Zero Downtime: A Fronteira entre Alta Disponibilidade e Alucinação Coletiva

Desmontando o mito do Zero Downtime. Uma análise cínica e técnica sobre SLAs, Teorema CAP, custos de redundância e por que 100% de uptime não existe.
Por: Sysadmin Sênior (que já viu seu "cloud nativo" cair por causa de DNS)
Sentem-se. Não, não toquem nesse switch. E parem de sorrir como se tivessem acabado de descobrir o Kubernetes.
Hoje vamos ter uma conversa difícil. Aquela conversa que o seu CTO visionário — que leu dois artigos no Medium e agora acha que "serverless" significa que não existe hardware — evita a todo custo. Vamos falar sobre a mentira mais lucrativa e perigosa da indústria de TI moderna: o Zero Downtime.
Vocês olham para os SLAs de "cinco noves" (99,999%) e veem uma meta. Eu olho e vejo uma úlcera gástrica e um orçamento estourado. A indústria criou uma alucinação coletiva onde acreditamos que, se empilharmos complexidade suficiente, containers suficientes e camadas de abstração suficientes, poderemos derrotar a entropia.
Spoiler: A entropia sempre vence. E ela geralmente chega numa sexta-feira às 17h45.
O Mito do 100%: Por que a Física (e a Escavadeira) odeiam o seu SLA
Vamos começar com matemática básica, algo que parece ter sido esquecido nas reuniões de planejamento de Q1. Um ano tem 525.600 minutos.
Se você promete 99,9% (Três Noves) de disponibilidade, você tem uma "gordura" de 8 horas e 45 minutos de inatividade por ano. É um tempo razoável para reiniciar um banco de dados, aplicar patches de segurança críticos ou recuperar um backup após o estagiário rodar um DROP TABLE sem WHERE.
Agora, quando o Marketing vende 99,999% (Cinco Noves), sua margem de erro cai para 5 minutos e 15 segundos por ano.
Deixe-me repetir: Cinco minutos. Por ano.
Nesse tempo, você mal consegue logar na VPN, passar pelo MFA e abrir o terminal. A física odeia essa promessa. Roteadores queimam. Raios cósmicos flipam bits em memórias ECC (sim, acontece). E, o predador natural mais eficiente da infraestrutura de fibra óptica — a escavadeira retroescavadeira — não se importa com o seu cluster Kubernetes geo-redundante.
Em 2024, vimos a nuvem da Microsoft (Azure) e a AWS sofrerem interrupções regionais. Se as empresas que literalmente constroem a Internet e possuem orçamentos maiores que o PIB de pequenos países não conseguem garantir 100%, o que faz você pensar que sua equipe de três pessoas e um script em Bash vai conseguir?
O "Zero Downtime" ignora a realidade física de que o hardware falha. A busca pelo 100% não é apenas cara; é matematicamente impossível em um sistema finito. O custo para passar de 99,9% para 99,99% não é linear; é exponencial. Você gasta 10x mais para ganhar segundos que seu usuário final provavelmente nem notaria se o seu frontend tivesse um tratamento de erro decente (o que, spoiler, não tem).
A Falácia do Deploy Contínuo: Quando o 'Rolling Update' vira 'Rolling Disaster'
Ah, CI/CD. A ideia de que podemos empurrar código para produção vinte vezes ao dia sem intervenção humana. "Se doer, faça com mais frequência", dizem os evangelistas do DevOps.
O problema é que automatizamos o sucesso, mas raramente automatizamos o fracasso com a mesma competência.
Em um cenário de Zero Downtime Deployment, utilizamos técnicas como Rolling Updates ou Blue/Green Deployments. Na teoria, substituímos as instâncias da aplicação uma a uma, sem derrubar o serviço. Lindo. Na prática, o que acontece quando a versão v2.0.1 introduz um vazamento de memória sutil que só aparece sob carga real?
