TrueNAS e ZFS em Produção: O Guia de Arquitetura para Alta Disponibilidade

Guia técnico para arquitetos: do layout de VDEVs à escolha de SLOG com PLP. Evite gargalos de performance e garanta integridade em storage ZFS corporativo.
A arquitetura de armazenamento não é sobre escolher o disco mais rápido ou a interface mais moderna. É sobre gerenciar o inevitável: a falha, a latência e o custo de propriedade ao longo do tempo. Quando falamos de TrueNAS e ZFS em ambientes de produção, frequentemente vejo engenheiros focados na taxa de transferência (throughput) máxima, ignorando completamente o comportamento do sistema sob estresse constante ou durante a reconstrução de um array.
ZFS não é apenas um sistema de arquivos; é um gerenciador de volume lógico com opiniões fortes sobre integridade de dados. Implementá-lo em produção exige entender como ele "pensa" sobre seus dados. Se você tratar o ZFS como um RAID de hardware tradicional, você já começou errado. A disponibilidade não é um produto que você compra, mas uma propriedade emergente de um sistema bem arquitetado.
Resumo em 30 segundos
- RAM é o rei: Antes de pensar em cache SSD (L2ARC), maximize a RAM. O L2ARC consome memória para indexação e pode degradar a performance se o sistema não tiver memória base suficiente.
- O perigo do CoW: O mecanismo Copy-on-Write do ZFS garante integridade, mas gera fragmentação severa ao longo do tempo. Pools cheios (>80%) sofrem de latência de cauda (tail latency) drástica.
- Special VDEV exige Enterprise: Mover metadados para SSDs acelera o sistema, mas cria um ponto único de falha crítico. O uso de SSDs com PLP (Power Loss Protection) e redundância tripla é mandatório aqui.
O sintoma da latência de cauda em pools fragmentados
A promessa do ZFS é a consistência. No entanto, em ambientes corporativos, a consistência de latência é frequentemente mais valiosa que a velocidade bruta. O problema que observamos em clusters de armazenamento que envelhecem não é a falha catastrófica, mas a degradação silenciosa da performance.
Isso ocorre devido à natureza Copy-on-Write (CoW) do ZFS. Ao contrário de sistemas de arquivos que sobrescrevem blocos de dados no local (in-place), o ZFS sempre escreve novos dados em um novo bloco e, em seguida, atualiza os ponteiros de metadados. Em um pool vazio, isso é trivial. O alocador de espaço encontra grandes faixas contíguas e escreve sequencialmente.
O cenário muda drasticamente quando o pool atinge 70% ou 80% de ocupação. O espaço livre torna-se fragmentado. O que deveria ser uma escrita sequencial transforma-se em uma operação de busca aleatória (random seek) desesperada por blocos livres. O resultado é o aumento da latência de cauda (p99 latency). A maioria das suas requisições pode ser rápida, mas aquele 1% mais lento pode travar uma aplicação de banco de dados ou causar timeouts em uma VM crítica.
 Figura: O impacto da fragmentação no mecanismo Copy-on-Write e na latência de busca.
Figura: O impacto da fragmentação no mecanismo Copy-on-Write e na latência de busca.
Como vemos na representação acima, a fragmentação transforma a física do disco mecânico (HDD) no gargalo final. A solução arquitetural não é apenas "adicionar mais discos", mas planejar a capacidade para operar abaixo de 70% ou implementar vdevs de alocação dedicados.
A anatomia do TXG e o custo oculto do Copy-on-Write
Para mitigar a penalidade de escrita do CoW, o ZFS agrupa as escritas em memória RAM antes de enviá-las ao disco. Esse grupo é chamado de Transaction Group (TXG). Por padrão, o ZFS fecha um TXG a cada 5 segundos (ou quando atinge um limite de tamanho) e o descarrega para o disco.
Aqui reside um trade-off clássico de arquitetura. Um TXG grande permite que o ZFS reordene as escritas para otimizar o movimento da cabeça do disco (elevator sorting), transformando escritas aleatórias em sequenciais. Isso é brilhante. No entanto, durante o flush do TXG, o subsistema de I/O pode ficar saturado, bloqueando leituras concorrentes.
