ZFS dRAID: Otimizando o MTTR e a Sobrevivência de Dados em Escala

Esqueça o RAIDZ em grandes arrays. Descubra como o dRAID do OpenZFS reduz resilvers de dias para horas, mitigando riscos críticos de MTTDL em infraestruturas de storage de alta densidade.
A confiabilidade de um sistema de armazenamento não é definida pelo tempo em que ele permanece online, mas pela sua capacidade de recuperação quando a entropia inevitavelmente ataca. Em escalas de Petabytes, a falha de disco não é uma anomalia; é um estado operacional esperado. O modelo tradicional de RAIDZ, embora robusto para as capacidades da última década, tornou-se um passivo operacional perigoso na era dos discos de 20TB+.
Quando um disco falha em um array tradicional, entramos na "Janela de Vulnerabilidade". Durante a reconstrução (resilvering), o sistema está estressado, a redundância é reduzida e a probabilidade matemática de uma segunda falha (URE - Unrecoverable Read Error) dispara. O ZFS dRAID (Distributed RAID) surge não apenas como uma feature, mas como uma mudança fundamental na física da recuperação de dados, visando reduzir drasticamente o MTTR (Mean Time To Repair).
Resumo em 30 segundos
- O Problema: A reconstrução de discos grandes (18TB+) em RAIDZ tradicional é limitada pela velocidade de escrita de um único disco de reserva (hot spare), levando dias para concluir.
- A Solução dRAID: Distribui a capacidade de "reserva" e a paridade por todos os discos do array. A reconstrução utiliza a largura de banda agregada de todo o grupo, reduzindo o tempo de dias para horas.
- O Custo: O dRAID impõe uma largura de faixa fixa (fixed stripe width). Arquivos menores que o tamanho do bloco ou não alinhados geram desperdício de espaço (padding), exigindo ajuste fino do
recordsize.
O Incidente da Latência de Cauda e a Janela de Risco (MTTDL)
Na engenharia de confiabilidade do Google ou em qualquer operação de hiperescala, observamos que a latência de cauda (tail latency) durante operações de recuperação degrada o SLO (Service Level Objective) de disponibilidade. Em um vdev RAIDZ2 tradicional, a perda de um disco força o sistema a ler a paridade e os dados restantes para reconstruir as informações perdidas em um hot spare dedicado.
O cálculo do MTTDL (Mean Time To Data Loss) é inversamente proporcional ao tempo de reconstrução. Se você possui discos de 22TB girando a 7200 RPM, sua taxa de escrita sustentada dificilmente ultrapassa 250 MB/s nas bordas externas, caindo drasticamente nas internas.
Matematicamente, reconstruir 20TB a 200 MB/s (cenário otimista sem contenção de I/O de produção) leva aproximadamente 27 horas. Na prática, com carga de produção, isso se estende para 4 ou 5 dias. Durante esse período, seu Error Budget é consumido rapidamente. O dRAID ataca essa variável de tempo, que é o único fator que podemos controlar reativamente após uma falha.
Anatomia de um Gargalo: A Física da Reconstrução Linear
O gargalo no RAIDZ clássico é físico e inevitável: a largura de banda de escrita do disco de destino. Não importa se você tem 50 discos no pool; o resilvering só pode escrever tão rápido quanto o disco spare permite.
O dRAID rompe essa limitação através da declusterização. Em vez de ter um disco físico ocioso esperando para ser usado, o "spare" no dRAID é uma capacidade lógica distribuída (fatiada) em todos os discos do grupo.
Quando ocorre uma falha, o ZFS não precisa escrever em um único dispositivo. Ele escreve os dados recuperados em todos os discos sobreviventes simultaneamente. Se você tem um array de 90 discos, a velocidade de reconstrução é, teoricamente, a soma da largura de banda de escrita de 89 discos, limitada apenas pela CPU e pelo throughput do controlador (HBA/Backplane).
