exaustivamente a quantidade de VRAM em uma H100 ou a largura de banda de memória HBM3e. No entanto, existe um gargalo silencioso que frequentemente transforma clusters milionários em aquecedores de ambiente glorificados: o subsistema de armazenamento.
Quando um modelo de linguagem (LLM) entra em colapso durante a inferência ou o treinamento para por horas devido a um checkpoint lento, a culpa raramente é da GPU. O culpado reside na incapacidade do storage de lidar com duas cargas de trabalho diametralmente opostas e simultâneas: a leitura aleatória massiva exigida pelo RAG (Retrieval-Augmented Generation) e a escrita sequencial brutal dos checkpoints de treinamento.
Resumo em 30 segundos
- O Conflito de I/O: RAG exige latência ultrabaixa em leituras aleatórias (4k-16k), enquanto checkpoints exigem largura de banda máxima para escritas sequenciais massivas.
- A Falácia da Média: Em inferência vetorial, a latência média é irrelevante. O que mata a performance é a latência de cauda (p99), onde SSDs de consumo falham catastroficamente sob carga.
- Solução Arquitetural: O uso de GPUDirect Storage (GDS) e isolamento de namespaces NVMe são obrigatórios para evitar que a CPU se torne um despachante de dados engarrafado.
O impacto oculto da latência de cauda na inferência vetorial
A arquitetura de RAG transformou o armazenamento de um repositório passivo em um componente ativo da cadeia de inferência. Quando um usuário faz uma pergunta a um chatbot corporativo, o sistema não consulta apenas o modelo; ele realiza uma busca semântica em um banco de dados vetorial (como Milvus, Weaviate ou pgvector).
Do ponto de vista do disco, uma busca vetorial utilizando algoritmos como HNSW (Hierarchical Navigable Small World) é um pesadelo de I/O. O algoritmo navega por um grafo de vizinhos, gerando milhares de leituras aleatórias de pequenos blocos (geralmente 4KB a 16KB) para recuperar os vetores relevantes.
Aqui, a métrica de "MB/s" estampada na caixa do SSD é inútil. O que importa é a latência de cauda (Tail Latency). Se o seu SSD responde a 99% das requisições em 100 microssegundos, mas 1% delas leva 50 milissegundos (devido a garbage collection ou contenção de fila), a experiência do usuário final será de travamento. O LLM não pode começar a gerar a resposta até que o contexto vetorial seja recuperado.
