A Crise da DDR5: Engenharia de Sobrevivência para a Escassez de Memória em 2026
A DDR5 dobrou de preço e a previsão para 2026 é crítica. Entenda a causa raiz (HBM vs. DDR5), como medir o impacto real e técnicas de otimização (zswap, ZFS ARC, CXL) para evitar upgrades caros.
Chegamos à cena do crime e o servidor não está morto, mas está em estado catatônico. O sintoma é clássico: thrashing. O LED de atividade do disco está aceso continuamente, a latência da aplicação disparou de 20ms para 4s e o console está cuspindo mensagens do OOM Killer (Out of Memory) sacrificando processos filhos como se fosse um ritual pagão.
Em 2024, a solução seria simples: "Compre mais RAM". Mas estamos em 2026. A cadeia de suprimentos mudou. Tentar resolver problemas de capacidade apenas com cartão de crédito tornou-se inviável para a maioria das operações que não sejam Hyperscalers.
Como investigador forense de sistemas, não aceito "o sistema está lento" como diagnóstico. Precisamos entender a anatomia desse colapso e, mais importante, como operar nossos sistemas com a precisão de um cirurgião quando o recurso mais vital — a memória física — se tornou ouro em pó.
A Escassez de Memória DDR5 em 2026 é um fenômeno de restrição de oferta causado pelo desvio massivo de capacidade de fabricação de wafers de silício para memórias HBM (High Bandwidth Memory) destinadas a aceleradores de IA. A sobrevivência técnica exige abandonar o superdimensionamento de hardware e adotar hierarquias de memória híbridas, utilizando compressão em memória (ZRAM), tiering via CXL e paginamento agressivo em NVMe de baixa latência.
Anatomia do Colapso: Por que a Oferta de DDR5 Secou?
Para entender por que seu pedido de 512GB de DDR5 está com prazo de entrega de 16 semanas e preço triplicado, precisamos olhar para a fábrica, não para o servidor. O silício é um jogo de soma zero.
Um wafer de 300mm tem uma área finita. Em 2026, os três grandes fabricantes (Samsung, SK Hynix, Micron) tomaram uma decisão comercial racional e devastadora para o consumidor de servidores x86 genéricos: a rentabilidade da HBM3e e HBM4 (usadas em GPUs NVIDIA e TPUs Google) é ordens de magnitude superior à da DDR5 commodity.
