Biblioteca Técnica
Guias aprofundados, benchmarks e análises de arquitetura para profissionais de infraestrutura.
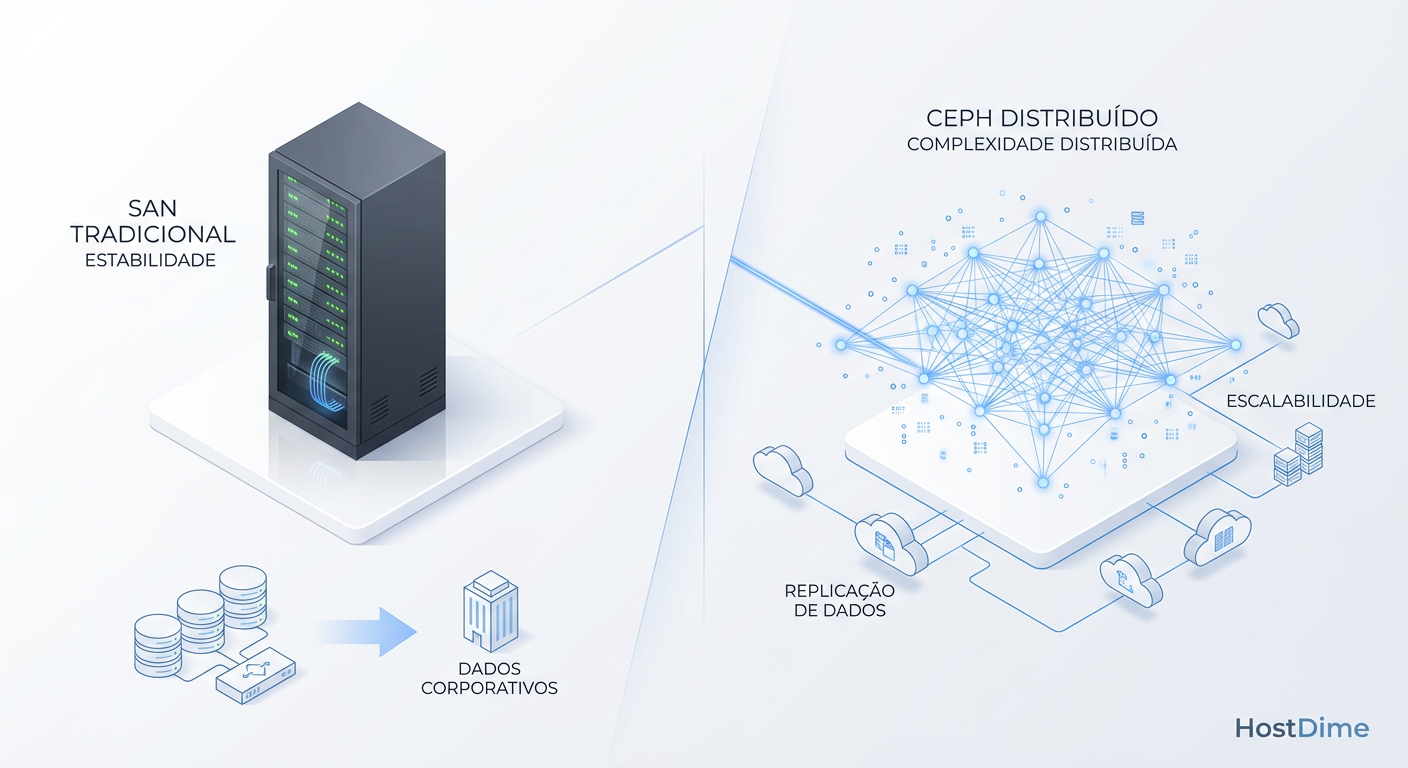
Ceph vs. SAN Tradicional: Onde a Complexidade Cobra Juros
Pare de comparar apenas o preço por TB. Entenda os trade-offs reais de latência, custo operacional (OpEx) e arquitetura entre Ceph e Storage Area Networks (SAN) antes de migrar.
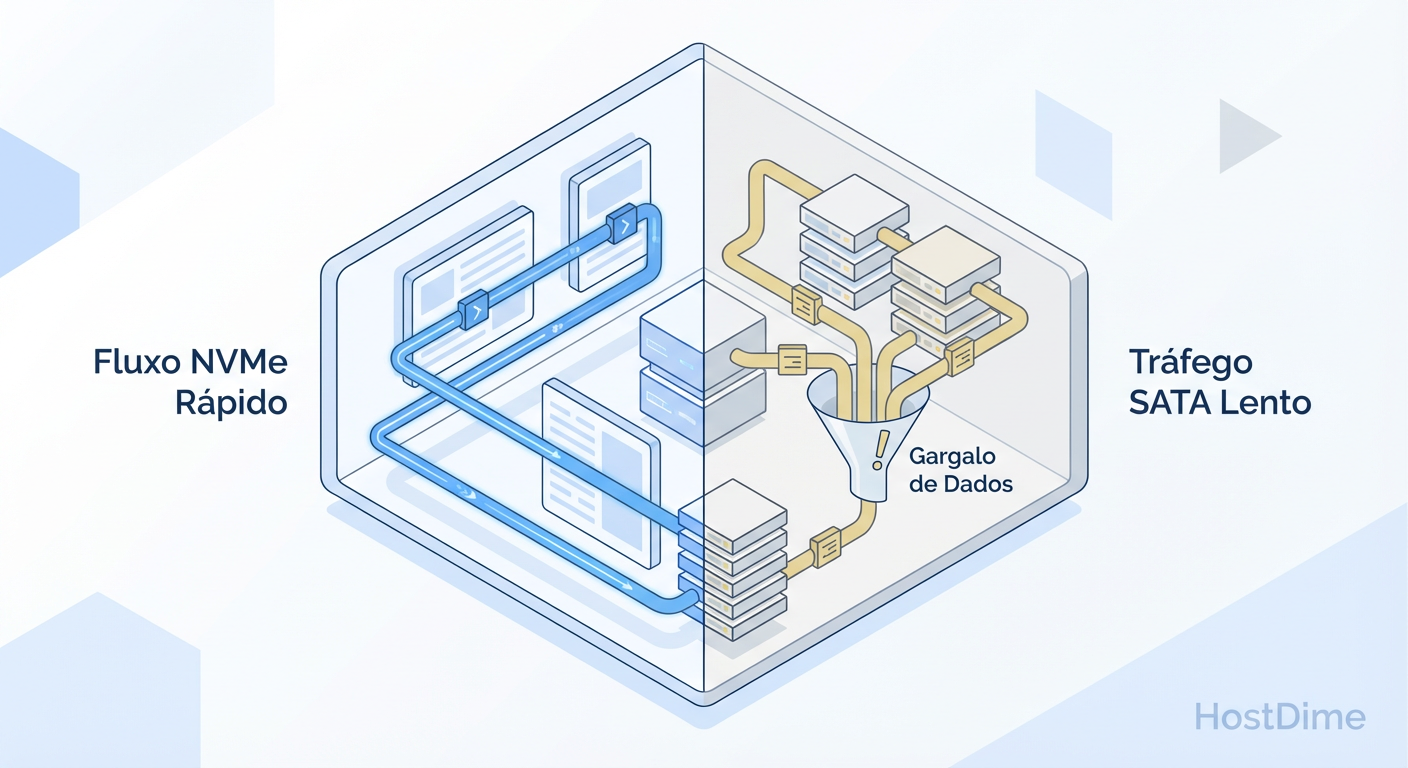
Ceph: SSD SATA vs NVMe e o Custo Oculto da Latência Mista
Misturar SSD SATA e NVMe no mesmo pool do Ceph cria gargalos invisíveis. Entenda a diferença de protocolos (AHCI vs PCIe), o impacto na latência de cauda e como arquitetar corretamente.

IO Scheduler do Hypervisor e Ceph: O Gargalo do "Double Scheduling"
Seus OSDs virtualizados sofrem com latência alta? O culpado pode ser o IO Scheduler do host. Entenda o conflito de filas, como diagnosticar gargalos e por que 'none' ou 'noop' são essenciais para o desempenho do Ceph.

Ceph e Overcommit: Onde o Modelo Mental do Thin Provisioning Quebra
O Thin Provisioning no Ceph é uma aposta arriscada. Entenda a matemática real do overcommit, os perigos dos limites 'nearfull' e como evitar o travamento total do seu cluster de storage.
Ceph RBD Snapshots: O Mito do Backup Simples e o Custo da Extração
Snapshots no Ceph são instantâneos, mas não são backups. Entenda a mecânica do RADOS, os perigos do `rbd export`, o custo de I/O e como garantir consistência real sem corromper bancos de dados.

Ceph em Multi-Datacenter: Latência, Split-Brain e os Limites da Física
Estender um cluster Ceph entre datacenters parece mágica, mas a latência não perdoa. Entenda os trade-offs reais entre Stretch Clusters e RBD Mirroring para evitar desastres de I/O.
Ceph e Banco de Dados: Por que o Tuning Genérico Destrói a Performance
Workloads transacionais em Ceph exigem mais que largura de banda. Entenda a latência de gravação, os perigos do cache RBD e como ajustar o BlueStore e RocksDB para bancos de dados.

Ceph QoS e Multi-tenancy: Isolamento Real ou Ilusão de Controle?
Cansado de 'vizinhos barulhentos' derrubando seu banco de dados no Ceph? Entenda a diferença entre Limites RBD e o algoritmo mClock, e aprenda a medir se o isolamento de tenants realmente funciona.

Erasure Coding vs. RAID: O Fim da Redundância Local em Escala Petabyte
RAID 6 não escala. Descubra como o Erasure Coding resolve o dilema de custo vs. durabilidade em Object Storage (Ceph), entendendo a matemática e o preço de performance.
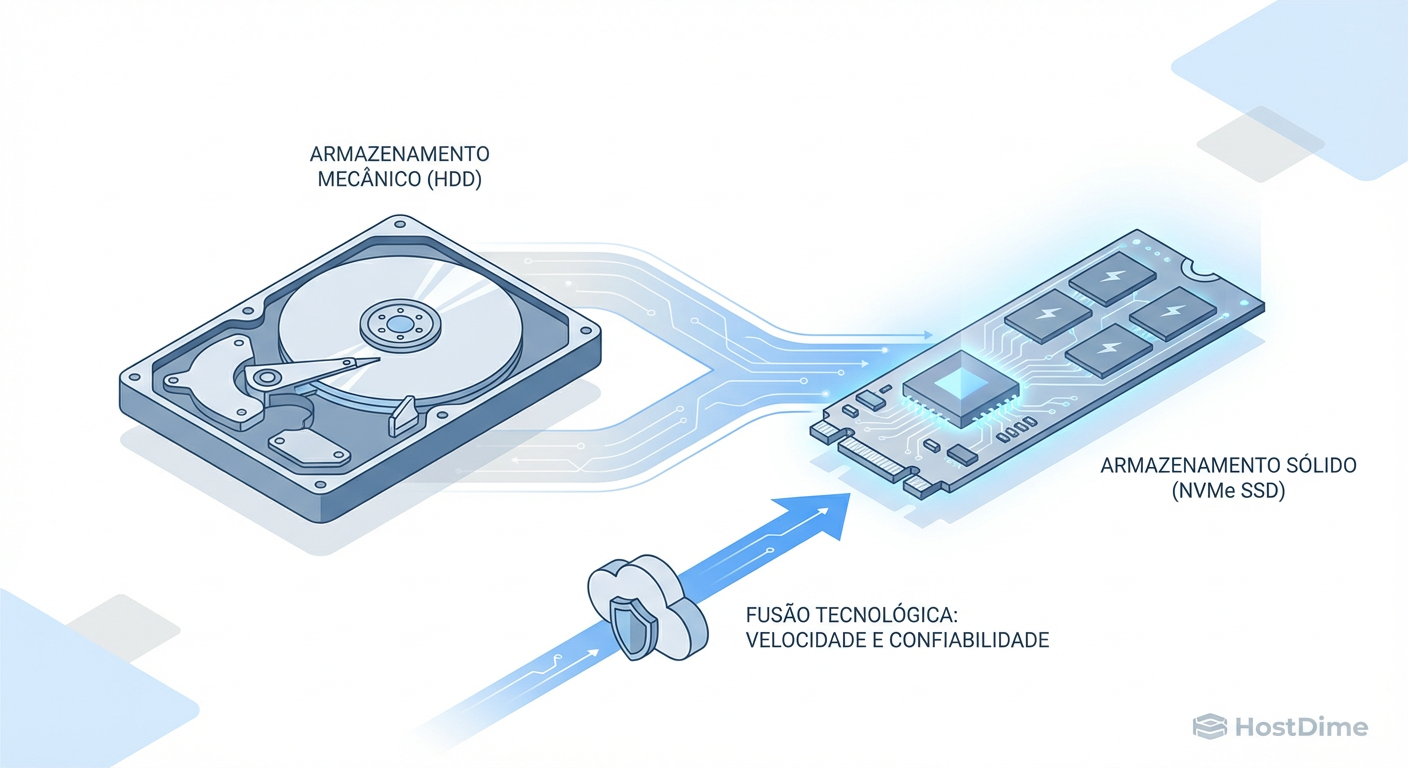
Hybrid RAID e Tiering: O Guia Realista de Cache SSD sobre HDDs
Pare de desperdiçar SSDs. Entenda a arquitetura real do Hybrid RAID, as diferenças entre LVM Cache e ZFS SLOG, e como evitar o 'Write Cliff' ao acelerar arrays de HDDs.

Power Loss Protection (PLP) em SSDs: O Segredo da Integridade e Performance em RAID
Entenda por que SSDs sem PLP são um risco para Arrays RAID e ZFS. Descubra a relação crítica entre capacitores, segurança de dados e a performance de escritas síncronas.
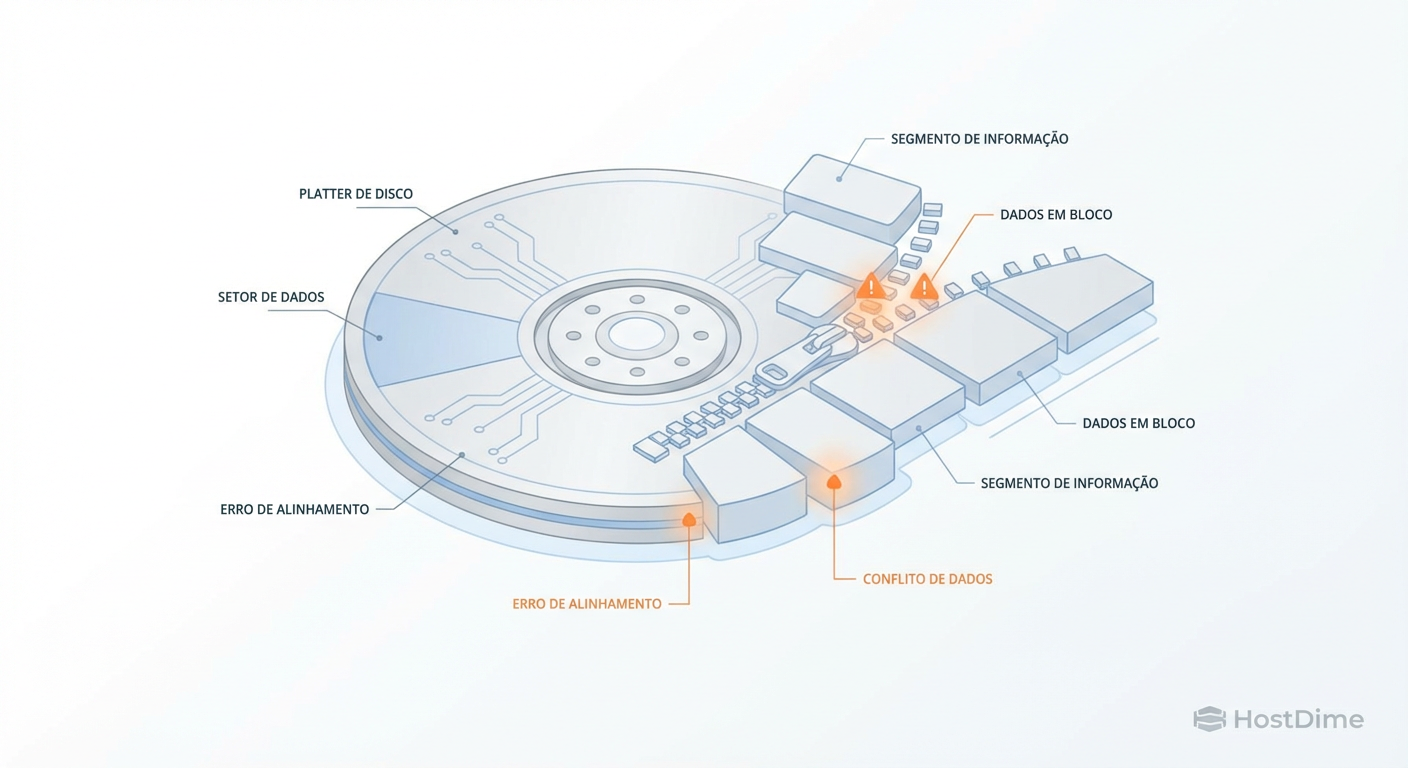
Alinhamento de Partições e RAID: O Fim do Read-Modify-Write em Discos 4K
Seu RAID está lento? O problema pode ser o desalinhamento entre setores 4K e o stripe size. Aprenda a diagnosticar, calcular e corrigir o Write Penalty.
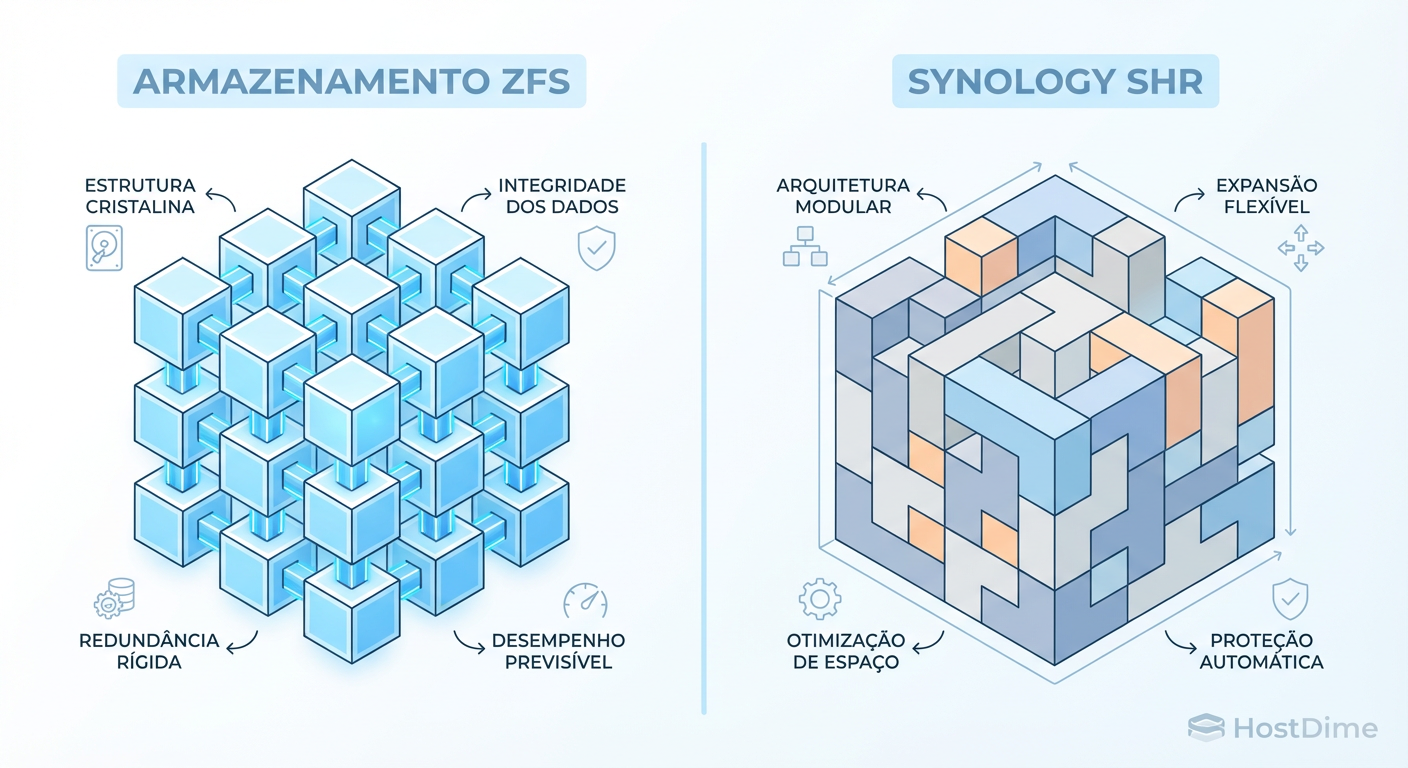
RAID em NAS Doméstico: A Batalha Real entre ZFS (TrueNAS) e SHR (Synology)
Não escolha seu NAS pelo chassi, mas pelo sistema de arquivos. Entenda os trade-offs reais de integridade, expansão e custo entre ZFS e SHR antes de comprar os discos.
Benchmarking RAID: A Verdade Sobre Performance com FIO e Iometer
Pare de adivinhar sua performance de storage. Aprenda a medir IOPS, latência e throughput em RAID 5, 6 e 10 usando metodologias científicas com fio e iometer.

Criptografia em Linux RAID: O Guia Definitivo de LUKS sobre mdadm
Aprenda a arquitetura correta para criptografar arrays RAID com LUKS. Entenda o impacto de performance, gerenciamento de chaves e por que a ordem das camadas define a sobrevivência dos seus dados.
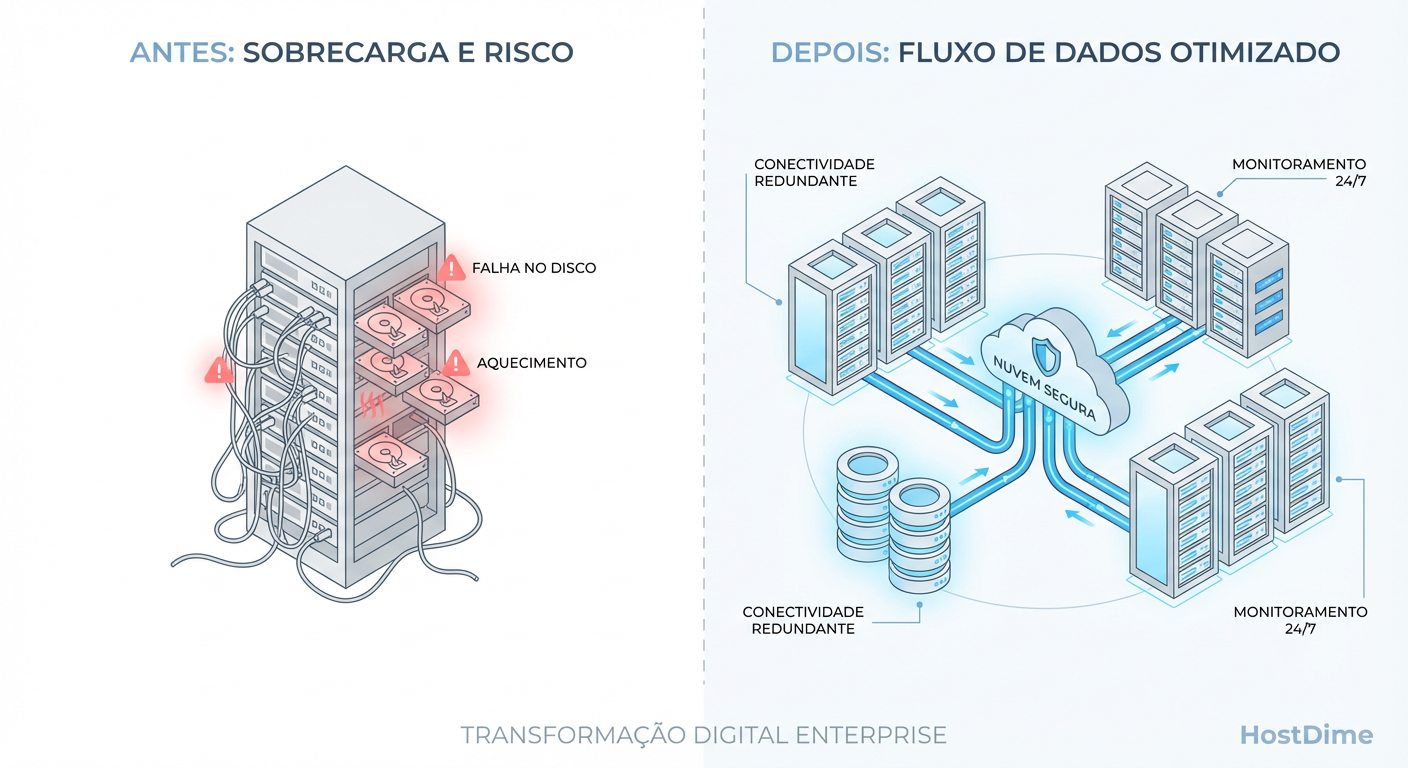
Escalabilidade Horizontal: A Realidade da Migração de RAID Local para Storage Distribuído
O RAID local tem um teto físico. Entenda os trade-offs reais de latência, complexidade de rede e consistência ao migrar para storage distribuído (Ceph, GlusterFS, MinIO).

Bit Rot e Corrupção Silenciosa: Por Que o RAID Não Salva Seus Dados
Você confia no RAID para integridade de dados? Erro fatal. Entenda como o Bit Rot passa despercebido por controladores tradicionais e por que Checksumming é a única defesa real.

RAID com Discos SMR: O Guia de Sobrevivência e Armadilhas (2026)
Evite o desastre no seu storage. Entenda por que discos SMR destroem arrays RAID, a diferença crítica entre DM-SMR e HM-SMR, e como diagnosticar gargalos de escrita antes de perder dados.

Intel VROC vs Hardware RAID: A Realidade do Desempenho NVMe
VROC é Hardware RAID? Vale a pena pagar pela chave de licença? Analisamos a arquitetura Intel VMD, gargalos PCIe e quando abandonar controladoras tradicionais.
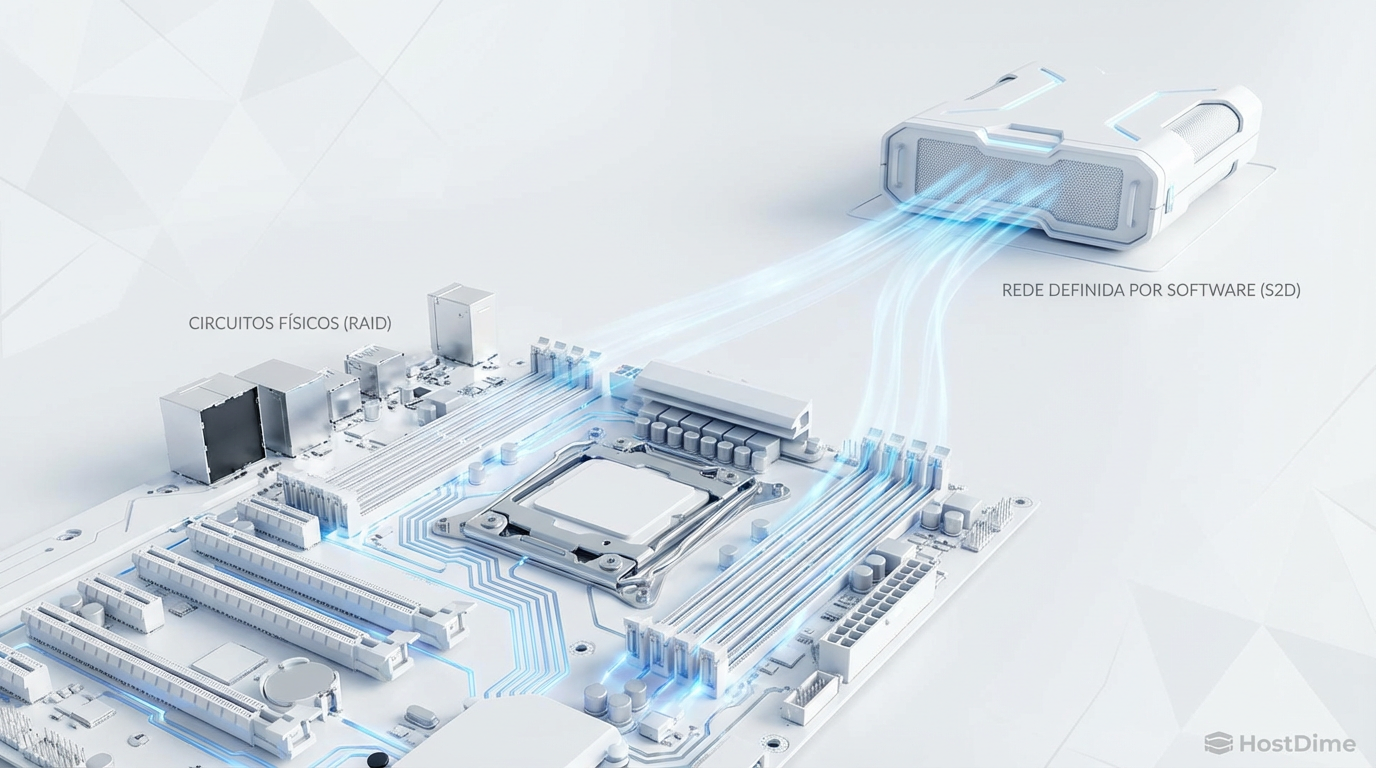
Storage Spaces Direct vs. Hardware RAID: Performance, Riscos e Arquitetura
Pare de adivinhar entre S2D e RAID tradicional. Uma análise profunda de engenharia sobre latência, overhead de CPU, resiliência e quando o Software-Defined Storage mata o Hardware RAID (e vice-versa).

RAID para Machine Learning: Como Alimentar GPUs sem Gargalos de I/O
Suas GPUs estão ociosas esperando dados? Aprenda a otimizar RAID e Filesystems (XFS/ZFS) para o throughput massivo exigido por treinos de Deep Learning.

Falhas em Controladoras RAID: Diagnóstico, Cache Preservado e Recuperação Segura
Quando o controlador morre, o RAID desaparece. Aprenda a diferenciar falhas de disco de falhas de HBA, gerenciar cache sujo (dirty cache) e realizar a importação de configurações estrangeiras sem corrupção de dados.
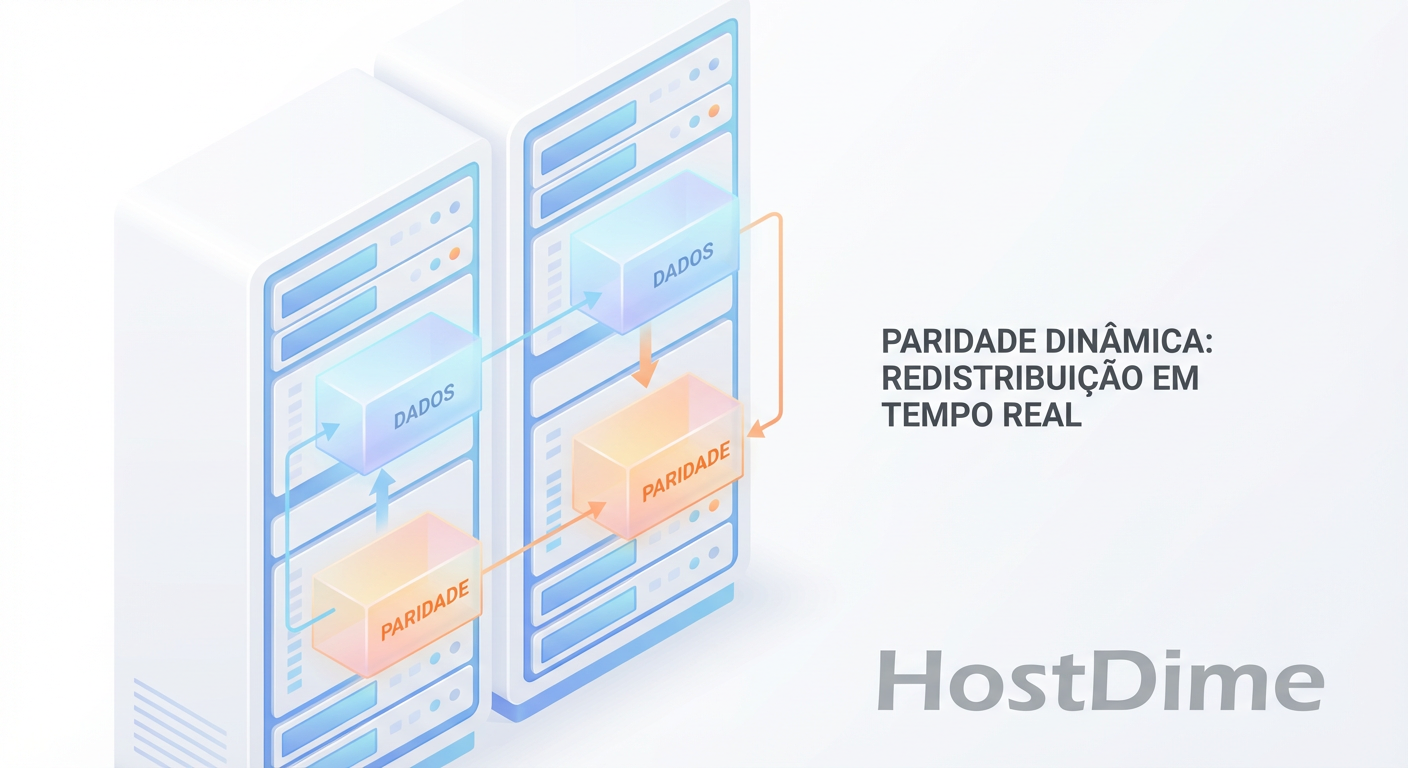
RAID Adaptativo: O Fim da Geometria Estática e o Ajuste Dinâmico de Paridade
Esqueça o RAID 5 ou 6 fixo. Entenda como algoritmos de RAID Adaptativo e Erasure Coding ajustam a paridade em tempo real para equilibrar performance e proteção.

Kubernetes e RAID: Onde os Dados Realmente Vivem (e Morrem)
Esqueça a abstração mágica. Entenda como integrar RAID com Kubernetes Persistent Volumes, os riscos de Local PVs e como medir o impacto de I/O em seus containers.

Termodinâmica do Storage: Energia e Refrigeração em Arrays de 30TB+ (2026)
Esqueça o 'Watts por TB'. Descubra como a física dos drives HAMR/MAMR de alta capacidade impacta o cooling, o consumo real em RAID e por que seu rack pode derreter em 2026.

