ZFS em NVMe: A Engenharia por Trás do ashift e recordsize para Baixa Latência

Descubra como otimizar pools ZFS em drives NVMe ajustando ashift, recordsize e alinhamento de blocos. Guia técnico para SREs focado em reduzir latência e write amplification.
A latência é o assassino silencioso da confiabilidade. Em um mundo ideal, o armazenamento seria uma superfície plana e previsível. Na realidade, gerenciamos pilhas de abstrações geológicas onde o sistema de arquivos (ZFS) e o firmware do dispositivo (SSD NVMe) frequentemente falam idiomas diferentes. Quando implantamos arrays de flash de alto desempenho, é comum observar um fenômeno perturbador: hardware capaz de centenas de milhares de IOPS entregando uma fração disso sob carga real. O problema raramente é o hardware em si, mas sim o desalinhamento geométrico entre como o ZFS pensa que o disco funciona e como a memória NAND realmente opera.
Resumo em 30 segundos
- A Mentira da Geometria: SSDs modernos mentem sobre o tamanho de seus setores físicos (512b ou 4k) para manter compatibilidade, mas operam internamente com páginas de 8k, 16k ou maiores.
- O Custo do Desalinhamento: Configurar
ashiftourecordsizeincorretamente gera Amplificação de Escrita (Write Amplification), onde uma pequena gravação lógica força o dispositivo a reescrever grandes blocos físicos, destruindo a latência e a vida útil do drive.- Sintonização Fina: Para cargas de banco de dados (OLTP), alinhar o
recordsizedo ZFS com o tamanho da página da aplicação (ex: 16k para InnoDB) é a intervenção de maior impacto para reduzir a latência de cauda (p99).
A primeira regra da engenharia de confiabilidade de armazenamento é: não confie no que o disco diz ao sistema operacional. Historicamente, discos rígidos operavam com setores de 512 bytes. Para evitar que sistemas operacionais legados quebrassem, a indústria de SSDs adotou uma emulação (512e), apresentando-se logicamente como setores pequenos, mesmo que sua estrutura física (NAND pages) fosse de 4KiB, 8KiB ou 16KiB.
Quando o ZFS envia uma gravação menor do que o tamanho real da página física da NAND, o controlador do SSD é forçado a executar um ciclo de Read-Modify-Write (RMW). Ele deve ler a página física inteira para a memória DRAM do drive, modificar a pequena parte solicitada e gravar a página inteira de volta em um novo bloco livre (devido à natureza erase-before-write da flash).
⚠️ Perigo: Esse processo é invisível para o sistema operacional, mas catastrófico para seus SLIs (Service Level Indicators). O que deveria ser uma operação de microssegundos se transforma em milissegundos de latência de cauda, causando jitter na aplicação.
Em um ambiente de homelab ou enterprise, ignorar essa camada física é negligência. O ZFS, sendo um sistema Copy-on-Write (CoW), já possui seu próprio overhead. Somar o CoW do sistema de arquivos ao RMW do firmware do SSD cria uma tempestade perfeita de latência.
A Geometria Oculta: Por que ashift=12 pode estar matando seu SSD
A propriedade ashift define o tamanho mínimo do bloco de alocação no ZFS (2 elevado à potência de ashift). Durante anos, o conselho padrão foi: "use ashift=12 (4KiB) para discos modernos". Em 2025, essa recomendação tornou-se perigosamente simplista para NVMe de alta densidade.
Muitos SSDs de consumo de alta capacidade (como as séries QLC) e até drives enterprise (como certos modelos Kioxia ou Samsung PM series) possuem tamanhos de página física interna de 8KiB ou 16KiB. Se você cria um pool com ashift=12 (4k) em um drive cuja página física real é 16k, o ZFS pode tentar gravar dois blocos de 4k independentes. O SSD, por sua vez, pode ter que realizar duas operações de programação na mesma página física ou espalhá-las de forma ineficiente, aumentando drasticamente a amplificação de escrita (WAF).