Em arquiteturas de alta disponibilidade, ajustar o tamanho e o tempo do TXG é essencial. Se você prioriza a segurança dos dados síncronos (como em bancos de dados via iSCSI/NFS), você precisará de um dispositivo de log separado (SLOG). Mas atenção: o SLOG não é um cache de escrita. Ele é um dispositivo de intenção. As escritas vão para o SLOG apenas para garantir persistência em caso de queda de energia, enquanto ainda residem na RAM para serem organizadas no TXG.
💡 Dica Pro: Nunca use um SSD de consumo para SLOG. A latência de escrita sustentada e a resistência (DWPD) são insuficientes. Você precisa de memória persistente ou SSDs baseados em tecnologia de baixa latência (como Intel Optane ou Kioxia FL6) com capacitores de proteção contra perda de energia (PLP).
Por que o cache L2ARC em SSDs de consumo é uma armadilha
Existe um mito persistente na comunidade de entusiastas e até entre alguns arquitetos júnior de que "adicionar um SSD como cache de leitura (L2ARC) sempre melhora a performance". Isso é demonstravelmente falso em muitos cenários.
O L2ARC (Level 2 Adaptive Replacement Cache) consome memória RAM. Para cada bloco de dados armazenado no SSD de cache, o ZFS precisa manter um registro (header) na RAM para saber onde esse dado está. Se você tem um servidor com 64GB de RAM e adiciona um L2ARC de 2TB, você pode estar consumindo 4GB ou mais de RAM apenas para indexar o cache.
Essa é memória que deixa de ser usada pelo ARC (o cache primário na RAM), que é ordens de magnitude mais rápido que qualquer NVMe. O resultado? Você expulsa dados do cache mais rápido (RAM) para indexar dados no cache mais lento (SSD).
A decisão de usar L2ARC deve ser baseada em métricas, não em intuição.
Verifique a taxa de acerto do ARC (
arc_summary). Se for >90%, você não precisa de L2ARC.Verifique o tamanho do "working set" (dados quentes). Se ele couber na RAM, o L2ARC ficará ocioso.
Se você decidir usar, a escolha do hardware é crítica.
SSDs de consumo (mesmo os NVMe "Pro" ou "Evo") não possuem consistência de latência sob carga. Quando o L2ARC é preenchido, o ZFS precisa escrever nele. Se o SSD engasgar durante uma escrita (garbage collection interna), ele pode travar a leitura, derrotando o propósito do cache.
A engenharia do Special VDEV e a necessidade inegociável de PLP
Uma das inovações mais significativas no OpenZFS recente é o Special VDEV. Esta classe de vdev permite isolar metadados (e opcionalmente blocos de dados pequenos) em dispositivos dedicados, geralmente flash, enquanto os dados brutos permanecem em HDDs rotacionais baratos.
Em termos de TCO (Custo Total de Propriedade), isso é revolucionário. Metadados são pequenos e aleatórios; HDDs odeiam isso. Mover essa carga para SSDs libera os HDDs para fazerem o que fazem melhor: leituras e escritas sequenciais de grandes arquivos.
 Figura: Separação física de cargas de trabalho: Metadados em Flash vs. Dados em Rotacional.
Figura: Separação física de cargas de trabalho: Metadados em Flash vs. Dados em Rotacional.
No entanto, a arquitetura do Special VDEV introduz um risco existencial. Diferente do L2ARC (que se falhar, o sistema apenas perde performance), o Special VDEV é parte integrante do pool. Se o Special VDEV falhar, você perde todo o pool. Não há recuperação.
Por isso, a engenharia dessa camada não aceita cortes de orçamento:
Redundância: Nunca use um único disco. Use espelhamento (Mirror). Para ambientes críticos, recomendo espelhamento triplo (3-way mirror).
PLP (Power Loss Protection): SSDs sem capacitores de proteção de energia podem corromper dados em voo ou suas tabelas de tradução interna (FTL) durante um corte abrupto. Em um Special VDEV, essa corrupção pode tornar o pool inimportável.