Testes de Stress em RAID: Como Simular Falhas e Validar Redundância Real
Não espere a produção cair. Aprenda a executar testes de stress em RAID, simular falhas de disco sob carga (fio/mdadm) e medir o impacto real na latência durante o rebuild.
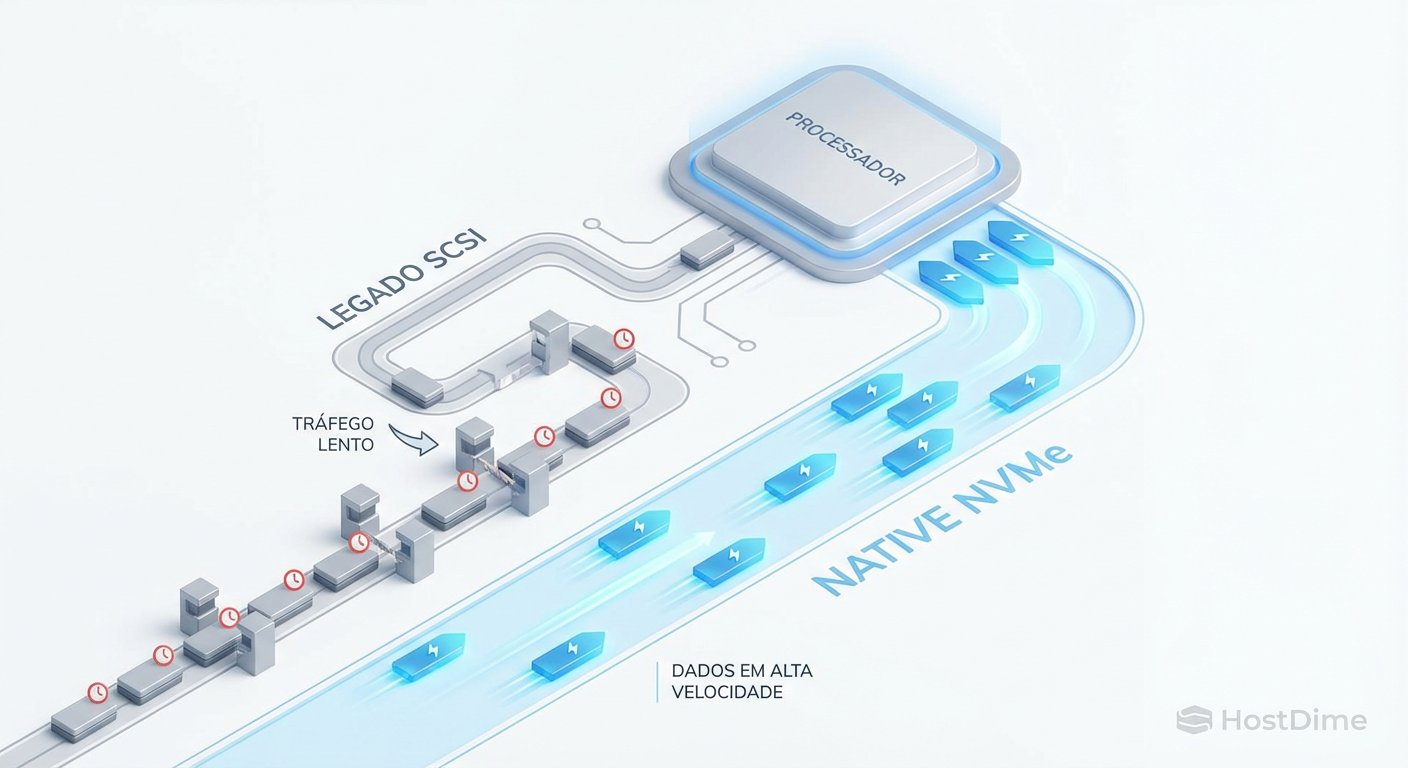
Native NVMe no Windows Server 2025: O Fim do Gargalo SCSI e o Salto de Performance
O stack SCSI legado está sufocando seus SSDs. Entenda a arquitetura Native NVMe do Windows Server 2025, saiba como validar o driver e medir o ganho real de IOPS.
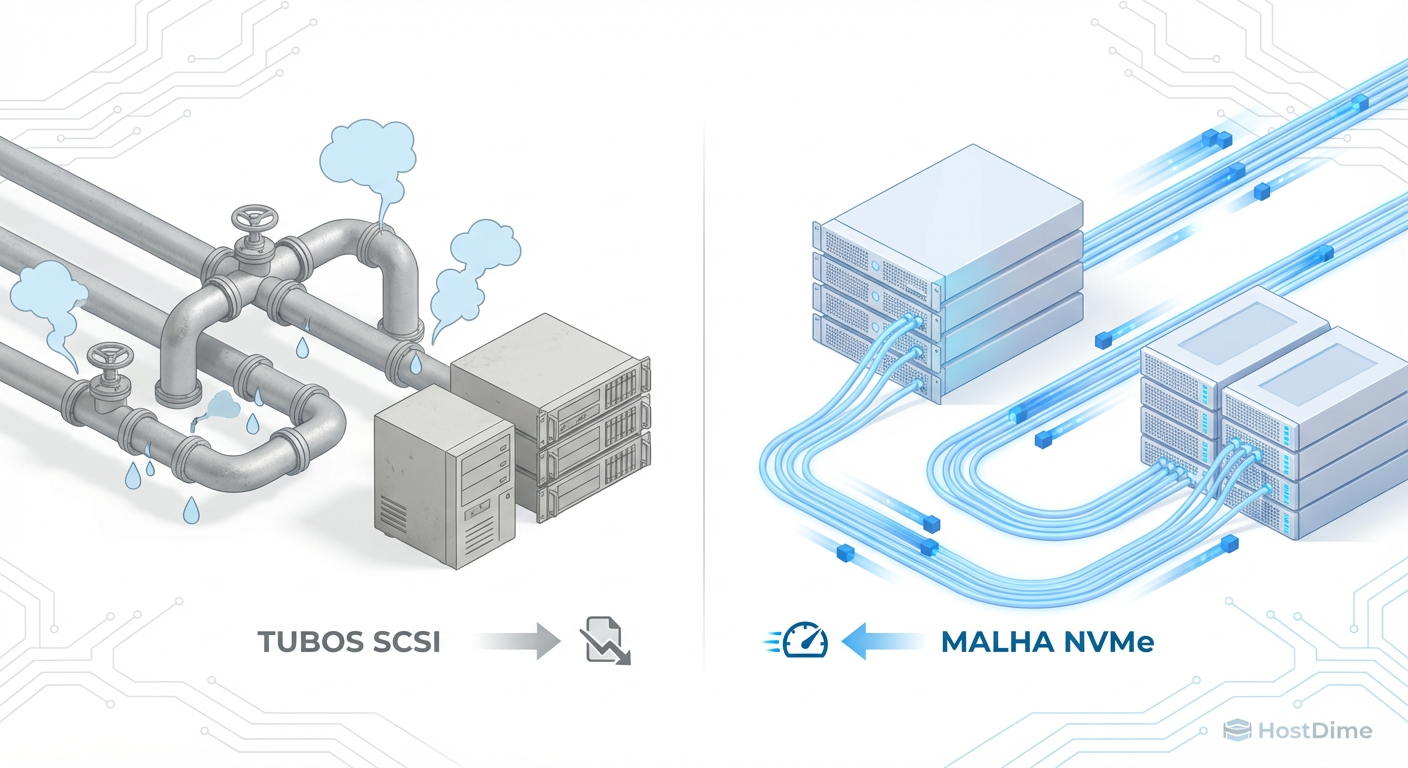
NVMe-oF vs iSCSI em 2025: O Fim da Era SCSI e a Realidade do Storage Desagregado
NVMe over Fabrics (NVMe-oF) não é apenas mais rápido que iSCSI, é arquiteturalmente diferente. Analisamos NVMe/TCP, RDMA e o suporte nativo no Windows Server para decidir o futuro do seu storage.

RAID Hardware vs. Software na Era NVMe: A Morte da Controladora Dedicada em 2026?
Descubra por que controladoras RAID Hardware tornaram-se o maior gargalo para SSDs NVMe. Análise técnica de latência, PCIe lanes e por que o Software RAID (ZFS/mdadm) vence em 2026.

ZFS vs MDADM vs Hardware RAID: A Batalha do NVMe e o Custo do Rebuild
Análise forense do impacto em CPU e latência entre ZFS, MDADM e Hardware RAID em arrays NVMe. Descubra quem sobrevive a um rebuild sem travar seu servidor.
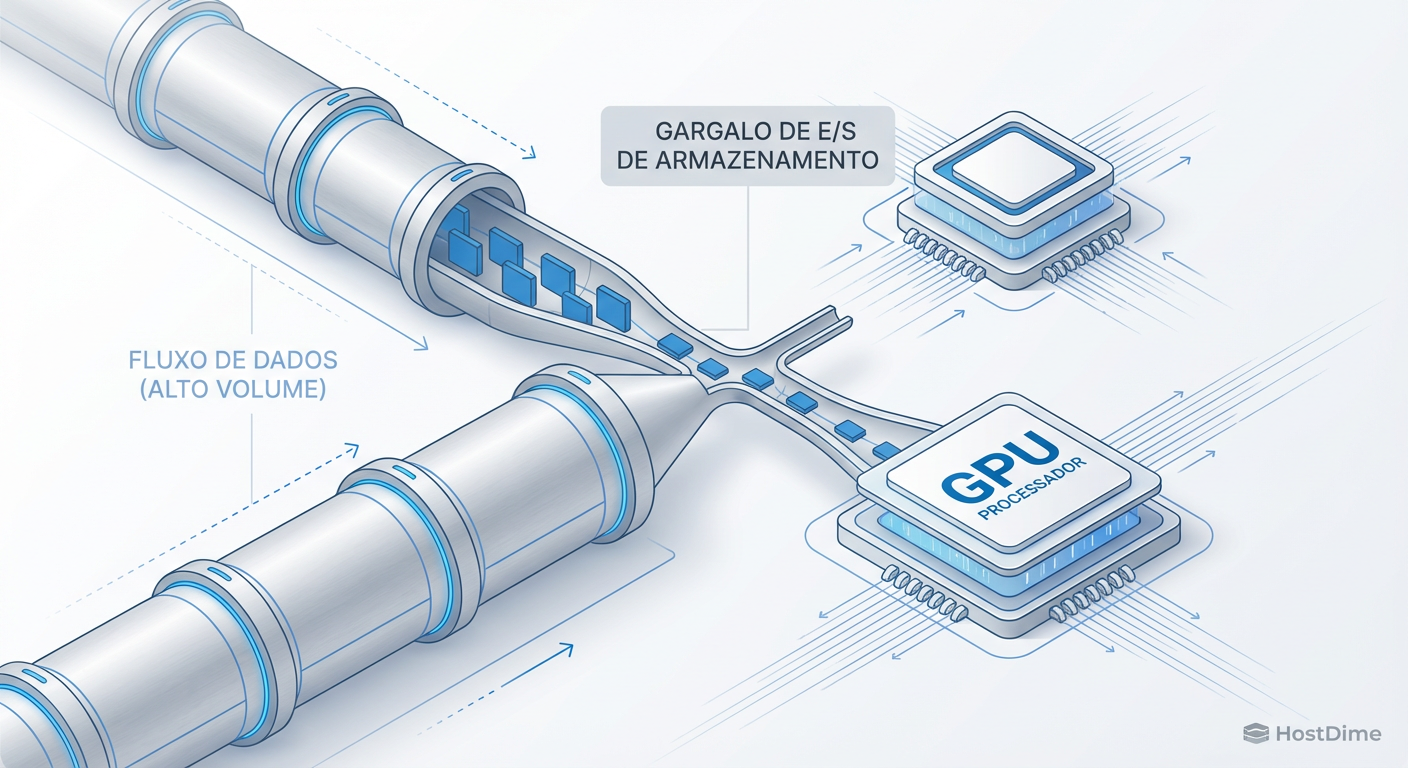
Storage para AI e RAG: A Verdade Sobre a Infraestrutura de GenAI em 2026
Seus GPUs estão ociosos esperando por dados? Analisamos o perfil de I/O de cargas de trabalho RAG, o fim do POSIX para AI e como arquitetar storage de alto desempenho para 2026.
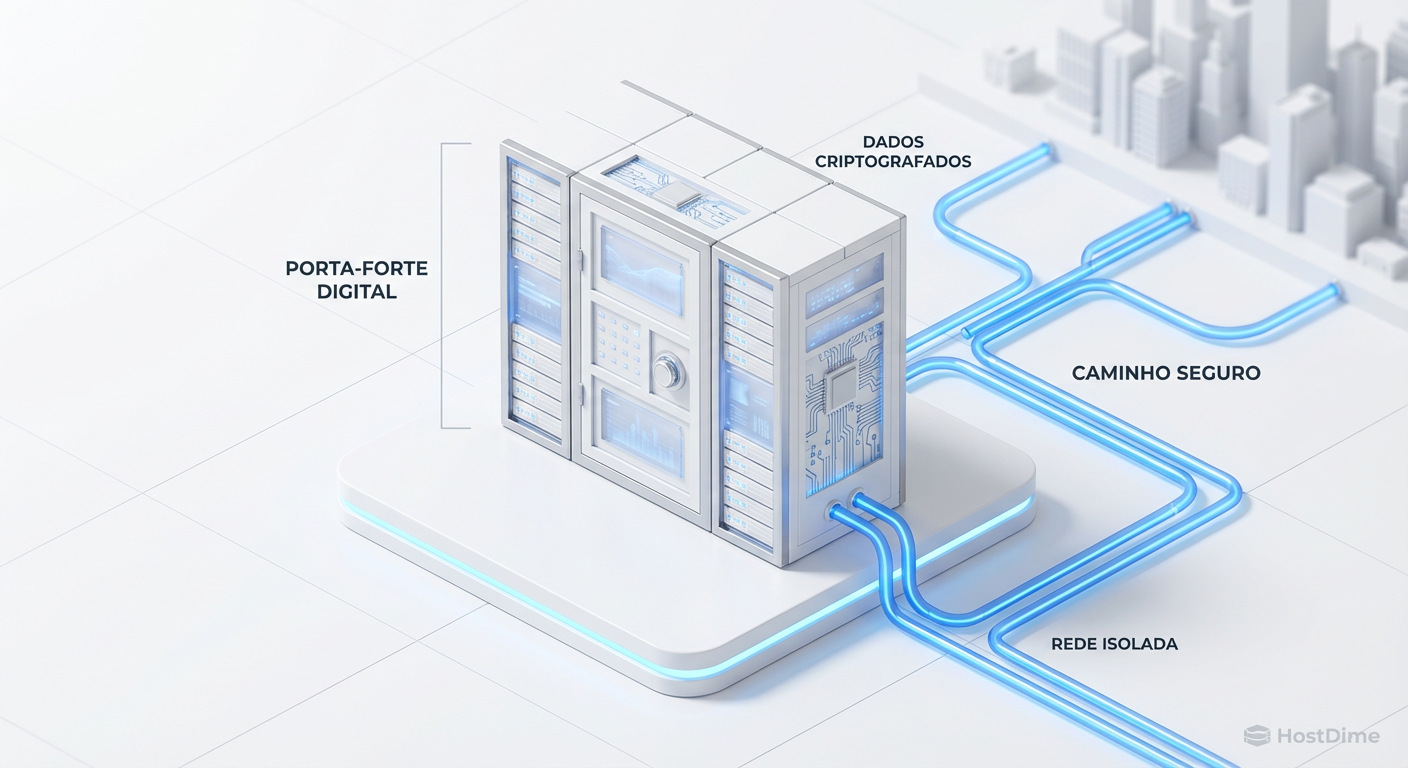
Cyber Recovery além do Hype: Engenharia de Imutabilidade e Air-Gap em Storage
Não confie apenas no selo 'Ransomware-Proof'. Entenda a arquitetura de snapshots imutáveis, a verdade sobre Air-Gapping e como projetar um Cyber Recovery Vault que resista a ataques de privilégio administrativo.

Crise de Storage 2025: O Impacto da AI nos Preços de SSD e HDD e Como Mitigar
A demanda por AI está consumindo a produção de NAND e HDDs. Entenda a escassez prevista para 2025 e aprenda estratégias de arquitetura (Tiering, Compressão, QLC) para proteger seu orçamento.
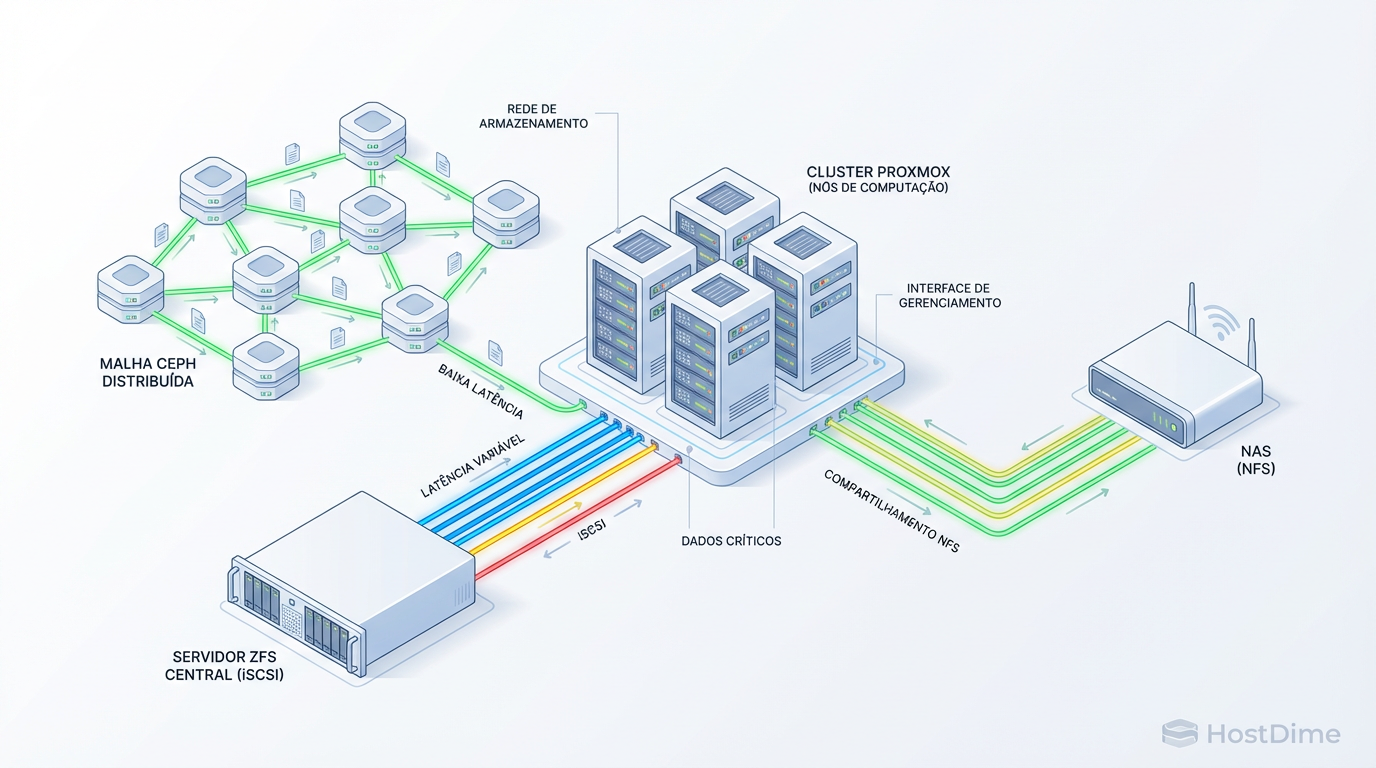
Storage Compartilhado no Proxmox: Ceph, NFS ou ZFS over iSCSI? Arquitetura para HA Real
Não escolha seu storage no cara ou coroa. Compare arquitetura, latência e complexidade entre Ceph, ZFS over iSCSI e NFS para clusters Proxmox HA de alta performance.

Migração VMware para Proxmox: Guia de Engenharia de Storage (vmdk para qcow2/zvol)
Fuja do lock-in sem perder dados. Guia técnico para migrar VMs do ESXi para Proxmox VE, focando na conversão correta de vmdk, drivers VirtIO e escolha entre qcow2 ou ZFS raw.

vSAN vs. Open Source em 2025: Análise Real de Custo e Performance (Pós-Broadcom)
Os aumentos de licença VMware inviabilizaram seu vSAN? Comparamos arquitetura, latência e TCO real entre vSAN, Ceph (Proxmox) e ZFS para decidir seu futuro em 2025.
ReFS Deduplicação e Compressão no Windows Server 2026: Otimização Real para Hyper-V
Pare de desperdiçar storage em Hyper-V. Entenda a arquitetura de deduplicação nativa do ReFS no Windows Server 2026, meça o impacto na CPU e aprenda a configurar sem destruir a performance de IOPS.

S2D Stretch Cluster no Windows Server 2026: A Realidade da Latência e Alta Disponibilidade
Não acredite apenas no marketing de 'Zero RPO'. Entenda a arquitetura de Campus Cluster no S2D, o impacto da replicação síncrona na performance e como configurar Fault Domains corretamente no Windows Server 2026.

VMware vSphere 9: Guia de Performance de Storage e Otimização VMFS/vVols
Domine o subsistema de storage do vSphere 9. Entenda as diferenças reais entre VMFS-6 e vVols, configure NVMe-oF e elimine gargalos de I/O com métricas, não suposições.

RAID Controllers NVMe Nativo em 2025: Análise Técnica (Broadcom vs Microchip)
Hardware RAID para NVMe ainda faz sentido em 2025? Analisamos os controladores Tri-Mode da Broadcom e Microchip, latência, IOPS e quando abandonar o Software RAID.

RAID em SSDs: A Verdade Sobre Bit Rot, Rebuilds e Degradação de Performance
Seu array All-Flash não é invencível. Entenda a física da amplificação de escrita, por que o Bit Rot acontece em SSDs e como evitar que um rebuild mate seus dados.

AIOps em Storage: A Realidade Técnica da Automação e Previsão de Falhas em 2026
Cansado de apagar incêndios? Descubra como o AIOps evoluiu de buzzword para necessidade técnica em 2026, automatizando tiering preditivo e análise de falhas sem o marketing vazio.

NVMe/TCP vs RoCE vs Fibre Channel: O Guia Forense de Escolha para NVMe-oF
Pare de adivinhar sua infraestrutura de storage. Analisamos os trade-offs reais de latência, complexidade de rede e custo entre NVMe/TCP, RoCE v2 e FC-NVMe.

Proxmox Storage: LVM-Thin vs ZFS Local - O Guia Definitivo de Performance e Trade-offs
Pare de adivinhar entre LVM-Thin e ZFS. Entenda a arquitetura de blocos, o impacto na RAM (ARC), métricas de IOPS e quando a complexidade do ZFS não paga a conta no Proxmox.
RAID Crítico: Guia de Engenharia para Recuperação de Arrays com Múltiplas Falhas (2026)
O array desmontou e o backup falhou? Pare tudo. Aprenda o protocolo 'Read-Only', clonagem forense com ddrescue e técnicas de remontagem virtual para salvar dados em cenários de desastre.

Sustentabilidade em Storage: Do Hype à Redução Real de Watts por TB
Esqueça o 'greenwashing'. Aprenda a medir Watts/TB, entenda a física dos HDDs a Hélio, o papel das fitas LTO e como a arquitetura de dados reduz a conta de energia e refrigeração.
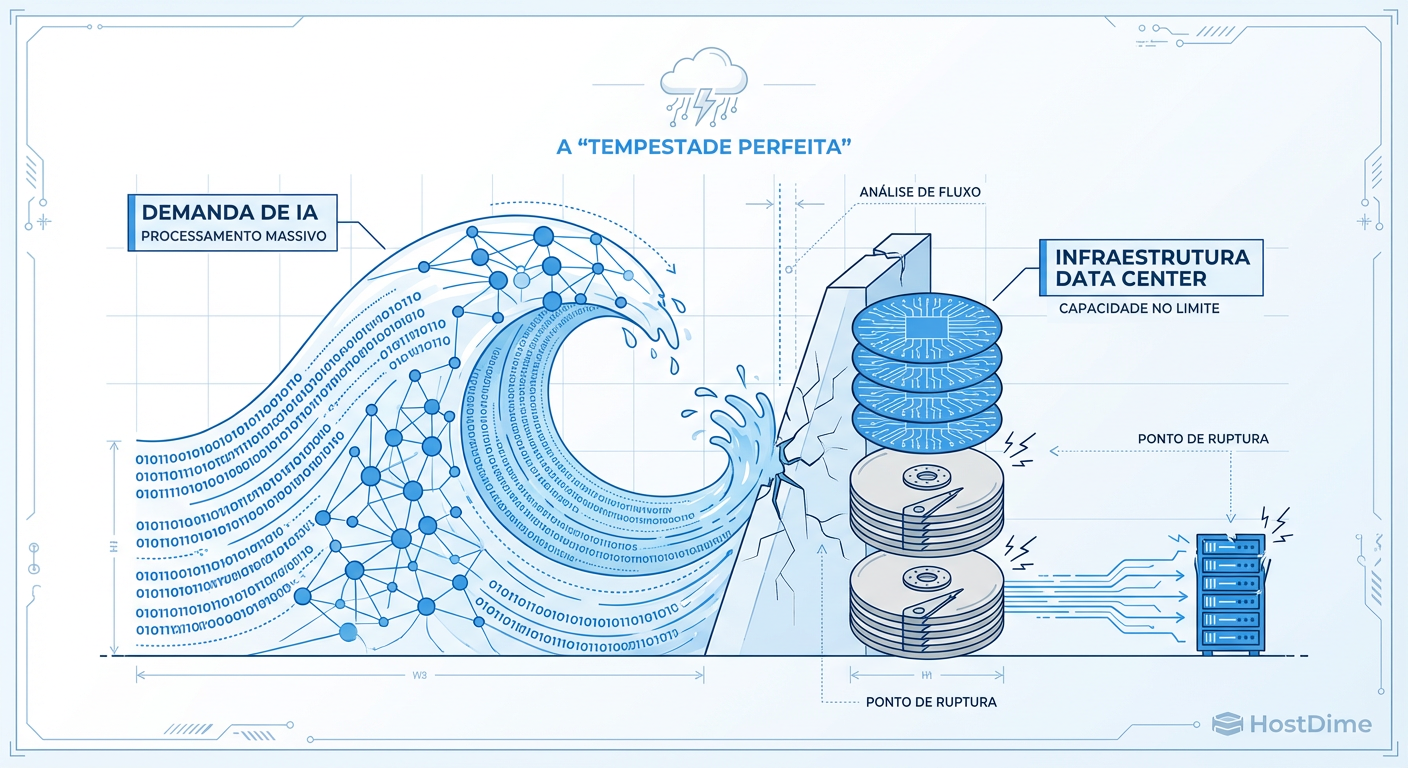
A Tempestade Perfeita do Storage em 2026: Quando a IA Quebrou a Cadeia de Suprimentos de NAND e HDD
Análise técnica da escassez de armazenamento prevista para 2026. Entenda como o ciclo de treinamento de IA colidiu com a estagnação da produção de wafers e como preparar sua infraestrutura.

O Choque de Preço dos SSDs Enterprise em 2025: Análise, Previsão 2026 e Estratégias de Sobrevivência
Os SSDs Enterprise dobraram de preço. Entenda o ciclo do NAND, o impacto da IA no forecast de 2026 e como auditar sua infraestrutura para não gastar orçamento à toa.

QLC SSDs vs. Nearline HDDs: A Morte do Disco Mecânico no Data Center de IA?
A transição de HDDs Nearline para QLC SSDs em workloads de IA não é luxo, é física. Analisamos densidade, Watts/TB e o temido 'Write Cliff' para provar o TCO.

QLC vs. TLC em Workloads de AI: Realidade de Endurance e Latência para 2026
Pare de superdimensionar storage. Entenda a física dos estados de voltagem, o impacto real na latência de cauda (p99) e onde o QLC é seguro para Arquiteturas de AI Enterprise.

Storage Enterprise na Era AI: Estratégias de Mitigação para Escassez e Latência
Seus arrays estão cheios e a latência alta? Aprenda a mitigar a escassez de storage em ambientes de IA, otimizando tiering, formatos de dados e arquitetura sem compras de pânico.

HAMR, MAMR e a Sobrevivência dos HDDs: A Matemática do Storage em 2026
O HDD morreu? Não se você souber fazer as contas. Análise técnica sobre HAMR, densidade de 30TB+ e o trade-off crítico de IOPS/TB para arquiteturas de dados em 2026.
Storage AI e TCO: Quando a Escassez de IOPS Mata o ROI das GPUs
Descubra como a escassez de componentes e gargalos de performance no storage impactam o TCO de projetos de IA. Aprenda a calcular o custo real de GPUs ociosas.
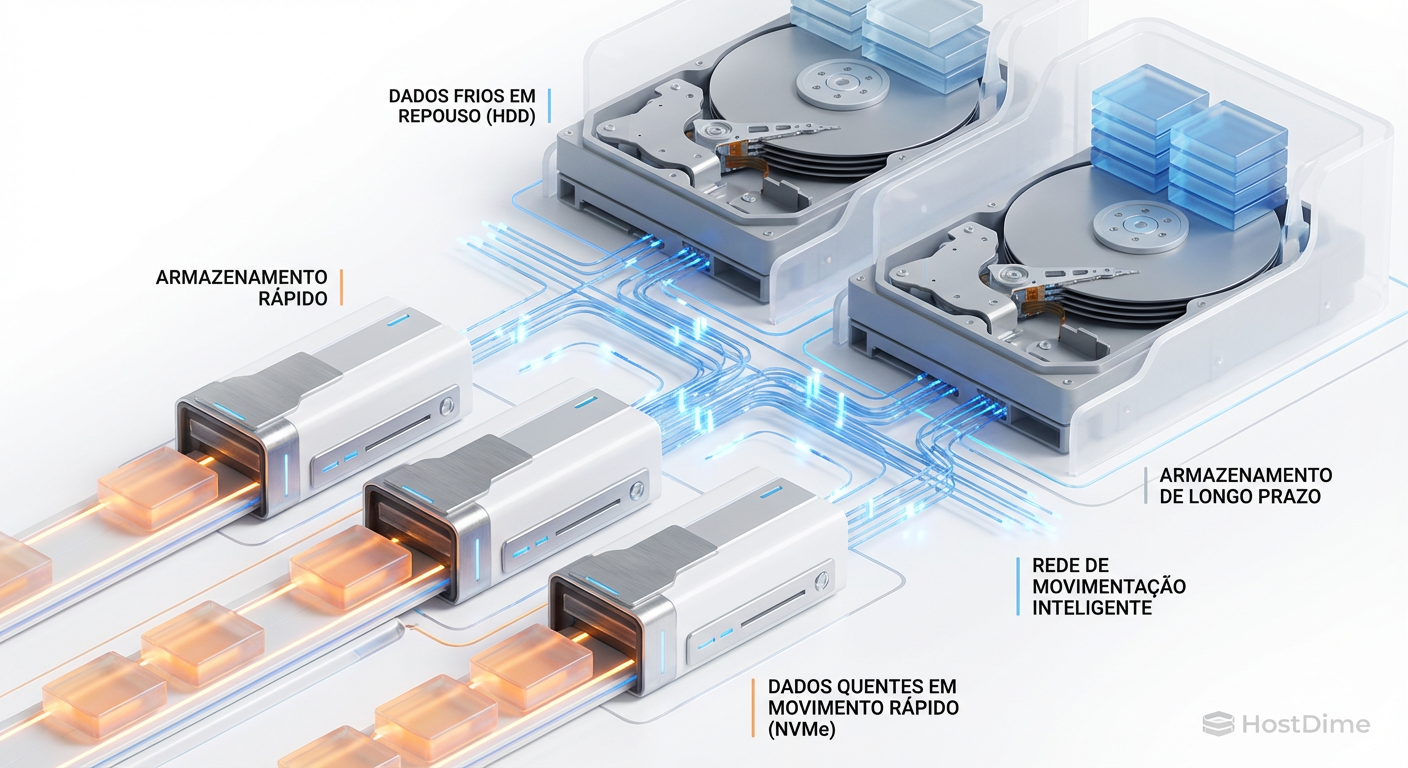
Storage Tiering Híbrido: Otimizando Ceph, vSAN e Storage Spaces na Escassez
Não compre Flash às cegas. Aprenda a arquitetar Tiering Inteligente e Caching em Ceph, vSAN e S2D para equilibrar IOPS e custo sem sacrificar a integridade dos dados.

QLC em Archival de IA: Física do Bit Rot, Retenção e Riscos Reais
Análise técnica sobre a viabilidade de SSDs QLC para armazenamento de longo prazo em IA. Entenda a física da retenção de dados, read disturb e por que o 'custo por TB' pode enganar.

O Fim da Era HDD e a Ascensão do Computational Storage: Realidade ou Hype para 2030?
Análise técnica sobre a paridade de custo SSD/HDD, o declínio dos discos mecânicos e como o Computational Storage resolverá o gargalo da CPU na próxima década.

O Choque do NVMe em 2025: Por que a IA Quebrou o Mercado de NAND (e Como Sobreviver)
Preços de SSDs Enterprise dobraram e a produção de 2026 já sumiu. Entenda a crise de NAND causada pela IA e as estratégias de arquitetura para salvar seu orçamento de storage.