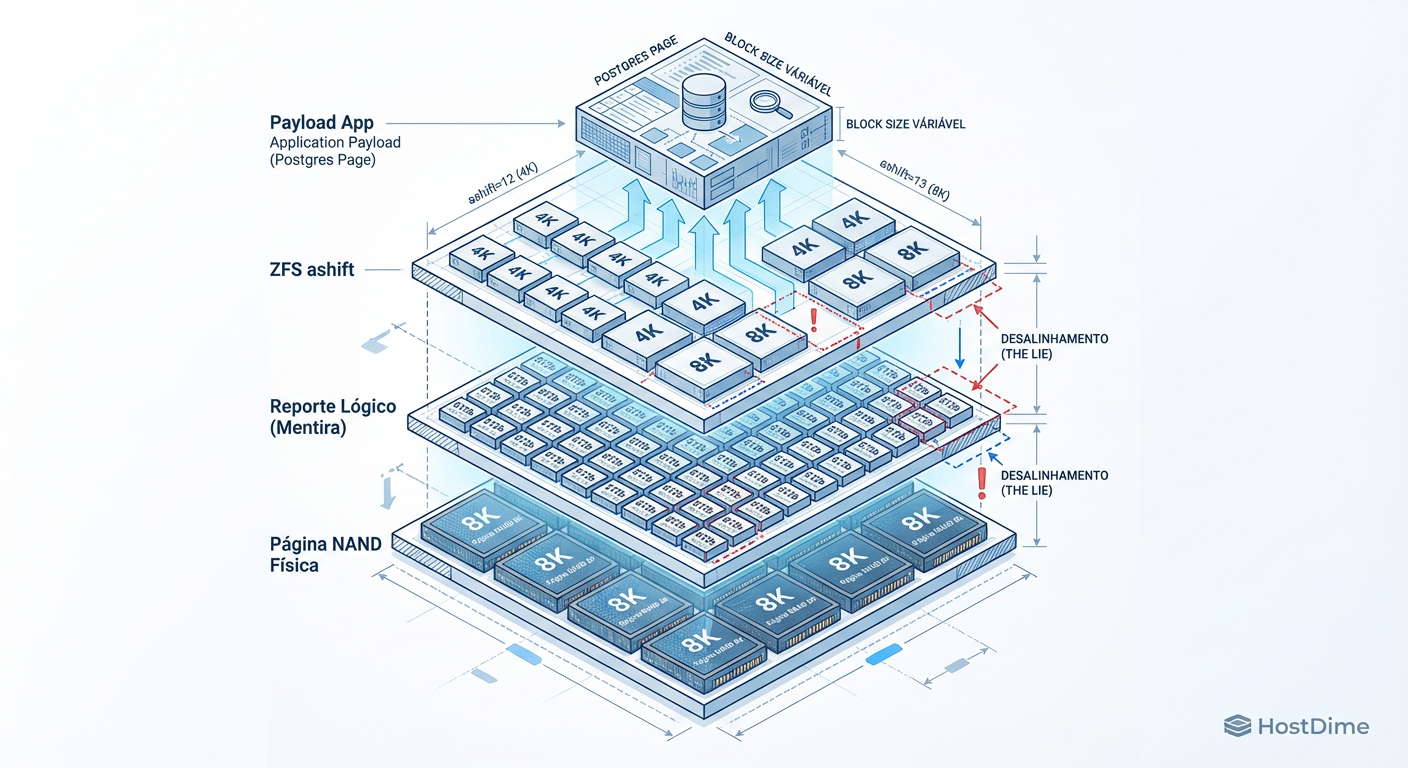 Fig. 2: A Pilha de Abstração de Armazenamento. O desalinhamento entre a geometria física real da NAND e a configuração lógica do ZFS cria gargalos invisíveis.
Fig. 2: A Pilha de Abstração de Armazenamento. O desalinhamento entre a geometria física real da NAND e a configuração lógica do ZFS cria gargalos invisíveis.
Para descobrir a verdade, não basta olhar o datasheet de marketing. É necessário investigar as especificações técnicas profundas ou realizar testes de fio (Flexible I/O tester) comparando IOPS e latência com diferentes alinhamentos.
