ZFS Híbrido: A Arbitragem de Latência que o Seu CFO Vai Amar

Esqueça o All-Flash. Descubra como special vdevs e tiering NVMe no ZFS entregam 90% da performance por 40% do custo em 2026.
A era do "All-Flash para tudo" encontrou um obstáculo formidável em 2026: a voracidade da Inteligência Artificial. Enquanto arquitetos de soluções celebravam a paridade de preço prevista entre SSD e HDD no início da década, a realidade de mercado impôs uma correção brutal. A demanda insaciável por armazenamento de alta performance para alimentar pipelines de treinamento e inferência de LLMs (Large Language Models) criou uma escassez artificial e elevou o custo por terabyte da memória NAND.
Para o CFO moderno, isso não é apenas um problema de TI; é um problema de alocação de capital. Continuar tratando armazenamento de dados frios ou mornos como ativos de alta performance é um erro de OPEX que corrói a margem operacional. É aqui que entra a arquitetura de ZFS Híbrido, não como uma tecnologia de "legado", mas como uma ferramenta sofisticada de arbitragem de latência.
Resumo em 30 segundos
- O Cenário de 2026: A demanda de IA por armazenamento rápido inflacionou o preço dos SSDs Enterprise, tornando o modelo "All-Flash" proibitivo para dados gerais.
- A Estratégia: O ZFS Híbrido utiliza "Special VDEVs" para armazenar metadados em flash e dados brutos em HDD, entregando performance de SSD na navegação com custo de disco mecânico.
- O Resultado Financeiro: Essa arquitetura permite uma redução drástica no TCO (Custo Total de Propriedade), alocando o CAPEX caro (NVMe) apenas onde ele gera retorno tangível em IOPS.
O imposto da IA sobre o preço do flash em 2026
A dinâmica de oferta e demanda do mercado de semicondutores sofreu uma ruptura. Com os grandes hyperscalers absorvendo a produção global de chips NAND de alta densidade (QLC e TLC) para alimentar clusters de computação de IA, o custo do armazenamento flash enterprise parou de cair e, em muitos segmentos, subiu.
Para um departamento de FinOps, ignorar essa macroeconomia é negligência. Ao projetar um novo cluster de armazenamento, seja um TrueNAS Scale para uma PME ou uma SAN baseada em ZFS para virtualização, insistir em arrays puramente flash para cargas de trabalho mistas é pagar um "imposto de IA" desnecessário.
O custo por TB do disco mecânico (HDD) continua sendo a âncora de valor para retenção de dados em escala. A diferença de preço entre um HDD Enterprise de 24TB e um SSD Enterprise de capacidade equivalente aumentou, ampliando o delta de eficiência de capital. O objetivo, portanto, não é eliminar o HDD, mas mitigar sua única fraqueza: a latência mecânica.
A falácia do datacenter all-flash para dados não estruturados
Existe uma dissonância cognitiva no mercado de storage. Vendedores de hardware empurram soluções NVMe completas sob a promessa de "simplicidade de gestão" e "performance garantida". No entanto, a análise de telemetria de dados reais mostra que, em ambientes de arquivos não estruturados (SMB/NFS, repositórios de backup, arquivos de mídia), a regra de Pareto é implacável.
Aproximadamente 80% dos dados gravados tornam-se "frios" em questão de dias ou semanas. Manter um PDF acessado pela última vez em 2024 num drive NVMe Gen5 é o equivalente digital a alugar um escritório na Avenida Faria Lima para guardar caixas de arquivo morto. É um desperdício de CAPEX premium.
💡 Dica Pro: Utilize ferramentas de análise de dados como o
zfs-statsou relatórios do TrueNAS para auditar a "temperatura" dos seus dados. Se menos de 20% do seu pool é acessado diariamente, você é o candidato ideal para a arbitragem de latência híbrida.
A matemática da arbitragem de latência via special vdevs
A grande inovação do OpenZFS que permite essa engenharia financeira chama-se Special VDEV (ou Allocation Classes). Diferente do cache tradicional (L2ARC), que é volátil e oportunista, o Special VDEV é uma parte integrante e persistente do pool de armazenamento.
A mágica acontece na separação de responsabilidades:
Metadados e Pequenos Blocos: São direcionados fisicamente para dispositivos flash (SSDs/NVMe).
Dados Brutos (Payload): Permanecem nos discos mecânicos (HDDs).
Por que isso importa para o seu ROI? Porque a "sensação" de lentidão em um sistema de armazenamento raramente vem da taxa de transferência (throughput) de um arquivo grande. Ela vem da latência de busca (seek time) ao listar diretórios, encontrar arquivos ou ler pequenos blocos de dados.