O orquestrador (seja K8s ou Nomad) vê que a aplicação subiu e respondeu ao health check (que geralmente é um return 200 OK estúpido que não testa nada real). Ele então mata a versão antiga estável e propaga a versão quebrada para 100% do parque.
Parabéns. Em vez de ter um servidor fora do ar, você agora tem Zero Downtime na entrega de erros 500 para todos os seus clientes simultaneamente.
A lição brutal de incidentes como o da CrowdStrike em julho de 2024 (onde um update defeituoso travou 8,5 milhões de máquinas Windows) é que a velocidade de entrega é inimiga da estabilidade. Um sistema projetado para Zero Downtime que propaga mudanças instantaneamente é apenas um mecanismo muito eficiente de suicídio corporativo.
Checklist de Sobrevivência para Deploys:
Canary Deploys Reais: Não teste em 1% do tráfego. Teste em 1% do tráfego interno primeiro.
Health Checks Semânticos: Seu health check deve testar se o banco responde, não se o servidor HTTP está de pé.
Kill Switch: Se o deploy automatizado é o botão de "Ligar", onde está o botão físico de "Parar tudo agora pelo amor de Deus"?
Arquitetura Active-Active: O Custo Exponencial de Fingir que Falhas não Existem
Aqui entramos no território onde os consultores ganham seus bônus e os sysadmins perdem o sono. A gerência adora o termo "Active-Active". Soa dinâmico. Soa produtivo. "Por que ter um Data Center parado (Passive) se podemos usar os dois?"
Porque sincronização de estado é um inferno, é por isso.
Em uma arquitetura Active-Passive, você tem um primário claro. A escrita vai para lá. Se ele morrer, você promove o secundário. Há um downtime de failover? Sim, talvez 30 segundos ou alguns minutos. Mas a complexidade é gerenciável.
Em uma arquitetura Active-Active real (multi-master), você está tentando escrever em dois lugares ao mesmo tempo e garantir que ambos concordem sobre a verdade.
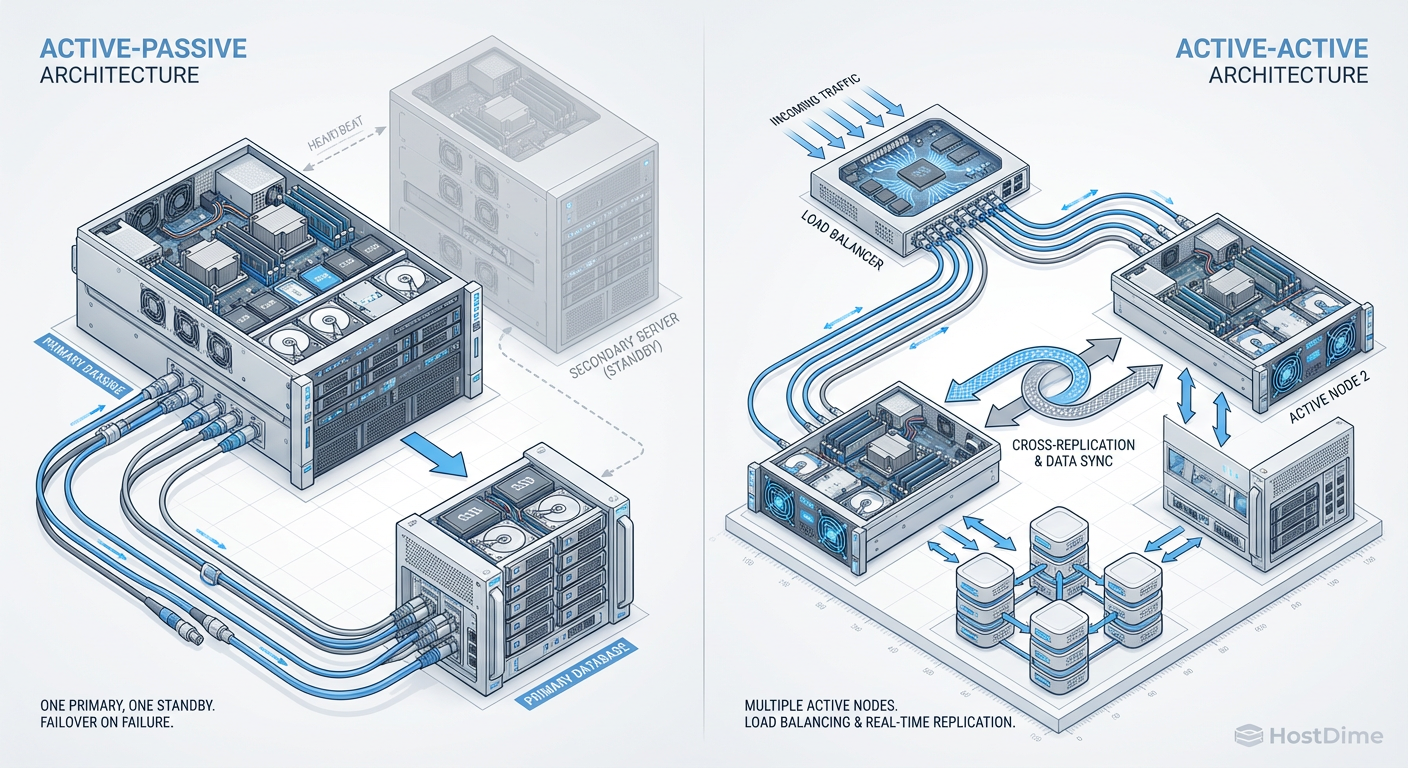 Figura: Fig. 1: A diferença entre ter um estepe no porta-malas (Active-Passive) e tentar dirigir dois carros ao mesmo tempo (Active-Active). A complexidade escala mais rápido que a disponibilidade.
