Telemetria NVMe host-initiated: decodificando a caixa preta do firmware

Aprenda a extrair e analisar logs de telemetria NVMe para investigação forense de falhas em SSDs enterprise, indo muito além dos atributos SMART básicos.
O cenário é clássico e frustrante: um servidor de banco de dados crítico sofre um pico de latência de 5 segundos. O watchdog do kernel dispara, o I/O congela e, em seguida, tudo volta ao normal. Você abre o dmesg, verifica o /var/log/syslog e o que encontra? Nada. Talvez um genérico "nvme0: controller reset due to timeout". O sistema operacional é cego para o que acontece dentro do controlador do SSD. Ele vê apenas a submissão do comando e a ausência da resposta.
Para um investigador forense de sistemas, "não sei" não é uma resposta aceitável. A causa raiz não desapareceu; ela está escondida nos registradores internos e nos buffers de memória do dispositivo de armazenamento. É aqui que entra a Telemetria NVMe Host-Initiated. Não estamos falando de atributos SMART básicos. Estamos falando de extrair o estado da memória do controlador no momento exato do crime.
Resumo em 30 segundos
- Além do SMART: Enquanto o SMART conta erros passados, a Telemetria captura o estado atual da memória, filas e registradores do firmware no momento de uma falha.
- Padronização: Desde a especificação NVMe 1.3, existe um método padrão (Log Pages 0x07 e 0x08) para extrair esses dados sem ferramentas proprietárias obscuras.
- Ação Forense: Você pode (e deve) configurar seus sistemas para disparar a coleta de telemetria automaticamente quando o kernel detectar latências anômalas, permitindo a análise post-mortem real.
O silêncio ensurdecedor dos logs do kernel
Quando um SSD NVMe falha silenciosamente ou apresenta latência de cauda (tail latency), o kernel do Linux atua apenas como um observador externo. O driver NVMe submete um comando na Submission Queue e toca uma campainha (doorbell). Se o firmware do drive entrar em um loop de Garbage Collection agressivo, sofrer um bit flip na sua DRAM interna ou encontrar uma race condition no manuseio da NAND, o host não recebe nenhum código de erro imediato. Ele apenas espera.
A lacuna de observabilidade entre o driver do host e o firmware do dispositivo é o local onde a maioria dos problemas de performance modernos se esconde. Ferramentas como iostat ou sar mostram o sintoma (latência alta), mas nunca a causa.
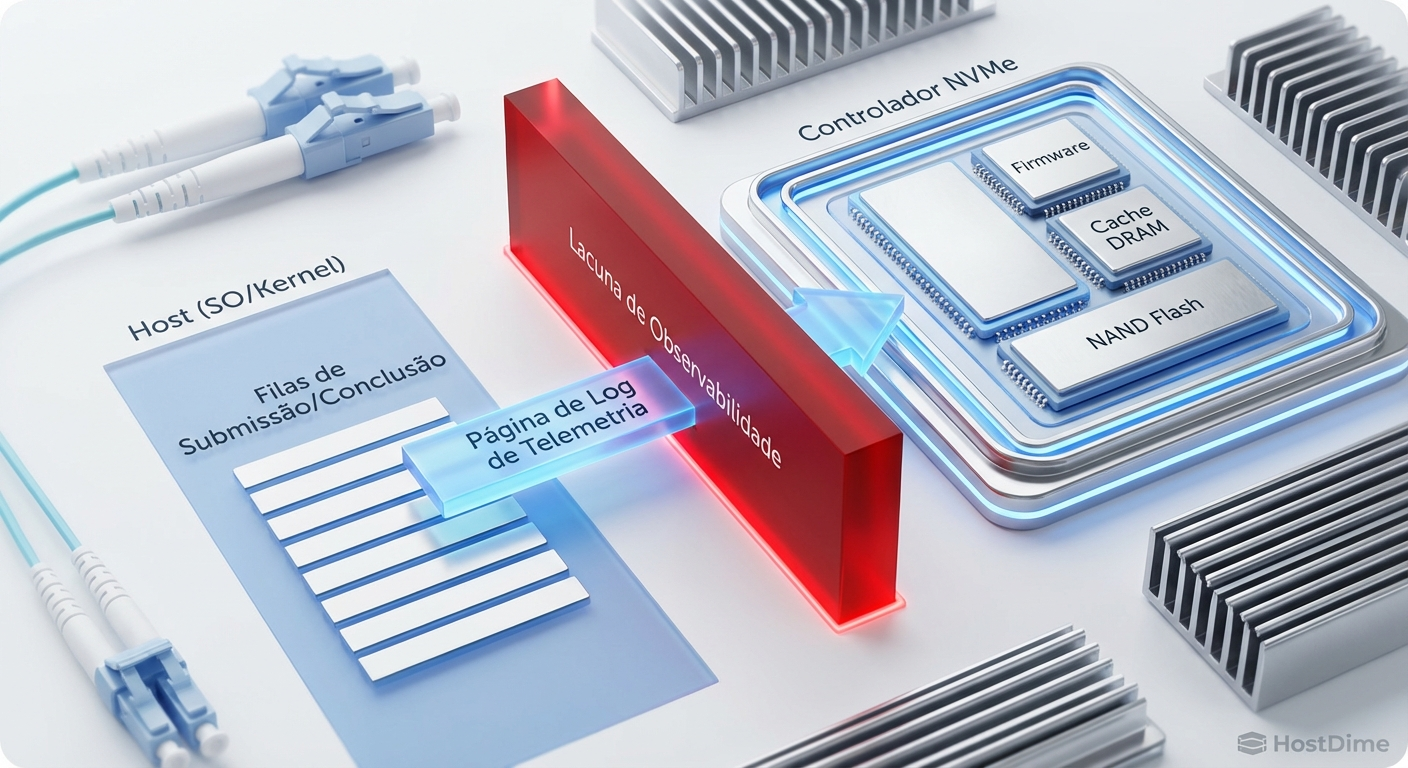 Figura: O abismo de observabilidade: A Telemetria atua como uma ponte direta entre o estado interno do firmware e o sistema operacional, ignorando a abstração das filas de comando.