Ao mover 100% dos metadados para o flash, operações como ls, find, ou a indexação de um banco de dados ocorrem na velocidade do silício, não na velocidade de rotação de um prato magnético. Você está, efetivamente, arbitrando a latência: entregando a experiência de usuário (UX) de um sistema All-Flash, mas pagando o custo por TB de um sistema mecânico.
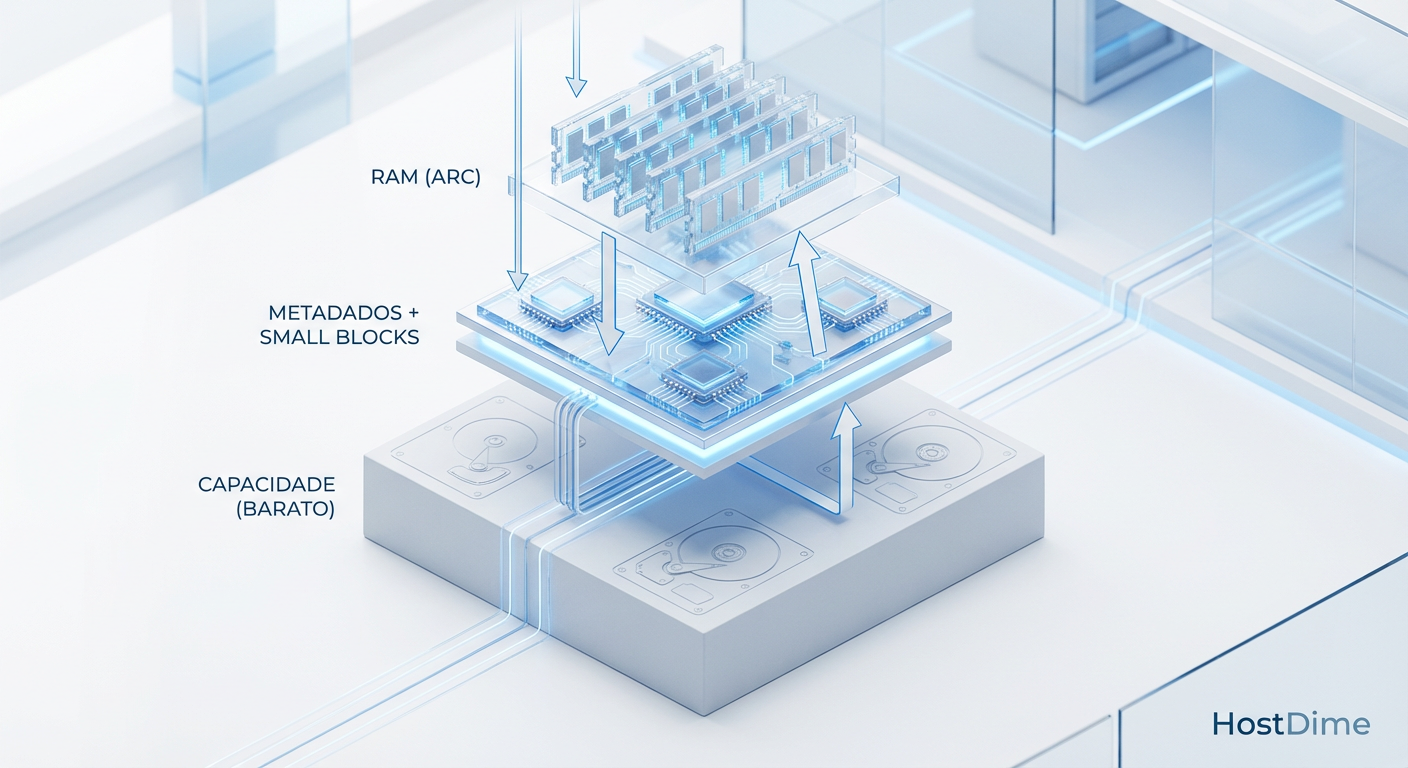 Fig 1. A Hierarquia de Valor: Onde cada dólar investido retorna mais IOPS.
Fig 1. A Hierarquia de Valor: Onde cada dólar investido retorna mais IOPS.
Mitigando o risco catastrófico na arquitetura de metadados
Aqui reside o ponto de inflexão onde a economia pode se tornar um desastre se mal arquitetada. O Special VDEV não é um cache; ele contém os metadados primários. Se você perder esse dispositivo, você perde todo o pool de armazenamento. Os dados nos HDDs tornam-se um amontoado de bits ilegíveis sem o mapa de alocação.