Figura: Fig. 1: A diferença entre ter um estepe no porta-malas (Active-Passive) e tentar dirigir dois carros ao mesmo tempo (Active-Active). A complexidade escala mais rápido que a disponibilidade.
A figura acima ilustra a dor. No Active-Passive, você tem um estepe. No Active-Active, você está tentando dirigir dois carros, em duas estradas diferentes, chegando ao mesmo destino no mesmo milissegundo, enquanto carrega a mesma carga.
Os custos ocultos do Active-Active:
Resolução de Conflitos: O usuário A atualiza um registro no DC 1. O usuário B atualiza o mesmo registro no DC 2, 10ms depois. Quem ganha? Se você respondeu "o último", você acabou de perder dados.
Latência de Replicação: A velocidade da luz é uma limitação chata. Sincronizar dados entre São Paulo e Virgínia (US-East-1) leva tempo. Para garantir consistência forte, você precisa travar a transação até que ambos confirmem. Isso mata sua performance.
Complexidade de Debug: Quando algo quebra no Active-Active, boa sorte descobrindo em qual nó o estado corrompido se originou. É como procurar uma agulha num palheiro, mas o palheiro está em chamas e a agulha é virtual.
A maioria das empresas não precisa de Active-Active. Elas precisam de um failover automatizado decente e de parar de ter medo de 2 minutos de indisponibilidade às 3 da manhã.
O Teorema CAP e a Realidade Distribuída: Escolha dois e não chore
Desenvolvedores adoram ignorar o Teorema CAP (Consistency, Availability, Partition Tolerance). Eles acham que, se usarem o banco de dados NoSQL da moda, podem ter os três.
Eric Brewer provou, e a realidade confirma diariamente: em um sistema distribuído (que obrigatoriamente deve tolerar Partição de rede - o P), você só pode escolher entre:
Consistência (C): Todos veem os mesmos dados ao mesmo tempo. Se a rede falhar, o sistema trava (perde Disponibilidade) para não mentir.
Disponibilidade (A): O sistema sempre responde, mesmo que a rede falhe. Mas ele pode te entregar dados velhos ou conflitantes (perde Consistência).