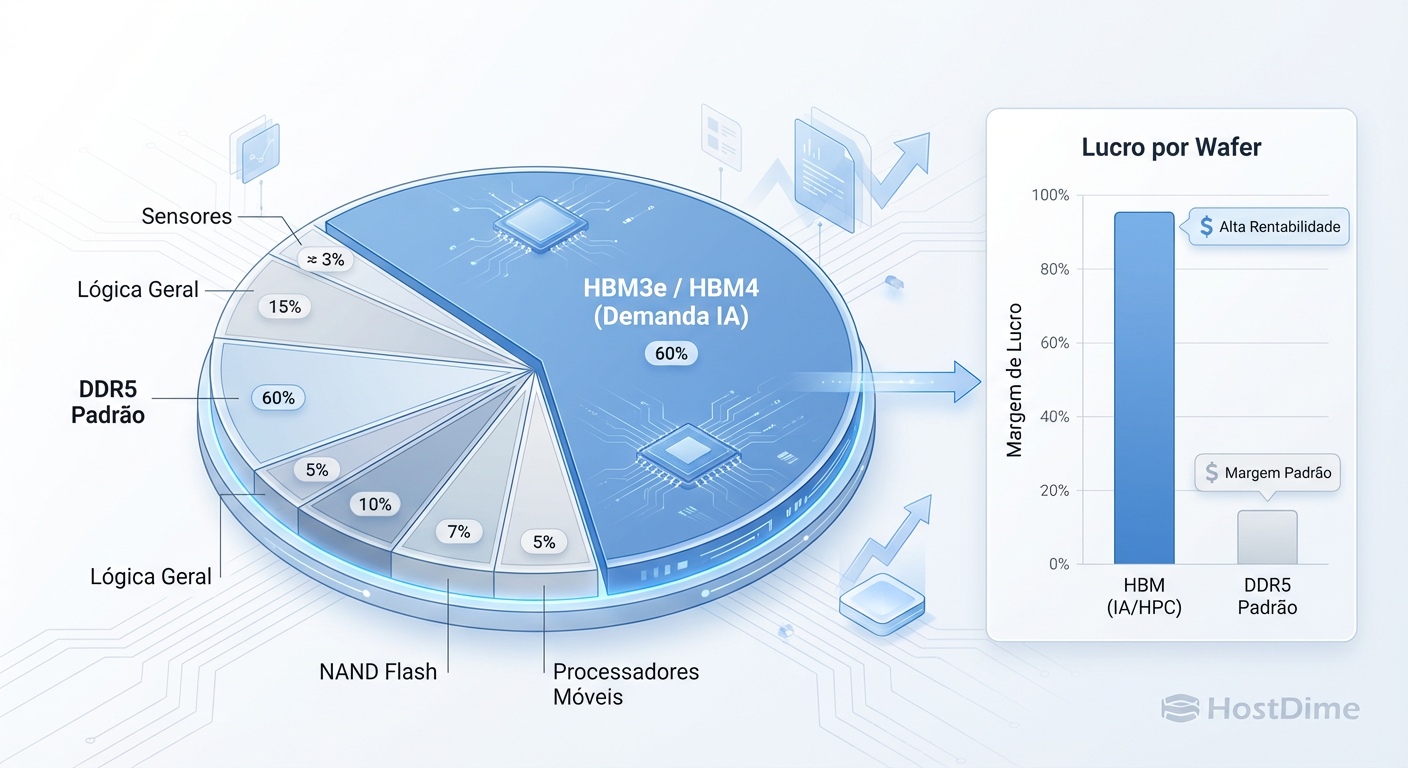 Figura: A Economia do Wafer: Por que os fabricantes priorizam HBM em detrimento da sua RAM DDR5.
Figura: A Economia do Wafer: Por que os fabricantes priorizam HBM em detrimento da sua RAM DDR5.
O "crime" aqui não é malícia, é matemática de mercado. A produção de HBM é complexa e tem baixo rendimento (yield), exigindo mais wafers para a mesma quantidade de bits funcionais. O resultado é que a linha de produção que faria sua DDR5 agora está ocupada empilhando dies para treinar LLMs.
Isso nos deixa com uma realidade dura: a memória que você tem hoje é provavelmente a memória que você terá pelos próximos 12 meses. Precisamos fazer engenharia de sobrevivência.
DDR4 vs. DDR5 em 2026: A Ilusão da Largura de Banda
Antes de entrarmos nos ajustes de kernel, precisamos desmantelar o hype do marketing. Se você ainda tem estoques de servidores DDR4 ou está considerando hardware "legado" renovado para expandir seu cluster, a análise forense de performance pode surpreendê-lo.
A indústria vende DDR5 baseada em Largura de Banda (Bandwidth). Sim, 6400 MT/s é o dobro de 3200 MT/s. Mas a Latência Real (True Latency) — o tempo entre o pedido da CPU e o primeiro dado chegar — não melhorou na mesma proporção. A latência CAS (Column Address Strobe) aumentou em ciclos para compensar a velocidade do clock.
Tabela Comparativa: A Realidade da Latência (DDR4 vs DDR5)
| Métrica | DDR4-3200 (CL 22) | DDR5-6400 (CL 40) | Veredito Forense |
|---|---|---|---|
| Largura de Banda Teórica | ~25.6 GB/s | ~51.2 GB/s | DDR5 vence em throughput massivo (streaming de vídeo, ETL). |
| Latência CAS (Ciclos) | 22 | 40 | DDR5 "gasta" mais ciclos esperando. |
| Latência Real (Nanosegundos) | ~13.75 ns | ~12.5 ns | Empate técnico. A melhora é marginal (<10%). |
| Custo por GB (Cenário 2026) | Baixo (Estoque legado) | Altíssimo (Escassez) | DDR4 oferece melhor ROI para DBs transacionais. |
Conclusão da Evidência: Se sua carga de trabalho é transacional (bancos de dados SQL, Redis, microserviços com muitos random access), a DDR5 não vai salvar seu dia. Manter infraestrutura DDR4 bem ajustada é uma estratégia válida de sobrevivência, não um sinal de obsolescência.