💡 Dica Pro: Para SSDs NVMe modernos, especialmente QLC ou de alta capacidade (>4TB), considere testar
ashift=13(8KiB). Embora você perca um pouco de eficiência de espaço em arquivos minúsculos, a redução na sobrecarga do controlador do SSD e o ganho na vida útil (endurance) frequentemente compensam. Lembre-se: oashifté imutável após a criação do VDEV.
Sintonizando o Payload: O impacto crítico do recordsize em Bancos de Dados
Enquanto o ashift lida com a camada física, o recordsize dita o comportamento lógico do ZFS. O padrão do ZFS é recordsize=128k. Isso é excelente para streaming sequencial de vídeo ou backups (throughput), mas é desastroso para cargas de trabalho aleatórias como bancos de dados (IOPS e Latência).
Imagine um banco de dados PostgreSQL. Ele opera com páginas de 8k. Quando o PostgreSQL precisa alterar uma linha, ele grava uma página de 8k. Se o seu ZFS está configurado com recordsize=128k, o ZFS precisa ler o bloco de 128k inteiro, modificar os 8k relevantes e gravar os 128k novamente (devido ao CoW). Isso é uma amplificação de 16x na camada do sistema de arquivos, antes mesmo de chegar ao disco.
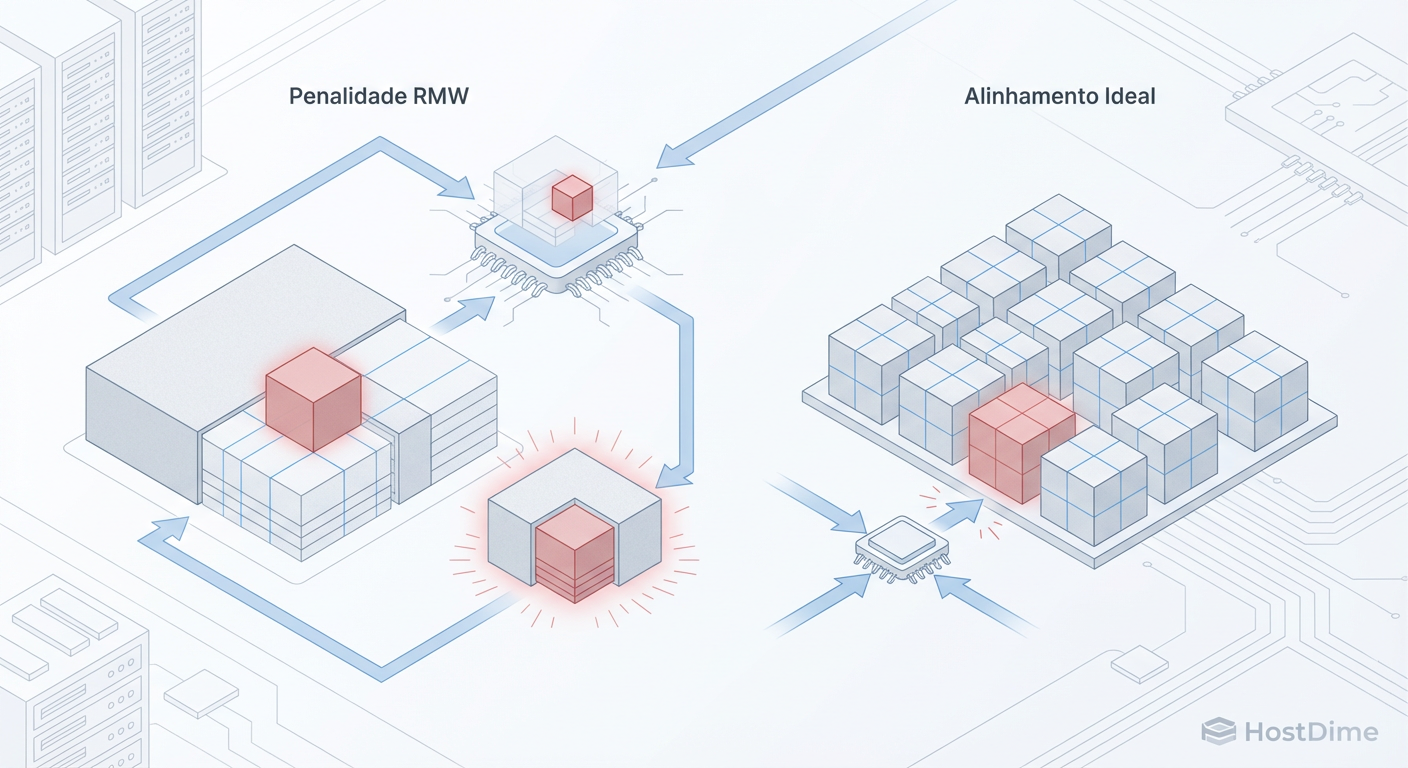 Fig. 1: O ciclo vicioso do Read-Modify-Write (RMW). Um recordsize desajustado obriga o controlador a ler e reescrever blocos inteiros para pequenas alterações, multiplicando a latência.
