ZFS dRAID: Por que seus Hot Spares são pesos de papel caros

Descubra como o dRAID no OpenZFS elimina o gargalo de reconstrução do RAIDZ tradicional, transformando dias de risco em horas de recuperação usando geometria distribuída.
Você acabou de receber o alerta do PagerDuty às 3 da manhã. Um disco de 24TB no seu pool principal de arquivamento decidiu encerrar sua carreira precocemente. Se você está rodando uma configuração RAIDZ2 tradicional, parabéns: você acabou de entrar na "Zona de Ansiedade da Resilverização", um lugar onde o tempo passa devagar, a performance do storage cai para o nível de um pendrive USB 2.0 e a probabilidade de um segundo disco falhar durante o processo dispara estatisticamente.
Enquanto você serve o café e observa a barra de progresso estimar "14 dias restantes", sua infraestrutura está essencialmente refém da física mecânica. É aqui que precisamos ter uma conversa séria sobre como a arquitetura de armazenamento tradicional parou no tempo, enquanto a densidade dos discos explodiu.
Vamos falar sobre o OpenZFS dRAID (Distributed RAID) e por que manter discos de hot spare parados no seu chassi é um insulto ao seu orçamento de CAPEX.
Resumo em 30 segundos
- Gargalo físico: Em RAID tradicional, a velocidade de reconstrução é limitada pela velocidade de gravação de um único disco spare, independentemente de quantos discos existam no array.
- Desperdício de capital: Hot spares dedicados são ativos depreciativos que consomem energia e slot, mas não oferecem IOPS nem capacidade até que algo quebre.
- A revolução dRAID: O dRAID distribui a capacidade de reserva (spare) em todos os discos do grupo. Isso permite que todos os discos participem da reconstrução, reduzindo o tempo de recuperação de semanas para horas.
O pânico da resilverização de 24TB
Lembro-me de quando discos de 4TB eram considerados "densos". Naquela época, perder um disco e reconstruí-lo (o processo que o ZFS chama de resilvering) levava algumas horas. Era gerenciável. Você podia ir almoçar e voltar com o array saudável.
Corta para 2026. Estamos empilhando discos de 22TB, 24TB e até 30TB com tecnologia HAMR (Heat-Assisted Magnetic Recording) em JBODs de alta densidade. O problema é que, embora a capacidade tenha aumentado exponencialmente, a taxa de transferência sequencial de um disco mecânico mal dobrou na última década. Estamos tentando encher uma piscina olímpica com a mesma mangueira de jardim que usávamos para encher uma banheira.
Se o seu pool ZFS está cheio de dados e um disco morre, o sistema precisa ler a paridade e os dados restantes para reconstruir o conteúdo perdido. Em um VDEV RAIDZ tradicional, o destino dessa reconstrução é um único disco: o hot spare que acabou de ser ativado.
A física cruel do gargalo de um único atuador
Aqui reside o problema fundamental. Não importa se você tem um servidor com 60 baias e largura de banda de backplane suficiente para transmitir Netflix para um país pequeno. Se você usa hot spares tradicionais, a velocidade de recuperação do seu array é limitada pela velocidade de gravação de um único atuador mecânico.
⚠️ Perigo: Um disco moderno de 7200 RPM sustenta cerca de 250MB/s a 280MB/s em escrita sequencial no início do prato, caindo para metade disso nas trilhas internas. Reconstruir 20TB a uma média de 200MB/s leva, na melhor das hipóteses teóricas, cerca de 28 horas.
Na prática? Adicione a latência de busca (seek time) porque o array ainda está servindo leituras de produção, a fragmentação do ZFS e a sobrecarga de metadados. Essas 28 horas viram facilmente uma semana. Durante essa semana, seus dados estão expostos. Se outro disco falhar (e eles adoram falhar em grupos, já que provavelmente vieram do mesmo lote de fabricação), você pode estar olhando para perda total de dados.