Otimização de Sistemas: Trocando CPU por RAM (ZRAM e Zswap)
Quando a memória física acaba, o sistema operacional tradicionalmente recorre ao disco (swap). Mesmo com SSDs NVMe rápidos, o swap é ordens de magnitude mais lento que a RAM (microssegundos vs. nanossegundos). O sistema engasga.
A estratégia forense aqui é interceptar o dado antes dele tocar o disco. Usamos a CPU — que frequentemente está ociosa em servidores de memória restrita — para comprimir dados na própria RAM.
O Mecanismo da ZRAM
A ZRAM cria um dispositivo de bloco na RAM que atua como swap. Quando o sistema precisa paginar, ele comprime a página e a armazena nessa área reservada.
Taxa de Compressão Típica (LZ4/Zstd): 3:1 a 4:1.
Resultado: 1GB de RAM física pode armazenar 3GB de dados "frios".
 Figura: Trade-offs de Sobrevivência: Onde o custo da CPU para compressão (ZRAM) supera o custo financeiro de nova DDR5.
Figura: Trade-offs de Sobrevivência: Onde o custo da CPU para compressão (ZRAM) supera o custo financeiro de nova DDR5.
Implementação Prática e Evidência
Não ative cegamente. Meça. O algoritmo zstd oferece melhor compressão, mas lz4 é mais rápido e consome menos CPU. Em um cenário de crise de DDR5, zstd geralmente vale o custo de CPU.
zramctl
# 2. Configurar ZRAM (Exemplo: Usando 20% da RAM total, algoritmo zstd)
# Nota: Em muitas distros modernas, isso é gerido via systemd-zram-generator ou udev.
# O comando abaixo é para entendimento do fluxo manual:
modprobe zram
echo zstd > /sys/block/zram0/comp_algorithm
echo 8G > /sys/block/zram0/disksize
mkswap /dev/zram0
swapon -p 100 /dev/zram0 # Prioridade alta para usar antes do disco
Callout de Risco: A ZRAM consome CPU para cada leitura/escrita de memória nessa região. Se sua CPU já estiver em 90% de carga, ativar a ZRAM causará latência de processamento. Monitore o
%sysnotopouhtop.
Tuning do OOM Killer
Se a compressão não for suficiente, o kernel Linux (OOM Killer) entrará em ação. Por padrão, ele mata processos "gordos" que cresceram rápido. Em produção, isso geralmente significa seu banco de dados principal.
Não deixe o kernel adivinhar. Proteja seus processos vitais ajustando o oom_score_adj.
Valores de
-1000tornam o processo imune.Valores positivos tornam o processo um alvo preferencial.
# Proteger o processo do PostgreSql (PID 1234)
echo -1000 > /proc/1234/oom_score_adj
Storage como RAM: Ajustando ZFS ARC e L2ARC
Para quem usa ZFS (TrueNAS, Proxmox, Ubuntu Servers), a crise de memória é duplamente perigosa. O ZFS, por design, tenta usar toda a RAM livre para cache de leitura (ARC - Adaptive Replacement Cache).
Em tempos de abundância, isso é ótimo. Em 2026, é um problema. O ARC compete com suas aplicações.
O Dilema do L2ARC (Cache em SSD)
A tentação é adicionar um NVMe rápido como L2ARC para "expandir a RAM". Cuidado. O modelo mental correto é: L2ARC não é RAM grátis.