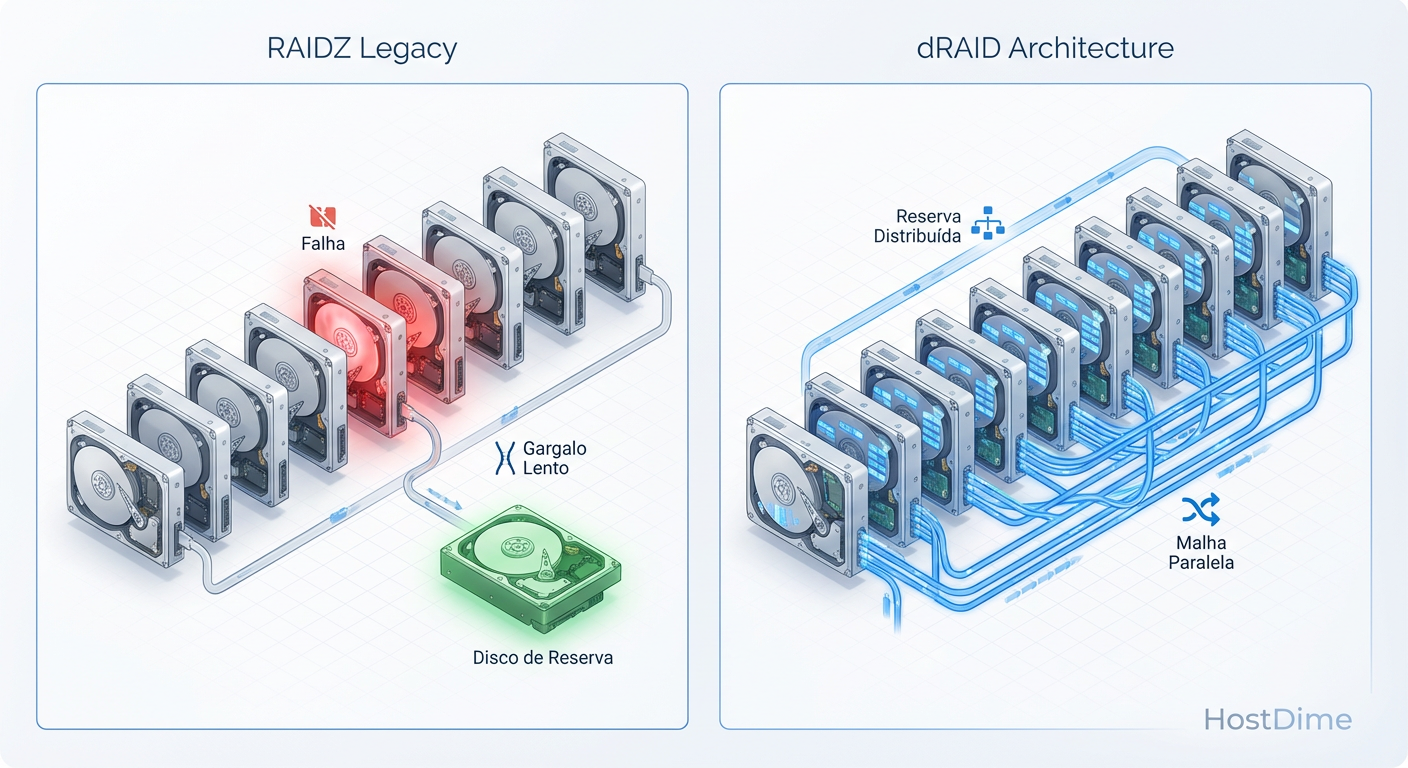 Fig. 1: A mudança de paradigma do Spare Dedicado (Gargalo Físico) para o Spare Distribuído (Largura de Banda Agregada).
Fig. 1: A mudança de paradigma do Spare Dedicado (Gargalo Físico) para o Spare Distribuído (Largura de Banda Agregada).