 Fig. 1: A diferença arquitetural de fluxo. No modelo tradicional, o spare é o gargalo. No dRAID, a largura de banda é agregada.
Fig. 1: A diferença arquitetural de fluxo. No modelo tradicional, o spare é o gargalo. No dRAID, a largura de banda é agregada.
A falácia do hot spare dedicado
Vamos falar de dinheiro, porque é isso que o CFO entende. Quando você compra um chassi de 90 baias e define 4 discos como hot spares globais, você está pegando o custo desses 4 discos (mais o custo do slot no chassi, mais a energia para mantê-los girando) e jogando no lixo.
Esses discos são "pesos de papel" glorificados. Eles não contribuem com IOPS. Eles não aumentam sua capacidade de armazenamento. Eles ficam lá, girando, desgastando seus rolamentos, esperando uma catástrofe. É como contratar quatro engenheiros seniores e dizer: "Fiquem sentados no saguão. Se alguém tiver um ataque cardíaco, vocês entram. Até lá, não toquem em nenhum código."
O dRAID elimina esse conceito arcaico. Não existe disco de hot spare dedicado. Existe capacidade de spare distribuída.
Como o dRAID mobiliza todo o chassi
O Distributed RAID (dRAID) no OpenZFS não é apenas uma nova letra no acrônimo; é uma mudança fundamental na topologia dos dados. Em vez de ter um disco físico vazio esperando, o dRAID reserva fatias lógicas de espaço em todos os discos do grupo.
Imagine um array de 90 discos. Em vez de 88 dados + 2 spares, o dRAID espalha os dados e a capacidade de reserva uniformemente pelos 90 discos.
Quando um disco falha, a mágica acontece:
O ZFS identifica os blocos perdidos.
Em vez de escrever para um único disco substituto, ele escreve os dados recuperados na "capacidade de reserva" distribuída em todos os 89 discos restantes.
A leitura necessária para reconstruir a paridade também vem de todos os discos.
O gargalo de um único atuador desaparece. A velocidade de reconstrução agora é limitada pela soma da largura de banda de todos os discos ou, mais frequentemente, pela CPU do seu controlador de storage.
💡 Dica Pro: O dRAID brilha em configurações grandes. Quanto mais discos ("spindles") você tiver no grupo, maior será o fator de multiplicação de performance durante o rebuild. Não tente usar isso em um NAS caseiro de 4 baias; você estará apenas complicando sua vida sem ganho real.
Matemática de fluxo: comparando tempos de recuperação
Vamos colocar números reais nisso. Suponha um pool com discos de 20TB.
Cenário A: RAIDZ2 Tradicional (1 VDEV de 10 discos + 1 Hot Spare)
Falha: Disco 3 morre. Hot Spare ativa.
Fluxo de Escrita: Limitado a 1 disco (~250 MB/s).
Tempo de Rebuild: ~22 a 30 horas (em um sistema ocioso).
Cenário B: dRAID2 (Pool de 50 discos com capacidade de reserva equivalente a 2 discos)
Falha: Disco 3 morre.
Fluxo de Escrita: Distribuído entre 49 discos.
Largura de Banda Potencial: 49 * 250 MB/s = ~12 GB/s (Teórico).
Gargalo Real: Provavelmente sua controladora SAS/HBA ou CPU, digamos que estabilize em 2 GB/s ou 3 GB/s.
Tempo de Rebuild: ~2 a 3 horas.
Reduzir a janela de vulnerabilidade de 30 horas para 3 horas não é apenas "bom". É a diferença entre um incidente operacional menor e ter que explicar ao conselho por que os backups em fita de LTO-9 precisam ser restaurados (o que, a propósito, vai demorar semanas e custar uma fortuna em taxas de recuperação de dados ou egress se você estiver puxando isso de um Glacier da vida).