DDR5 vs DDR4 em 2025: O Paradoxo do Preço e o Impacto do HBM no Enterprise
Em 2025, a escassez de wafers para HBM inverte a lógica de mercado: a memória DDR4 torna-se mais cara que a DDR5. Entenda o impacto no TCO de servidores, ZFS e infraestrutura.
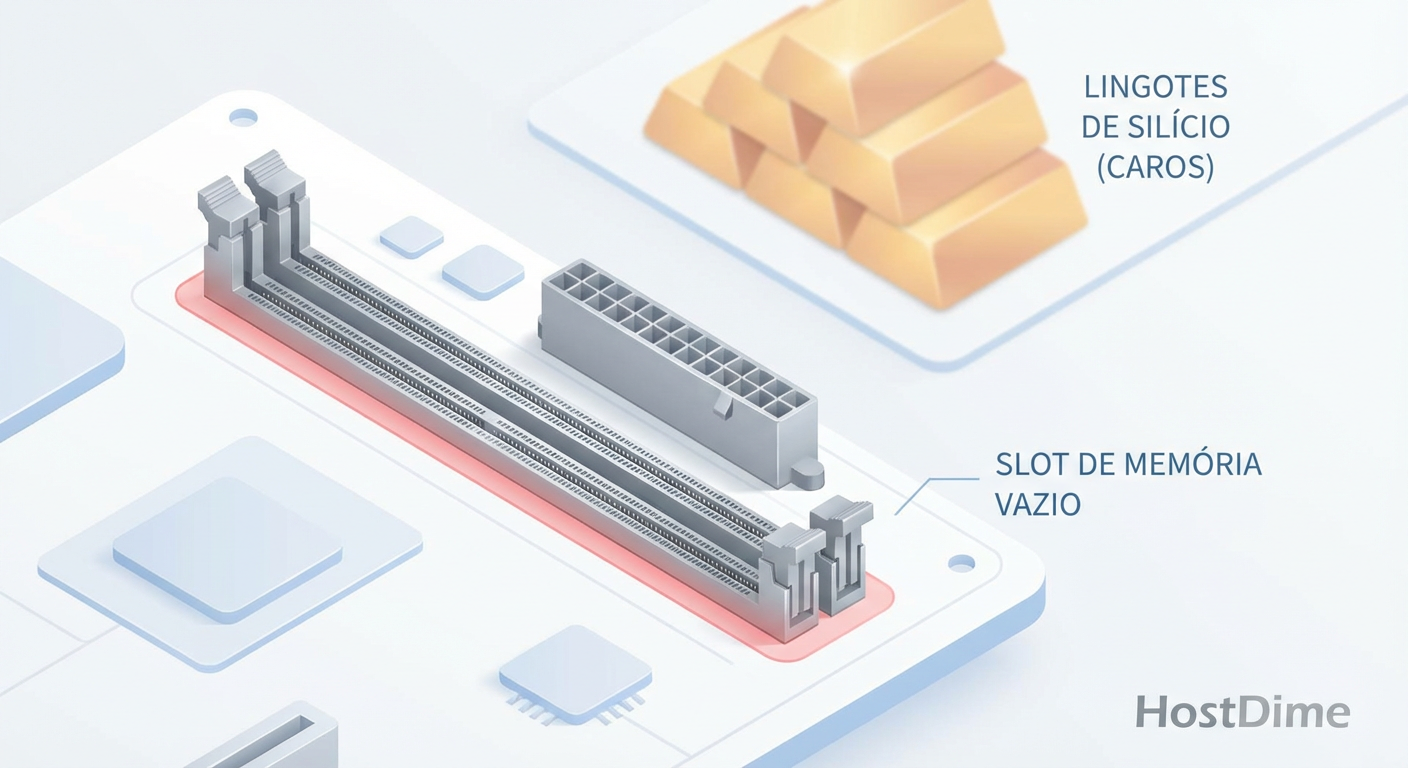
A Crise da DDR5: Engenharia de Sobrevivência para a Escassez de Memória em 2026
A DDR5 dobrou de preço e a previsão para 2026 é crítica. Entenda a causa raiz (HBM vs. DDR5), como medir o impacto real e técnicas de otimização (zswap, ZFS ARC, CXL) para evitar upgrades caros.
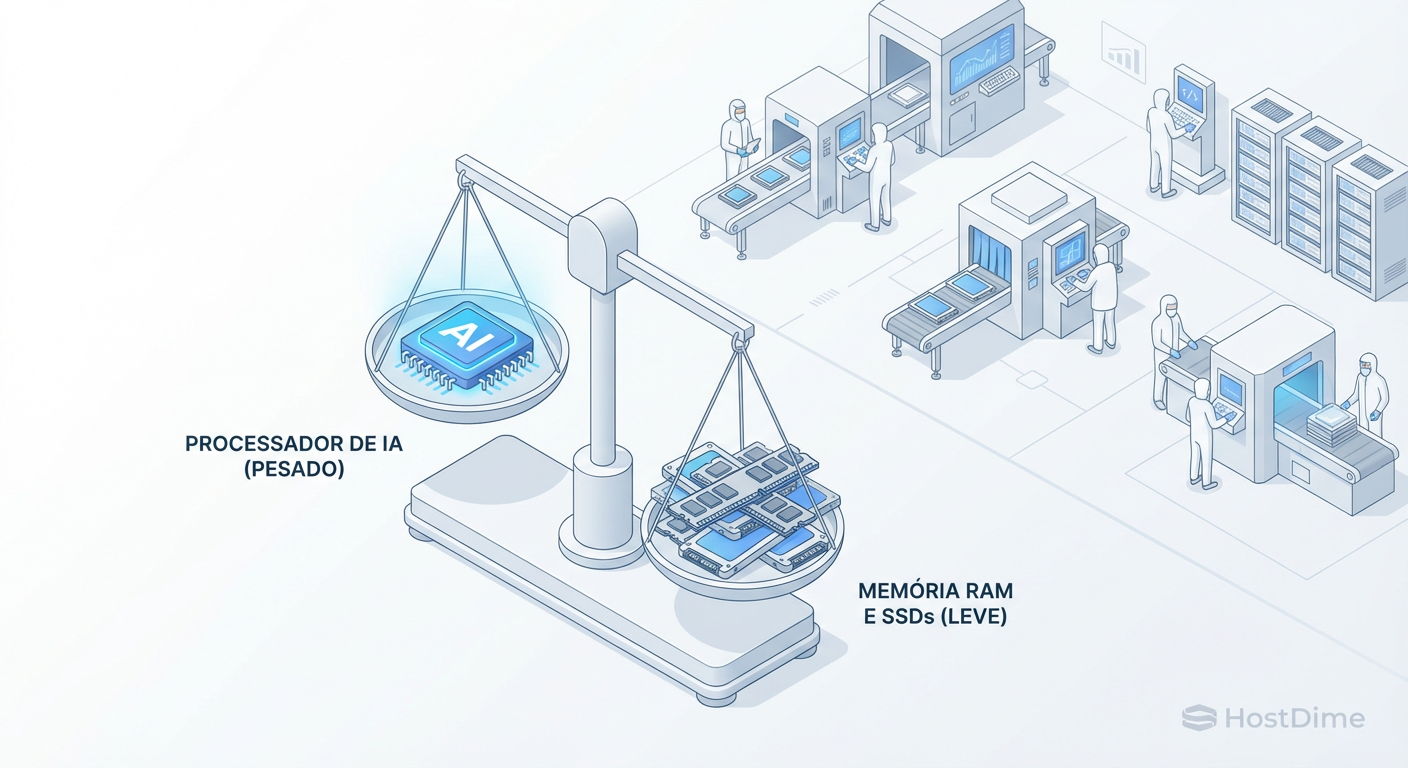
Crise de Hardware 2025: Estratégias de Sobrevivência para a Alta de SSDs e RAM
A demanda por IA está canibalizando a produção de NAND e DRAM. Entenda por que os preços vão triplicar e como auditar, otimizar e comprar storage de forma inteligente durante a escassez.

O Superciclo de Memória 2026-2027: Por que SSDs e DDR5 ficarão caros e como sobreviver
Análise técnica do superciclo de preços de SSD e DDR5 para 2026-2027. Entenda a escassez de wafers causada por IA/HBM e estratégias de arquitetura para mitigar custos de infraestrutura.
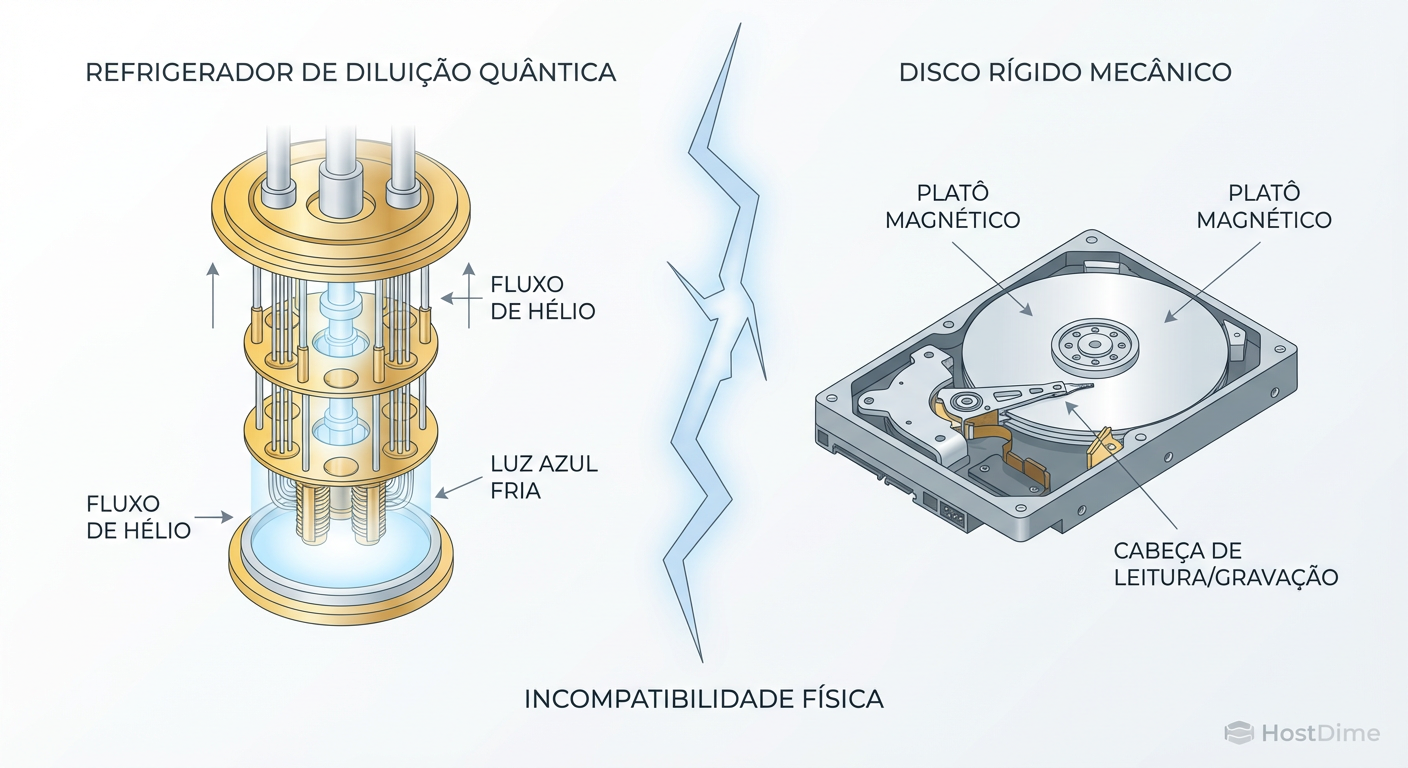
Memória Quântica não é Storage: O Mito do HD Quântico e a Realidade Física
Pare de esperar por SSDs quânticos. Entenda a diferença crítica entre estado quântico e persistência de dados, o Teorema da Não-Clonagem e por que o 'backup' quântico é fisicamente impossível.
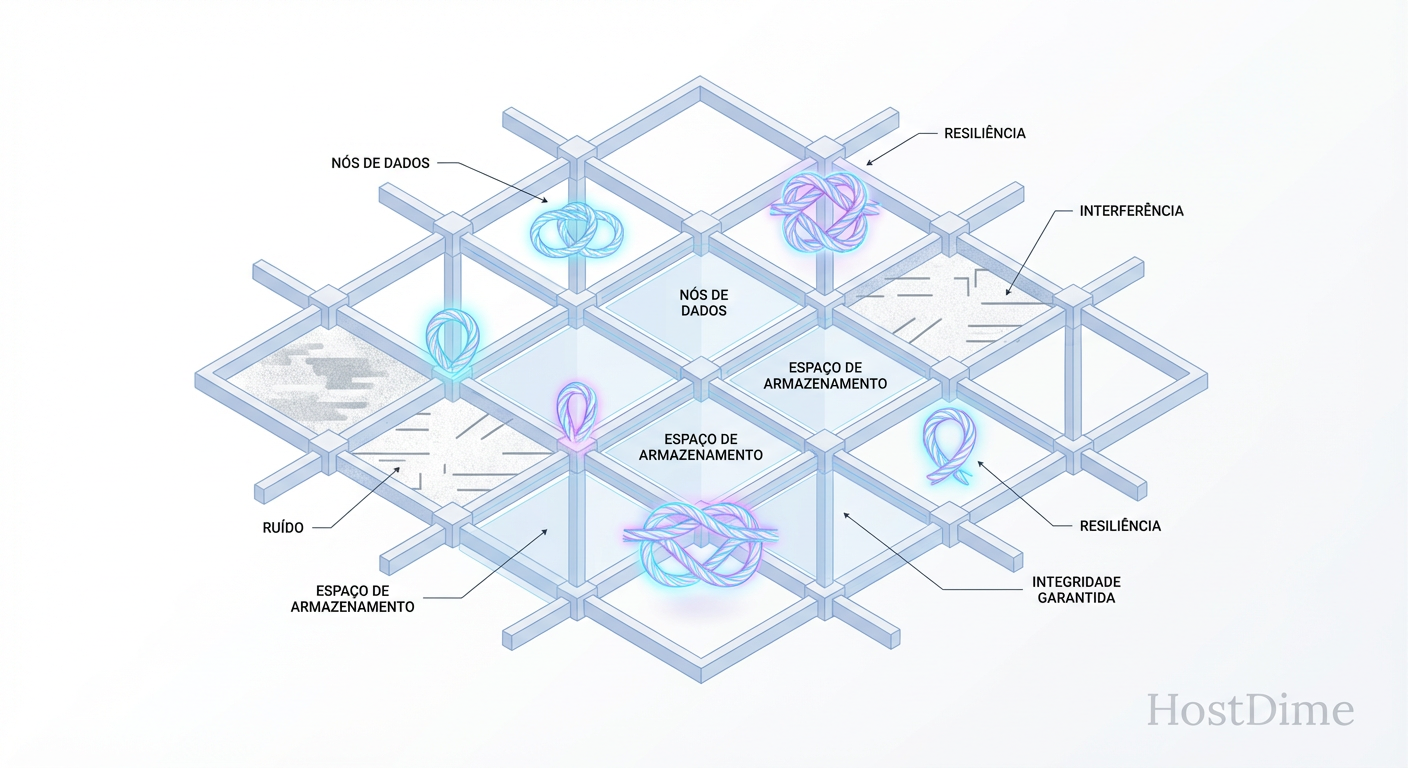
Storage Topológico: Quando a Geometria Salva seus Dados do Caos
Descubra como o Storage Topológico supera o bit-rot usando informação não-local. Entenda a física por trás da resiliência absoluta contra erros locais e o futuro além do ECC.

Limite de Landauer: O Custo Termodinâmico de Apagar Dados
Entenda o Limite de Landauer e por que apagar bits gera calor físico inevitável. Uma análise forense da termodinâmica aplicada a SSDs, eficiência energética e o futuro do storage.

Memórias Probabilísticas e Storage Class Memory: PCM, ReRAM e a Realidade dos Estados Instáveis
Entenda a física e os trade-offs do PCM e ReRAM. Uma análise técnica sobre Storage Class Memory, drift de resistência e por que o futuro do armazenamento lida com probabilidades, não apenas bits estáticos.

Storage como Estado Global: Por que o Modelo de Blocos Falha em Escala
Abandone a ilusão do disco local. Entenda por que arquiteturas modernas tratam storage como API de estado global, os riscos do POSIX distribuído e como projetar para consistência eventual.

Storage Quântico e Memória Quântica: A Realidade além do Hype
Esqueça SSDs infinitos. Entenda o que é Storage Quântico (Quantum Memory), o desafio da coerência temporal e por que ele é o 'Santo Graal' para a Internet Quântica.

Memória Quântica na Prática: A Realidade Técnica por Trás do Hype
Esqueça SSDs mais rápidos. Entenda como a memória quântica realmente funciona, os desafios de coerência e fidelidade, e por que ela é vital para a internet quântica, não para o seu banco de dados.

Storage Quântico vs SSD: A Verdade Física Além do Hype
Entenda as limitações físicas do NAND Flash, o problema do tunelamento quântico em SSDs atuais e o que realmente significa 'Storage Quântico' longe do marketing.
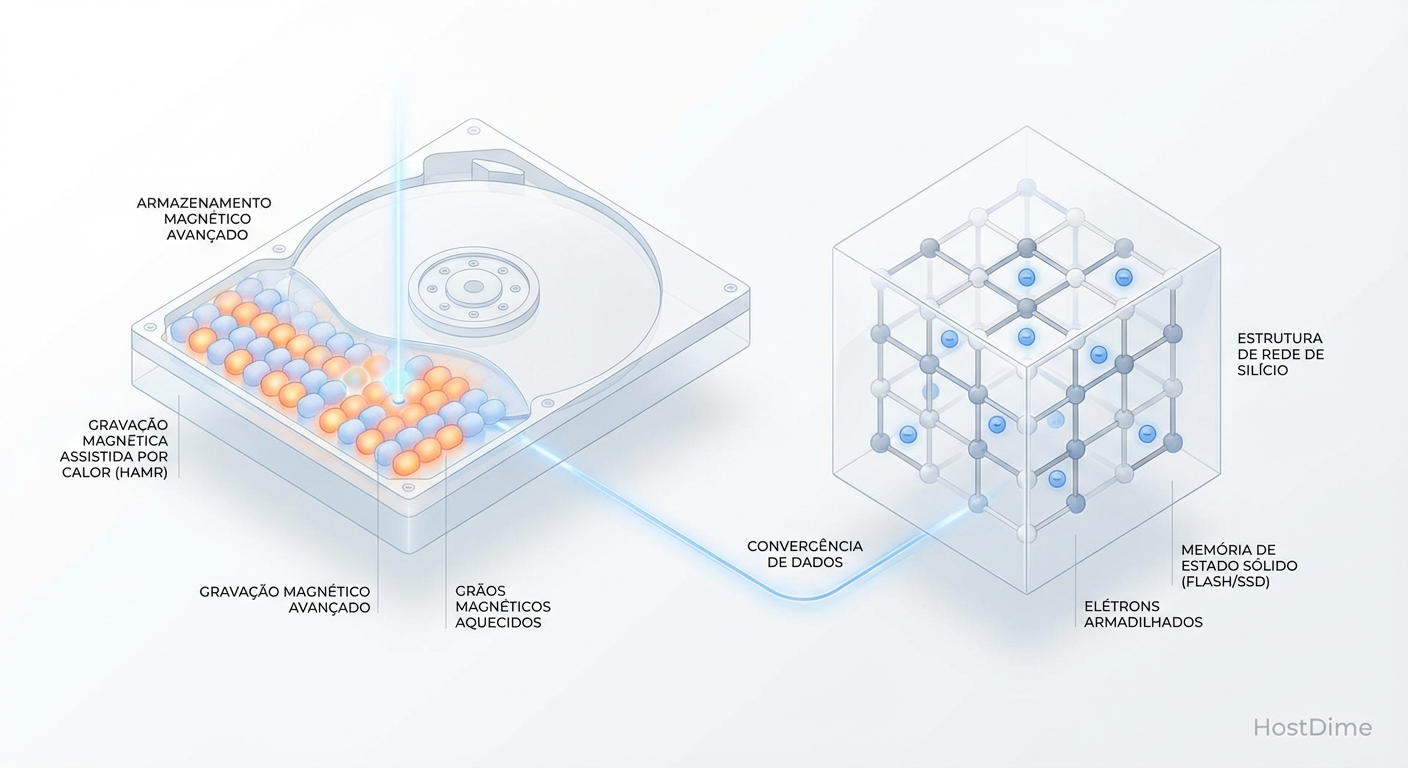
Limites Físicos do Storage: Quando a Física Impede o Terabyte Extra
Entenda as barreiras reais do armazenamento de dados: do efeito superparamagnético em HDDs ao tunelamento quântico em SSDs e a inevitável entropia.

Storage Quântico e o Data Center: Separando a Física do Marketing
O storage quântico vai substituir o NVMe? Entenda os desafios reais de coerência, o teorema da não-clonagem e o impacto imediato na criptografia de dados em repouso.
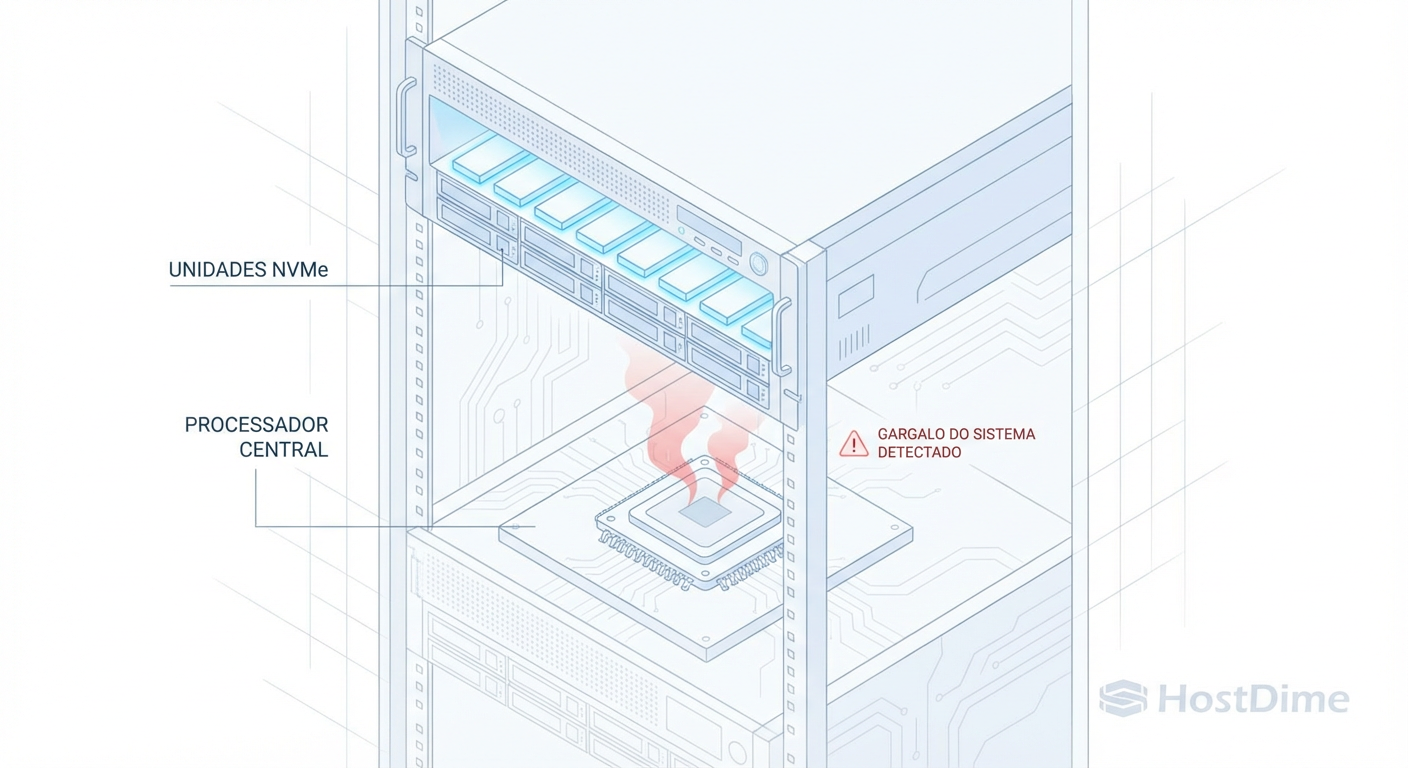
Ceph All-Flash: Por que NVMe Rápido Pode Quebrar a Estabilidade do Cluster
Migrou para NVMe e o Ceph ficou instável? Entenda o paradoxo da baixa latência com alta instabilidade, gargalos de CPU e como tunar RocksDB e BlueStore.
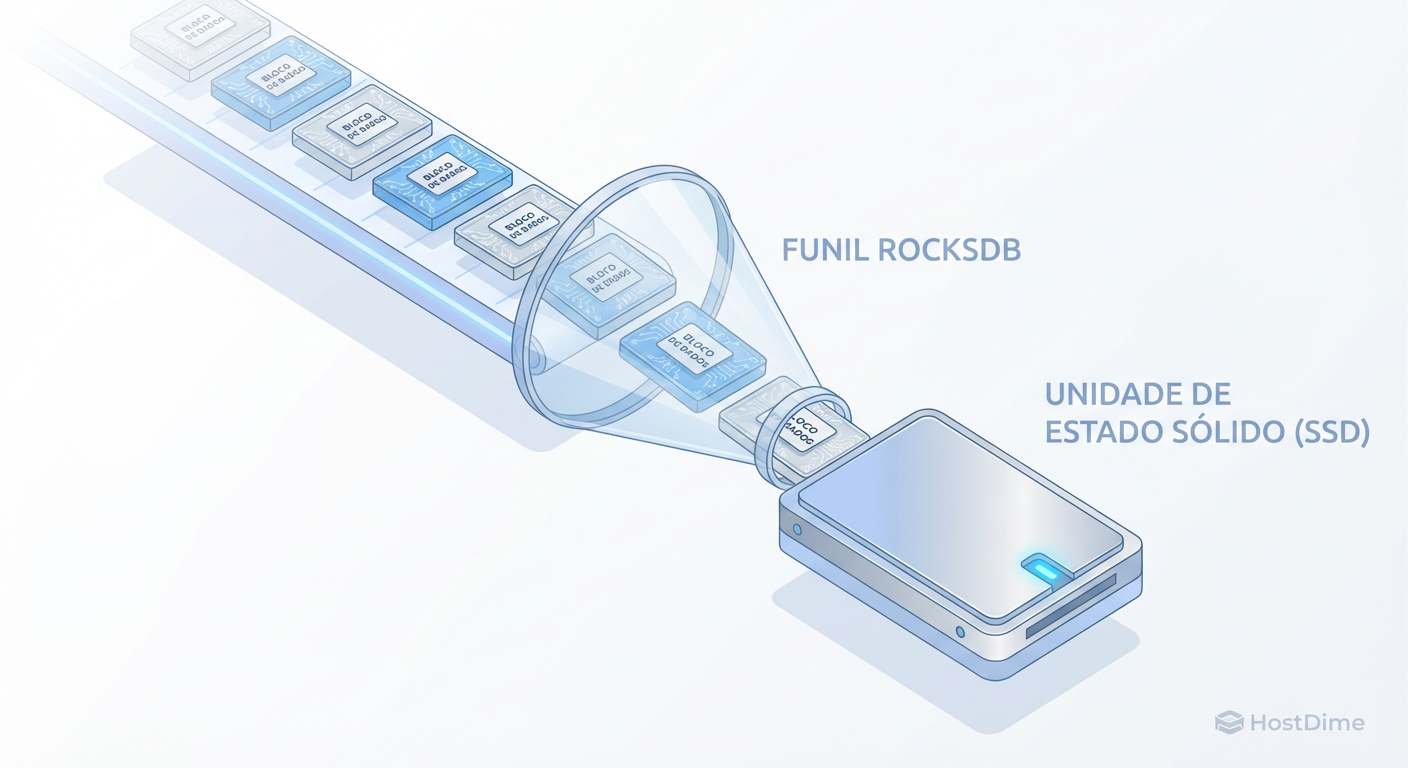
Ceph BlueStore Internals: A Anatomia do IOPS e o Layout de WAL/DB
Pare de adivinhar o tamanho do seu block.db. Entenda como o BlueStore realmente grava dados, o impacto do RocksDB no IOPS e como evitar o pesadelo do spillover.
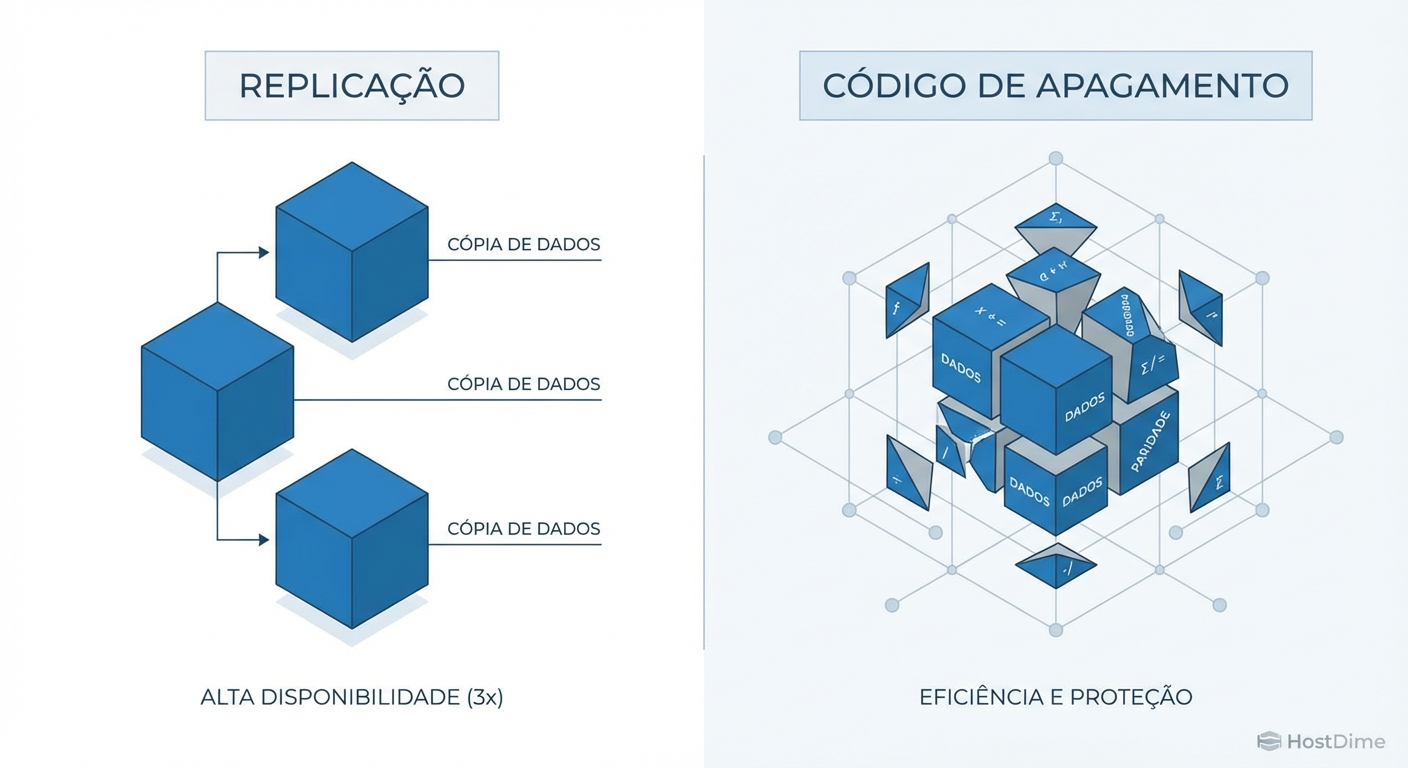
Ceph Replica vs Erasure Coding: O Preço da Latência na Economia de Disco
Economizar 50% de armazenamento com Erasure Coding no Ceph pode custar caro em latência e CPU. Analisamos o trade-off real entre Replica 3x e EC (k+m) para Block Storage e Object.
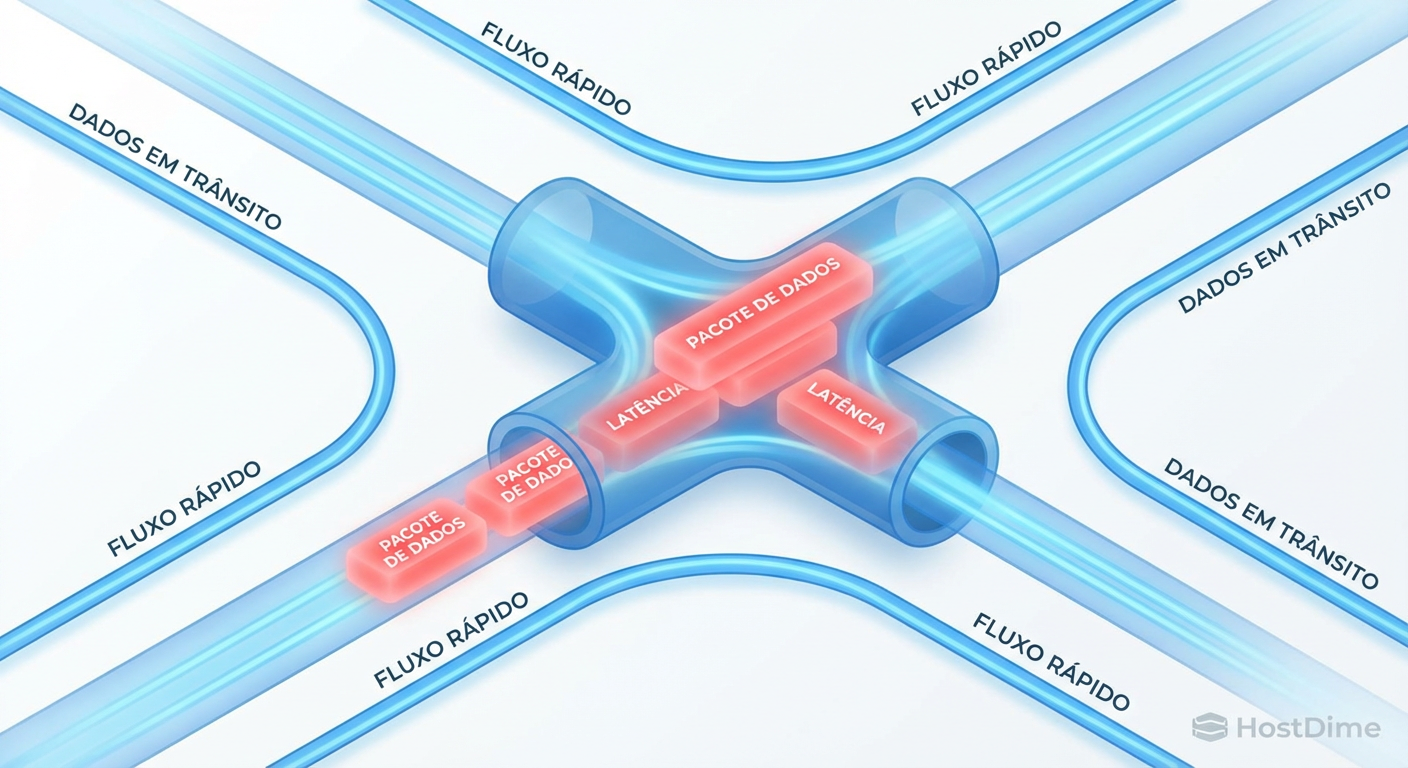
Ceph e Hypervisors: A Anatomia Forense dos Picos de Latência
Suas VMs travam aleatoriamente? Descubra a causa raiz dos latency spikes na interação entre KVM/QEMU e Ceph, do cache do disco ao penalty de replicação.
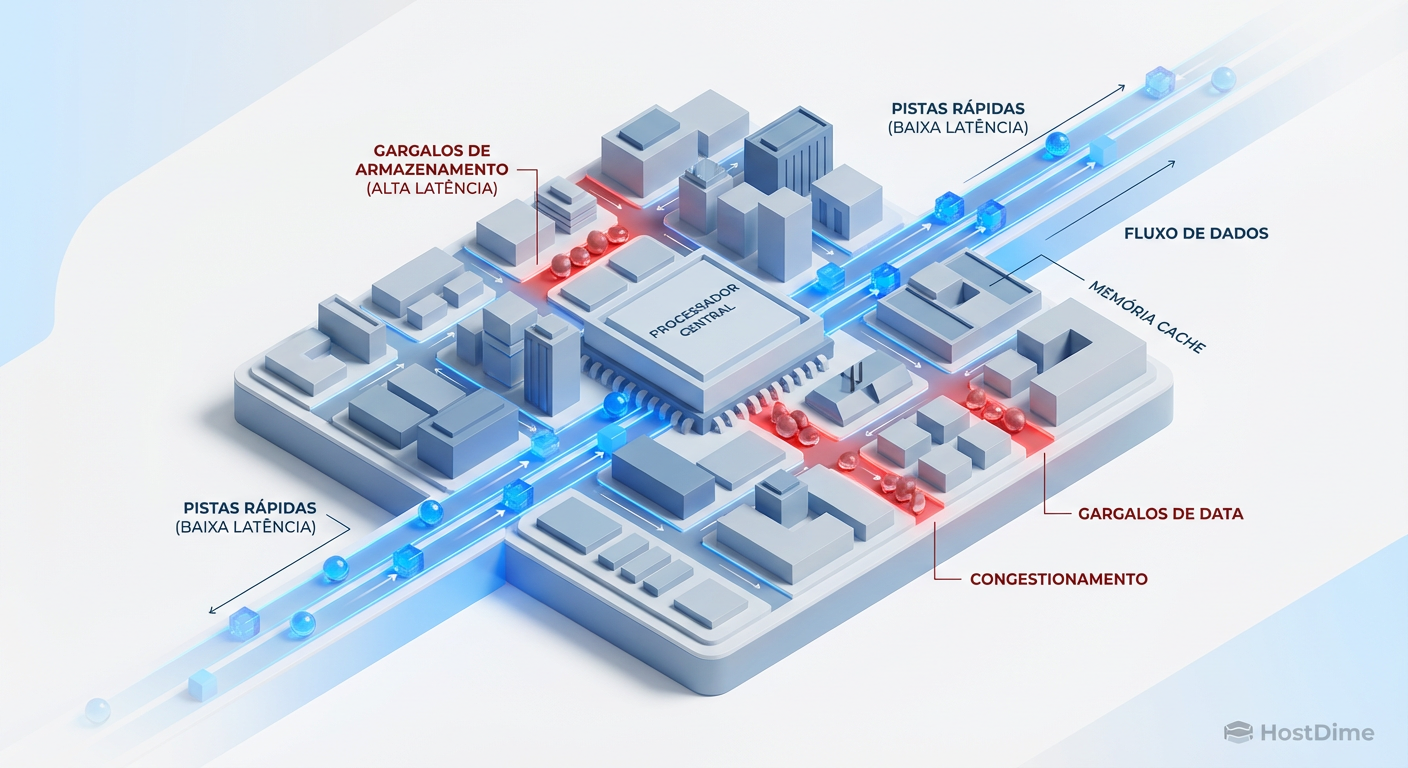
Ceph Tuning para VMs: Anatomia de Workloads DB, ERP e VDI
Suas VMs no Ceph estão lentas? Esqueça a largura de banda. Aprenda a tunar latência, cache RBD e Bluestore especificamente para Bancos de Dados, VDI e ERPs monolíticos.
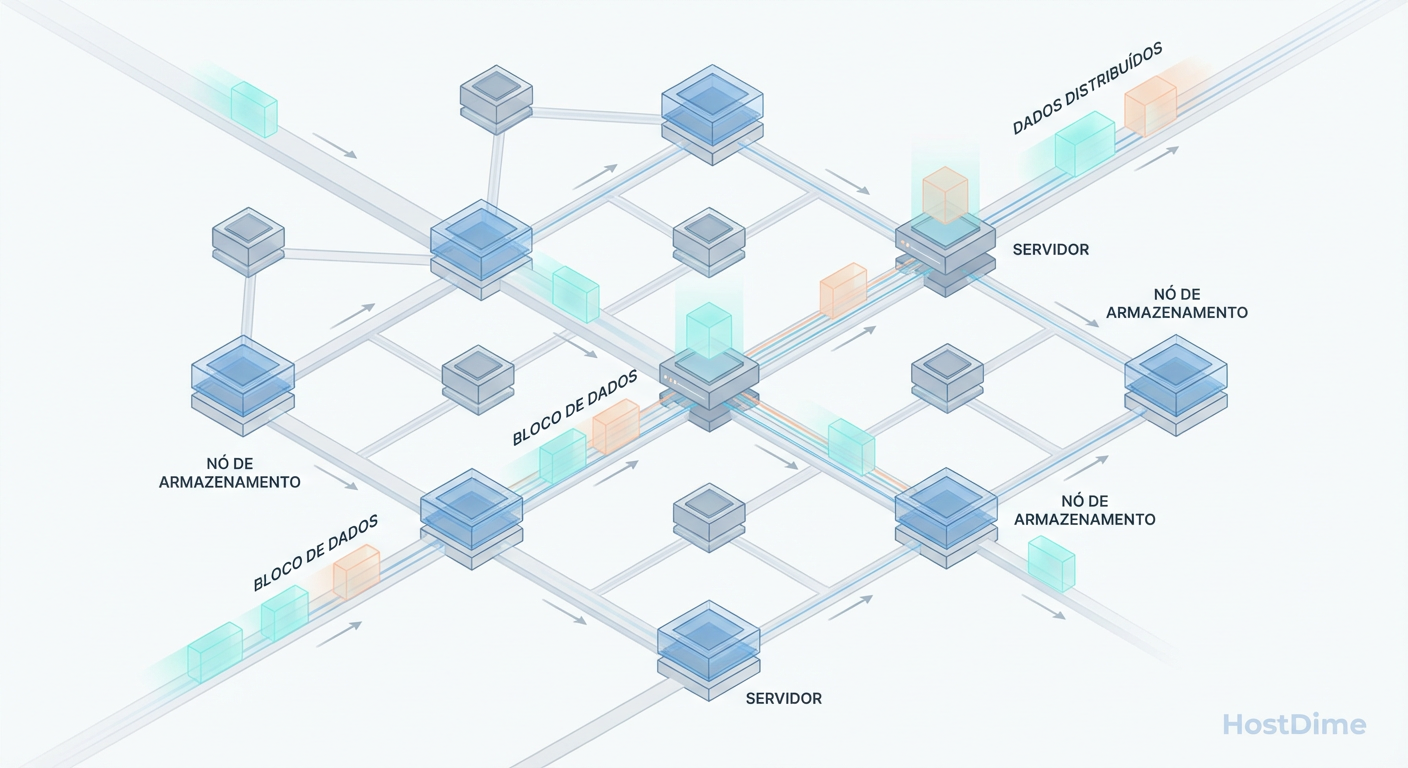
O Paradoxo de Performance do Ceph: Por que seus Benchmarks estão Mentindo
Entenda por que o Ceph parece lento em testes sintéticos mas escala em produção. Aprenda a medir latência distribuída, fila de I/O e a evitar a armadilha do 'dd'.