Do ponto de vista de gestão de risco, a economia feita na compra de HDDs deve subsidiar a redundância e a qualidade do flash utilizado no Special VDEV.
Redundância Obrigatória: Nunca utilize um único SSD para metadados. O padrão mínimo é um espelhamento (Mirror/RAID 1) de três vias para ambientes críticos, ou duas vias para laboratórios e ambientes menos sensíveis.
Endurance (DWPD): Metadados sofrem escritas intensas. SSDs de consumo (QLC sem DRAM) vão falhar prematuramente, gerando custos de substituição e risco operacional. O investimento deve ser em drives Enterprise ou, idealmente, memória de classe de armazenamento (como Intel Optane usada, ainda disponível no mercado secundário e altamente eficiente para latência).
⚠️ Perigo: Jamais adicione um Special VDEV ao seu pool ZFS sem redundância física. A falha desse vdev resulta na perda total e irreversível do zpool, independentemente da saúde dos seus HDDs. Trate esses drives como os componentes mais críticos da sua infraestrutura.
Convertendo eficiência de IOPS em margem operacional
A implementação de ZFS Híbrido não é apenas uma decisão técnica; é uma estratégia de defesa de margem. Vamos analisar o TCO de um servidor de arquivos de 500TB brutos projetado para 2026.
Cenário A: All-Flash (QLC Enterprise) O custo inicial é astronômico. Além do preço dos drives, o consumo energético (watts/TB) em idle de arrays flash de alta densidade pode surpreender, e a necessidade de controladoras PCIe com muitas pistas encarece o chassi.
Cenário B: Híbrido (HDD + NVMe Special VDEV) Você adquire HDDs de alta capacidade (ex: 22TB ou 24TB), que oferecem o menor custo por watt e por slot. Adiciona-se uma camada fina (geralmente 0.3% a 1% da capacidade total) de armazenamento NVMe de altíssima resistência para os metadados.
O resultado é uma curva de custo marginal onde cada dólar adicional gasto em NVMe para metadados retorna um ganho exponencial em IOPS percebidos (especialmente IOPS aleatórios), enquanto o custo de armazenamento de massa permanece linear e baixo.
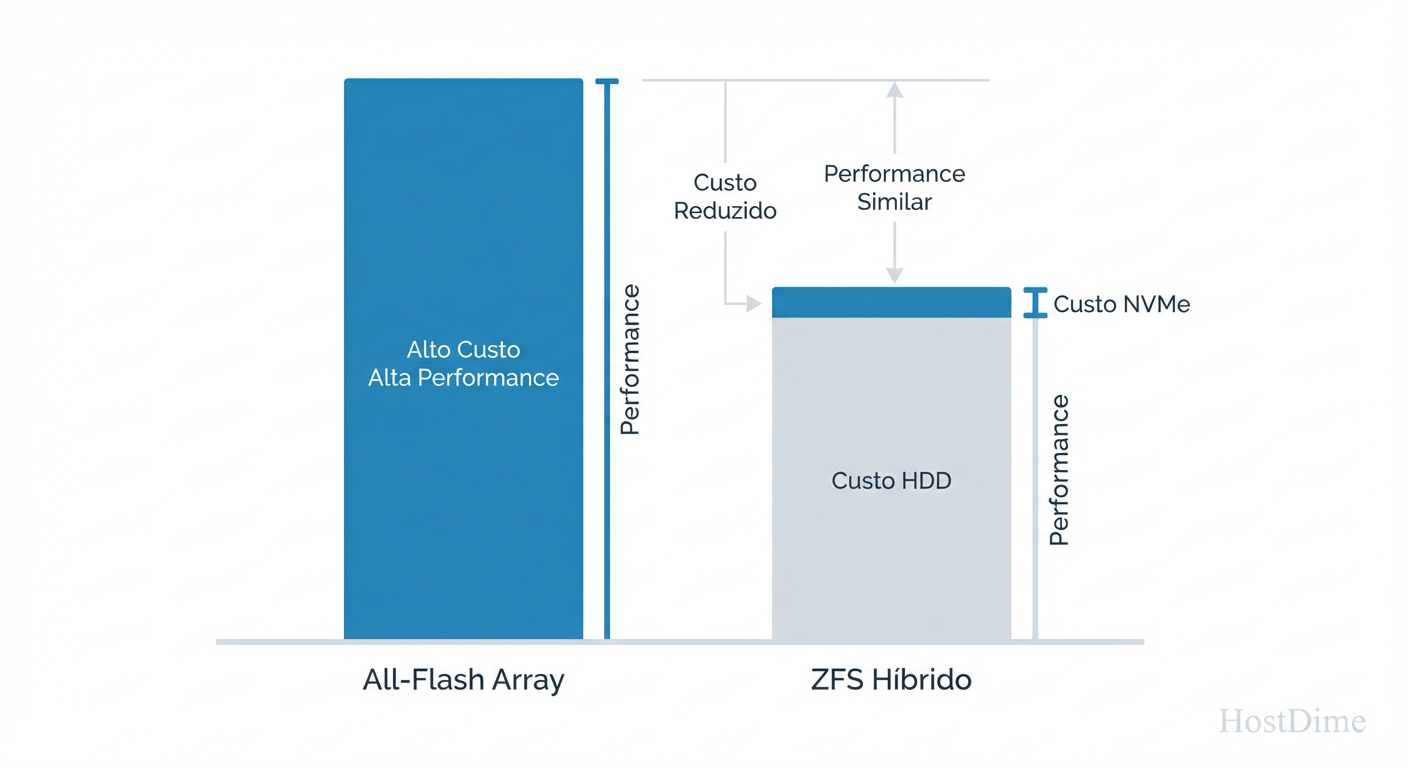 Fig 2. Otimização de CAPEX: Atingindo a 'Curva de Joelho' da performance com custo marginal.
Fig 2. Otimização de CAPEX: Atingindo a 'Curva de Joelho' da performance com custo marginal.
Ao apresentar este projeto, a linguagem não deve ser "vamos usar discos velhos", mas sim "vamos otimizar a estrutura de capital do nosso dado". Estamos pagando preço premium apenas pelo que exige performance premium (os metadados) e preço de commodity pelo que é commodity (o armazenamento em bloco).
O futuro é a segregação inteligente