Figura: O abismo de observabilidade: A Telemetria atua como uma ponte direta entre o estado interno do firmware e o sistema operacional, ignorando a abstração das filas de comando.
Para cruzar essa fronteira, precisamos parar de tratar o SSD como uma caixa preta e começar a tratá-lo como um computador independente que possui seus próprios logs de crash.
Arquitetura do comando Get Log Page: 0x07 e 0x08
A especificação NVM Express introduziu, a partir da versão 1.3, uma estrutura formalizada para telemetria. Antes disso, cada fabricante (Intel, Samsung, Micron) tinha métodos proprietários via Vendor Unique Commands (VUCs), o que tornava a automação em datacenters heterogêneos um pesadelo.
Existem dois tipos de identificadores de log cruciais para nossa investigação:
Log Page 0x07 (Telemetry Host-Initiated): É o foco deste artigo. O host (você ou seu script de monitoramento) decide que algo está errado e solicita um dump do estado atual do drive.
Log Page 0x08 (Telemetry Controller-Initiated): O próprio drive percebe que falhou (ex: um assert no firmware) e prepara um relatório para ser coletado na próxima oportunidade.
A estrutura de dados retornada é dividida em blocos de 512 bytes e organizada em três áreas principais:
Header: Padronizado. Contém identificadores, razão do trigger e tamanhos das áreas de dados.
Data Area 1: Dados de texto ou estruturados legíveis, geralmente contendo configurações básicas e estado de saúde.
Data Area 2 & 3: Onde a mágica (e a dor de cabeça) acontece. São áreas específicas do vendedor, frequentemente contendo dumps da SRAM/DRAM do controlador e trace logs do firmware.
💡 Dica Pro: O bit
Create Host Mesgno comando de telemetria é vital. Se definido como '1', você instrui o controlador a congelar o estado atual e gerar um novo snapshot. Se '0', você apenas lê o último snapshot gerado. Em uma investigação de incidente ativo, sempre force a geração de um novo relatório.
Por que o SMART ignora exceções de firmware
Muitos administradores confundem atributos SMART com telemetria. Essa confusão custa caro em diagnósticos. O SMART é um contador de odômetro; a telemetria é a caixa preta do avião.
Se um firmware encontra uma exceção de divisão por zero e reinicia o controlador em 200ms, o SMART pode, na melhor das hipóteses, incrementar o contador "Unsafe Shutdowns". Ele não lhe dirá onde no código o erro ocorreu ou qual comando estava sendo processado.
Tabela comparativa: SMART vs. Telemetria NVMe
| Característica | Atributos SMART / Health Log | Telemetria NVMe (Host-Initiated) |
|---|---|---|
| Foco | Desgaste físico e estatísticas acumuladas. | Estado lógico instantâneo e depuração. |
| Granularidade | Baixa (contadores incrementais). | Altíssima (dumps de memória, registros, filas). |
| Momento da Coleta | Contínuo (polling). | Sob demanda (incidente) ou pós-falha. |
| Padronização | Alta para atributos básicos, baixa para específicos. | Header padronizado, Payload proprietário. |
| Uso Forense | Previsão de falha de hardware. | Análise de causa raiz de bugs de software/firmware. |
Extração cirúrgica via nvme-cli
Não precisamos de ferramentas gráficas pesadas. O nvme-cli é a ferramenta padrão-ouro para interagir com o subsistema NVMe no Linux. A extração deve ser feita assim que a anomalia é detectada.
O comando base para extrair o log e salvar em formato binário é:
# Solicita a geração de um novo relatório (host-generate) e salva em binário
nvme telemetry-log /dev/nvme0 --host-generate --output-file=incidente_db_01.bin
Este comando envia o opcode de Get Log Page com o LID (Log Identifier) 0x07. O controlador então pausa suas operações de background não críticas para montar o payload.
⚠️ Perigo: A geração de telemetria (
--host-generate) pode induzir latência adicional momentânea enquanto o controlador reúne os dados da sua memória interna. Execute isso em produção apenas se o sistema já estiver comprometido ou se você tiver redundância (RAID/Replication) ativa.