CephFS vs RBD: A Verdade Sobre Performance em Virtualização
Pare de matar a performance das suas VMs. Entenda a arquitetura de I/O, o custo do MDS no CephFS e por que o RBD é o padrão ouro para blocos em ambientes virtualizados.
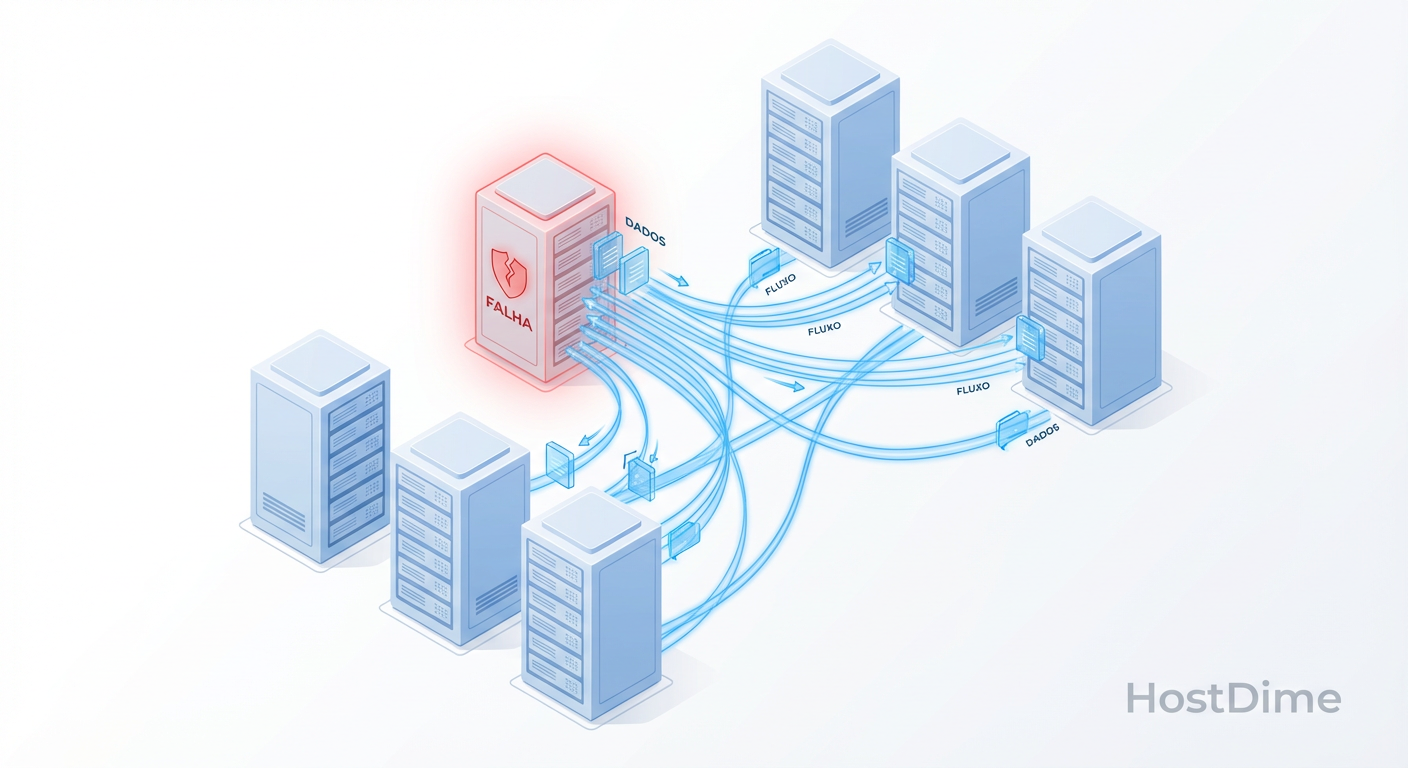
Ceph Recovery e Rebalance: Por que a Latência Explode e Como Controlar
Entenda a física do Ceph Recovery e Backfill. Descubra por que falhas de OSD geram tempestades de I/O e aprenda a ajustar o mClock e throttles para proteger a latência de produção.

Escalabilidade no Ceph: O Ponto de Ruptura dos OSDs e a Falácia do Infinito
O Ceph não escala infinitamente sem custos. Entenda como o excesso de OSDs satura os MONs, degrada o OSDMap e cria tempestades de peering que derrubam sua performance.
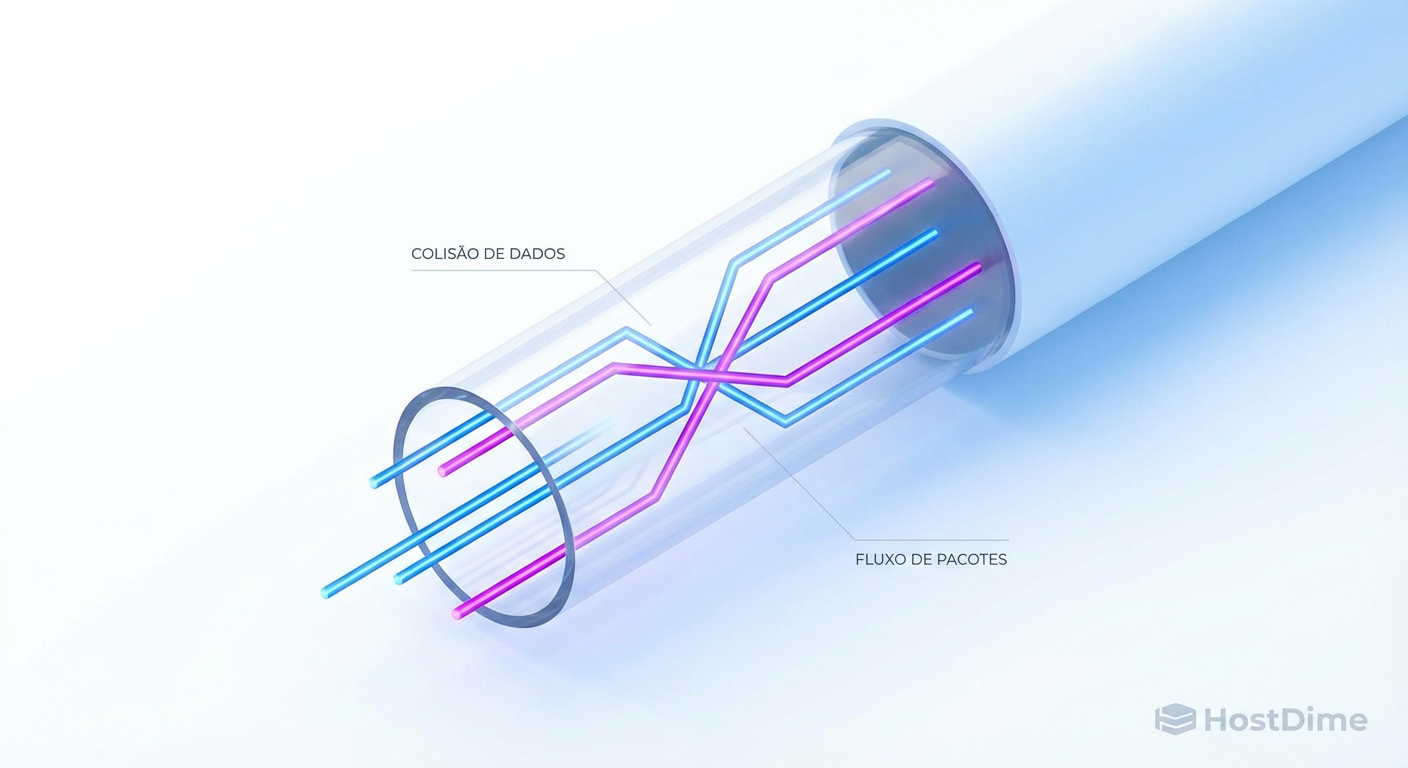
Network Jitter vs. Storage Distribuído: O Assassino de Performance Oculto
Alta largura de banda não salva seu cluster se a variância da latência (jitter) estiver alta. Entenda como o jitter na rede mata a performance de IOPS em Ceph, vSAN e iSCSI.

Ceph Networking: 10GbE vs 25GbE vs 100GbE e a Verdade sobre Gargalos
Pare de desperdiçar orçamento em placas 100GbE sem motivo. Descubra onde o gargalo real do Ceph se esconde: latência, CPU ou rede, e quando migrar de 10GbE para 25GbE.

Ceph no Proxmox: 5 Erros de Arquitetura que Custam Caro (e Como Evitar)
A facilidade da GUI do Proxmox esconde a complexidade do Ceph. Descubra por que SSDs sem PLP, redes de 1GbE e Réplica 2 são bombas-relógio no seu cluster HCI.
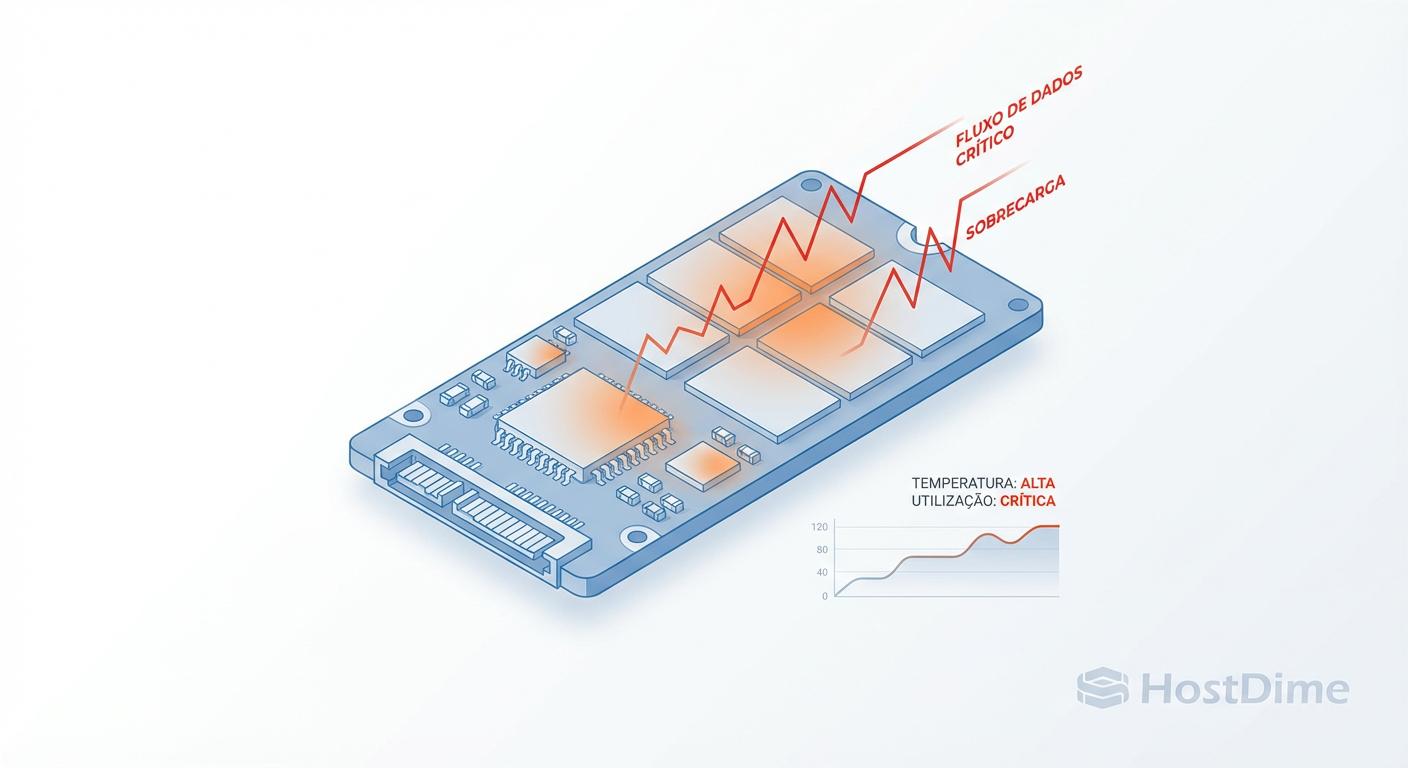
Ceph Write Amplification: Por que seus SSDs morrem cedo (e como evitar)
Seus SSDs no cluster Ceph estão desgastando rápido demais? Entenda a matemática brutal da Write Amplification, o papel do BlueStore e como tunar seu storage para sobreviver.
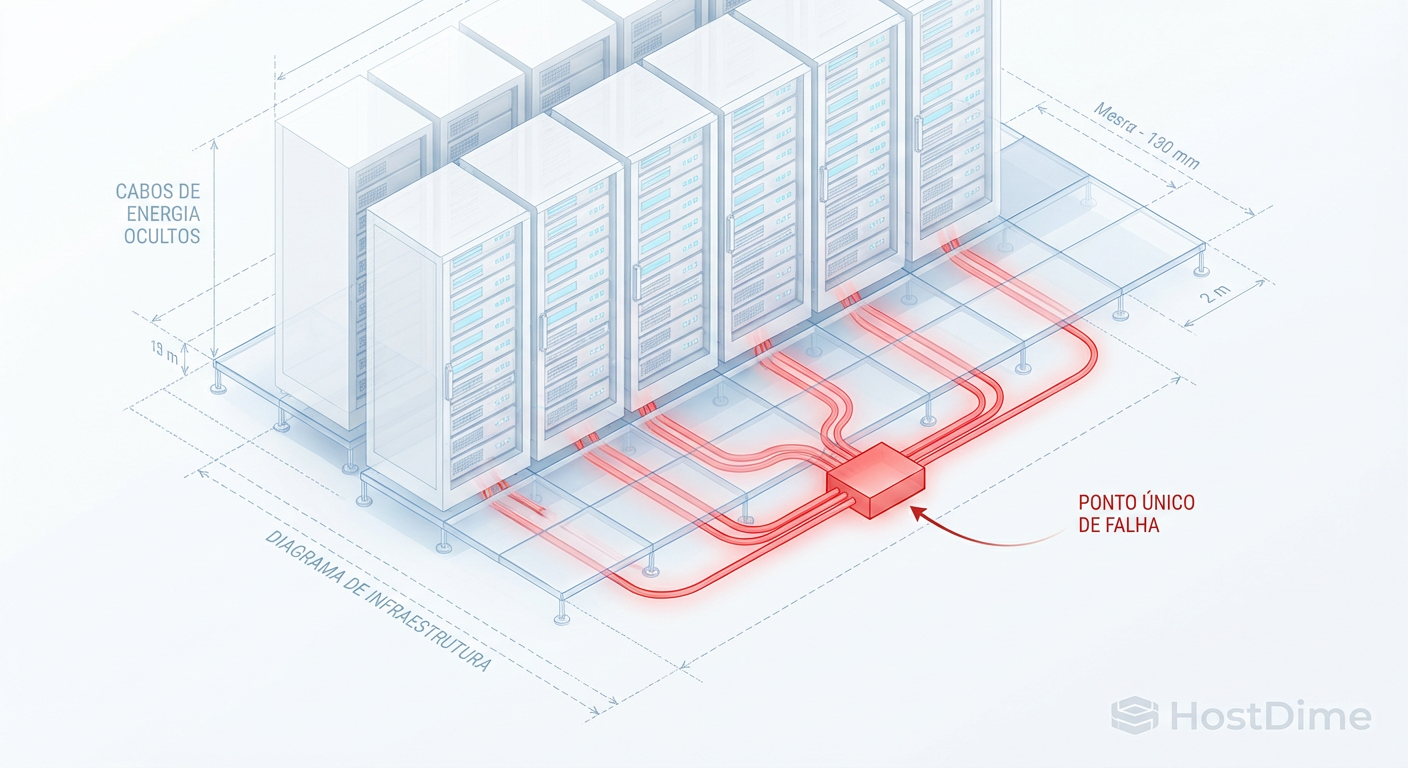
Ceph Failure Domains: Por que Rack-Aware não é suficiente (e o custo da paranóia)
A redundância de rack no Ceph falha quando dependências invisíveis (PDU, Switch, Ar-condicionado) são compartilhadas. Aprenda a mapear riscos reais no CRUSH map.

Ceph MON e Quorum: O Assassino Silencioso de Clusters (Arquitetura e Debug)
Seus OSDs estão de pé, mas o IO parou? Entenda como falhas de quorum, latência no RocksDB e clock skews nos Monitores Ceph derrubam sua infraestrutura.

Thin Provisioning no Ceph RBD: Arquitetura, Riscos de Overcommit e TRIM
Entenda como o Thin Provisioning funciona no Ceph RBD, os perigos reais do overcommitment em ambientes multi-tenant e como gerenciar o TRIM sem derrubar a performance.

Latência p99 em Storage Distribuído: Por que seu Banco de Dados trava (e o IOPS não importa)
Seu ERP está lento mas o monitoramento diz que está tudo bem? Descubra como a latência p99 (tail latency) em storage distribuído destrói a performance de bancos de dados transacionais e como medir o que realmente importa.
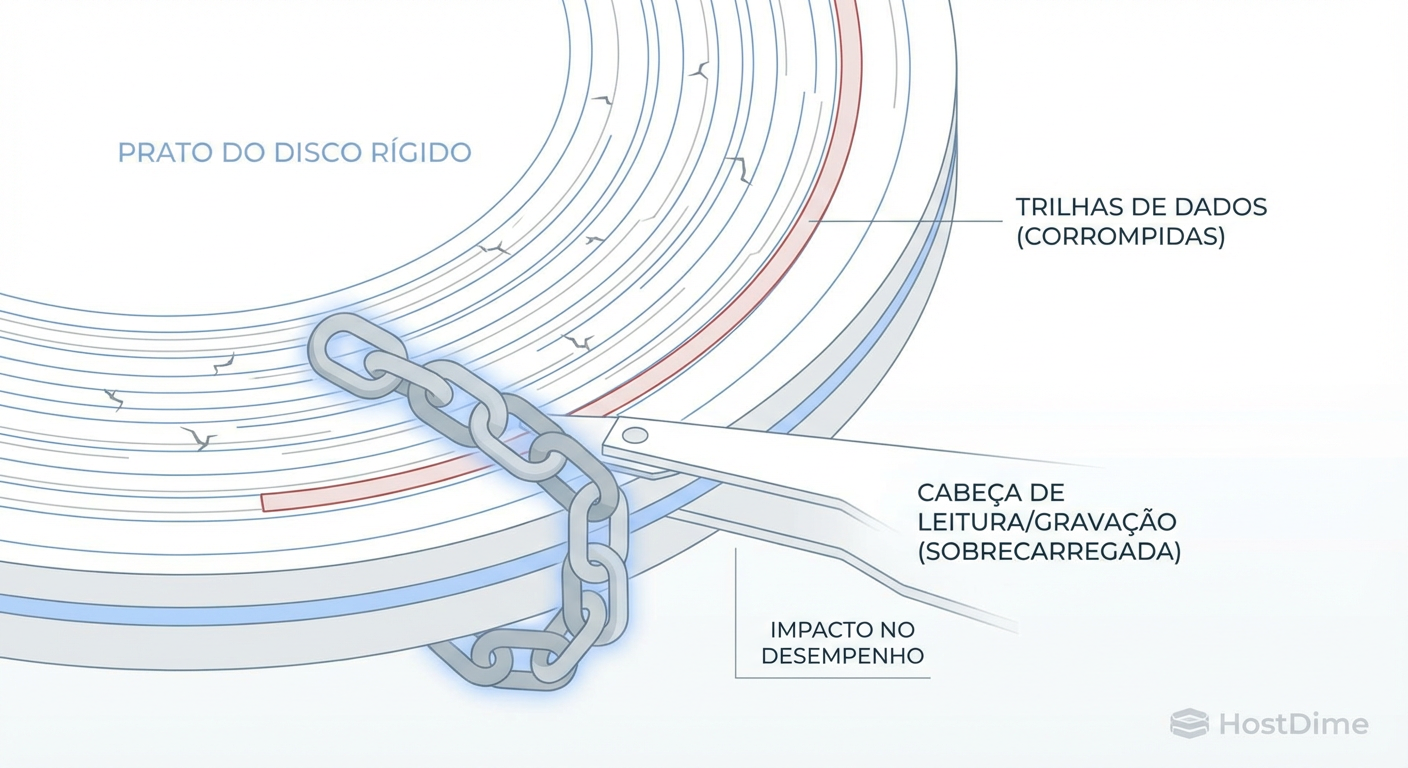
Ceph e Snapshots de VM: O Custo Invisível na Performance de Escrita (RBD)
Snapshots no Ceph não são de graça. Entenda a penalidade de Copy-on-Write (CoW), o impacto em latência de escrita e como medir o gargalo em volumes RBD.

Controladoras RAID NVMe em 2025: Análise Técnica das LSI/Broadcom Tri-Mode
Hardware RAID morreu? Não para NVMe. Análise forense das controladoras Broadcom 9500/9600, trade-offs de latência, cabeamento U.3 e quando abandonar o ZFS pelo silício.

RAID 5 com Discos de Tamanhos Diferentes: O Guia Definitivo de Capacidade e Desperdício
Descubra a matemática real por trás do RAID 5 com discos mistos. Entenda o desperdício de espaço, o gargalo do menor disco e quando soluções como SHR ou Btrfs superam o RAID tradicional.
RAID 6 vs RAID 5: A Verdade Sobre o Overhead de Escrita e Double Parity
Esqueça o medo infundado. Entenda a matemática do Read-Modify-Write (RMW), o impacto real do Double Parity em IOPS randômicos e por que o ganho de performance do RAID 5 raramente compensa o risco.

RAID 10 (1+0) em Bancos de Dados: Performance, Trade-offs e Configuração Real
Esqueça o 'best practice' genérico. Entenda a matemática de IOPS do RAID 10, por que ele supera o RAID 5/6 em latência de escrita e como configurar o chunk size correto para seu banco de dados.

Falhas Silenciosas em SSDs NVMe: O Abismo da Recuperação de Dados
Entenda por que SSDs NVMe falham sem aviso prévio. Uma análise técnica sobre FTL, corrupção de controlador e por que a recuperação é exponencialmente mais difícil que em HDDs.

TRIM, Garbage Collection e a Morte Silenciosa dos SSDs em RAID
Seus SSDs em RAID podem estar morrendo prematuramente. Entenda a interação crítica entre TRIM, Garbage Collection e Write Amplification, e aprenda a configurar seu array para longevidade real, seja em ZFS, mdadm ou Hardware RAID.
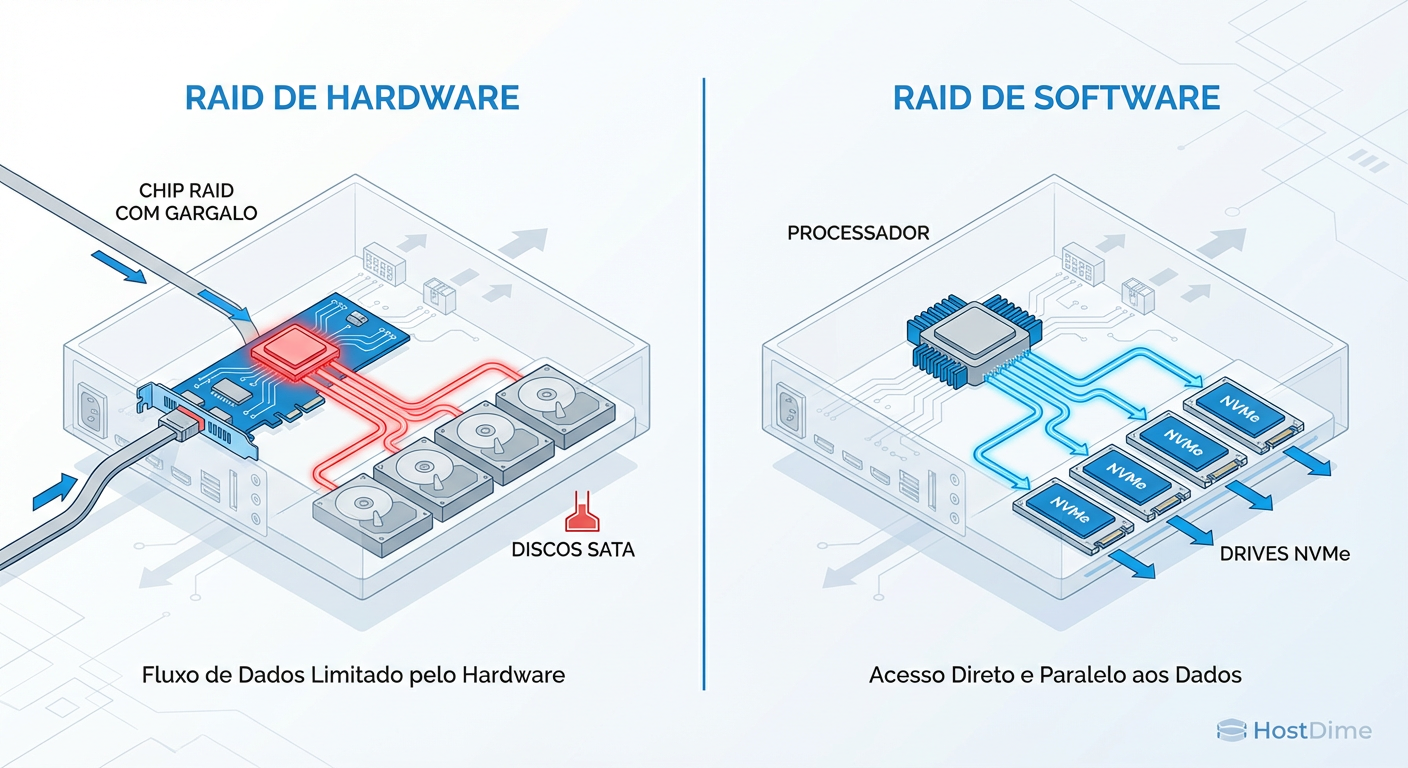
RAID Hardware vs Software (mdadm) em 2025: O Fim da Era das Controladoras?
Descubra por que o debate RAID Hardware vs Software mudou. Análise técnica de performance (NVMe vs SAS), segurança de dados e o risco do 'Vendor Lock-in' com mdadm no Linux moderno.

RAID 5 Rebuild: Otimizando Tempos de Reconstrução com Distributed Spares
Reduza o tempo de rebuild do RAID 5 de dias para horas. Entenda a matemática dos Distributed Spares (dRAID), elimine o gargalo do disco único e evite falhas catastróficas por URE.

LVM e Expansão de Storage: Adicionando Discos a Quente sem Downtime
Aprenda a expandir volumes RAID e LVM em servidores ativos sem desmontar partições. Um guia prático sobre PVs, VGs, LVs e redimensionamento de filesystem seguro.

RAID 0 com NVMe: O Mito da Escala Linear de IOPS e a Realidade da CPU
Descubra por que adicionar mais SSDs NVMe em RAID 0 não garante IOPS infinitos. Entenda os gargalos de CPU, PCIe e como calcular o desempenho real.
Parity Scrubbing Automatizado: A Única Defesa Real Contra o Bit Rot
O bit rot é silencioso e inevitável. Aprenda como o Parity Scrubbing automatizado detecta e corrige corrupção de dados antes que seja tarde demais. Guia prático para ZFS, MDADM e Btrfs.

RAID-Z vs. Hardware RAID: A Anatomia da Integridade de Dados no ZFS
Hardware RAID protege o disco, ZFS protege o dado. Entenda o 'Write Hole', a árvore de Merkle e por que o RAID-Z elimina a corrupção silenciosa onde controladores tradicionais falham.