Endurance: Metadados sofrem muitas escritas pequenas. SSDs com baixo TBW (Terabytes Written) falharão prematuramente.
⚠️ Perigo: Ao configurar um Special VDEV, certifique-se de que o tamanho do bloco de dados pequenos (
special_small_blocks) esteja ajustado corretamente. Se você configurar para enviar todos os blocos menores que 64K para o SSD, certifique-se de ter capacidade suficiente. Se o Special VDEV encher, os metadados transbordarão para os HDDs, reintroduzindo a latência que você tentou eliminar.
Validação de integridade com métricas de latência reais
Como validamos se nossa arquitetura TrueNAS/ZFS está entregando o que promete? A maioria dos benchmarks sintéticos (como CrystalDiskMark) é inútil para storage enterprise porque testam apenas o cache ou condições ideais.
Precisamos medir a latência sob carga constante (steady state). Ferramentas como fio são o padrão da indústria, mas devem ser configuradas para simular a carga real da aplicação, não apenas números aleatórios.
O que você deve buscar não é a média, mas os outliers. Um sistema de armazenamento saudável deve ter um histograma de latência "apertado".
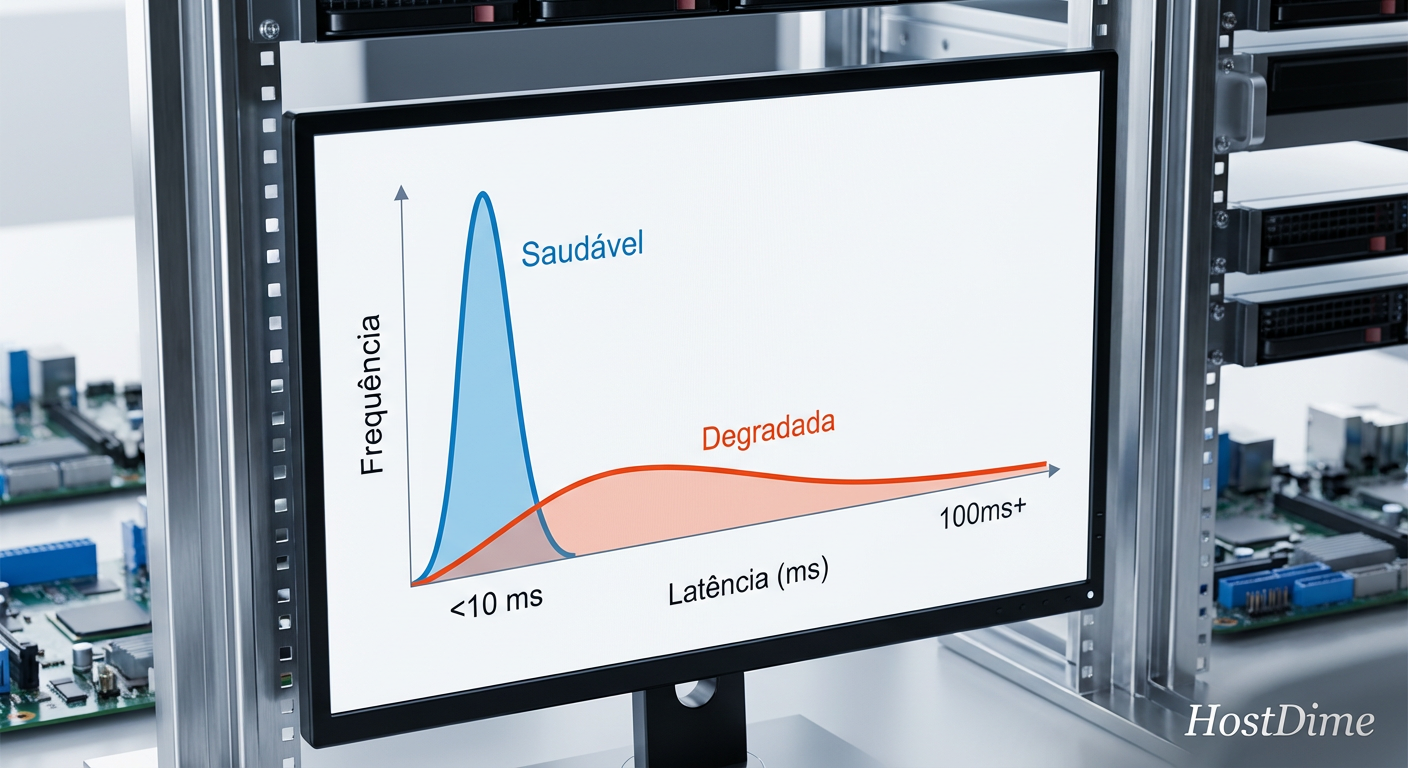 Figura: Histograma de latência: A diferença visual entre um pool saudável e um sofrendo de latência de cauda.