Decodificando o Header
Embora as Áreas 2 e 3 sejam frequentemente binários proprietários que exigem ferramentas do fabricante (como o Intel MAS ou Samsung DC Toolkit) para decodificação completa, o Header é legível e valioso.
Podemos visualizar o cabeçalho sem extrair todo o binário:
nvme telemetry-log /dev/nvme0 --host-generate | head -n 20
O campo mais crítico aqui é o Reason Identifier. A especificação permite que o host informe por que está pedindo a telemetria. Se você está automatizando isso, use códigos específicos para "Timeout", "Data Corruption" ou "Performance Degradation". Isso ajuda os engenheiros do fabricante a priorizar a análise do dump que você enviar.
 Figura: Anatomia de um Payload de Telemetria: O cabeçalho é a chave de acesso universal, enquanto as áreas de dados contêm os segredos profundos do fabricante.
Figura: Anatomia de um Payload de Telemetria: O cabeçalho é a chave de acesso universal, enquanto as áreas de dados contêm os segredos profundos do fabricante.
Correlação de timestamps: o desafio final
Ter o dump é inútil se você não souber quando os eventos internos ocorreram em relação ao relógio do seu servidor. O kernel opera em tempo UTC/Local (Unix Epoch), enquanto o controlador NVMe geralmente opera em "Power On Hours" (POH) ou ciclos de clock internos.
A correlação exige precisão. O comando nvme telemetry-log não retorna o timestamp do kernel. Você deve registrar o date +%s%N (nanossegundos) imediatamente antes e depois de disparar o comando de telemetria.
Dentro do log de telemetria, procure por contadores de tempo. Em drives Enterprise modernos, é comum encontrar referências ao Timestamp global se o recurso Timestamp (Feature Identifier 0x0A) tiver sido configurado pelo host durante a inicialização.
Se o seu sistema não sincroniza o relógio do NVMe regularmente, você terá que fazer a conversão manual:
Extraia o
Power On Hoursdo SMART atual.Extraia o timestamp do evento crítico dentro do log de telemetria (geralmente em ticks ou milissegundos desde o boot).
Faça a regra de três para alinhar com o log do
syslog.
Uma discrepância de 100ms pode significar a diferença entre culpar o drive por um timeout ou descobrir que o problema foi, na verdade, uma preempção do scheduler do host.
 Figura: Sincronização temporal: A única forma de provar a inocência ou culpa do armazenamento é alinhando os relógios do Host e do Controlador.
Figura: Sincronização temporal: A única forma de provar a inocência ou culpa do armazenamento é alinhando os relógios do Host e do Controlador.
O Veredito
A telemetria NVMe Host-Initiated não é apenas uma ferramenta de suporte para fabricantes; é uma arma de defesa para administradores de sistemas e engenheiros de armazenamento. Em um ambiente onde a latência é dinheiro, aceitar a opacidade do firmware é negligência.
Minha recomendação técnica é clara: implemente triggers automáticos em sua infraestrutura. Se a latência de I/O exceder um limiar crítico (ex: 2 segundos), seu sistema de monitoramento deve disparar automaticamente o nvme telemetry-log e salvar o artefato. Quando o fornecedor disser "o hardware está saudável segundo o SMART", você terá o dump da memória provando que o firmware travou em uma race condition. É assim que se resolvem problemas de verdade.
Referências & Leitura Complementar
NVM Express Base Specification 2.0, Section 5.14 (Telemetry Log Pages). Disponível em nvmexpress.org.
OCP (Open Compute Project) Datacenter NVMe SSD Specification, Section on Telemetry Requirements.
Manpage oficial do nvme-cli:
man nvme-telemetry-log.Linux Kernel Documentation:
/Documentation/block/para detalhes sobre o subsistema de bloco e timeouts.
O que é a Telemetria NVMe Host-Initiated?
É um mecanismo padronizado na especificação NVMe 1.3+ que permite ao host (sistema operacional ou administrador) solicitar dumps internos de estado e logs de erro do controlador do SSD. Diferente dos logs passivos, é uma ação deliberada para capturar o contexto de uma falha no momento em que ela é detectada pelo host.Qual a diferença entre SMART e Telemetria NVMe?
O SMART monitora a saúde a longo prazo e estatísticas acumuladas (desgaste da NAND, temperatura, horas ligadas). A Telemetria é um snapshot forense que captura o estado exato da memória RAM, registradores e filas de execução do firmware no momento de um incidente ou crash, permitindo depuração profunda.Preciso de ferramentas proprietárias para extrair a telemetria?
Não para a extração. O comando padrão `nvme-cli` (especificamente `nvme telemetry-log`) pode puxar os dados de qualquer drive compatível com NVMe 1.3 ou superior. No entanto, a decodificação completa do payload binário (especialmente a Data Area 3) geralmente requer ferramentas do fabricante, mas o cabeçalho e a estrutura são padronizados.
Bruno Albuquerque
Investigador Forense de Sistemas
"Não aceito 'falha aleatória'. Com precisão cirúrgica, mergulho em logs e timestamps para expor a causa raiz de qualquer incidente. Se deixou rastro digital, eu encontro."