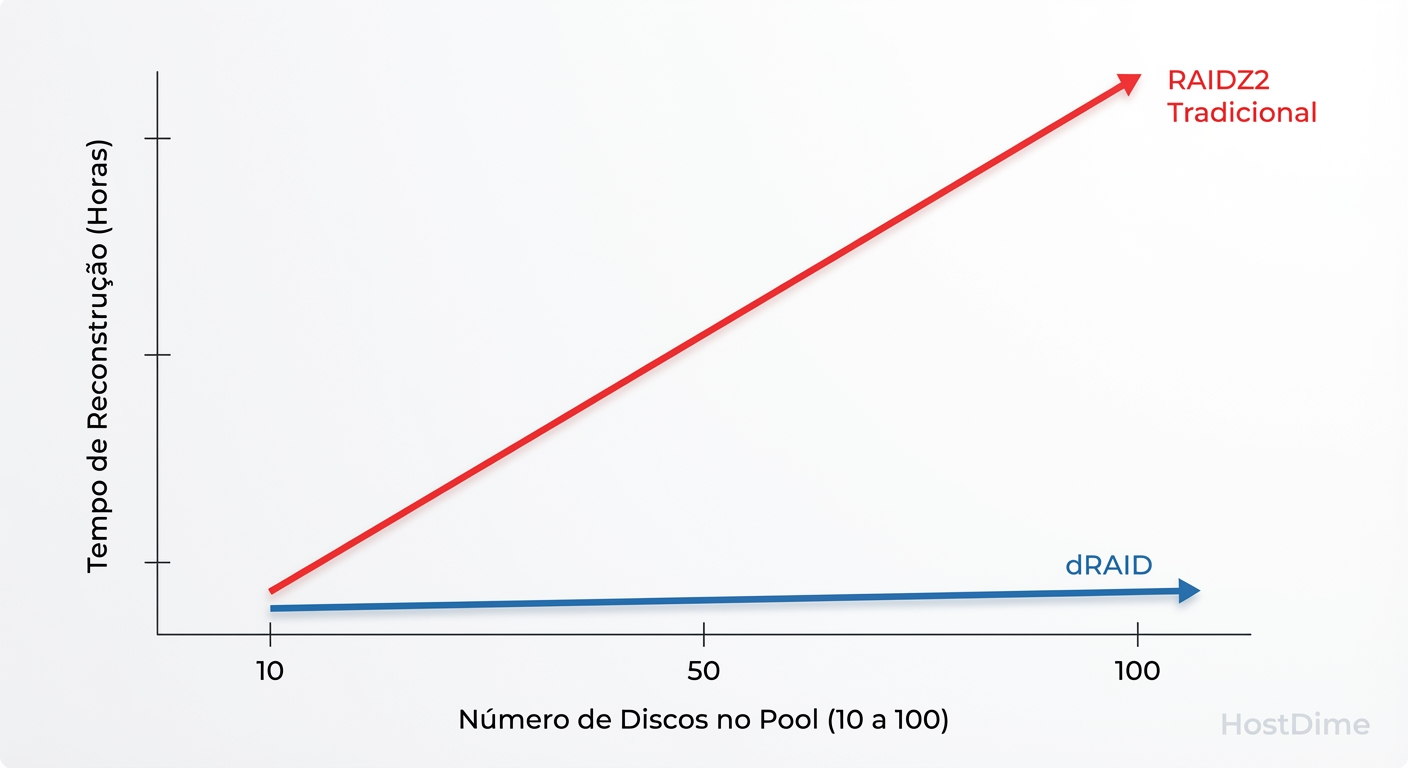 Fig. 2: O impacto da escala. Enquanto o RAIDZ lineariza o tempo de recuperação, o dRAID mantém a performance constante ao adicionar spindles.
Fig. 2: O impacto da escala. Enquanto o RAIDZ lineariza o tempo de recuperação, o dRAID mantém a performance constante ao adicionar spindles.