RAID-Z2 vs RAID-Z3: A Matemática da Sobrevivência em Discos de 20TB+
RAID-Z2 ainda é seguro? Analisamos a probabilidade de falha durante o resilvering, o impacto de performance do RAID-Z3 e quando a tripla paridade é obrigatória.
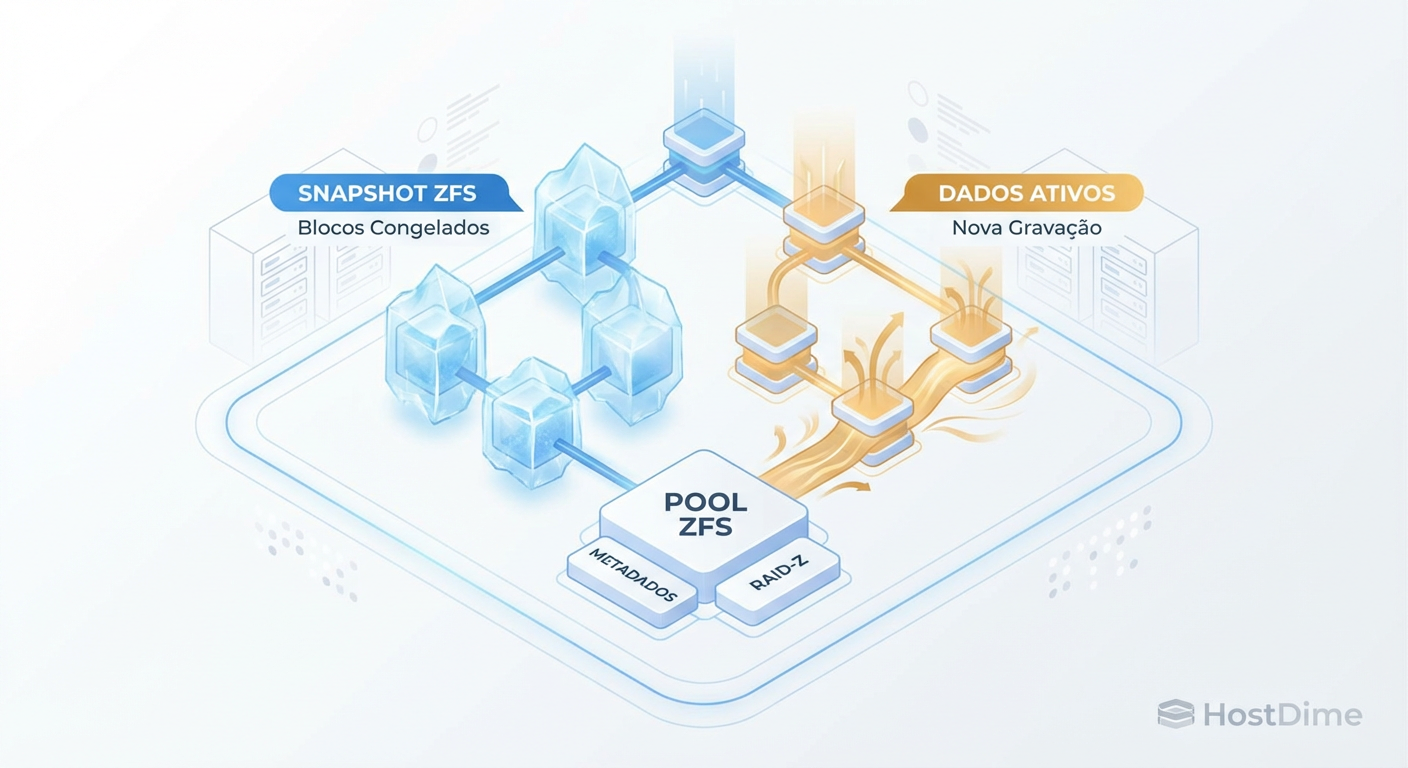
Domine Snapshots e Clones no ZFS: Arquitetura, RAID-Z e Performance
Entenda a mecânica Copy-on-Write dos snapshots ZFS. Descubra como gerenciar clones, evitar overhead em RAID-Z e interpretar métricas de 'Used' vs 'Referenced'.
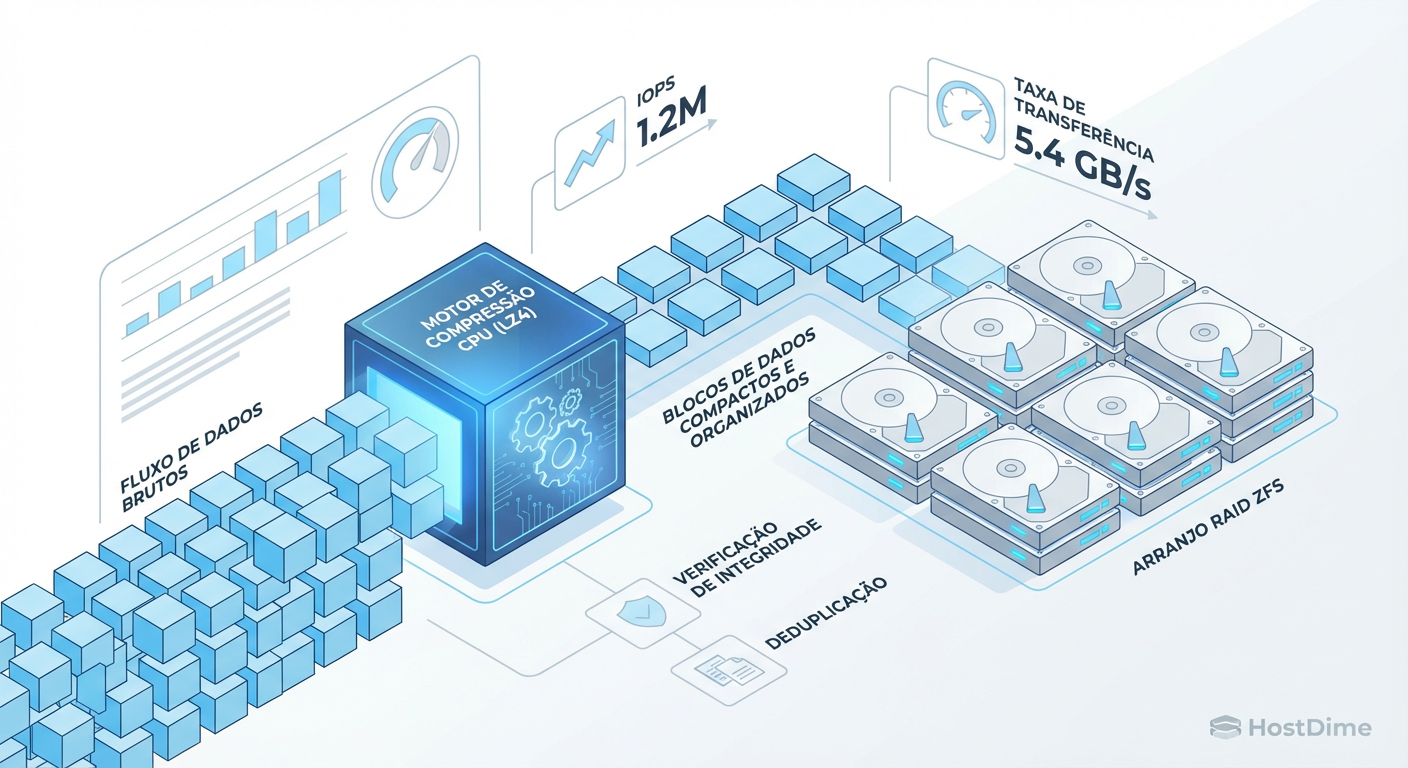
ZFS Compression em RAID-Z: Análise Forense de Performance e Trade-offs
A compressão inline no ZFS não serve apenas para economizar espaço. Descubra como algoritmos como LZ4 e ZSTD podem acelerar o throughput em vdevs RAID-Z e entenda o impacto do 'padding' na eficiência.

Deduplicação no ZFS: O Custo Oculto da Economia de Espaço em Arrays Enterprise
Ativar 'zfs set dedup=on' pode destruir a performance do seu storage. Entenda a Tabela de Deduplicação (DDT), o impacto na RAM e por que a compressão ZSTD geralmente é a melhor escolha.

Btrfs RAID 5/6 em 2025: O Veredito Técnico sobre Estabilidade e o "Write Hole"
Btrfs RAID 5/6 ainda corrompe dados? Analisamos o status do Kernel 6.x, a persistência do Write Hole e a estratégia de Metadata em RAID1c3 para quem precisa de densidade.

Migração Btrfs: Convertendo RAID 1 para RAID 5 (Guia de Sobrevivência)
Aprenda a converter um array Btrfs de RAID 1 para RAID 5 on-line. Entenda os riscos do 'write hole', a importância dos metadados em RAID 1 e como executar o balanceamento sem perda de dados.

Btrfs vs ZFS: Análise Profunda de Checksums e Mecanismos de Self-Healing
Entenda como Btrfs e ZFS combatem o 'bit rot' silencioso. Uma comparação técnica dos algoritmos de checksum, árvores de Merkle e a realidade da autocorreção de dados.

Btrfs além do Hype: Domine Subvolumes, Snapshots e Backups Incrementais
Pare de confiar cegamente no RAID. Entenda a arquitetura CoW do Btrfs, configure subvolumes corretamente e implemente backups incrementais atômicos com send/receive.

Ceph BlueStore vs. FileStore: Arquitetura de OSDs e Performance Real
Entenda a física por trás do armazenamento no Ceph. Compare BlueStore e FileStore, elimine a penalidade de dupla escrita e aprenda a dimensionar WAL/DB em NVMe.
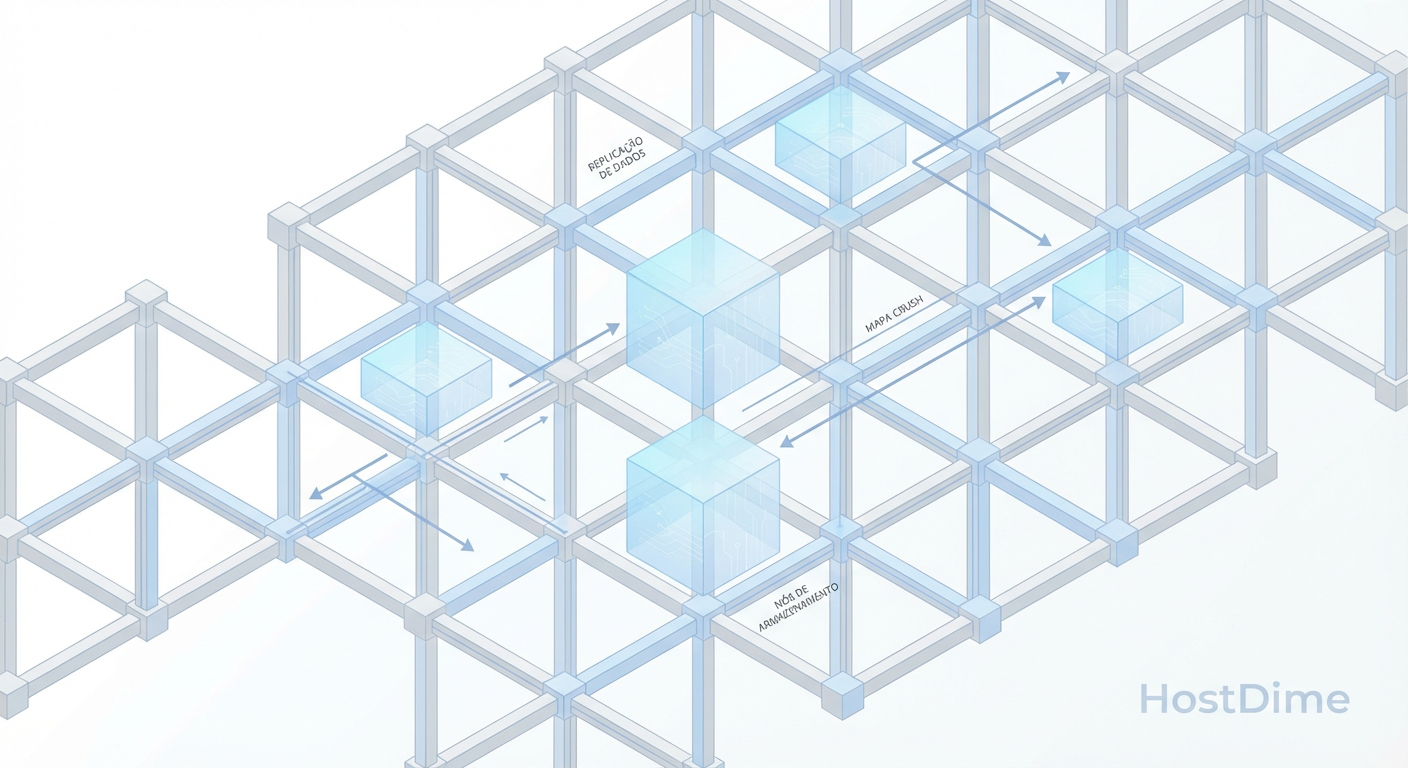
Ceph CRUSH Map e Placement Groups: A Matemática da Performance de Storage
Esqueça o controlador RAID. Aprenda a otimizar a distribuição de dados no Ceph ajustando CRUSH Maps e Placement Groups (PGs) para latência baixa e recuperação rápida.

NVMe-oF com RoCEv2: O Guia de Sobrevivência para Baixa Latência em 100GbE
Domine o NVMe over Fabrics (RoCEv2). Entenda os perigos do PFC, como configurar ECN em redes 100GbE e as métricas reais para garantir latência de flash local via Ethernet.

NVMe-oF TCP vs RoCE: Análise Pragmática de Performance e Deploy em 2025
Pare de configurar PFC cegamente. Analisamos os trade-offs reais entre NVMe/TCP e RoCEv2: latência, overhead de CPU e a complexidade de redes 'lossless' em 2025.

iSER vs. NVMe-oF: Quando o iSCSI RDMA ainda vence (e quando migrar)
Análise forense de storage: compare a latência, overhead e trade-offs reais entre iSER (iSCSI over RDMA) e NVMe-oF. Saiba quando manter a infraestrutura atual ou investir na migração.
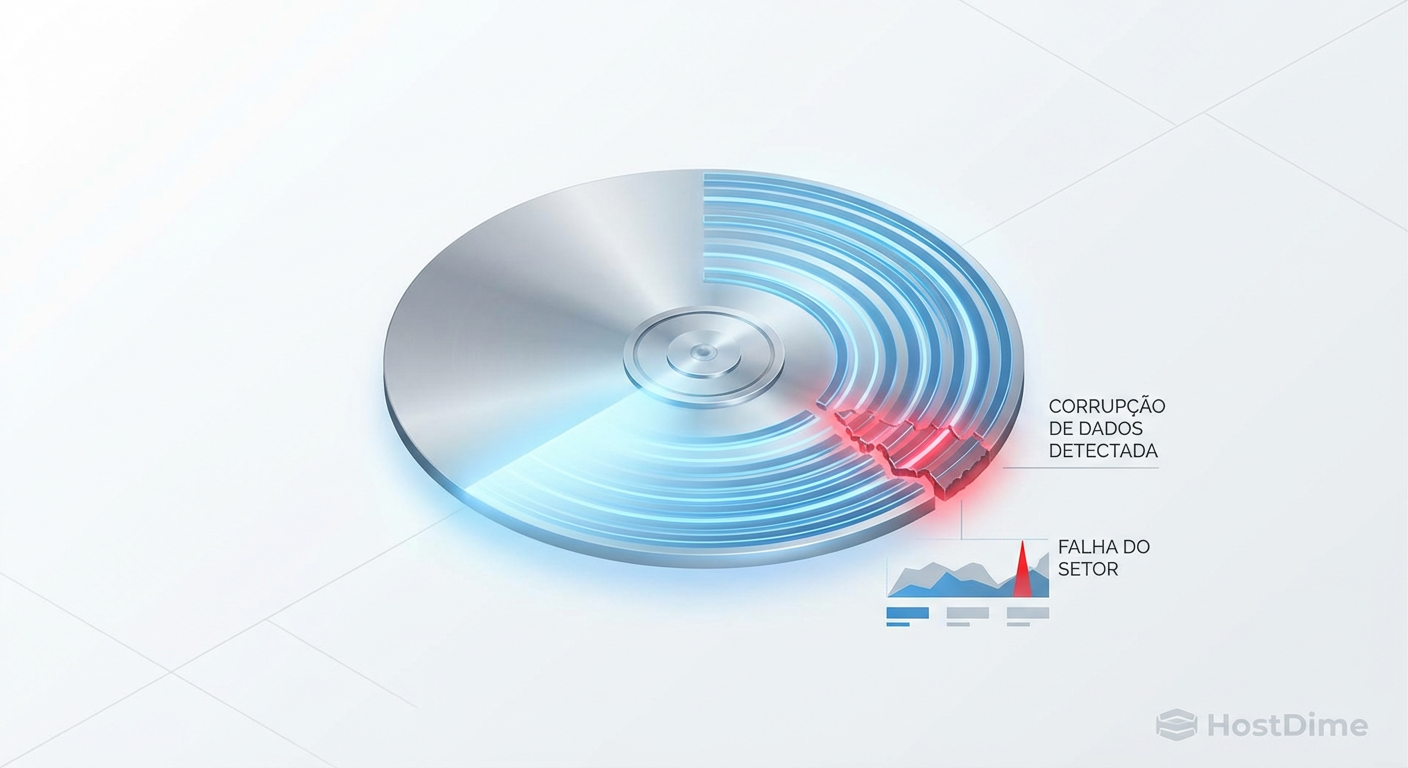
RAID 5 Write Hole: Por que seus dados correm perigo (e como corrigir)
Entenda o 'Write Hole' no RAID 5: a falha de atomicidade que corrompe dados silenciosamente. Análise técnica de soluções via BBU, Journaling e ZFS.
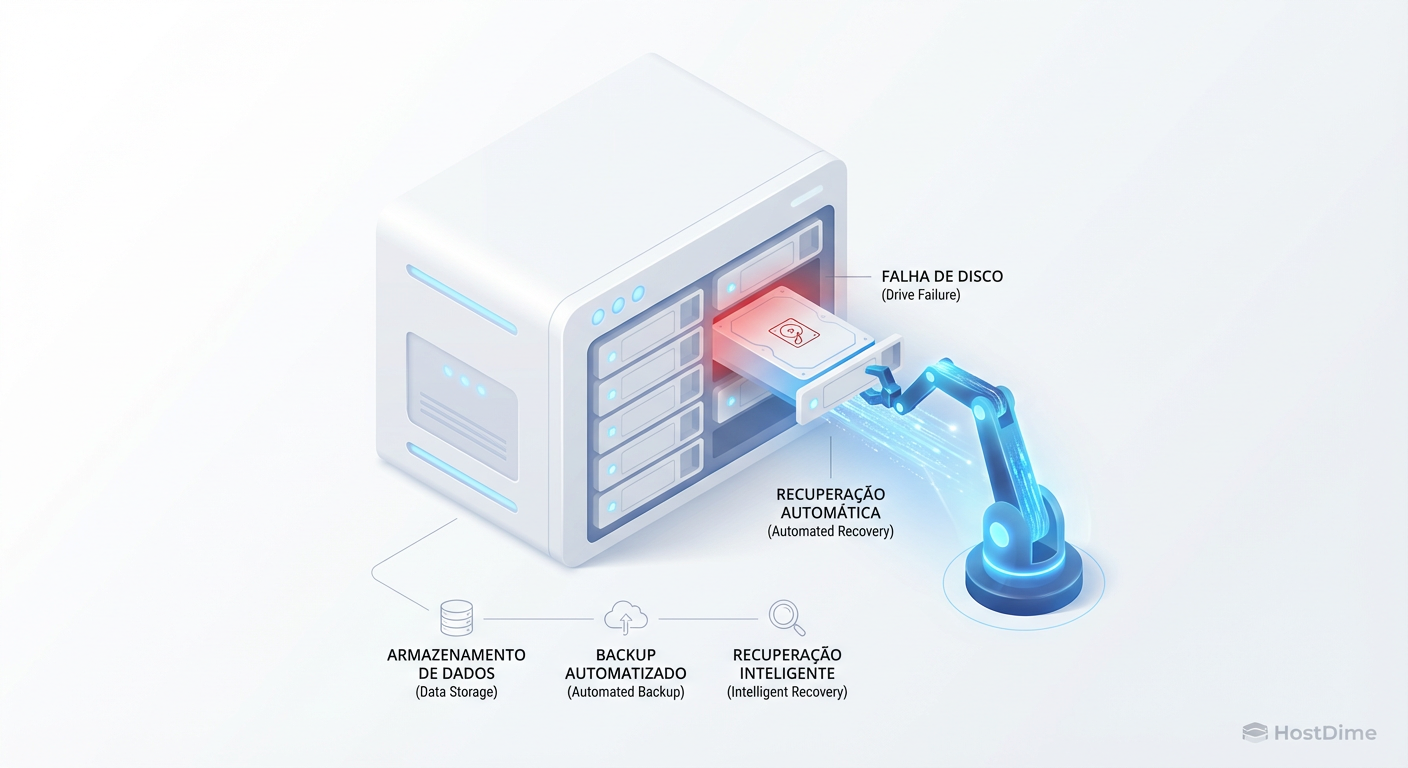
Hot Spares Globais vs. Dedicados: Otimizando a Recuperação em Storage Corporativo
Não desperdice discos. Entenda a matemática entre Hot Spares Globais e Dedicados, o impacto no MTTR e por que o Spare Distribuído (dRAID) é o futuro da recuperação.

RAID 50 e RAID 60: Arquitetura, Performance e a Matemática do Risco
Entenda quando o RAID aninhado (Nested) salva seu storage. Análise técnica de RAID 50 vs 60: penalidade de escrita, domínios de falha e trade-offs reais de capacidade.

RAID Stripe Size: Otimizando para Workloads Sequenciais e Randômicos
Descubra como o Stripe Size define a performance do seu storage. Uma análise técnica sobre alinhamento, penalidade de Read-Modify-Write e o trade-off entre IOPS e Throughput.

Monitoramento de Discos em RAID: Indo Além do Status SMART e Prevendo Falhas Reais
Não confie apenas no LED verde. Aprenda a monitorar atributos SMART críticos através de controladoras RAID, interpretar valores RAW e antecipar falhas de disco antes da perda de dados.

Recuperação de Dados em RAID Degradado: Estratégia Forense com ddrescue e TestDisk
Pare o rebuild agora. Aprenda a metodologia segura para clonar discos falhos com ddrescue e reconstruir arrays RAID logicamente antes de perder seus dados definitivamente.

RAID na Virtualização: Passthrough de Controladora vs Software RAID no Hypervisor
Decida a arquitetura de storage correta para seus VMs. Análise profunda de latência, integridade de dados (ZFS) e trade-offs entre IOMMU Passthrough e RAID gerenciado pelo Host.

RAID 5: O Equilíbrio entre Desempenho e Custo Ainda Vale a Pena?
Descubra se o RAID 5 ainda vale a pena. Análise técnica de paridade, performance e riscos de reconstrução para Sysadmins veteranos.

SSD Enterprise vs Consumidor: Por Que o PLP Salva Seus Dados
Entenda a diferença crítica entre SSDs Enterprise e Consumidor. Saiba como o Power Loss Protection (PLP) previne corrupção de dados em falhas de energia.

ZFS ARC: O Mito da RAM Devorada e a Arte do Tuning Real
Seu servidor está sem RAM ou o ZFS está apenas fazendo o trabalho dele? Entenda o ARC, analise hit rates e saiba quando (e como) limitar a memória.

Erasure Coding vs. RAID 6: A Matemática da Sobrevivência em Escala
RAID 6 não escala infinitamente. Entenda a matemática do Erasure Coding, o custo real em CPU/Latência e por que discos de 20TB mudaram as regras do jogo.
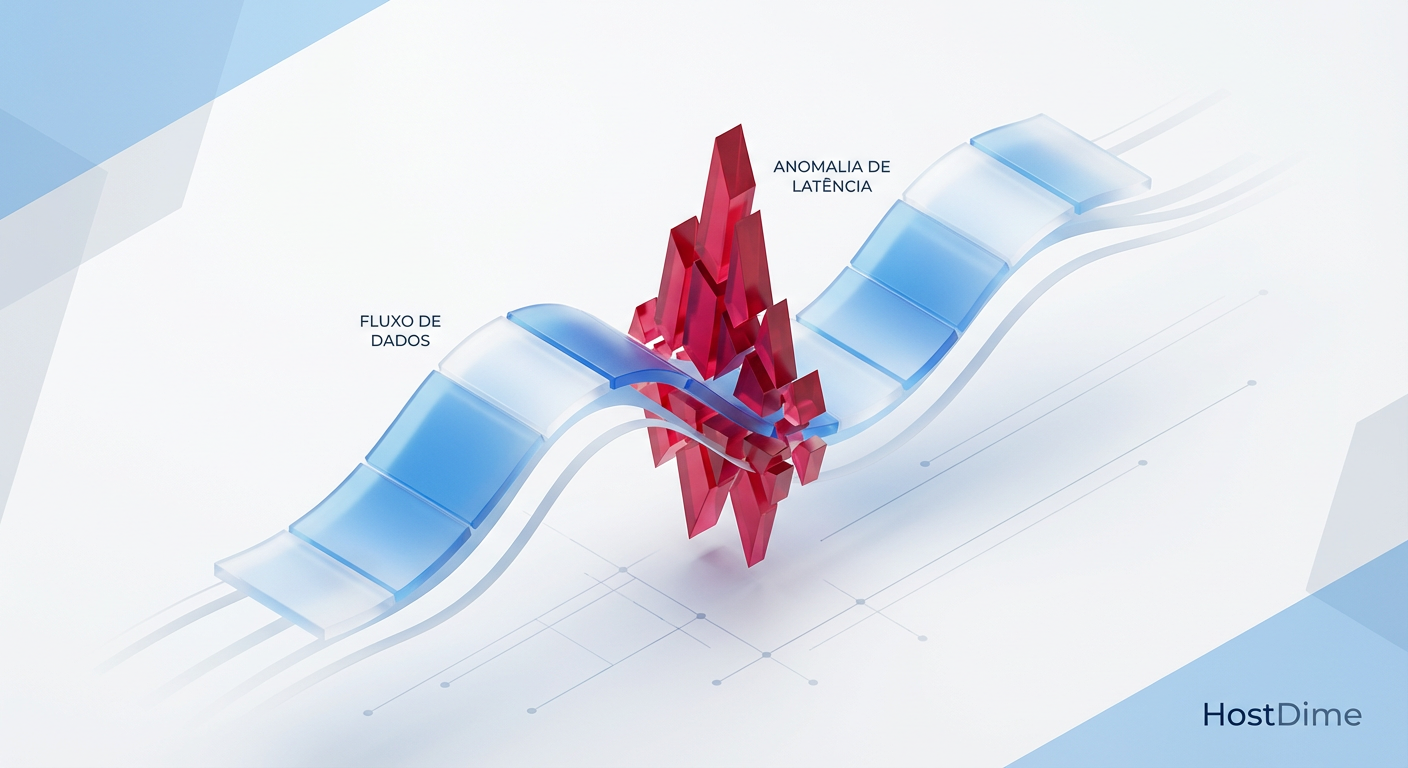
A Tirania da Média: Por que seu Storage parece rápido mas trava a produção (e como o p99 resolve)
Pare de monitorar médias. Descubra como a latência de cauda (p99/p99.9) destrói a performance e aprenda a usar histogramas e heatmaps para ver a verdade.
ZFS no Proxmox: O Duelo recordsize vs volblocksize (O Fim do Write Amplification)
Pare de matar seus SSDs. Entenda a matemática entre o bloco do ZFS e a sua VM, elimine o Read-Modify-Write e otimize databases no Proxmox.

ZFS ARC: O Fim da Regra '1GB por TB' e a Ciência do Cache Real
Esqueça os mitos de dimensionamento do ZFS. Aprenda a analisar o Working Set, interpretar o arcstat e ajustar a memória baseada em evidências, não em regras de 2010.
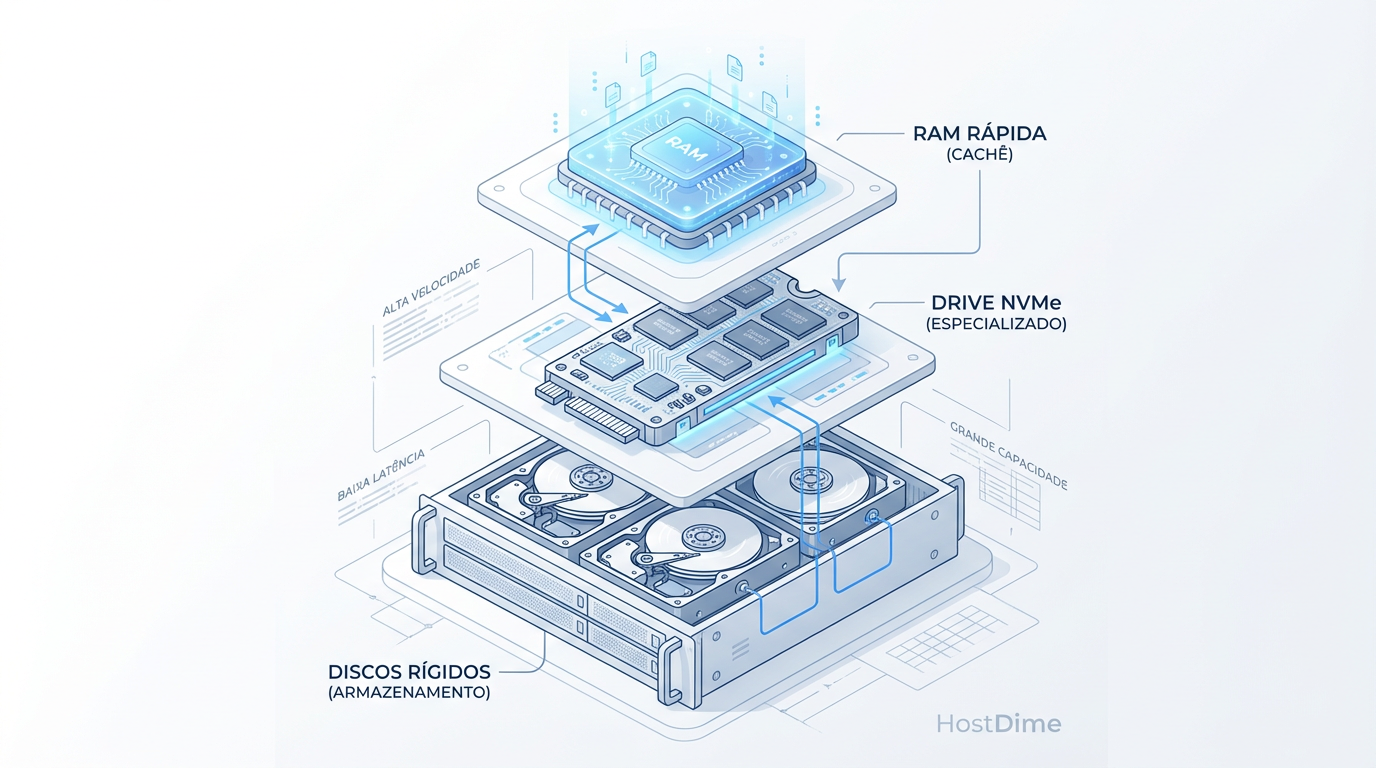
ZFS L2ARC: O Turbo que Pode Frear seu Storage (E Como Saber a Diferença)
L2ARC não é mágica. Entenda o 'Imposto de RAM', analise métricas reais com arcstat e descubra se o cache SSD vai acelerar ou matar a performance do seu ZFS.
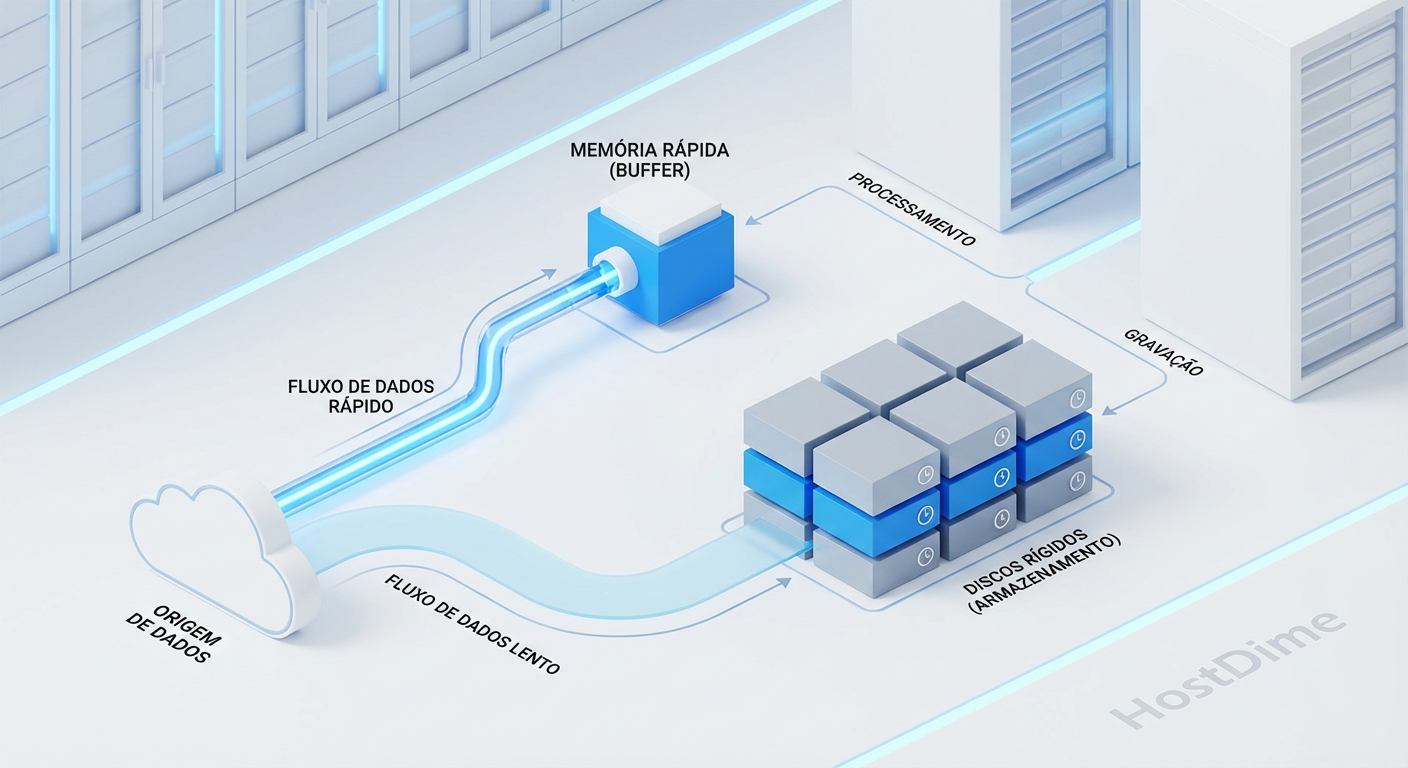
SLOG e Sync Writes: O acelerador que você provavelmente não precisa (ou está usando errado)
Pare de tratar SLOG como 'cache de escrita'. Entenda o ciclo de vida do ZFS, diagnostique gargalos de latência e escolha o hardware certo (PLP) sem queimar dinheiro.
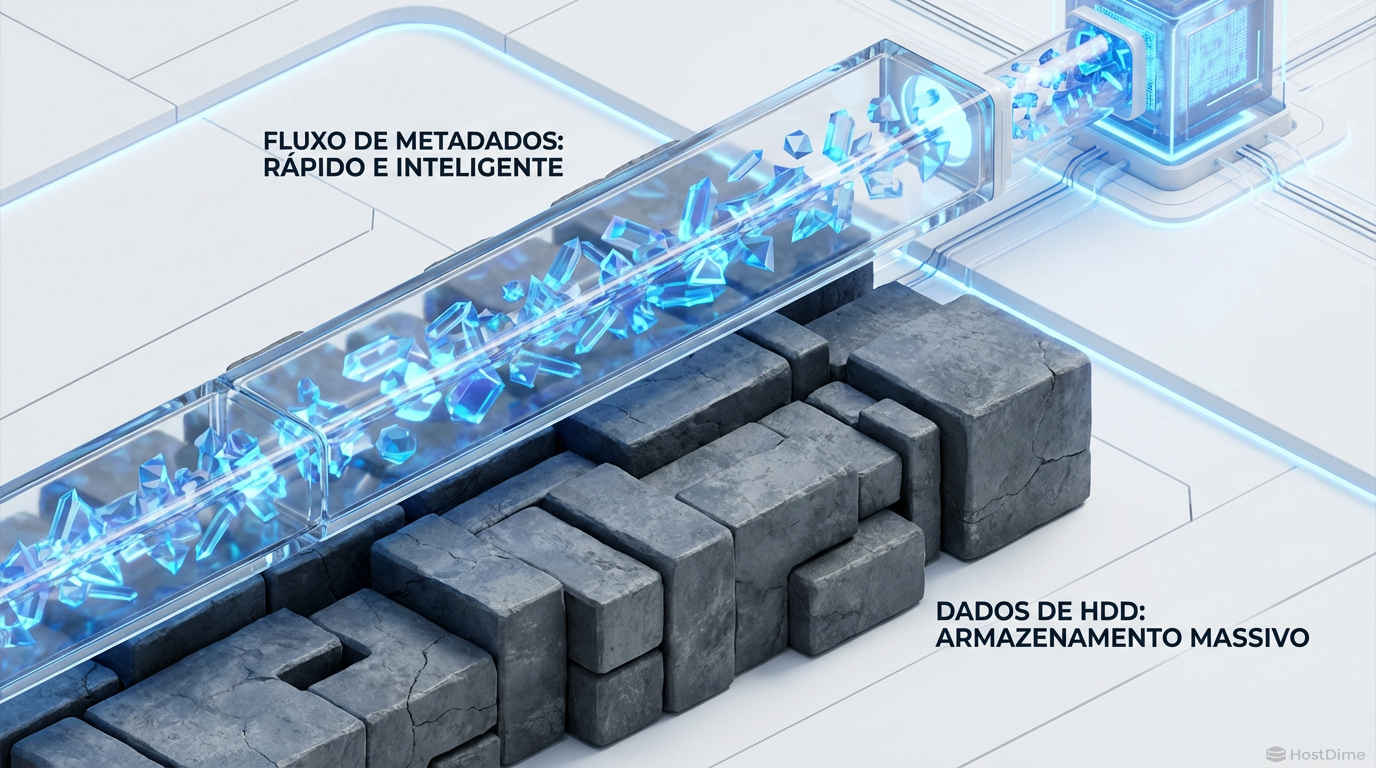
ZFS Special VDEVs: O Fim do Gargalo de IOPS (Sem Perder Dados)
Acelere pools de HDD movendo metadados para Flash. Entenda a arquitetura do ZFS Special VDEV, os riscos críticos de redundância e o tuning do special_small_blocks.
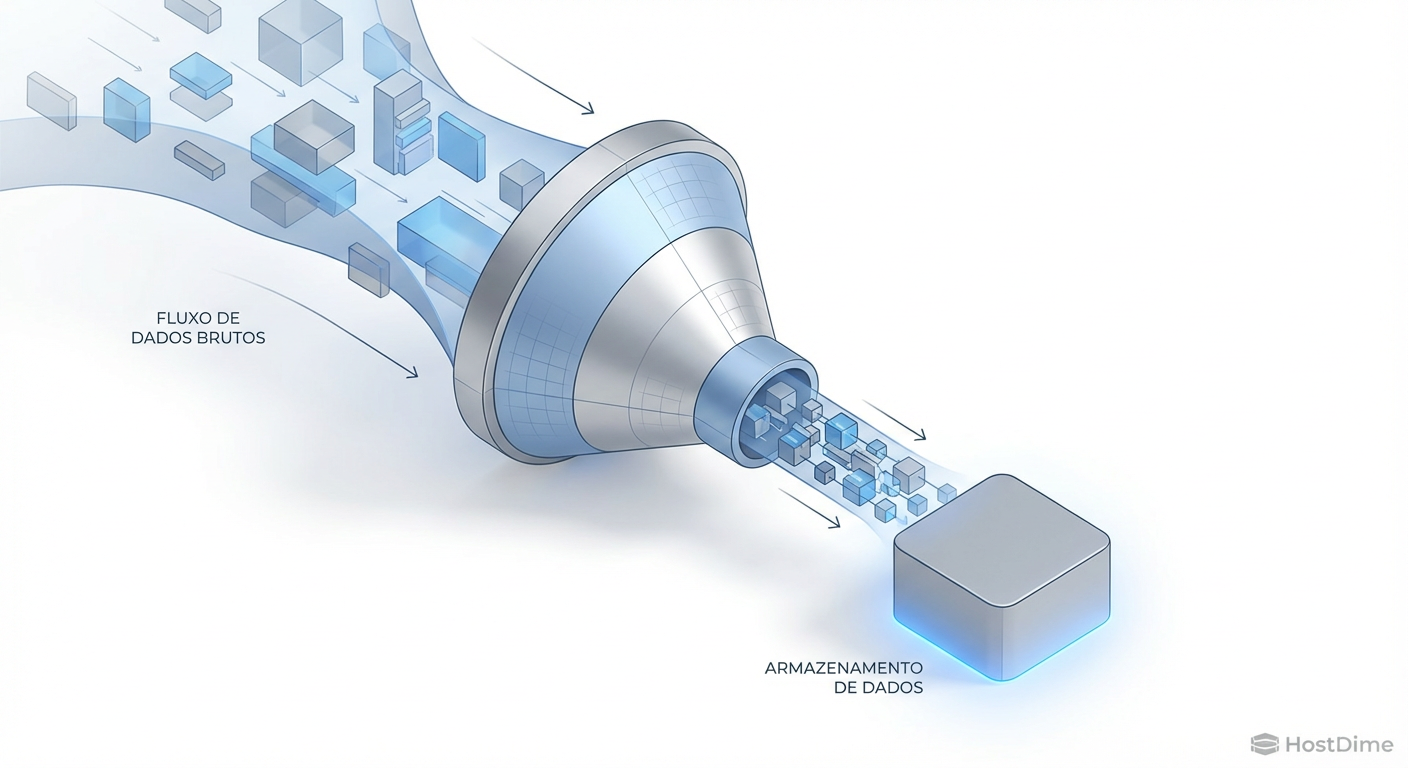
Compressão no ZFS: A mecânica da 'Performance Grátis' (e quando a conta chega)
LZ4 é realmente mágico? Analisamos o trade-off entre ciclos de CPU e latência de disco, a revolução do ZSTD e o impacto oculto no ARC.