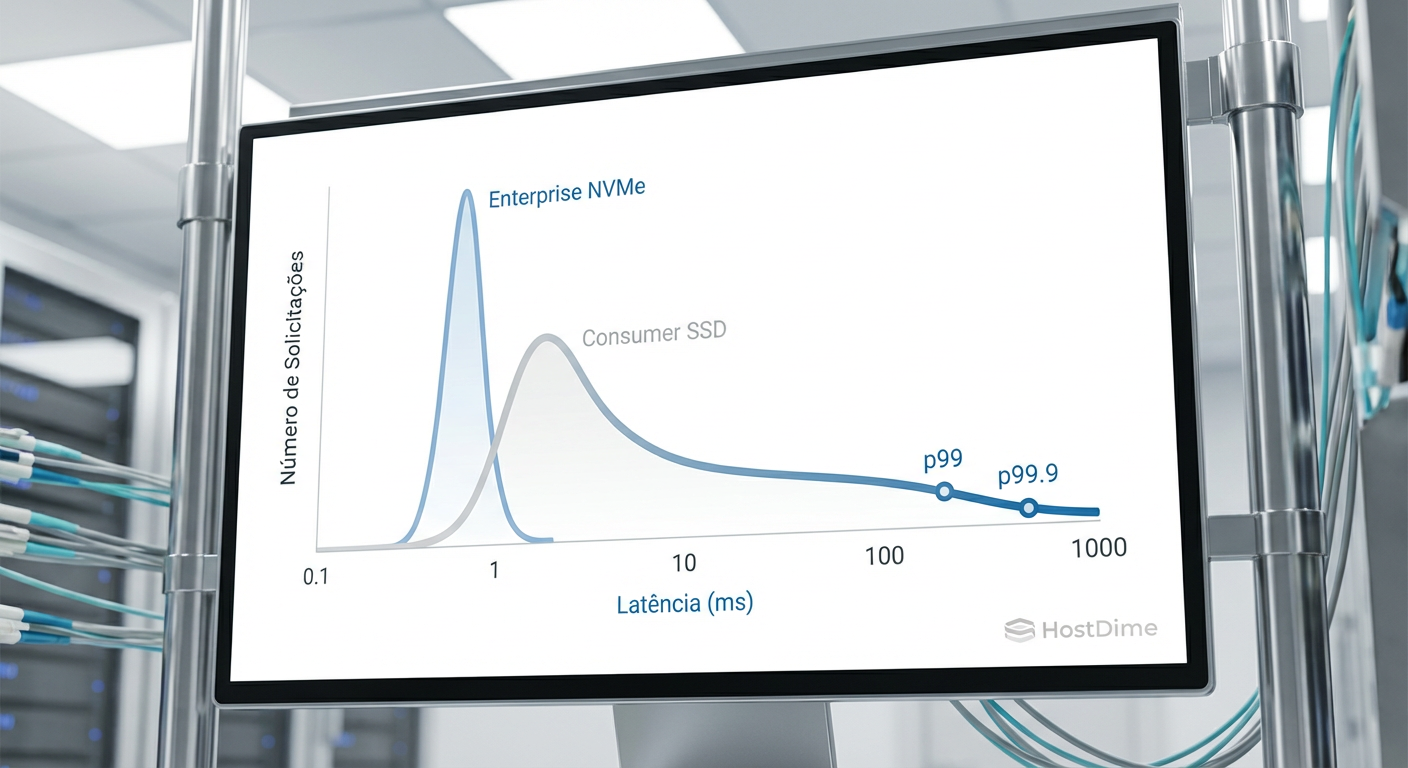 Figura: Histograma comparativo de latência: A diferença crítica entre a consistência de um NVMe Enterprise e a cauda longa imprevisível de um SSD de consumo.
Figura: Histograma comparativo de latência: A diferença crítica entre a consistência de um NVMe Enterprise e a cauda longa imprevisível de um SSD de consumo.
⚠️ Perigo: SSDs baseados em QLC (Quad-Level Cell) sem DRAM cache dedicada são inadequados para RAG. A latência de leitura dispara assim que o cache SLC se esgota ou durante operações de reescrita em segundo plano, causando timeouts na aplicação de IA.
Anatomia do I/O: A colisão de cargas
O cenário se agrava quando introduzimos o treinamento ou fine-tuning na mesma infraestrutura. Enquanto o RAG bombardeia o disco com leituras aleatórias pequenas, o processo de treinamento precisa periodicamente despejar o estado dos pesos do modelo para o disco (checkpointing).
Um checkpoint de um modelo como o Llama-3-70B pode ter centenas de gigabytes. Isso gera uma operação de escrita sequencial massiva que satura completamente a largura de banda do barramento PCIe e o buffer de escrita do controlador do SSD.
Se o RAG e o Checkpoint compartilharem o mesmo caminho de dados sem isolamento, ocorre o fenômeno de "Noisy Neighbor" (Vizinho Barulhento). As leituras pequenas do RAG ficam presas na fila atrás de blocos massivos de escrita do checkpoint. O resultado é um aumento na latência de inferência que pode saltar de sub-milissegundos para segundos inteiros.
Tabela Comparativa: Perfis de Carga
| Característica | RAG (Busca Vetorial) | Checkpointing (Treinamento) |
|---|---|---|
| Padrão de I/O | 100% Leitura Aleatória | 100% Escrita Sequencial |
| Tamanho de Bloco | 4KB - 16KB | 1MB - 4MB |
| Métrica Crítica | Latência p99 (IOPS em QD baixo) | Throughput (MB/s sustentados) |
| Impacto de Falha | Lentidão na resposta do Chatbot | Perda de horas de treinamento (crash) |
| Protocolo Ideal | NVMe (Baixa Latência) | GPUDirect / Burst Buffer |
Arquitetando o subsistema: Isolamento e Bypass
Para mitigar essa colisão, não basta adicionar mais discos. É necessário arquitetar o fluxo de dados. A abordagem tradicional de passar todos os dados pela RAM do sistema e pela CPU (bounce buffers) é ineficiente para as taxas de transferência atuais do PCIe Gen5.