Figura: Histograma de latência: A diferença visual entre um pool saudável e um sofrendo de latência de cauda.
Ao analisar a imagem acima, observe a "cauda longa" na curva degradada. Aqueles poucos I/Os que levam 200ms ou 500ms são os que causam timeouts em aplicações sensíveis. Em um ambiente TrueNAS, você pode monitorar isso via Prometheus e Grafana, extraindo métricas detalhadas do exportador ZFS.
Se você observar essa cauda crescendo, é um indicador antecipado de que:
Seu pool está muito fragmentado.
Seus discos estão próximos da saturação de IOPS.
Um disco específico está falhando silenciosamente (tentando recuperar setores defeituosos e demorando para responder).
O fator humano e a complexidade
A alta disponibilidade (HA) no TrueNAS Enterprise envolve dois controladores (nós) conectados ao mesmo chassi de discos (JBOD) via SAS multipath. Se um nó falha, o outro importa o pool. Parece simples, mas a complexidade operacional aumenta exponencialmente.
Você precisa garantir que o "split-brain" (ambos os nós tentando escrever no disco ao mesmo tempo) seja impossível. O TrueNAS utiliza reservas persistentes SCSI para isso. Mas, em minha experiência, a falha mais comum em HA não é o hardware, é a configuração humana ou atualizações de firmware incompatíveis entre os controladores.
A pergunta que você deve fazer não é "podemos pagar pelo HA?", mas sim "podemos gerenciar a complexidade do HA?". Para muitos cenários, um sistema robusto de replicação ZFS (ZFS Send/Receive) para um segundo servidor "warm standby" oferece um RTO (Recovery Time Objective) aceitável com uma fração da complexidade e custo de um cluster HA ativo-passivo verdadeiro.
Considerações Finais
Arquitetar soluções de armazenamento com TrueNAS e ZFS exige uma mudança de mentalidade: do foco em "velocidade máxima" para "latência previsível". O custo oculto de um pool mal planejado não aparece no dia 1, mas no dia 400, quando a fragmentação atinge o pico e a restauração de um backup demora dias em vez de horas.
Invista em RAM antes de investir em L2ARC. Invista em SSDs Enterprise com PLP para SLOG e Special VDEVs antes de investir em mais capacidade bruta. E, acima de tudo, monitore a latência de cauda, pois ela é o verdadeiro indicador de saúde da sua infraestrutura. O armazenamento é a fundação de todo o stack tecnológico; construa-o sobre rocha, não sobre areia.
Referências & Leitura Complementar
OpenZFS Documentation - Performance and Tuning: Análise detalhada dos parâmetros ajustáveis do ARC e L2ARC.
Micron Technical Brief: "SSD Endurance and Power Loss Protection for Enterprise Storage" – Detalha a física das falhas de NAND sem PLP.
FreeBSD Mastery: ZFS (Michael W. Lucas & Allan Jude): A referência definitiva para entender a mecânica interna do ZFS.
SNIA (Storage Networking Industry Association): "Solid State Storage Performance Test Specification (PTS)" – Metodologia padrão para testes de performance em estado estável.

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."