ZFS Dedup: A Armadilha da Economia de Espaço (Análise Técnica)
Antes de rodar 'zfs set dedup=on', leia isto. Entenda a Tabela de Deduplicação (DDT), o custo brutal de RAM e por que compressão ZSTD é quase sempre a melhor escolha.

Scrub vs. Resilver: O Preço Oculto da Integridade de Dados
Integridade não é mágica, é I/O. Entenda a diferença mecânica entre Scrub e Resilver, o impacto na latência e como tunar o ZFS para não derrubar a produção.
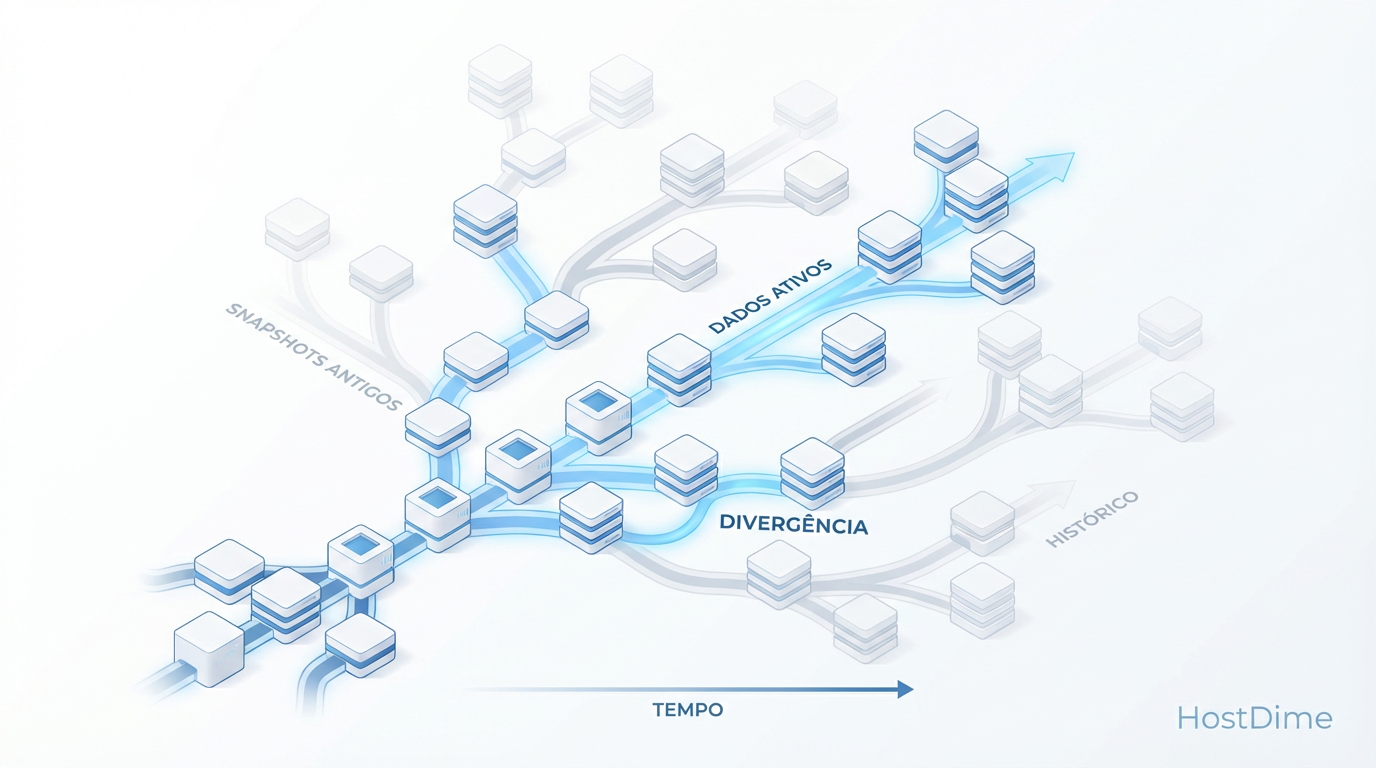
ZFS Snapshots: O Poder do 'Undo' e a Armadilha da Fragmentação
Snapshots são instantâneos, mas não são grátis. Entenda a física do Copy-on-Write, o pesadelo do espaço retido e como evitar que seu pool sufoque.

ZFS Send/Receive: A Anatomia da Migração (Quase) Instantânea
Esqueça o rsync. Entenda como o ZFS serializa blocos para migrações de petabytes com janela de manutenção de segundos. O guia de engenharia para replicação.
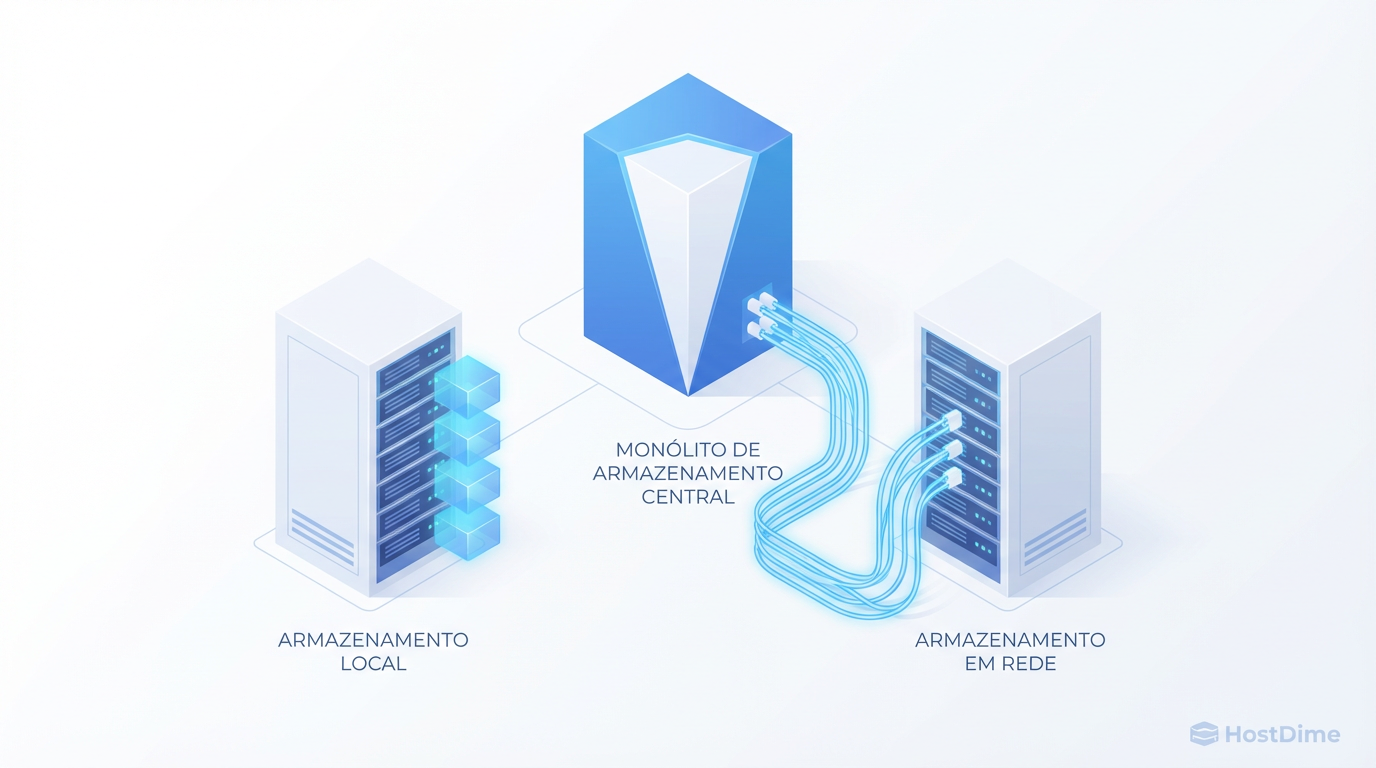
Proxmox: Storage Local vs. Compartilhado — A Batalha entre Latência e Mobilidade
Pare de seguir dogmas. Analisamos o 'imposto de rede' do storage compartilhado contra a performance bruta do disco local (ZFS) para decidir sua arquitetura.
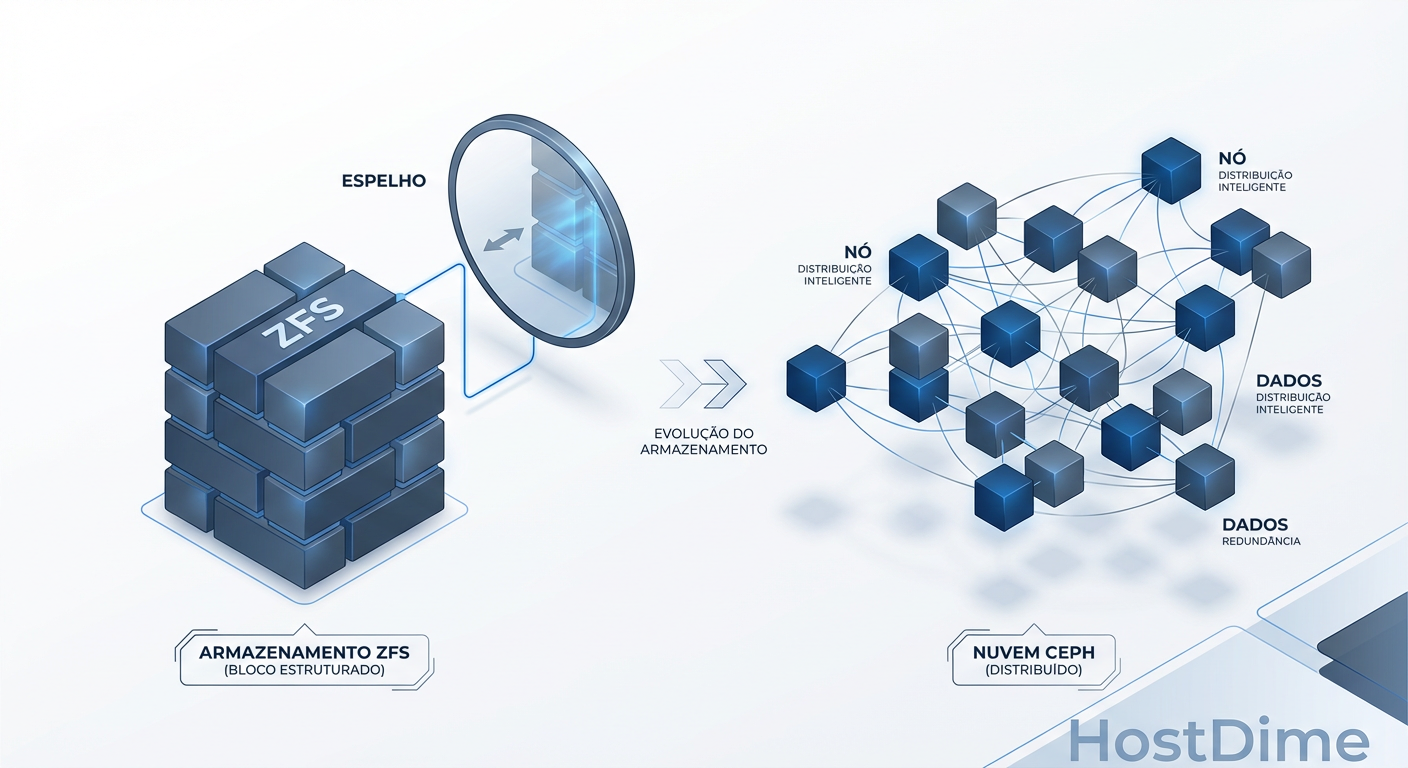
Proxmox: Ceph vs. ZFS Replication — Escolhendo sem Fanatismo
ZFS é rápido mas assíncrono. Ceph é robusto mas exige hardware. Uma análise profunda sobre latência, consistência e custos para decidir seu storage HA.

Proxmox: Matando o Mito 'Disco Local vs. Storage' (Guia de Arquitetura)
Pare de adivinhar. Entenda os trade-offs reais de latência e confiabilidade entre ZFS Local, NFS/iSCSI e Ceph no Proxmox. Sem hype, apenas engenharia.

Proxmox Disk Cache: A Verdade sobre Writeback, None e a Integridade dos Dados
Pare de chutar configurações. Entenda o fluxo de I/O no KVM, o impacto do ZFS ARC vs Host Page Cache e quando o Writeback destrói seus dados.
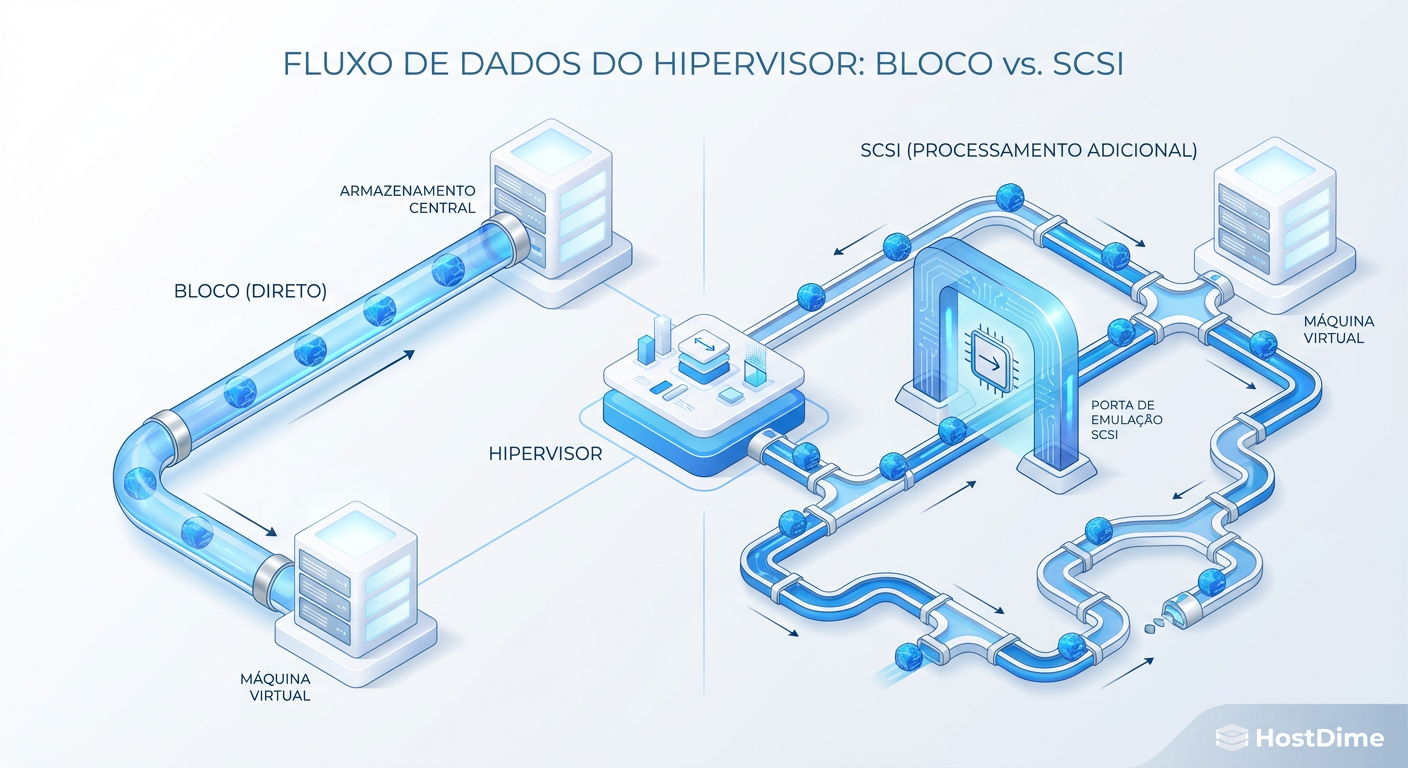
VirtIO-blk vs. VirtIO-SCSI: Anatomia da Latência e o Mito da Performance
Pare de chutar configurações no KVM. Entenda a arquitetura de ring buffers, o impacto real do overhead SCSI e quando o VirtIO-blk ainda vence.
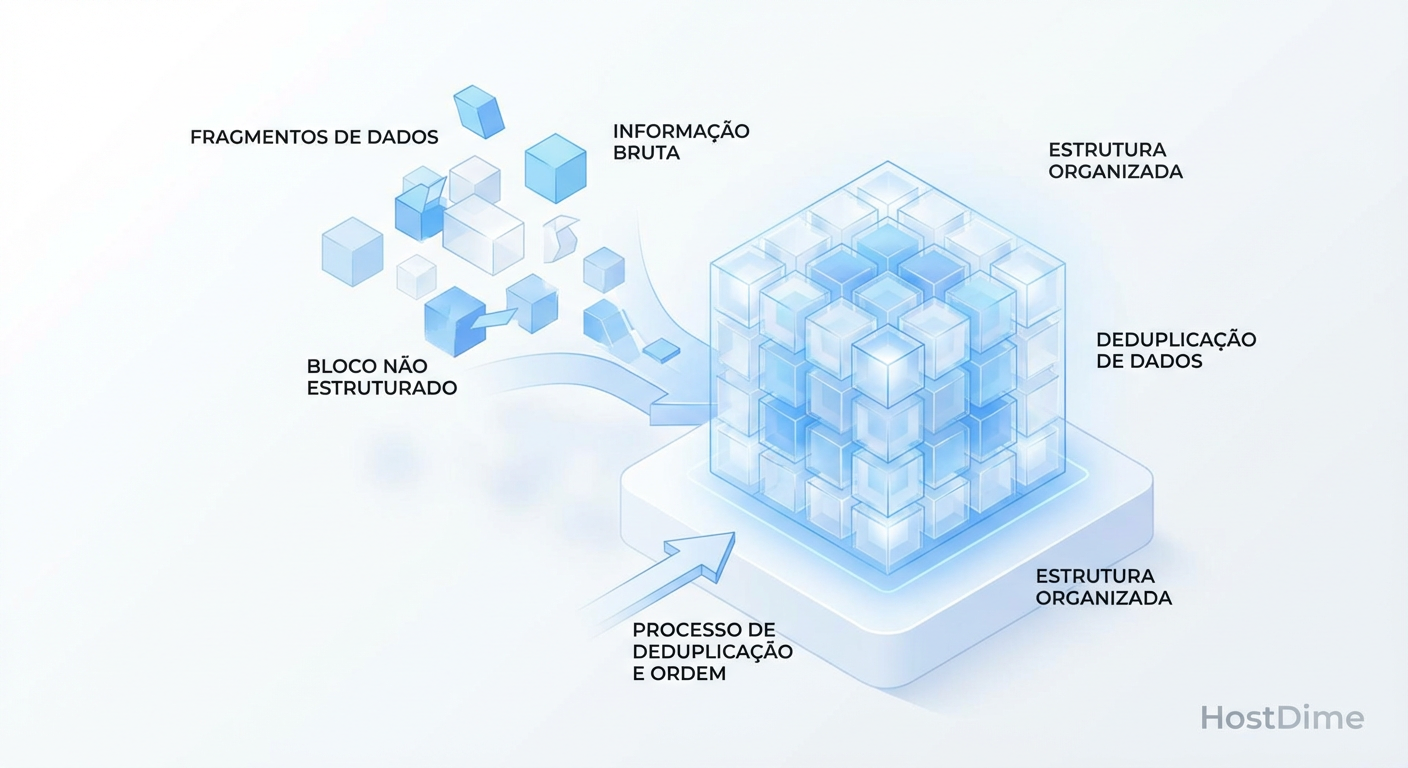
Proxmox Backup Server: Ocultando a Latência e Domando o I/O
Esqueça a largura de banda. No PBS, IOPS é rei. Aprenda a tunar ZFS, entender o Garbage Collection e dimensionar datastores sem gargalos.
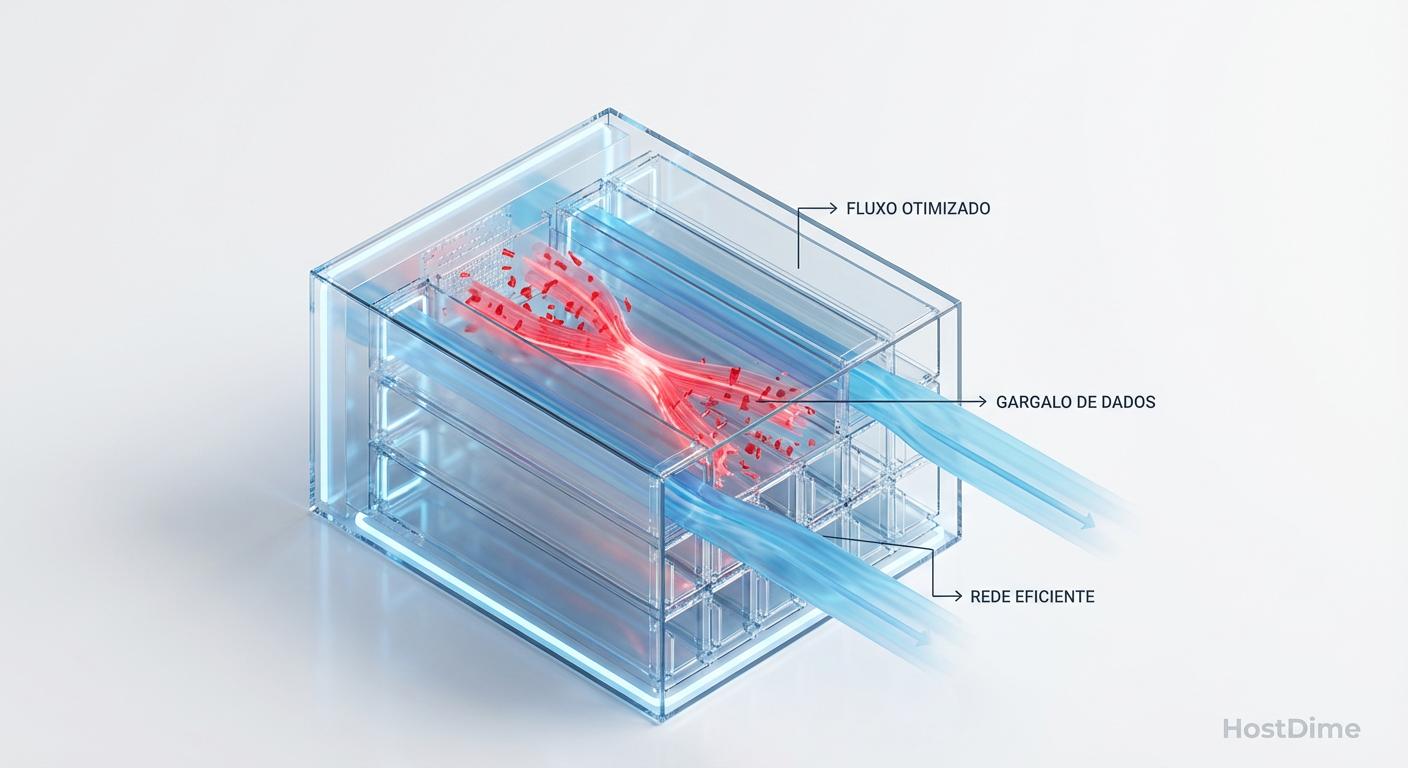
Windows VM Travando no Proxmox? A Anatomia do Gargalo de IO
Seu Windows congela durante backups ou updates? Entenda a interação entre VirtIO, iothreads e Cache no QEMU/KVM e elimine a latência.
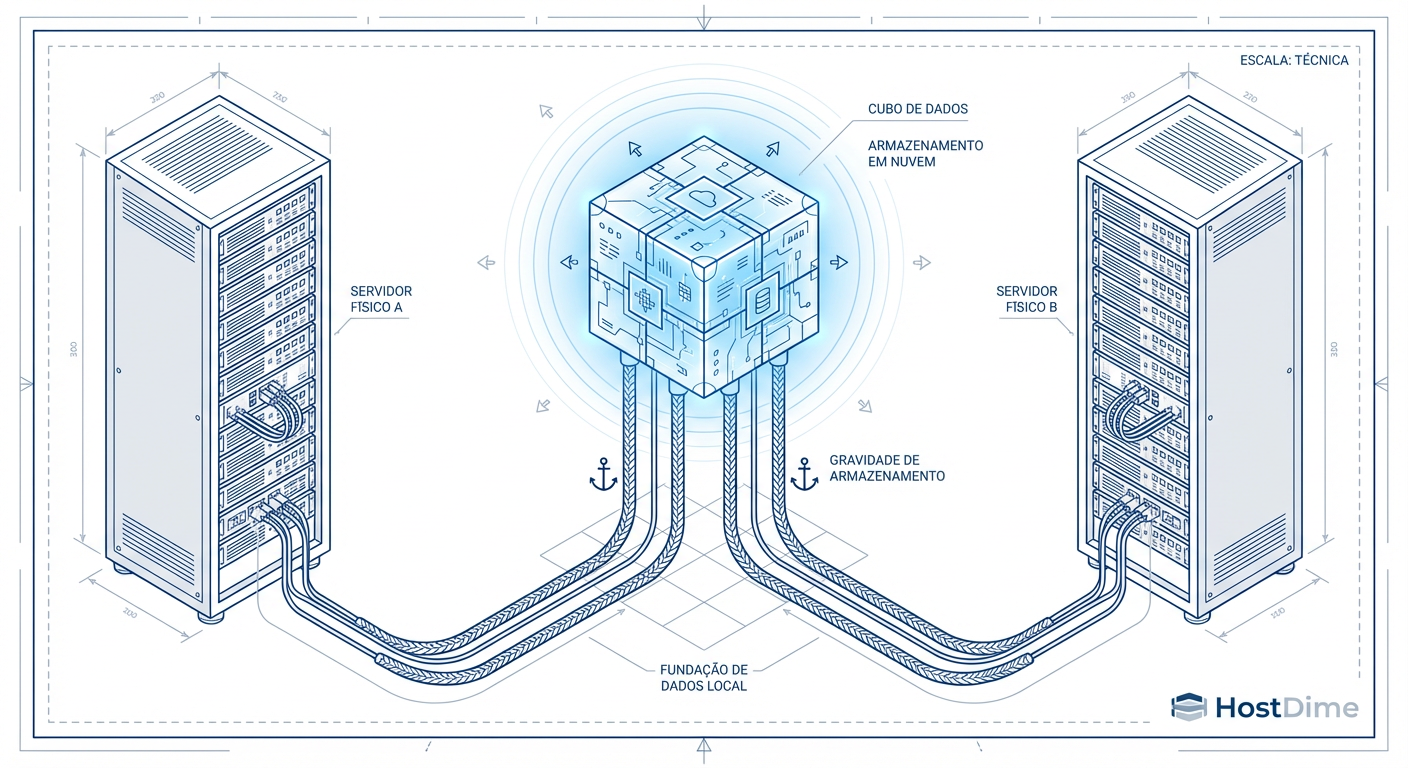
Live Migration: O Storage é o "Ponto Único de Verdade" (e de Falha)
Live migration parece mágica, mas é física pura. Entenda como latência de disco, locking e coerência de cache decidem se sua VM migra ou corrompe.
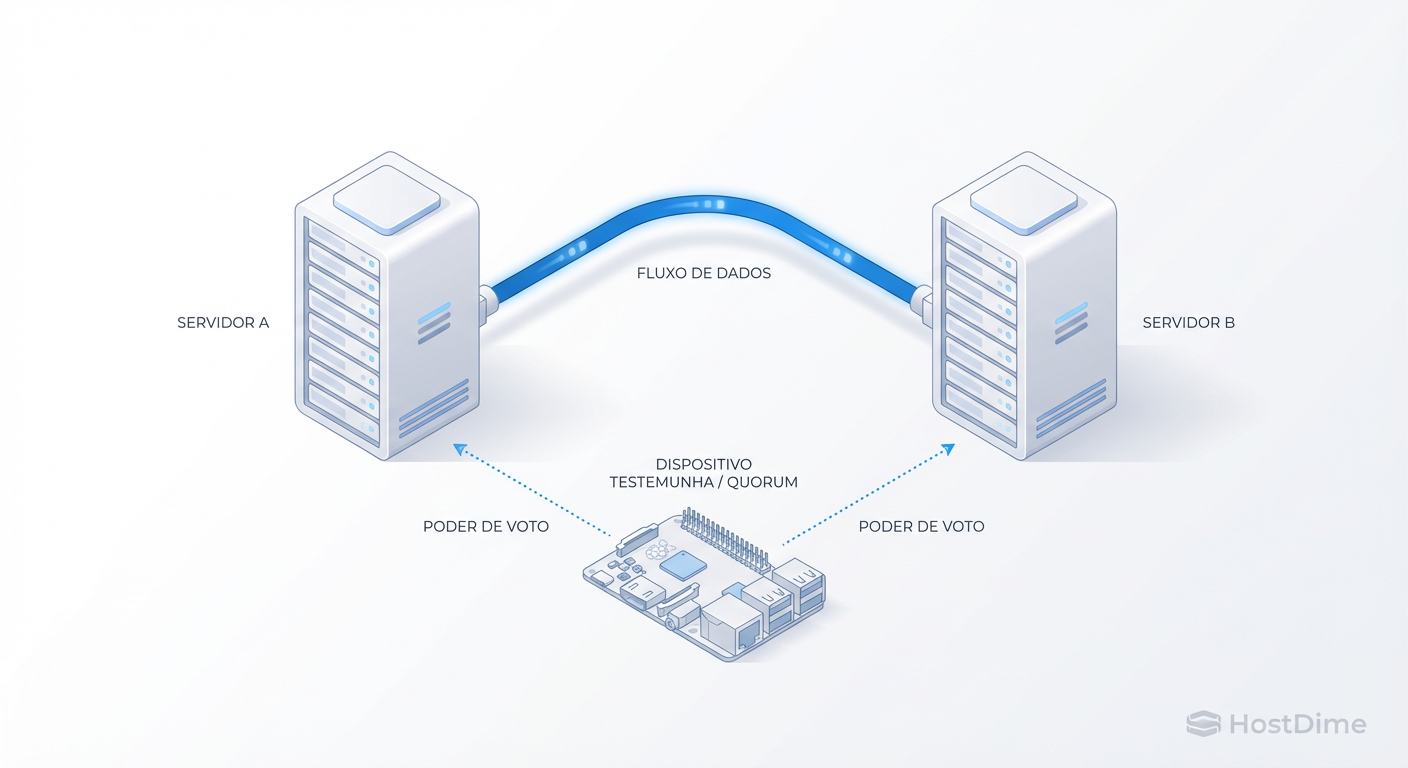
Proxmox HA sem Ceph: A Realidade da Replicação ZFS e o Mito dos 2 Nós
Cluster Proxmox de 2 nós funciona? Domine a arquitetura de HA com ZFS Replication e QDevice. Entenda os riscos de RPO, evite split-brain e economize hardware.