Fig. 1: O ciclo vicioso do Read-Modify-Write (RMW). Um recordsize desajustado obriga o controlador a ler e reescrever blocos inteiros para pequenas alterações, multiplicando a latência.
Esse desalinhamento consome largura de banda do barramento PCIe, ciclos de CPU para cálculo de checksum e, crucialmente, espaço no ARC (Adaptive Replacement Cache). O cache fica poluído com dados que a aplicação não solicitou.
Tabela de Alinhamento Recomendado
| Aplicação / Workload | Padrão da App | ZFS recordsize Ideal | Benefício Principal |
|---|---|---|---|
| PostgreSQL | 8 KiB | 8 KiB (ou 16k com compressão) | Redução de RMW e Latência |
| MySQL / InnoDB | 16 KiB | 16 KiB | Alinhamento de Página |
| BitTorrent / VM Images | Variável | 64 KiB - 1M | Throughput Sequencial |
| Logs de Texto | Streaming | 128 KiB (Default) | Compressão Eficiente |
Ao alinhar o recordsize com a aplicação, transformamos operações de modificação (RMW) em operações de substituição pura ou gravação nova, aliviando a pressão sobre o subsistema de armazenamento.
O Custo da Abstração: Overhead de Metadados e Fragmentação em Flash
Reduzir o recordsize parece uma bala de prata para latência, mas na engenharia de confiabilidade, não existem soluções, apenas trade-offs. Ao configurar recordsize=4k ou 8k em todo o dataset, aumentamos drasticamente a quantidade de metadados que o ZFS precisa gerenciar.
Cada registro (record) no ZFS requer um ponteiro de bloco (blkptr), que contém checksums, endereços físicos e atributos de transação. Se você tem 1TB de dados:
Com
recordsize=128k: Você tem cerca de 8 milhões de registros.Com
recordsize=8k: Você tem cerca de 134 milhões de registros.
O processamento desses metadados consome CPU e, mais importante, IOPS. Em SSDs NVMe, isso é menos problemático do que em HDDs mecânicos, mas ainda introduz overhead. Além disso, a compressão do ZFS (LZ4 ou ZSTD) funciona no nível do registro. Comprimir blocos de 4k é notoriamente ineficiente; o algoritmo mal tem contexto suficiente para encontrar padrões repetitivos.
💡 Dica Pro: Utilize datasets segregados. Mantenha o sistema operacional e binários em
recordsizepadrão. Crie um dataset específico para os arquivos de dados do banco (ex:/var/lib/postgresql/data) e aplique o tuning fino apenas ali. Nunca apliquerecordsizepequeno globalmente no pool.
Monitoramento e Observabilidade: Métricas que importam (SLIs de Storage)
Como SREs, não podemos melhorar o que não medimos. O comando zpool iostat -v 1 é útil para uma visão rápida, mas é insuficiente para diagnósticos de latência complexos. Precisamos observar a distribuição da latência, não apenas a média.