Para ter Zero Downtime (Disponibilidade total), você deve sacrificar a Consistência durante uma falha de rede.
O que isso significa na prática? Significa que seu carrinho de compras pode mostrar um item que já não tem no estoque. Significa que o saldo bancário pode aparecer diferente no app e no site por alguns segundos.
A "Alucinação Coletiva" é acreditar que podemos enganar o Teorema CAP com "configurações otimizadas". Não podemos. Bancos de dados distribuídos modernos (CockroachDB, Spanner, DynamoDB) fazem mágicas com relógios atômicos e Paxos/Raft, mas no final do dia, se o cabo de fibra submarino for cortado, alguém tem que esperar ou alguém vai ler dado errado.
Tabela: O Preço das Escolhas no CAP
| Escolha | O que você ganha | O que você perde (O Pesadelo) | Exemplo Típico |
|---|---|---|---|
| CP (Consistência + Tolerância a Partição) | Dados sempre corretos. | Downtime. O banco rejeita escritas se não puder falar com o cluster. | Bancos Relacionais Tradicionais, Sistemas Financeiros. |
| AP (Disponibilidade + Tolerância a Partição) | Zero Downtime (teórico). O sistema sempre responde. | Inconsistência. Usuários veem dados fantasmas, "split-brain". | DNS, Caches, Mídias Sociais (Likes). |
| CA (Consistência + Disponibilidade) | O Nirvana. | A Realidade. Não existe em sistemas distribuídos, pois redes falham. | Sua planilha Excel local (até o HD falhar). |
Veredito Técnico: Pare de Prometer Milagres, Comece a Gerenciar o Erro
O Zero Downtime é um termo de marketing, não uma especificação de engenharia. Perseguir essa quimera leva a sistemas frágeis, excessivamente complexos e terrivelmente caros.
A verdadeira maturidade técnica não é impedir que as coisas quebrem — é aceitar que elas vão quebrar e garantir que isso doa o menos possível.
Em vez de gastar milhões tentando alcançar o "quinto nove", invistam em:
Graceful Degradation: Se o microserviço de "Recomendações" cair, a página inicial deve carregar sem ele, e não retornar um erro 500 branco.
Observabilidade Real: Logs que humanos conseguem ler e métricas que alertam sobre sintomas (latência alta), não apenas causas (CPU alta).
Error Budgets (Orçamento de Erro): O conceito de SRE do Google é brilhante. Defina quanto tempo você pode ficar fora do ar. Se você tem 43 minutos de "budget" por mês e só usou 10, ótimo, faça deploys arriscados. Se estourou, congele a produção.
Parem de tentar ser o Google. Vocês não são. E mesmo o Google cai.
A melhor arquitetura é aquela que você consegue explicar e consertar às 3 da manhã, bêbado de sono. Simplicidade é o máximo da sofisticação — e da disponibilidade.
Agora, saiam do meu escritório. Tenho backups de fita para verificar.
Referências & Leitura Complementar
Brewer, E. A. (2000). Towards robust distributed systems. (A origem do Teorema CAP).
Google SRE Team. Site Reliability Engineering: How Google Runs Production Systems. O'Reilly Media. (Especifique o capítulo sobre Error Budgets).
RFC 791: Internet Protocol. (Para lembrar que a rede é hostil por design).
Kleppmann, M. Designing Data-Intensive Applications. O'Reilly Media. (A bíblia para entender por que bancos de dados mentem para você).
CrowdStrike Incident Report (2024): External Technical Root Cause Analysis. (Um estudo de caso moderno sobre como updates automáticos destroem a disponibilidade).

Otávio Henriques
Arquiteto de Soluções Enterprise
"Com duas décadas desenhando infraestruturas críticas, olho além do hype. Foco em TCO, resiliência e trade-offs, pois na arquitetura corporativa a resposta correta quase sempre é 'depende'."