Benchmark de Storage no Proxmox: O Guia Anti-Ilusão
Pare de se enganar com números inflados pelo cache. Aprenda a usar o fio, entender o I/O path do KVM/ZFS e medir a performance real do seu storage.
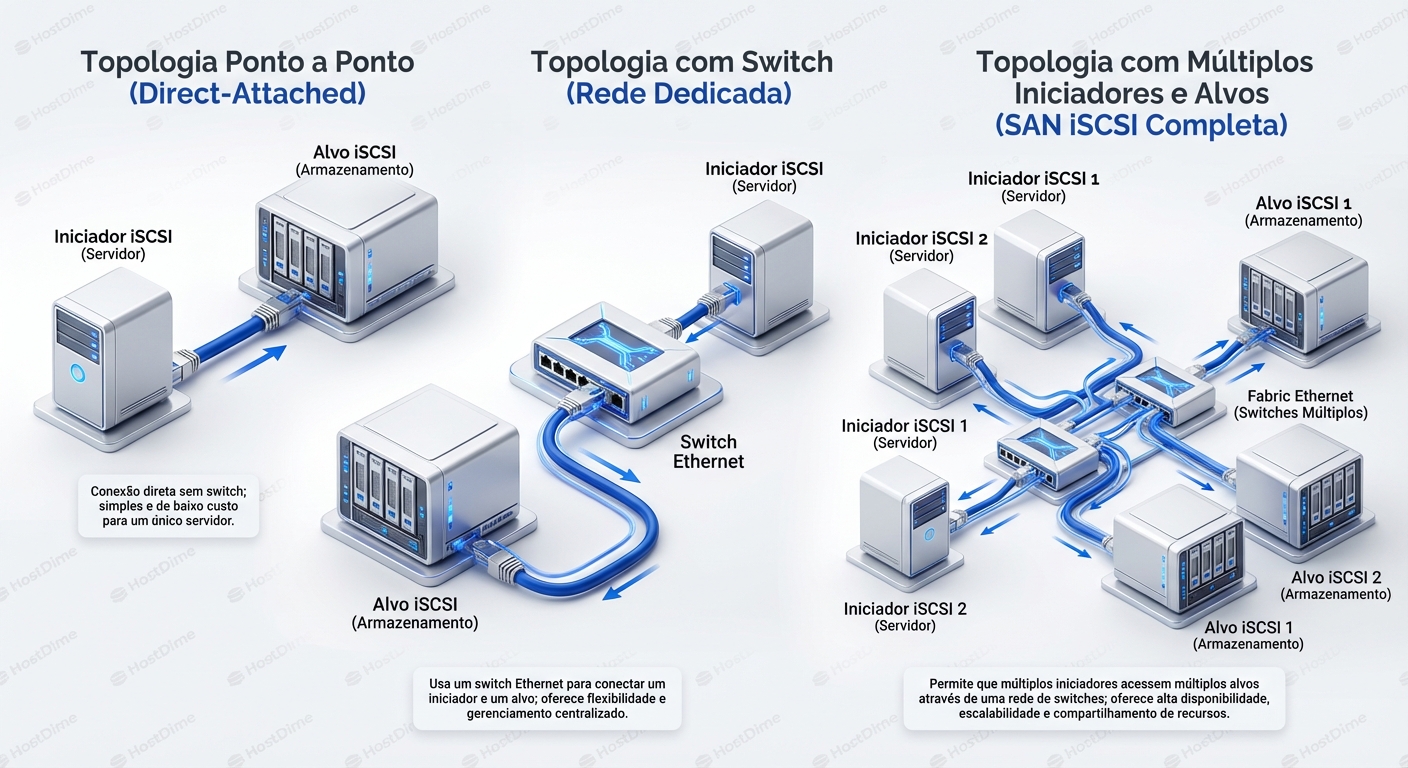
iSCSI Conceitos Topologia E Boas Praticas
iSCSI Desmistificado: Arquitetura, Topologias e Melhores Práticas...

Spanning Tree E Storage Armadilhas Em L2
Para entender o problema, precisamos alinhar nosso modelo mental sobre como um switch funciona versus como o Spanning Tree *pensa* que ele deve funcionar....

Read Cache Vs Write Cache
Imagine um servidor de banco de dados sem cache. Cada consulta, por mais simples que seja, exigiria uma busca no disco, esperando milissegundos preciosos. Em um...

Qos Para Storage Quando Aplicar E Como Medir Ganhos
São 03:00 da manhã. O pager toca. O alerta é crítico: latência da API de checkout disparou para 4 segundos. Você abre o dashboard do banco de dados e vê o uso d...
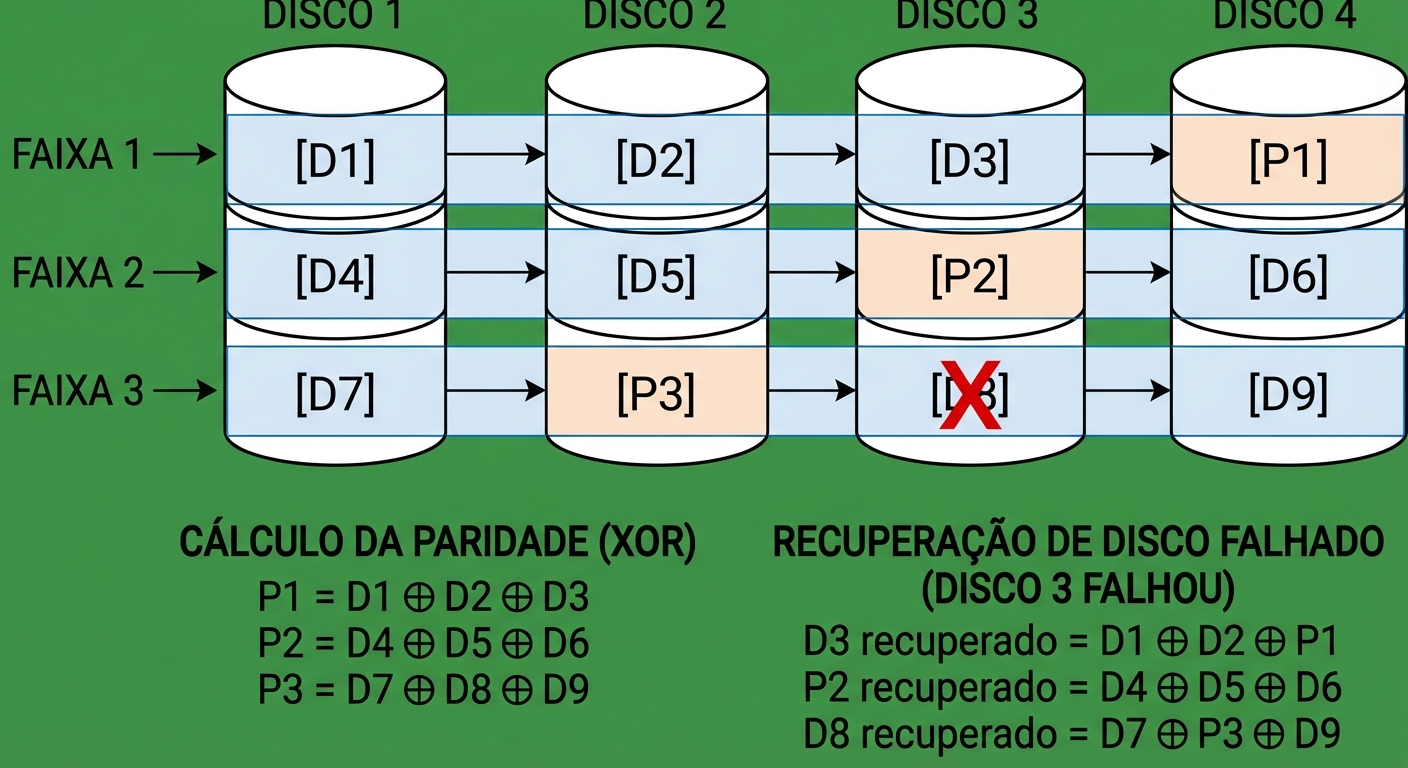
RAID 5: Prós, Contras e Quando Ainda Serve
Olá! Hoje vamos mergulhar no mundo do RAID 5. RAID (Redundant Array of Independent Disks) é uma forma de combinar vários discos rígidos em uma única unidade lóg...

RAID 50 vs RAID 60: Quando Usar e Por Quê
RAID (Redundant Array of Independent Disks) é uma tecnologia para melhorar o desempenho e/ou aumentar a tolerância a falhas do armazenamento de dados. RAID 50 e...

Backup Full Incremental E Diferencial Em Storage
---...
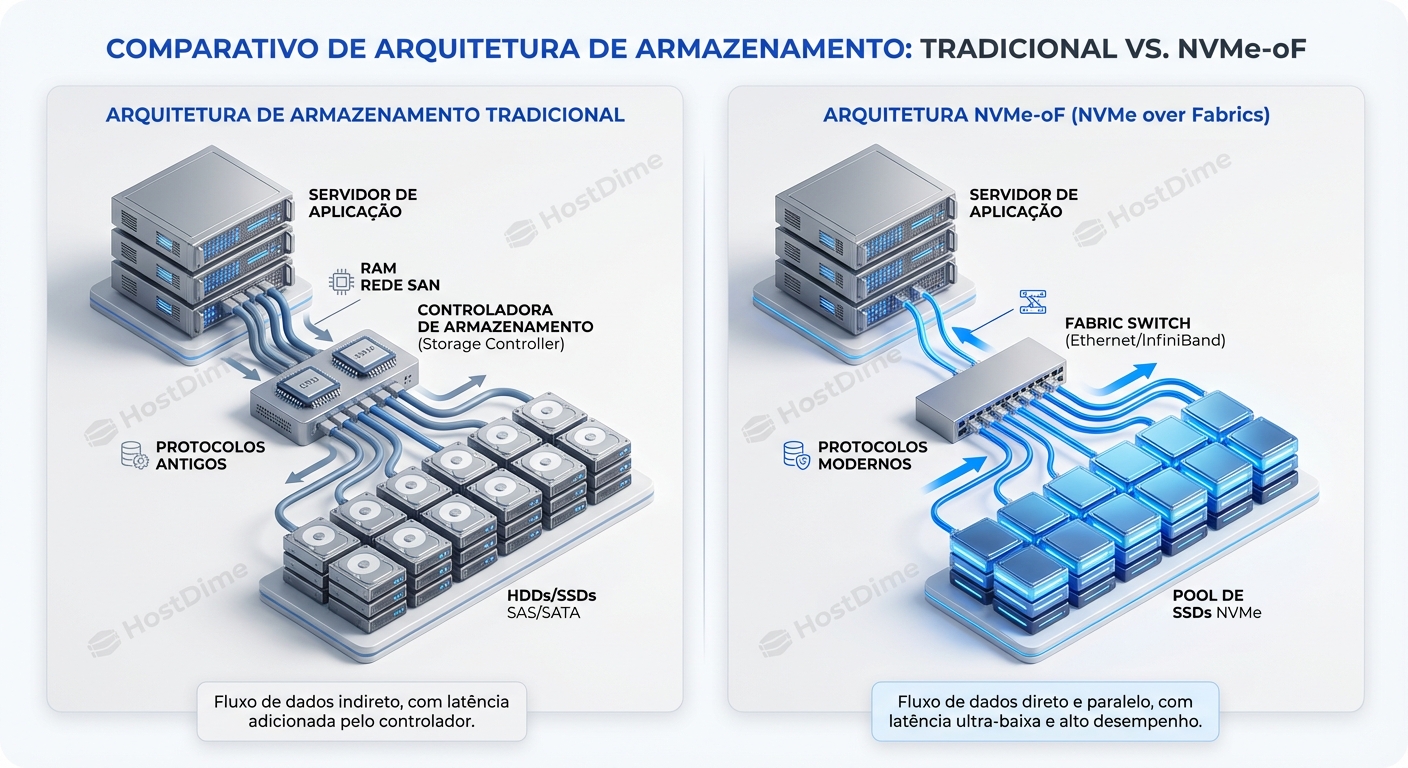
NVMe Of Visao Geral E Casos De Uso
NVMe-oF: Desmistificando o protocolo e seus casos de uso...

Kubernetes E Storage Desvendando O Csi Rworwx E Os Perigos Ocultos
A escolha da solução de storage em Kubernetes é uma das decisões mais cruciais no ciclo de vida de uma aplicação. Não se trata apenas de "onde os dados serão a...
Compressao Impacto Em CPU E Latencia
A compressão de dados é uma faca de dois gumes. Por um lado, reduz o espaço de armazenamento e a largura de banda de transmissão, diminuindo custos e melhorando...

Controladoras Dual Controller Como Evitar Single Point Of Failure
O termo de marketing mais perigoso em armazenamento é "Active-Active". Quando um vendor diz isso, você imagina dois processadores somando forças para dobrar a p...

NVMe Of A Revolucao De Performance No Armazenamento Em Rede
A evolução do hardware de armazenamento expôs uma dívida técnica crítica na infraestrutura de datacenter. Enquanto a mídia de armazenamento transitou de **HDDs ...

Bit Rot E Silent Data Corruption Como Detectar E Corrigir
A corrupção silenciosa de dados ocorre quando informações são alteradas sem que o sistema ou o usuário percebam. Diferente de uma falha de disco completa, onde ...

IOPS, Throughput e Latência: Desvendando o Triângulo Mágico do Storage
"O banco de dados está lento!" Essa frase, ou variações dela, assombram sysadmins, SREs e engenheiros de infraestrutura em todo o mundo. Mas o que *realmente* e...

Overcommit De Storage Como Da Ruim E Como Evitar
Overcommit de storage é uma prática comum, mas perigosa, que pode levar a instabilidades severas em ambientes de produção. A ideia de alocar mais espaço do que ...
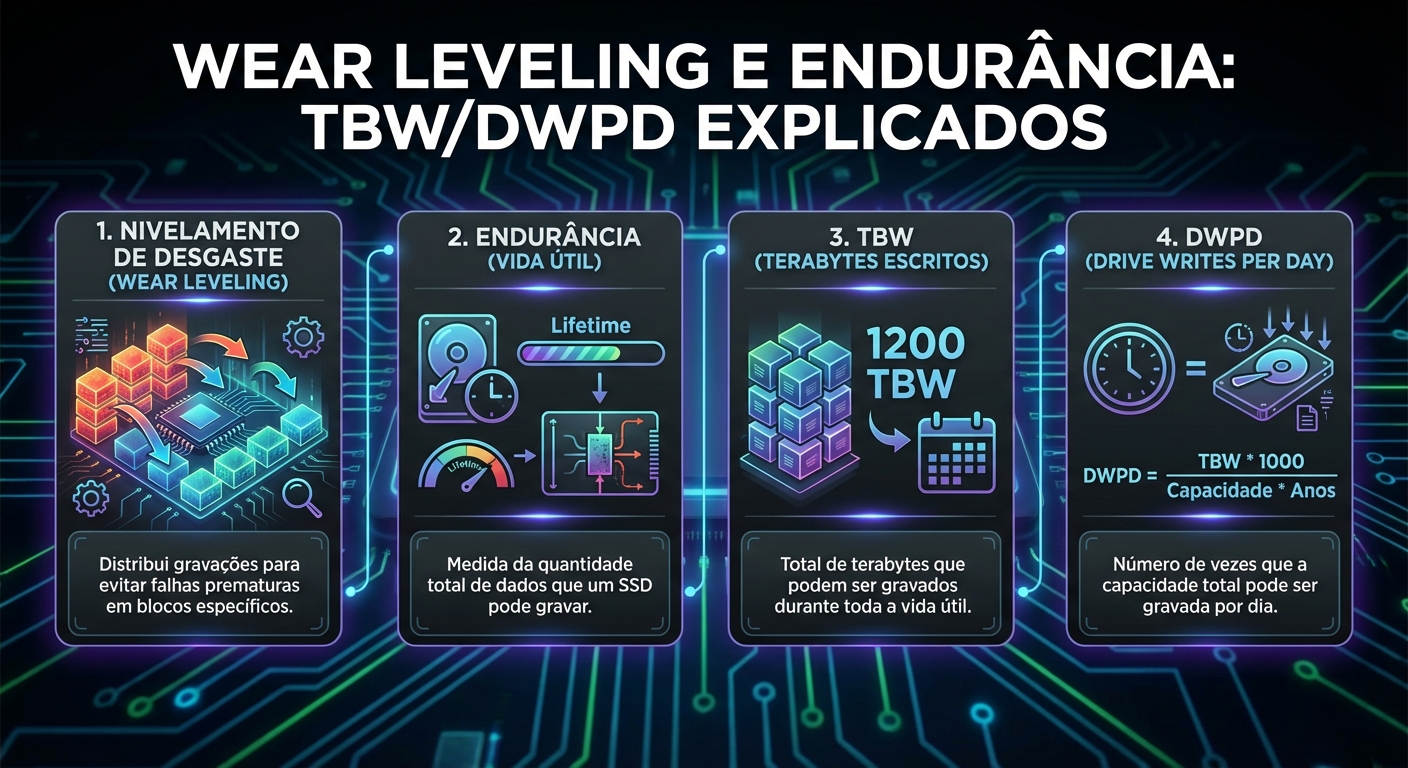
Wear Leveling E Endurance Tbwdwpd Explicados
TBW (Terabytes Written) TBW é uma métrica que indica a quantidade total de dados que podem ser escritos em um SSD durante sua vida útil, sob condições específic...

Redes Para Storage L2 Dedicado Vs Roteado L3
Você já esteve naquela situação às 3 da manhã de um sábado? O cluster de Ceph ou vSAN decide iniciar um *rebalance* massivo após a falha de um disco de 18TB. De...
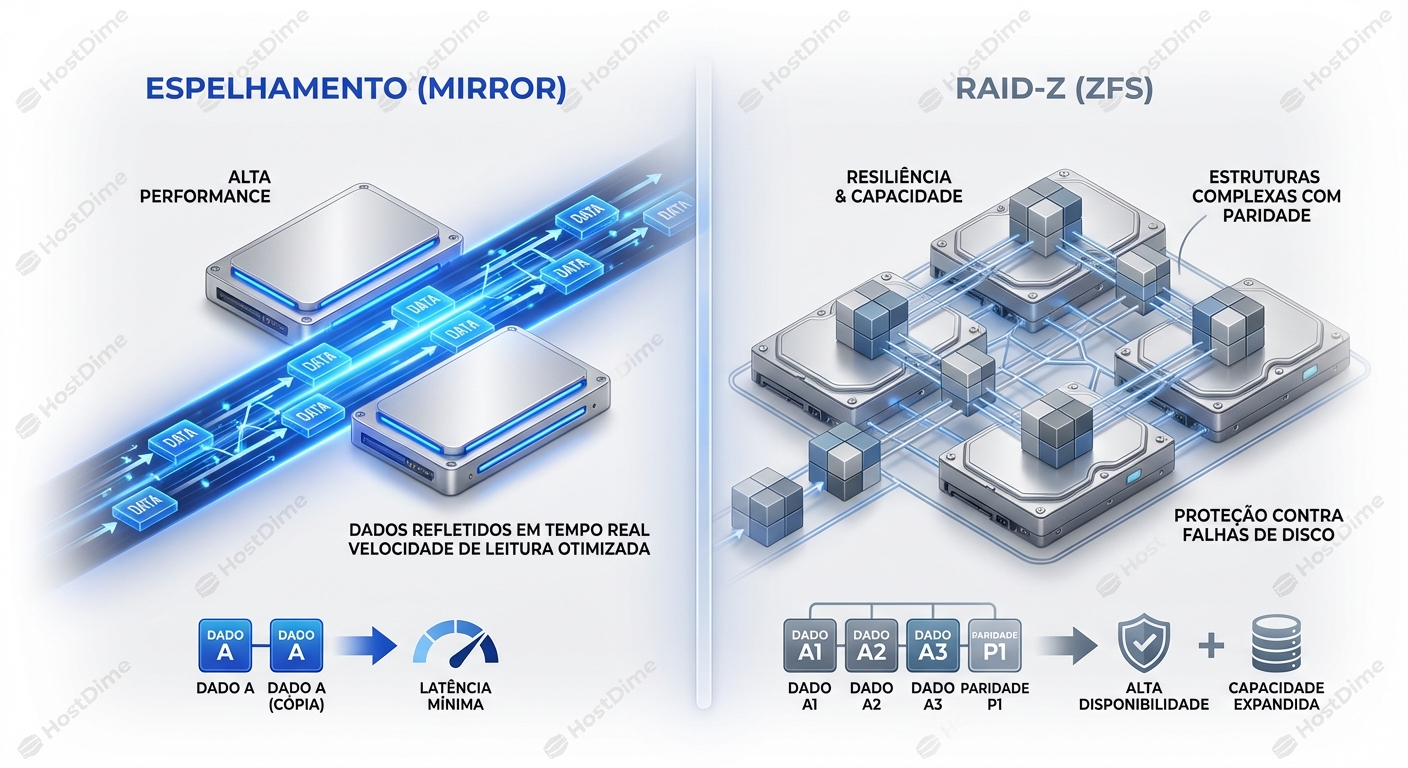
ZFS Mirror Vs Raidz1Raidz2Raidz3 Quando Usar
A escolha entre ZFS Mirror e RAIDZ (RAIDZ1, RAIDZ2, RAIDZ3) é crucial para determinar o desempenho, a capacidade de armazenamento e a tolerância a falhas do seu...

Timeout E Retries Parametros Criticos Em San
Você recebe o alerta às 03:00 da manhã. O banco de dados principal parou de responder. O dashboard de monitoramento está vermelho, mas estranhamente, o servidor...

Ceph Rbd Vs Cephfs Vs Rgw Diferencas E Usos
O Ceph é uma plataforma unificada, mas a performance muda drasticamente dependendo da interface. **RBD** oferece a menor latência e acesso direto aos OSDs (ideal para VMs e DBs). **CephFS** introduz a complexidade do MDS para garantir POSIX (ideal para arquivos compartilhados). **RGW** adiciona o overhead do protocolo HTTP e indexação de buckets (ideal para S3/Backups). A escolha errada da interface pode destruir a performance do seu cluster, independentemente da velocidade dos discos. --- Muitos administradores tratam o Ceph como uma "caixa preta mágica" onde você joga dados e eles ficam seguros. Embora a parte da segurança dos dados (durabilidade) seja verdadeira, a performance é uma história completamente diferente. A maior confusão que vejo em campo é a escolha da interface errada para o workload errado. Não, você não deve montar um bucket S3 via FUSE para rodar um banco de dados. E não, você não deve usar CephFS se precisa apenas de um disco virtual para uma VM. Para entender isso, precisamos dissecar o **Data Path**: o caminho que o bit percorre desde a aplicação até ser gravado no disco físico. Como discutimos no guia sobre [Block, File e Object Storage](/articles/tipos-de-armazenamento-block-file-object), cada tipo tem sua própria "taxa" de processamento. No Ceph, essa taxa é paga antes de chegar ao layer RADOS. ## A Base de Tudo: RADOS e a Ilusão das Interfaces No fundo, o Ceph não sabe o que é um arquivo, um bloco iSCSI ou um objeto S3. O Ceph só entende **Objetos RADOS**. Toda a mágica acontece no **librados**. RBD, CephFS e RGW são apenas "tradutores" que convertem as chamadas da sua aplicação em operações que o cluster entende. 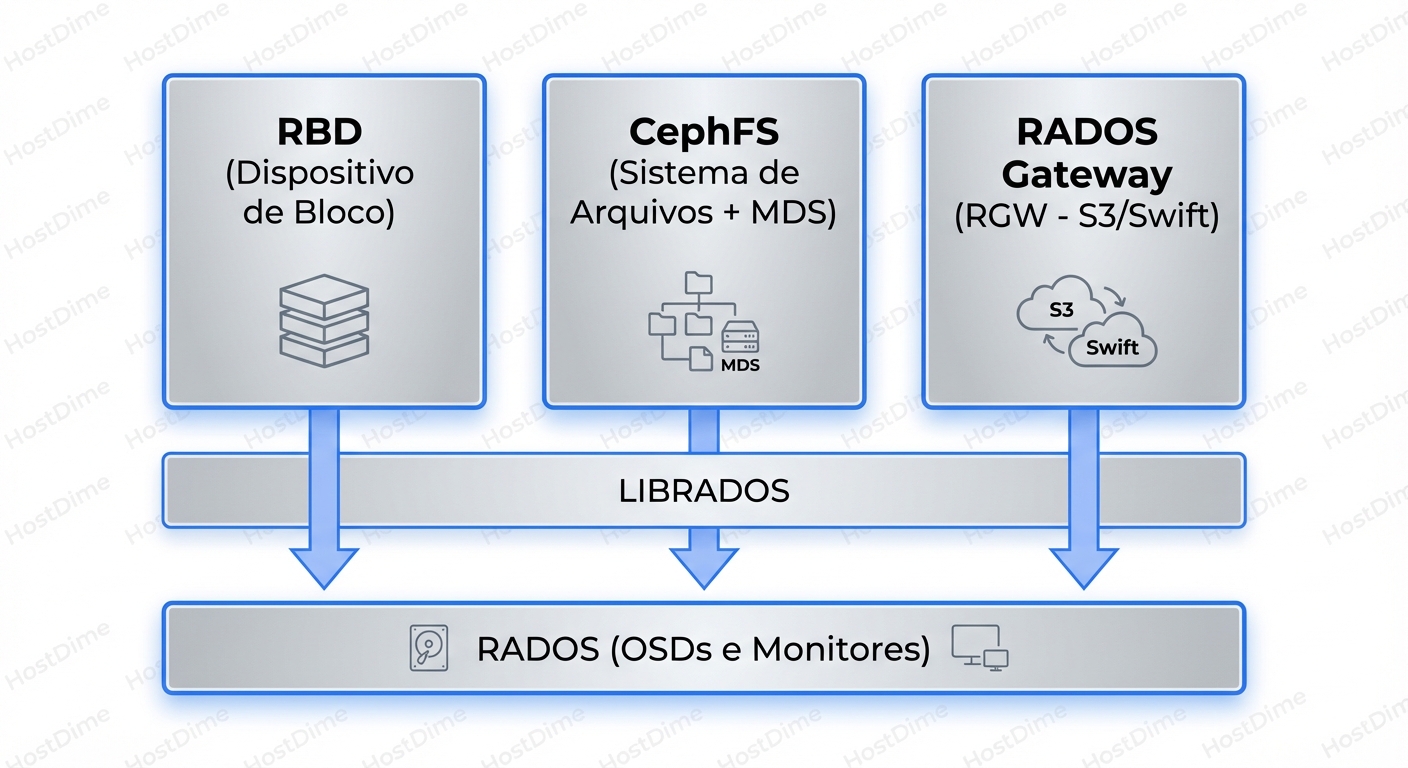 Quando você grava um bloco de 4MB no RBD, ele quebra isso em objetos RADOS. Quando você faz upload de um arquivo no RGW, ele também vira objetos RADOS. A diferença é **como** essa tradução ocorre e quantos "pedágios" (hops de rede e CPU) você paga no caminho. ## 1. RBD (RADOS Block Device): O Caminho Expresso O RBD é, na maioria dos casos, a interface mais performática do Ceph. Por quê? Porque ele é "burro" da maneira certa. O driver do cliente (`librbd`, usado pelo QEMU/KVM, ou o módulo do kernel Linux) faz o trabalho pesado. Ele pega o mapa do cluster (OSD Map), calcula via algoritmo CRUSH exatamente onde os dados devem estar e fala **diretamente com os OSDs**. ### O Data Path do RBD: 1. **Aplicação (ex: VM)** envia write de 4KB. 2. **Librbd** mapeia esse write para um objeto (ex: `rbd_data.1234`). 3. **Librbd** calcula o PG (Placement Group) e os OSDs primários/secundários. 4. **Socket Direto:** O cliente abre conexão TCP direto com o OSD responsável. Não há "servidor de metadados" no meio do caminho para operações de I/O de dados. O overhead é mínimo. **Comandos Práticos:** Para verificar o mapeamento real de um objeto RBD e ver onde ele vive: ```bash rbd ls -l pool_vms/vm-100-disk-0 # Descobrir onde o prefixo do objeto está mapeado ceph osd map pool_vms rbd_data.1025774b0dc51.0000000000000001 ``` **Quando usar:** * Discos de Máquinas Virtuais (Proxmox, OpenStack). * Bancos de dados (via block device montado). * Qualquer cenário onde [IOPS, Throughput e Latência](/articles/iops-throughput-latencia-guia-completo) sejam críticos. ## 2. CephFS: O Custo do POSIX O CephFS é incrível porque é um sistema de arquivos distribuído POSIX-compliant. Isso significa que você pode ter 100 servidores montando a mesma pasta e gravando simultaneamente. Mas a conformidade POSIX custa caro. Para manter a consistência de diretórios, permissões e *locks* de arquivos, o Ceph precisa de um componente extra: o **MDS (Metadata Server)**. ### O Data Path do CephFS: O tráfego é bifurcado (Split-brain architecture): 1. **Metadados (open, ls, chmod):** O cliente fala com o **MDS**. O MDS mantém a árvore de diretórios na RAM (para velocidade) e faz flush para o RADOS. 2. **Dados (read, write):** Uma vez que o cliente sabe onde o arquivo está (graças ao MDS), ele fala **diretamente com os OSDs**, similar ao RBD. **O Gargalo:** Se você tiver milhões de arquivos pequenos, o MDS vira o gargalo. Um `ls -l` em um diretório com 1 milhão de arquivos pode travar sua aplicação, mesmo que seus discos OSD estejam ociosos. **Tuning Crítico:** Você precisa ajustar o cache do MDS e, em clusters grandes, usar *MDS Pinning* para distribuir subárvores de diretórios entre múltiplos MDS ativos. ```bash # Verificar status do MDS e lag ceph fs status # Definir afinidade de cache para diretórios quentes (Pinning) setfattr -n ceph.dir.pin -v 1 /mnt/cephfs/hot_data ``` **Quando usar:** * Pastas compartilhadas (Home directories, Webroot de clusters). * Workloads HPC (High Performance Computing). * Kubernetes RWX (ReadWriteMany) volumes. ## 3. RGW (RADOS Gateway): A Camada Web O RGW é a interface que transforma o Ceph em um "AWS S3 on-premise". Ele é fundamentalmente diferente de RBD e CephFS porque fala HTTP/REST. ### O Data Path do RGW: Aqui o overhead é maior. 1. **Cliente** envia requisição HTTP (PUT/GET). 2. **Load Balancer** (HAProxy/Nginx) recebe e passa para o RGW. 3. **RGW Daemon** processa o HTTP, autentica a request, consulta o **Bucket Index** (metadados do bucket). 4. **RGW** converte o payload em objetos RADOS e envia aos OSDs. Além da latência do protocolo TCP/HTTP, o RGW tem um custo pesado de **Indexação**. Cada bucket mantém um índice (geralmente no RocksDB via OSDs) listando seus objetos. Se você colocar 10 milhões de objetos num único bucket sem *sharding* (fragmentação do índice), a performance de escrita vai despencar. 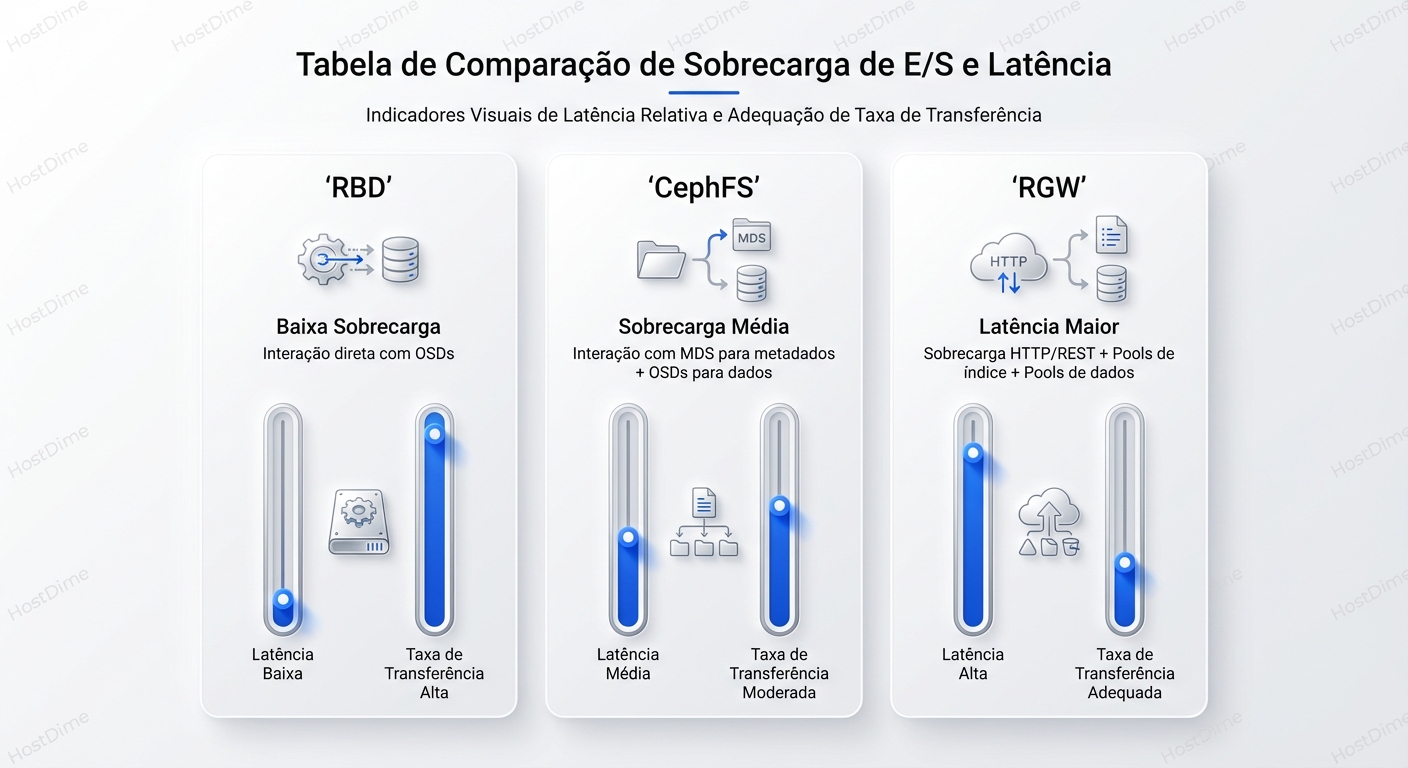 **Estratégia de Backup:** O RGW é o destino clássico para backups. Como discutimos em [Backup Full, Incremental e Diferencial](/articles/backup-full-incremental-e-diferencial-em-storage), ferramentas modernas (Veeam, Kasten, Velero) falam S3 nativamente. O overhead de latência do RGW não importa tanto para throughput de backup, desde que a largura de banda seja alta. **Quando usar:** * Armazenamento de objetos imutáveis (Imagens, PDFs, Logs). * Target de Backup. * Aplicações Cloud-Native. * Federated Storage (Multi-site replication). ## Comparativo Técnico: Overhead e Latência Para decidir a arquitetura, use esta matriz de decisão. Note como o cache do cliente afeta o resultado, um conceito que exploramos em [Read-ahead e Write Buffering](/articles/read-ahead-write-buffering-ajuda-atrapalha). | Característica | RBD (Block) | CephFS (File) | RGW (Object) | | :--- | :--- | :--- | :--- | | **Protocolo** | Nativo Ceph (TCP) | Nativo Ceph (TCP) | HTTP/REST | | **Componente Central** | Librbd (Client-side) | MDS (Metadata Server) | RGW Daemon (Gateway) | | **Latência Típica** | Baixa (< 1-2ms + Network) | Média (Depende do MDS) | Alta (Overhead HTTP) | | **Gargalo Comum** | OSD (Disco/Rede) | CPU/RAM do MDS | CPU do RGW / Bucket Index | | **Cache Client-side** | RBD Cache (RAM do Host) | Kernel Page Cache | Inexistente (Stateless) | | **Ideal para** | IOPS intensivo, Virtualização | Compartilhamento, HPC | Throughput, Web, Archival | ## Veredito: Qual escolher? 1. **Performance Pura (IOPS/Latência):** Use **RBD**. Se você precisa rodar um banco de dados, formate um volume RBD com XFS/Ext4 e monte localmente. Nunca coloque um DB sobre CephFS ou montagens S3 (s3fs/go-ofys), pois a consistência e latência serão terríveis. 2. **Colaboração:** Use **CephFS**. Se múltiplos servidores precisam ler/escrever nos mesmos arquivos simultaneamente, esta é a única opção viável que mantém a sanidade do POSIX. 3. **Escala Infinita e Web:** Use **RGW**. Se a aplicação foi feita para web (GET/PUT), não tente forçá-la a usar arquivos. O RGW escala horizontalmente: precisa de mais performance? Suba mais gateways RGW atrás do Load Balancer. O Ceph é poderoso porque permite misturar esses workloads no mesmo cluster RADOS subjacente. No entanto, isolar pools e definir "Crush Rules" separadas (ex: SSD para RBD, HDD para RGW) é a marca de uma arquitetura madura.

"Write Hole": A Paridade Que Te Abandona na Pior Hora
---...