O mercado de armazenamento está caminhando para uma bifurcação clara. De um lado, o armazenamento efêmero e ultra-rápido para computação (RAM/CXL/HBM). Do outro, o armazenamento de capacidade (HDD/Tape). O "meio termo" — o SSD de capacidade — está sendo espremido economicamente pela demanda de IA.
Para o gestor de infraestrutura e o analista de FinOps, a arquitetura de ZFS Híbrido com Special VDEVs representa a resposta racional a esse cenário de 2026. Ela permite navegar a volatilidade dos preços de componentes sem sacrificar a performance operacional necessária para as aplicações modernas. A recomendação estratégica é clara: audite seus pools, identifique a proporção de metadados e pare de pagar preço de NVMe para armazenar dados que seus usuários não acessam há meses. Otimize a latência, não a capacidade.
Perguntas Frequentes
1. Qual a diferença entre L2ARC e Special VDEV? O L2ARC é um cache de leitura; se ele falhar ou for removido, você não perde dados, apenas performance temporária. O Special VDEV é armazenamento primário para metadados; se ele falhar sem redundância, o pool é perdido. O Special VDEV garante que todos os metadados estejam no flash, enquanto o L2ARC apenas armazena o que foi acessado recentemente e não coube na RAM (ARC).
2. Posso usar SSDs de consumo (NVMe M.2 comuns) para Special VDEV? Financeiramente parece atrativo, mas tecnicamente é arriscado. SSDs de consumo geralmente carecem de proteção contra perda de energia (PLP - Power Loss Protection) e têm baixa durabilidade (TBW). Para Special VDEVs, a integridade dos dados é vital. Se o orçamento for apertado, prefira SSDs Enterprise usados a SSDs de consumo novos.
3. Qual o tamanho ideal para o Special VDEV?
Uma regra prática conservadora é calcular 0.3% a 0.5% da capacidade total do pool para metadados puros. Se você planeja armazenar também pequenos arquivos (ex: arquivos menores que 64KB) no flash, esse percentual deve subir para 1% a 3%, dependendo do perfil dos seus dados (use o comando zdb para analisar a distribuição de tamanho de blocos atual).
4. O ZFS Híbrido substitui o All-Flash para bancos de dados transacionais? Não. Para cargas de trabalho de banco de dados com escrita intensiva e aleatória (OLTP) onde a latência de escrita do payload é crítica, o All-Flash ainda é o rei. O Híbrido brilha em servidores de arquivos, backups, media streaming, virtualização geral e repositórios de objetos.

Arthur Costas
Especialista em FinOps
"Transformo infraestrutura em números. Meu foco é reduzir TCO, equilibrar CAPEX vs OPEX e garantir que cada centavo investido no datacenter traga ROI real."