Para um monitoramento eficaz de Storage em ZFS sobre NVMe, foque nestes SLIs:
Latência de Disco por Percentil (p90, p99): A média esconde os picos. Se a média é 0.5ms mas o p99 é 100ms, seu banco de dados está travando para 1% das requisições. Ferramentas baseadas em eBPF (como
biolatencydo pacote bcc-tools) são essenciais aqui para ver a latência real entregue pelo dispositivo NVMe.ARC Hit Rate (Metadata vs. Data): Um
recordsizemuito pequeno pode explodir o tamanho dos metadados, expulsando dados úteis do cache. Monitorekstat.zfs.misc.arcstats.meta_used. Se os metadados consumirem mais de 25-30% do ARC, reavalie seurecordsize.Dirty Data Sync Time: O ZFS agrupa gravações em Transaction Groups (TXGs). O tempo que leva para "limpar" (sync) esses dados para o NVMe é crítico. Se o sistema engasga durante o sync, você verá picos de latência de leitura.
Amplificação de Escrita (WAF): Compare a quantidade de dados lógicos escritos pela aplicação versus a quantidade de dados físicos escritos na NAND (disponível via SMART/NVMe logs). Um WAF alto (>2.0 em workloads sequenciais ou >5.0 em randômicos) indica desalinhamento de
ashiftourecordsize.
O Futuro é Zoned (Previsão Técnica)
Estamos nos aproximando do limite do que a camada de tradução de flash (FTL) tradicional pode suportar sem introduzir latência inaceitável. A tendência para os próximos anos é a adoção de ZNS (Zoned Namespaces) em NVMe.
Neste modelo, a responsabilidade de gerenciar a geometria da flash sai do firmware do SSD e sobe para o sistema de arquivos. O ZFS já está evoluindo para suportar gravação sequencial em zonas, eliminando a necessidade de "Garbage Collection" dentro do drive. Isso alinhará perfeitamente a estrutura log-structured do ZFS com a física da NAND, potencialmente eliminando o problema do ashift como o conhecemos hoje. Até lá, a engenharia manual de geometria continua sendo um requisito obrigatório para alta performance.
Perguntas Frequentes
1. Mudar o ashift ou recordsize afeta dados existentes?
O ashift é definido na criação do VDEV e não pode ser alterado sem destruir e recriar o pool. O recordsize pode ser alterado a qualquer momento, mas afeta apenas novos arquivos criados ou modificados após a mudança. Para aplicar a arquivos existentes, você deve reescrevê-los (ex: zfs send | zfs recv ou copiar o arquivo).
2. O ZFS em NVMe precisa de um dispositivo SLOG (ZIL) separado? Geralmente não, a menos que você tenha requisitos de durabilidade síncrona extremos e seu pool principal seja feito de flash QLC lenta. Se o pool principal já é NVMe TLC de alta qualidade, adicionar um SLOG (mesmo que Optane) traz ganhos marginais de latência para a maioria dos workloads, adicionando complexidade e pontos de falha.
3. Por que não usar sempre ashift=13 (8k)?
Se você usar ashift=13 em um drive que nativamente é 4k, você desperdiçará espaço. Qualquer arquivo menor que 8k ocupará 8k físicos. Em sistemas com milhões de pequenos arquivos de log ou código fonte, esse desperdício (slack space) pode reduzir a capacidade efetiva do pool em 20-30%.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Seção sobre Namespaces e LBA Formats. Entenda como o drive reporta sua geometria.
OpenZFS Documentation - Performance Tuning: Documentação oficial sobre parâmetros de tunning de VDEV e Dataset.
Micron 7450 SSD Datasheet (2024): Exemplo técnico de mapeamento de 4KB vs 16KB em drives Enterprise.
PostgreSQL Documentation - Resource Consumption: Detalhes sobre a arquitetura de Pages e WAL do Postgres.

Roberto Sato
Planejador de Capacidade
"Traduzo métricas de consumo em modelos de crescimento sustentável. Minha missão é antecipar gargalos e garantir que sua infraestrutura escale matematicamente antes de atingir o limite crítico."