GPUDirect Storage (GDS)
A tecnologia GPUDirect Storage da NVIDIA (parte do Magnum IO) é fundamental aqui. Ela permite que a GPU leia e grave dados diretamente no NVMe via DMA (Direct Memory Access), contornando completamente a CPU e a memória do sistema.
Isso tem dois efeitos imediatos:
Redução de Latência: Elimina a cópia de dados redundante (NVMe -> RAM do Sistema -> VRAM da GPU).
Alívio da CPU: A CPU fica livre para gerenciar as requisições de inferência e pré-processamento de dados, em vez de atuar como um roteador de armazenamento.
 Figura: Comparação de fluxo de dados: O caminho tradicional via CPU versus o acesso direto via DMA do GPUDirect Storage.
Figura: Comparação de fluxo de dados: O caminho tradicional via CPU versus o acesso direto via DMA do GPUDirect Storage.
Namespaces e NVM Sets
Para o problema da colisão de filas, a especificação NVMe oferece recursos subutilizados: Namespaces e NVM Sets. Em vez de criar partições lógicas no sistema operacional, você deve configurar o isolamento no nível do controlador do drive.
Ao atribuir canais NAND específicos e filas de submissão/conclusão separadas para cargas de RAG e cargas de Checkpoint (usando NVM Sets), garantimos que uma escrita massiva não bloqueie fisicamente o acesso aos chips de memória flash que estão servindo as leituras vetoriais.
💡 Dica Pro: Em ambientes Linux, utilize o comando
nvme-clipara configurar NVM Sets isolados. Mapeie o volume de vetores para um Set e o volume de checkpoints para outro. Isso garante QoS (Qualidade de Serviço) no nível do hardware.
Metodologia de validação: Simulando o caos
Não confie em benchmarks sintéticos de "folha de dados" como CrystalDiskMark. Eles testam o pico de performance em condições ideais, o que é irrelevante para operações 24/7 de IA. Para validar seu storage, você precisa simular a carga mista.
A ferramenta padrão-ouro é o fio (Flexible I/O Tester), mas configurada corretamente.
O Teste de Tortura (Script Exemplo)
O objetivo é saturar o disco com escritas enquanto monitoramos a latência das leituras.
# Terminal 1: Simulando Checkpoint (Escrita Sequencial Massiva)
fio --name=checkpoint_hammer \
--filename=/dev/nvme0n1 \
--ioengine=libaio \
--rw=write \
--bs=1M \
--direct=1 \
--numjobs=1 \
--iodepth=32 \
--rate=2G \ # Limita para simular cenário real, ou remova para estresse total
--time_based --runtime=600
# Terminal 2: Simulando RAG (Leitura Aleatória Crítica)
fio --name=rag_simulation \
--filename=/dev/nvme0n1 \
--ioengine=libaio \
--rw=randread \
--bs=4k \
--direct=1 \
--numjobs=4 \
--iodepth=1 \ # RAG real geralmente tem QD baixo por thread
--time_based --runtime=600 \
--write_lat_log=rag_latency
Após a execução, não olhe apenas para a média. Analise o arquivo de log de latência (rag_latency_lat.1.log) e plote os percentis 99.9th. Se você vir picos acima de 10ms durante a execução do checkpoint, sua arquitetura falhou para inferência em tempo real.
 Figura: Saída do FIO destacando a latência de conclusão (clat) nos percentis superiores, onde os problemas de performance se escondem.
Figura: Saída do FIO destacando a latência de conclusão (clat) nos percentis superiores, onde os problemas de performance se escondem.