Nem tudo são flores: As limitações do dRAID
Como arquiteto, meu trabalho é dizer onde as coisas quebram. O dRAID não é mágico e traz suas próprias complexidades:
Rigidez de Expansão: Ao contrário de adicionar VDEVs RAIDZ espelhados ao longo do tempo, o dRAID exige planejamento. Uma vez criado o VDEV dRAID, você não pode simplesmente "adicionar mais um disco" para aumentar a largura do stripe facilmente (embora o recurso de expansão de RAIDZ esteja amadurecendo, o dRAID é mais complexo).
Custo de CPU: Calcular paridade e distribuir dados em larguras de banda massivas exige ciclos de processador. Se você está reciclando aquele servidor Xeon de 2015, pense duas vezes.
Layout Fixo: A capacidade de spare é definida na criação. Se você definiu capacidade para 2 falhas e teve 3, você está em apuros até substituir os discos físicos, assim como no modelo tradicional, mas sem a flexibilidade de simplesmente "plugar qualquer disco em qualquer lugar" tão intuitivamente para técnicos de campo não treinados.
O veredito para sua infraestrutura
Se você gerencia petabytes de dados ou tem chassis com mais de 24 baias, ignorar o dRAID é negligência arquitetural. O modelo tradicional de RAID (seja hardware ou software) não foi projetado para a era dos discos de 20TB+. A matemática da probabilidade de falha durante a reconstrução (MTTDL) tornou-se hostil demais para confiar em um único disco de destino.
Pare de tratar seus discos de spare como apólices de seguro passivas. Coloque-os para trabalhar. O dRAID permite que você utilize todo o IOPS disponível no chassi e transforma o evento de falha de disco — que costumava ser uma crise de dias — em um soluço de algumas horas.
E por favor, pare de pagar para armazenar ar em discos que não fazem nada. A AWS já cobra caro o suficiente pelo egress dos seus backups; não desperdice dinheiro também no seu on-prem.
Perguntas Frequentes
1. Posso converter meu pool RAIDZ2 existente para dRAID? Não. O dRAID é um novo tipo de VDEV. Você precisará criar um novo pool e migrar os dados (zfs send/recv). Sim, é doloroso, mas considere isso uma oportunidade para testar seus backups.
2. O dRAID substitui a necessidade de backups?
Jamais. RAID (distribuído ou não) é redundância para disponibilidade. Se você der um rm -rf acidental, o dRAID vai replicar sua estupidez com eficiência incrível e velocidade recorde.
3. Qual o tamanho mínimo de array para o dRAID valer a pena? A regra geral da comunidade OpenZFS sugere que o dRAID começa a fazer sentido matemático acima de 20 discos. Abaixo disso, a complexidade e a perda de capacidade por padding (preenchimento) podem não compensar os ganhos de tempo de reconstrução.
4. O dRAID funciona com SSDs/NVMe? Sim, e é assustadoramente rápido. No entanto, como SSDs já possuem tempos de reconstrução muito menores que HDDs, o ganho perceptível é menos crítico do que no cenário de "spinning rust" (discos mecânicos). Mas para arrays NVMe de grande escala, ajuda a evitar gargalos de CPU concentrados.
Referências & Leitura Complementar
OpenZFS Documentation: dRAID Feature Description & Management. (Consulte a documentação oficial do branch master para comandos atualizados).
M. Korn et al. (IBM Research): "Declustered RAID: A New Reliability Model for the Future of Storage". (O conceito base que originou implementações como o dRAID).
RFC ZFS dRAID: Detalhes técnicos da implementação de paridade declusterizada no código base do OpenZFS (Disponível no repositório oficial do GitHub).

Rafael Barros
Arquiteto de Cloud Storage
"Desenho arquiteturas de object storage escaláveis e guiadas por API. Meu foco é performance máxima sem deixar o orçamento sangrar com taxas de egress ocultas."