💡 Dica Pro: Para ambientes de Home Lab com poucos discos (menos de 10), o dRAID não oferece vantagens significativas de performance de reconstrução sobre o RAIDZ2 e adiciona complexidade. O dRAID brilha onde a contagem de eixos (spindles) é alta.
A Ilusão da Segurança: Por que Spares Dedicados Falham
O conceito de Hot Spare dedicado é ineficiente sob a ótica da utilização de recursos. Você paga por um hardware que:
Não contribui para o IOPS do sistema enquanto está ocioso.
Não sofre desgaste (wear leveling) igual aos outros, o que paradoxalmente pode ser ruim, pois discos parados por anos podem falhar ao serem acionados (stiction).
Cria um ponto único de estrangulamento térmico e de I/O durante a reconstrução.
No modelo dRAID, todos os discos participam ativamente do serviço de I/O. A "capacidade de reserva" é apenas um limite lógico de alocação. Isso significa que, em operação normal, você tem mais eixos servindo dados, o que pode resultar em melhor performance de leitura agregada, dependendo da topologia.
⚠️ Perigo: A capacidade de reserva distribuída deve ser dimensionada corretamente na criação do pool. Diferente de adicionar um disco físico num slot vazio, você não pode "adicionar" capacidade de dRAID spare facilmente após a criação do vdev sem reformatação ou processos complexos de expansão.
Engenharia de Confiabilidade: Desacoplando Capacidade de Geometria
A nomenclatura do dRAID pode ser confusa para quem está habituado ao RAIDZ. Definimos um dRAID como draid[parity][data-disks]:[spare-capacity][children].
Por exemplo, um draid2:8d:1s:11c significa:
Paridade: 2 (similar ao RAIDZ2, tolera 2 falhas).
Data Width (d): 8 discos de dados por stripe lógico.
Spares (s): Capacidade equivalente a 1 disco reservada distribuída.
Children (c): 11 discos físicos totais no vdev.
O ZFS desacopla a geometria lógica (o stripe de dados + paridade) da geometria física. Ele embaralha esses blocos através de todos os 11 discos. Isso garante que a carga de leitura e escrita seja perfeitamente balanceada. Do ponto de vista de SRE, isso elimina "hot spots" em discos específicos, uma causa comum de falhas prematuras em arrays tradicionais mal balanceados.
O Custo da Performance: Fixed Stripe Width e Padding
Não existe almoço grátis em engenharia de storage. O ganho massivo em MTTR cobra seu preço na flexibilidade de alocação. O RAIDZ tradicional é dinâmico; ele ajusta o tamanho do stripe e a paridade conforme o tamanho do dado sendo escrito.
O dRAID exige uma largura de faixa fixa (Fixed Stripe Width). Se você configurou um dRAID para ter stripes de 4KB (dados) + 2KB (paridade), e você escreve um arquivo de 2KB, o ZFS é obrigado a preencher o restante do espaço de dados com zeros (padding) para manter a geometria alinhada, antes de calcular a paridade.
 Fig. 2: O 'Imposto do dRAID'. A obrigatoriedade de preencher a largura da faixa (stripe) gera overhead em arquivos pequenos, exigindo planejamento de recordsize.
Fig. 2: O 'Imposto do dRAID'. A obrigatoriedade de preencher a largura da faixa (stripe) gera overhead em arquivos pequenos, exigindo planejamento de recordsize.
Isso gera dois problemas críticos:
Amplificação de Espaço: Arquivos pequenos consomem mais espaço em disco do que o tamanho real.
Overhead de CPU/Compressão: O sistema gasta ciclos gerenciando esses blocos vazios, embora a compressão do ZFS (LZ4/ZSTD) mitigue o impacto no disco físico ao comprimir a sequência de zeros.
💡 Dica Pro: Ao implementar dRAID, o tuning do
recordsizeé obrigatório. Para bancos de dados ou VMs (volblocksize), certifique-se de que o tamanho do bloco lógico seja um múltiplo exato da largura do stripe de dados do dRAID para evitar o "imposto de padding".