Outra ferramenta essencial é o mlat-client (se disponível em seu ambiente de orquestração) ou scripts personalizados em Python que medem a latência ponta-a-ponta da aplicação, inserindo timestamps antes e depois da chamada ao banco vetorial.
O veredito sobre hardware de consumo
É tentador usar SSDs NVMe "Gamer" de alto desempenho (Gen5, 14GB/s) para economizar custos em servidores de inferência locais. Esta é uma economia burra.
SSDs de consumo dependem agressivamente de caches SLC dinâmicos (pseudo-SLC). Durante um checkpoint de 200GB, esse cache se esgota em segundos. A velocidade de escrita cai então para a velocidade nativa da NAND (TLC ou QLC), que pode ser tão baixa quanto 200MB/s, causando um efeito dominó de latência em todo o sistema. Além disso, a falta de capacitores para proteção contra perda de energia (PLP) coloca a integridade dos índices vetoriais em risco a cada hard reset.
 Figura: Anatomia física: A presença de capacitores de proteção (PLP) e DRAM dedicada distingue o hardware Enterprise das opções de consumo.
Figura: Anatomia física: A presença de capacitores de proteção (PLP) e DRAM dedicada distingue o hardware Enterprise das opções de consumo.
Perspectivas para a próxima geração
O armazenamento para IA não é mais sobre "guardar arquivos"; é sobre alimentar pipelines de computação famintos. A separação estrita entre memória e armazenamento está desaparecendo. Tecnologias como CXL (Compute Express Link) prometem trazer pools de memória compartilhada que atuarão como uma camada intermediária entre a VRAM e o NVMe, absorvendo a brutalidade dos checkpoints sem paralisar o barramento.
Até que o CXL se torne onipresente, a recomendação é clara: priorize consistência sobre velocidade de pico. Use NVMe Enterprise, configure isolamento de namespaces e, sempre que possível, utilize caminhos de dados diretos como GPUDirect. A latência que você ignora hoje é a reclamação do usuário de amanhã.
Referências & Leitura Complementar
NVM Express Base Specification 2.0c (2022). Detalhes sobre NVM Sets e Endurance Groups.
NVIDIA GPUDirect Storage Design Guide (2023). Arquitetura de referência para implementação de GDS em Linux.
SNIA (Storage Networking Industry Association). "Performance Workloads for AI/ML". Whitepaper técnico sobre caracterização de I/O.
Malkov, Y. A., & Yashunin, D. A. (2018). "Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs". (Base teórica para entender o I/O do HNSW).
FAQ: Perguntas Frequentes
Qual a diferença fundamental de I/O entre RAG e treinamento de modelos?
O RAG depende de latência ultrabaixa em leituras aleatórias pequenas (4k-16k) para navegar em índices vetoriais. Já o treinamento e fine-tuning exigem throughput massivo para escritas sequenciais (checkpoints), que podem saturar o barramento e bloquear as leituras do RAG.Por que a latência média é uma métrica inútil para storage de IA?
Em inferência, a experiência do usuário é definida pelos piores casos. Uma latência média baixa pode esconder picos de travamento (latência de cauda p99 ou p99.9) causados por contenção de recursos, que quebram a fluidez de um chatbot ou agente de IA.O que é GPUDirect Storage e quando devo implementá-lo?
É uma tecnologia da NVIDIA que permite à GPU transferir dados diretamente do/para o NVMe via DMA, sem passar pela CPU ou RAM do sistema. É vital em cenários de alta largura de banda para evitar que a CPU se torne o gargalo durante o carregamento de datasets ou gravação de checkpoints.Posso usar SSDs NVMe Gen5 de consumo (Gamer) para servidores de inferência?
Não é recomendado para produção. SSDs de consumo sofrem com queda drástica de performance após o esgotamento do cache SLC e carecem de proteção contra perda de energia (PLP), comprometendo a estabilidade e a consistência da latência sob carga sustentada.
Dr. Elena Kovic
Metodologista de Benchmark
"Desmonto o marketing com análise estatística rigorosa. Meus benchmarks isolam cada variável para revelar a performance crua e sem filtros do hardware corporativo."