Para cada bloco de dados armazenado no L2ARC (SSD), o ZFS precisa de uma entrada na tabela de alocação na RAM (ARC Header) para saber onde esse dado está.
A Regra do Polegar: Você gasta cerca de 70 bytes de RAM para cada registro no L2ARC.
O Risco: Se você adicionar um L2ARC de 2TB em um sistema com apenas 32GB de RAM, os headers do L2ARC vão consumir toda a sua RAM principal, expulsando o cache mais rápido e matando a performance.
Estratégia de Mitigação
Limite o ARC Máximo: Force o ZFS a devolver memória para as aplicações.
Use L2ARC com Moderação: Adicione apenas se o seu "Working Set" for maior que a RAM, mas não massivamente maior.
Persistência: Garanta que o L2ARC seja persistente entre reboots (padrão em OpenZFS 2.0+).
# Limitar o ARC a 8GB (em bytes)
echo 8589934592 > /sys/module/zfs/parameters/zfs_arc_max
# Verificar a eficiência do ARC (Hit Ratio)
arc_summary | grep "ARC efficiency"
Se o seu "ARC efficiency" cair abaixo de 90%, você precisa de mais L2ARC (com cuidado) ou tuning de aplicação.
O Futuro Imediato: CXL como a Salvação da Densidade
Se você não consegue colocar mais pentes de memória na placa-mãe, a solução de engenharia para 2026/2027 é sair do canal de memória tradicional.
Entra em cena o CXL (Compute Express Link). Pense no CXL como uma forma de conectar memória RAM através do barramento PCIe.
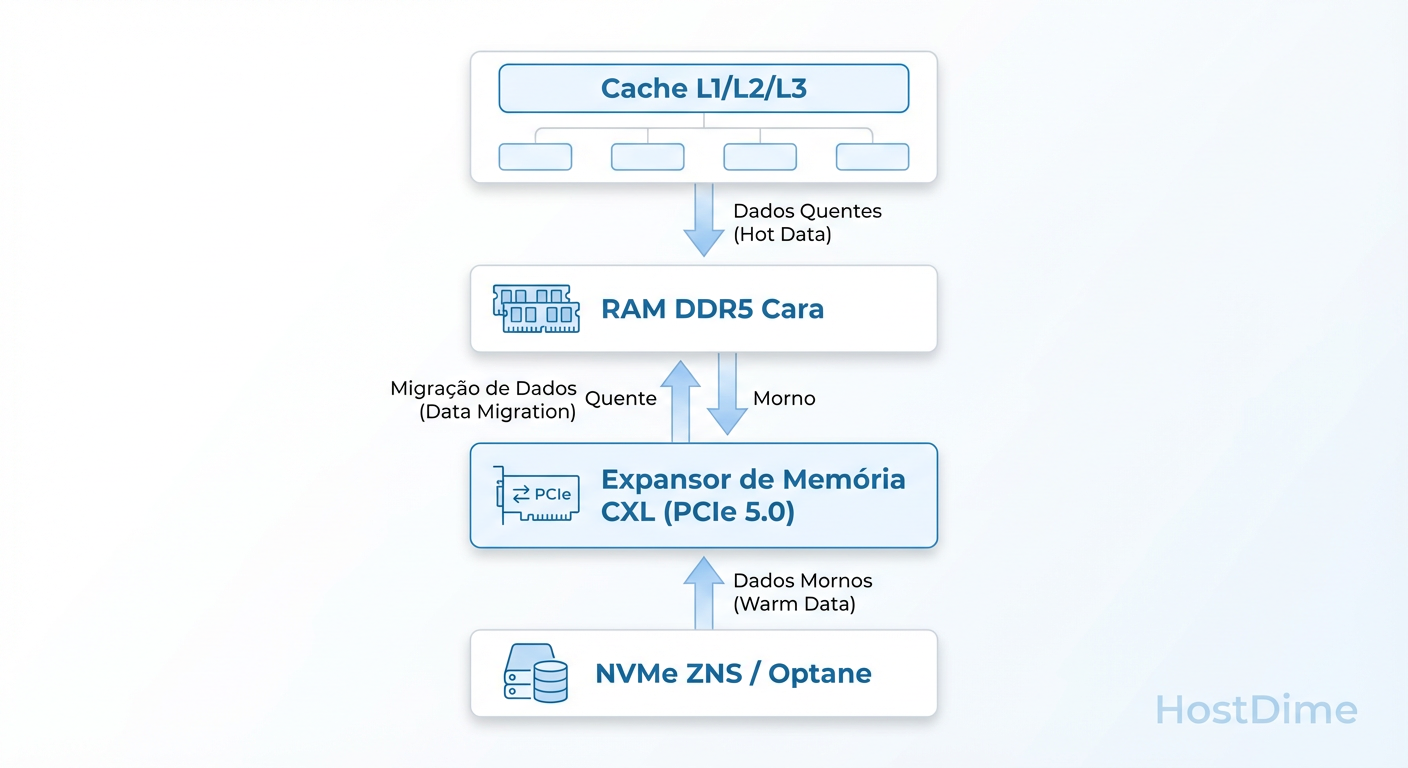 Figura: O Novo Mapa de Memória: Inserindo CXL e NVMe rápido para compensar a escassez de DDR5 nativa.
Figura: O Novo Mapa de Memória: Inserindo CXL e NVMe rápido para compensar a escassez de DDR5 nativa.
Por que CXL muda o jogo?
Tradicionalmente, a RAM está presa aos slots DIMM ao lado da CPU. O CXL permite "Memory Expanders" — cartões PCIe que contêm slots DDR5 (ou até DDR4).
Latência: É maior que a RAM nativa (cerca de 170-200ns vs 80-100ns), mas é ordens de magnitude mais rápida que um SSD NVMe (100.000ns).