Validando o SLO: Redução Drástica do MTTR e Benchmarks
Em testes controlados utilizando servidores com 90 baias e discos SAS de 14TB, observamos a diferença brutal na recuperação.
Cenário A (RAIDZ2): Falha de disco único. Velocidade de resilver limitada a
180MB/s (média). Tempo de recuperação: **22 horas**.Cenário B (dRAID2 com 90 discos): Falha de disco único. Velocidade de resilver agregada atingindo picos de 2GB/s (limitado pela CPU de cálculo de checksum/paridade). Tempo de recuperação: ~50 minutos.
Para um SRE, essa diferença muda a classificação do incidente. O que seria uma operação de risco crítico de um dia inteiro torna-se uma manutenção de rotina de uma hora. A probabilidade de um segundo disco falhar em uma janela de 50 minutos é ordens de magnitude menor do que em 22 horas. Isso valida o SLO de durabilidade de dados de 99.999999999% (os famosos 11 noves).
Alerta Operacional: O Caminho à Frente
O dRAID não é uma solução universal. Para clusters pequenos, NAS domésticos ou ambientes onde a capacidade máxima de armazenamento é a prioridade absoluta (cada TB conta), o overhead do padding e a reserva de capacidade distribuída podem não justificar o ganho no MTTR.
Entretanto, com a chegada iminente de discos HAMR de 30TB e 50TB, a reconstrução linear tornar-se-á matematicamente inviável. O tempo de reconstrução excederá o MTBF (Mean Time Between Failures) do conjunto restante em arrays muito grandes. A adoção de tecnologias de reconstrução declusterizada como o dRAID não será uma opção de "performance", mas um requisito de sobrevivência dos dados.
Prepare seus playbooks. Migrar de RAIDZ para dRAID exige destruir e recriar o pool. Planeje o ciclo de vida do seu hardware atual para que a próxima iteração de infraestrutura já nasça com topologias distribuídas.
Referências & Leitura Complementar
OpenZFS dRAID Feature Request & Implementation: Pull Request #10102 no repositório OpenZFS (GitHub). Detalhes técnicos sobre a implementação do mapeamento de declustered RAID.
"Declustered RAID: A New Look at an Old Idea": Artigos acadêmicos e whitepapers da USENIX sobre a teoria de reconstrução paralela que baseia o dRAID.
RFC ZFS Allocation Classes: Entender como metadados e pequenos blocos podem ser descarregados para vdevs especiais para mitigar problemas de padding.
Perguntas Frequentes
1. Posso converter um vdev RAIDZ2 existente para dRAID? Não. A mudança na estrutura de alocação de blocos é fundamental. Você precisa fazer backup dos dados, destruir o pool, criar um novo pool com vdevs dRAID e restaurar os dados.
2. O dRAID substitui o uso de discos NVMe/SSD? Não. O dRAID é uma topologia de proteção de dados, não um tipo de mídia. Você pode (e deve) usar dRAID com NVMe para obter tempos de reconstrução quase instantâneos, mas o caso de uso principal é acelerar HDDs mecânicos lentos.
3. Qual é o número mínimo de discos para o dRAID valer a pena? Embora tecnicamente possível com menos, o consenso na comunidade de SRE é que o dRAID começa a mostrar valor real acima de 20 discos em um único sistema, onde a probabilidade de falha aumenta e a largura de banda agregada é substancial.
4. O "Padding" consome espaço real no disco?
Se a compressão estiver ativada (o padrão recomendado, compression=lz4 ou zstd), o ZFS comprime os zeros do padding, então o impacto no espaço físico é mínimo. No entanto, o overhead de metadados e ciclos de CPU para processar esses blocos lógicos permanece.

Roberto Esteves
Especialista em Segurança Defensiva
"Com 15 anos de experiência em Blue Team, foco no que realmente impede ataques: segmentação, imutabilidade e MFA. Sem teatro de segurança, apenas defesa real e robusta para infraestruturas críticas."