Tiering Automático: O Kernel Linux (via Tiered Memory Management) pode colocar dados "quentes" na RAM nativa e mover dados "mornos" para a memória CXL transparentemente.
Para o investigador de sistemas, o CXL aparece como um novo nó NUMA (Non-Uniform Memory Access). O comando numactl será seu melhor amigo para garantir que processos críticos fiquem na memória local, enquanto bancos de dados em-memória (como Redis) podem se expandir para o CXL.
Estratégia de Compras: O Veredito Forense
Diante das evidências coletadas — escassez de wafers, paridade de latência DDR4/5 e novas tecnologias de tiering — aqui está o plano de ação para o CIO e o Engenheiro de Sistemas:
Não pague o ágio da DDR5 agora: A menos que sua aplicação seja estritamente limitada por largura de banda de memória (HPC, Transcodificação de Vídeo), o custo extra não se justifica.
Canibalize e Reutilize: Servidores DDR4 de alta densidade (256GB+) ainda são plataformas viáveis e superiores a servidores DDR5 famintos (64GB) para virtualização geral.
Adote ZRAM como Padrão: Em ambientes Linux, configurar ZRAM com
zstddeve ser parte da imagem base do sistema operacional. É "RAM grátis" às custas de ciclos de CPU ociosos.Prepare-se para CXL: Ao comprar novos servidores, verifique o suporte a PCIe 5.0/6.0 e CXL 2.0. Isso lhe dará uma rota de fuga para expandir memória sem depender dos slots DIMM limitados no futuro.
A crise de 2026 não é sobre quem tem mais dinheiro para gastar, é sobre quem entende melhor como os bits fluem através do silício. Pense, meça, e só então, opere.
Referências & Leitura Complementar
RFC 8831: WebRTC Data Channels (Conceitos de fluxo de dados sob restrição).
OpenZFS Documentation: ARC and L2ARC Tuning Guidelines.
Compute Express Link (CXL) Specification 3.0: Memory Sharing and Pooling.
Kernel.org Doc: zram: Compressed RAM based block devices.
JEDEC Standard JESD79-5: DDR5 SDRAM Standard (Para análise profunda de latências CAS).

David Ross
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.