RAID 60 Vs RAID 50 Analise De Risco E Performance Em Storage
O alerta no dashboard sinaliza a morte de um disco de 18TB, mas o verdadeiro crime ocorre durante a recuperação. Ao iniciar o *rebuild*, você submete o restante...

Write Amplification Causes Mitigation
SSDs revolucionaram o armazenamento de dados com sua velocidade e eficiência energética. No entanto, eles têm uma limitação fundamental: ao contrário dos HDDs (...

HBAs vs. Controladoras RAID: Quando Escolher Qual
O problema: Você precisa conectar um monte de discos a um servidor. Você tem duas opções principais: um HBA (Host Bus Adapter) ou uma controladora RAID. Qual vo...

O Fim Do HDD A Supremacia Dos Ssds De 60Tb
Identificamos o ponto de ruptura no hardware de armazenamento corporativo: a consolidação de drives de 61.44TB, exemplificados pelo Solidigm D5-P5336. Esta nova...
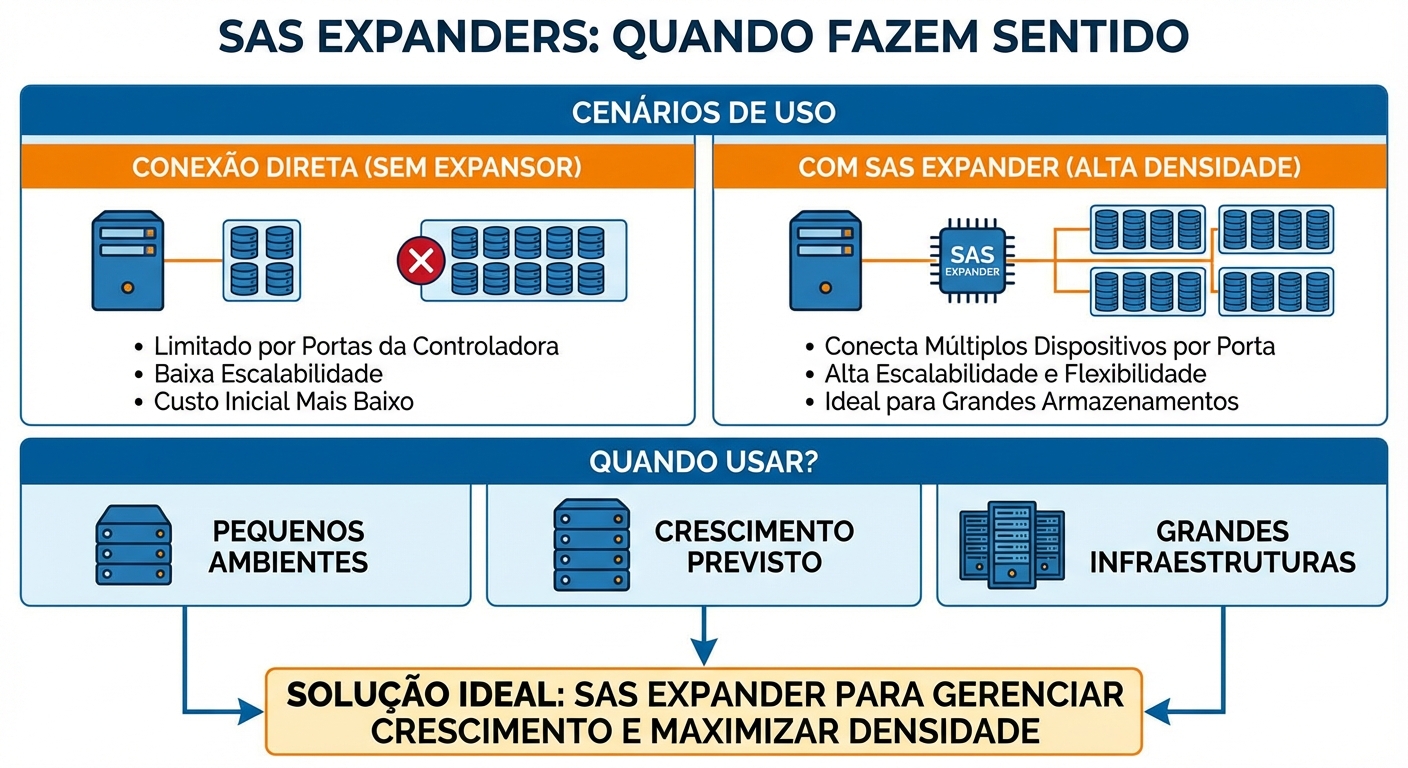
SAS Expanders: Quando Fazem Sentido
O Problema/Contexto:...

Ceph Arquitetura Basica E Quando Usar
Vamos ser honestos sobre o porquê de estarmos aqui. Ninguém acorda de manhã querendo gerenciar um cluster Ceph porque é "divertido". Nós fazemos isso porque a a...

Block, File e Object Storage: Um Guia Definitivo para Sysadmins e Engenheiros de Infraestrutura
Entender as nuances entre Block Storage, File Storage e Object Storage é crucial para qualquer profissional de infraestrutura. A escolha inadequada pode levar a...
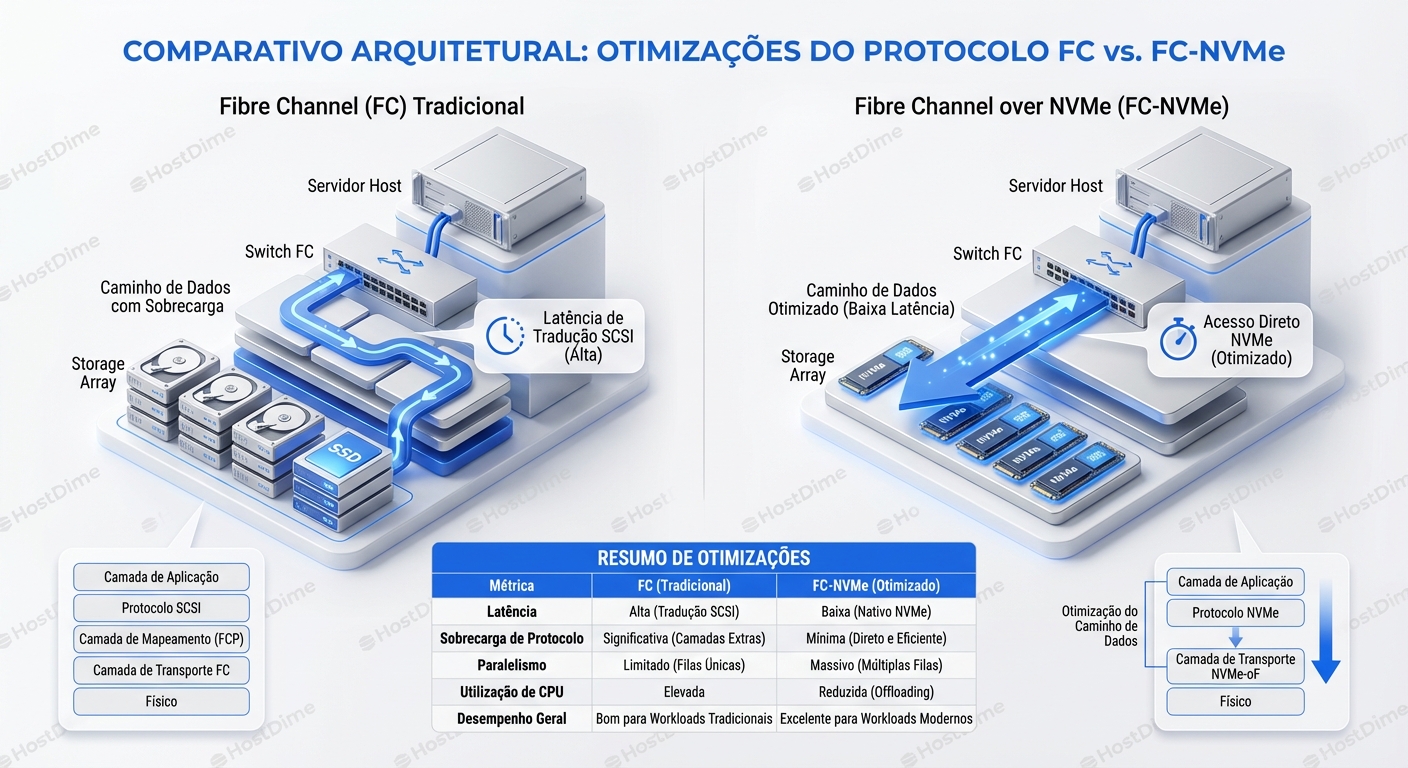
Fc NVMe O Que Muda Em Relacao Ao Fc Classico
FC-NVMe: A Revolução NVMe sobre Fibre Channel Explicada...

Jumbo Frames Mito Vs Realidade E Quando Usar
São 2 da manhã de uma terça-feira. O alerta no PagerDuty toca com uma daquelas mensagens vagas que fazem qualquer sysadmin experiente suspirar: "Latência alta n...

Acelere Seu Storage Implementando Cache Hierarquico L1 L2 L3
Marketing adora prometer "velocidade incrível" e "armazenamento ilimitado". A realidade? Latência. Ela é a inimiga número um da performance, e o storage é frequ...

Roce Vs Iwarp Conceitos E Riscos
Antes de entrarmos na briga dos protocolos, precisamos alinhar o modelo mental sobre por que estamos usando RDMA (Remote Direct Memory Access) em primeiro lugar...

Rebuild De RAID Como Estimar Tempo E Impacto
RAID. Aquela sigla mágica que promete proteger seus dados de desastres. Mas quando um disco pifa e o rebuild começa, a promessa vira uma tortura lenta. As estim...
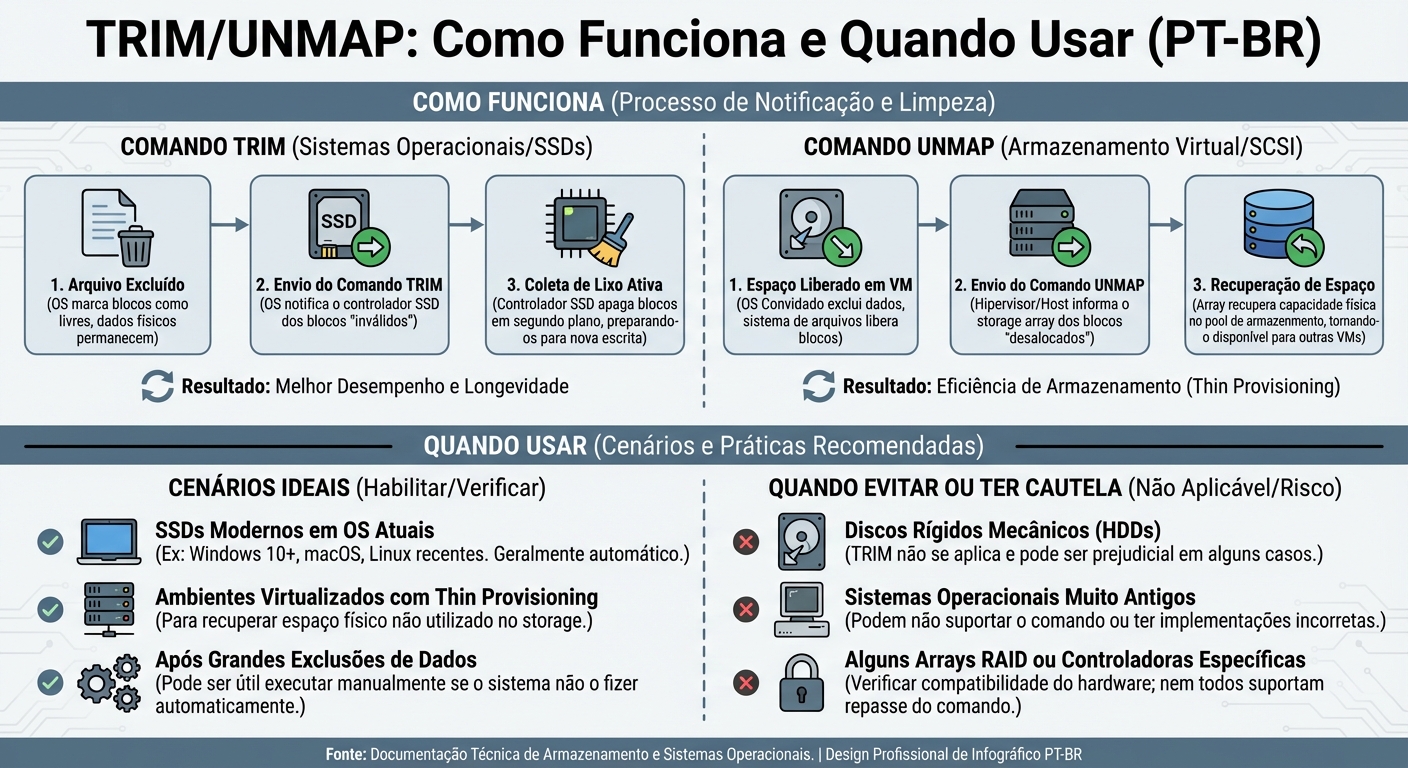
Trimunmap Como Funciona E Quando Usar
Discos rígidos tradicionais (HDDs) funcionam de uma maneira bastante direta: você escreve dados em um setor, e ele sobrescreve o que estava lá antes. Os SSDs (...

Lacp E Bonding O Que Ajuda E O Que Nao Ajuda
Antes de falarmos de *hashing* XOR ou frames Ethernet, precisamos ajustar o modelo mental. A intuição humana diz que se ligarmos dois canos de água em um tanque...

Backup De Saas A Verdade Critica Sobre Office 365 E Google Workspace
A suposição de que a migração para SaaS (Software as a Service) elimina a necessidade de estratégias de backup tradicionais é um **erro de arquitetura fundament...

Nic Offloads Tsogrolro Efeitos Colaterais Em Storage
Antes de falarmos sobre bits e bytes, precisamos ajustar nosso modelo mental sobre o que acontece quando o sistema operacional diz "envie este arquivo"....
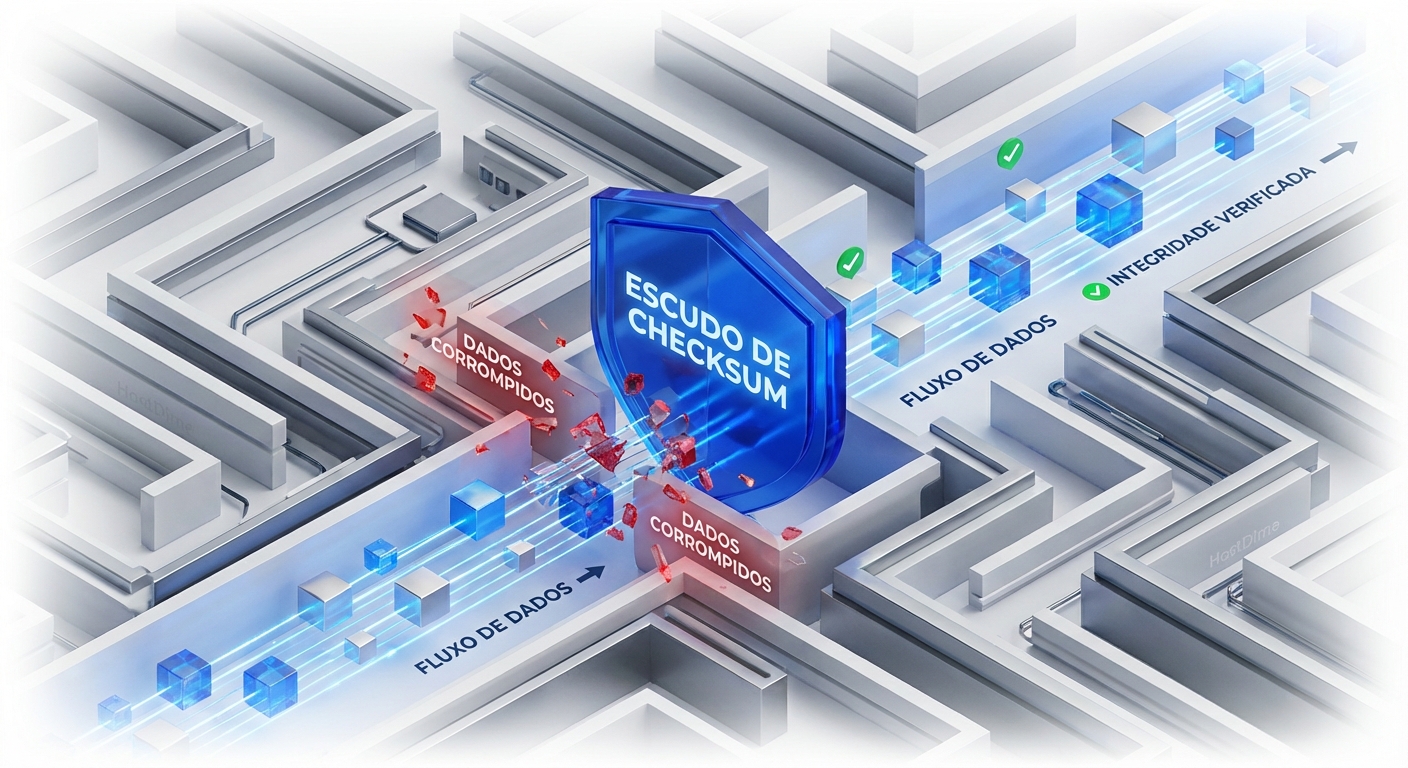
Checksums Por Que Mudam A Confiabilidade
Imagine a seguinte situação: você acabou de fazer um backup de 2TB de dados críticos. Semanas depois, precisa restaurar um arquivo vital, apenas para descobrir ...
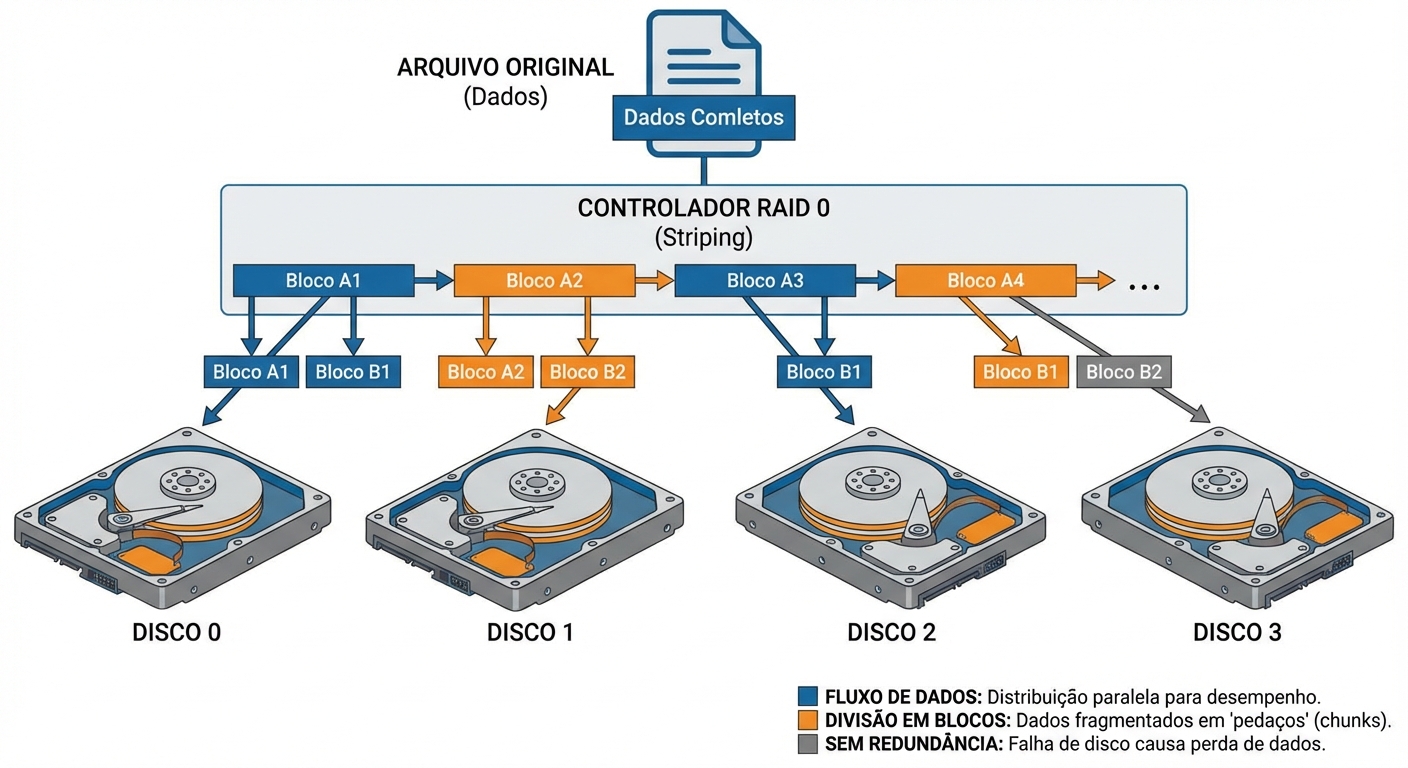
RAID 0: Onde faz sentido e onde é loucura
RAID 0: é como dar nitro ao seu carro, mas com um risco ENORME. Vamos entender isso!...

RAID 10 Vs RAID 01 A Ordem Dos Fatores Salva Seus Dados
Pare de tratar a matemática como engenharia; a ordem das operações define se você mantém seu emprego durante uma crise. O RAID 10 (stripe de espelhos) cria zona...
Scrub Por Que Existe E Qual Frequencia Usar
A integridade dos dados é uma preocupação central em qualquer infraestrutura de armazenamento. Discos falham, bits se invertem, e o silêncio desses problemas po...

Write-back vs Write-through: Riscos e Benefícios Desmistificados
O mundo do armazenamento de dados é cheio de compromissos. Uma das decisões mais cruciais que sysadmins, SREs e engenheiros de infraestrutura precisam tomar é c...
NVMe Of Tcp Vs Rdma Comparacao Realista
A busca por armazenamento de alta performance e baixa latência em data centers modernos tem impulsionado a adoção de tecnologias como NVMe-oF (NVMe over Fabrics...

Paridade Distribuida Como RAID 56 Escreve De Verdade
Seu chefe acabou de propor migrar o banco de dados para um RAID 5 para "economizar". Prepare-se para o desastre. RAID 5 e 6, apesar de suas vantagens em capacid...

Desvendando O SMB Performance Assinatura E Impactos Na Infraestrutura Moderna
A configuração do SMB (Server Message Block) invariavelmente apresenta um dilema central: como equilibrar a necessidade premente de segurança robusta com a dema...

NFS Desvendado Um Deep Dive Em Versoes Performance E Tuning Essencial
A lentidão em compartilhamentos NFS (Network File System) é um problema recorrente que assombra administradores de sistemas e usuários finais. A experiência, ou...

NVMe Em Chamas O Gargalo Invisivel Do Seu Servidor
Você pagou caro por drives Gen4 ou Gen5 prometendo 7000MB/s, mas o dashboard conta outra história durante o pico de carga. O marketing vende velocidade de *burs...

IOPS Throughput E Latencia Guia Pratico Para Diagnostico De Performance De Discos
Discos lentos são o câncer de qualquer sistema. Não adianta ter CPU de sobra e gigas de RAM se o disco não acompanha. A verdade é que, na maioria das vezes, o p...

Alua O Que E E Por Que Importa
Para entender o ALUA, primeiro precisamos destruir uma mentira confortável que o sistema operacional conta para si mesmo: a de que todos os cabos são iguais....
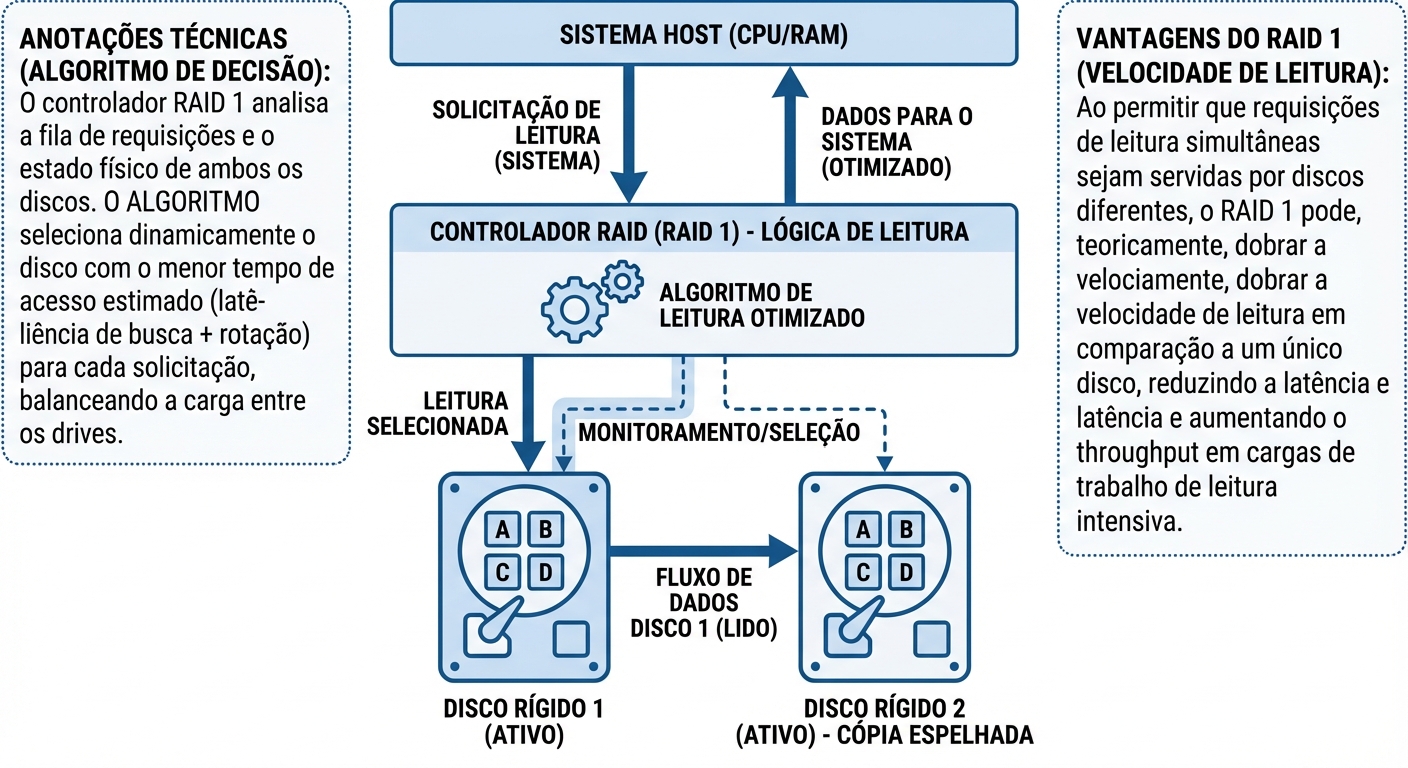
RAID 1: Espelhamento e Performance de Leitura
O RAID 1, também conhecido como espelhamento, é uma configuração de armazenamento que replica dados em dois ou mais discos. A ideia principal é ter redundância...

DAS vs NAS vs SAN vs SDS: O Guia Definitivo para Armazenamento de Dados
Como sysadmins, SREs e engenheiros de infraestrutura, uma das decisões mais cruciais que tomamos é: onde guardar os dados? Parece simples, mas a escolha da arqu...
Windows Storage Spaces Cenarios E Cuidados
**Storage Spaces x RAID: Uma Comparação Crucial**...

ZFS Special Vdev Acelerando Pools De HDD Com NVMe Dedicado
Vamos ser honestos: discos rígidos (HDD) são ótimos para armazenar terabytes de logs ou backups que você reza para nunca precisar, mas são péssimos para agilida...
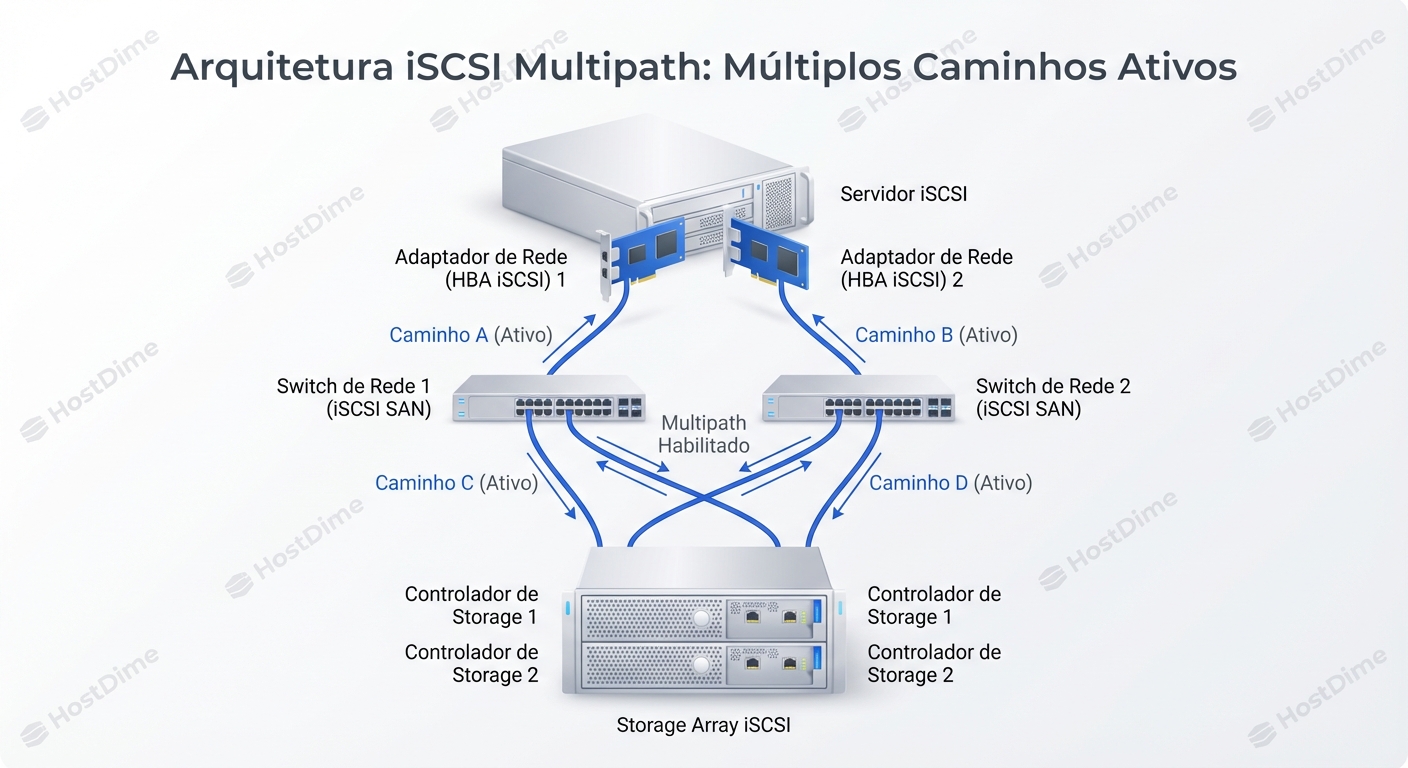
iSCSI Multipath Como Funciona E Como Configurar
iSCSI Multipath permite que um servidor estabeleça múltiplas conexões independentes para o mesmo target iSCSI (o storage). Cada conexão utiliza um caminho físic...

Latencia De Switch Por Que Switch E Tudo Igual E Falso
A maior armadilha mental que temos é visualizar um switch como um encanamento passivo. Imaginamos que os bits entram por uma porta e fluem eletricamente para ou...
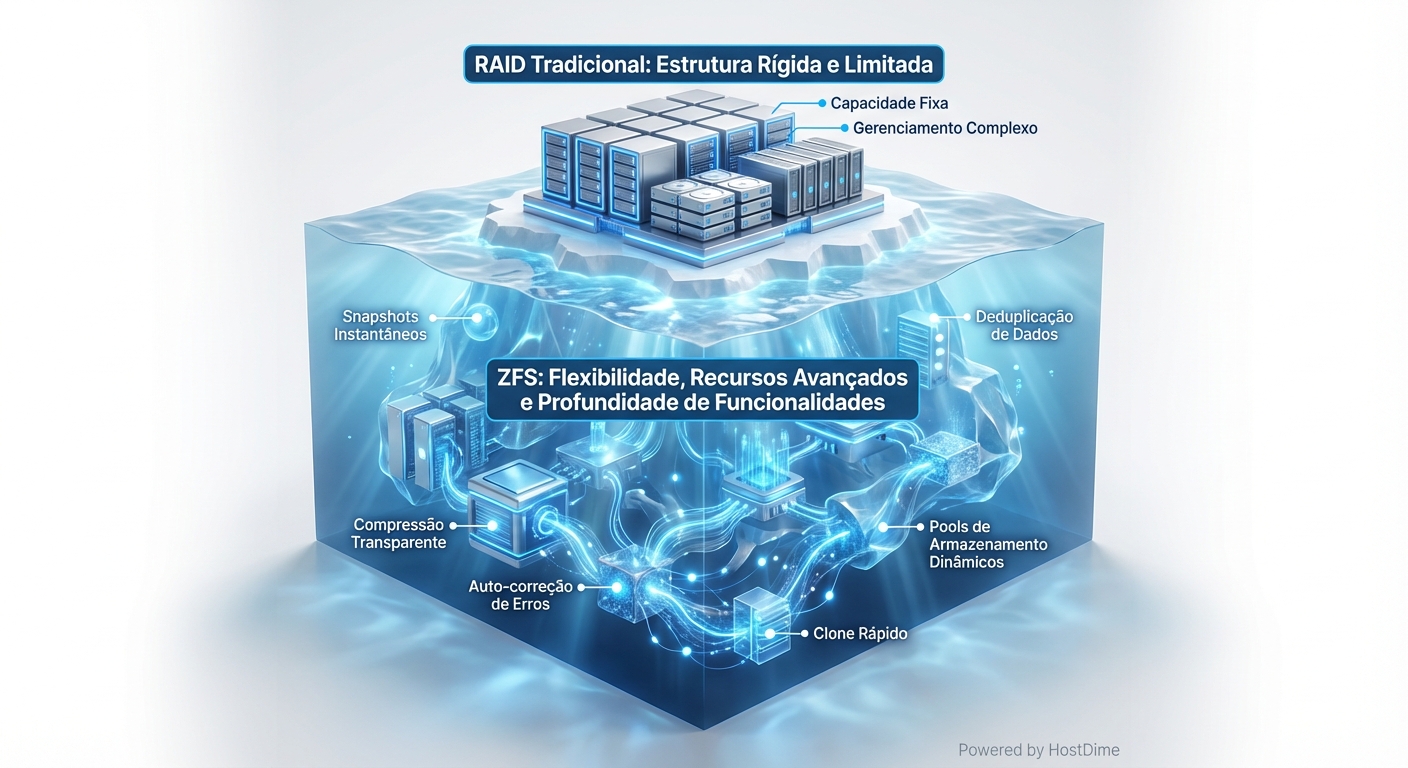
ZFS Vs RAID Tradicional Diferencas Conceituais
RAID te protege de falha de disco. ZFS te protege de *corrupção* de dados. Entenda a diferença, ou prepare-se para noites em claro....

RAID 10 Vs RAID 01 A Ordem Dos Fatores Altera O Produto
**Visualizando a Distribuição de Dados**...

URE: O Inimigo Silencioso do seu RAID
---...

Diagnostico Rapido SSD NVMe Lento Guia Pratico Para Sysadmins
SSDs NVMe são vendidos como a oitava maravilha da velocidade, e, *na maioria das vezes*, entregam o prometido. Mas quando a performance despenca, a dor de cabeç...
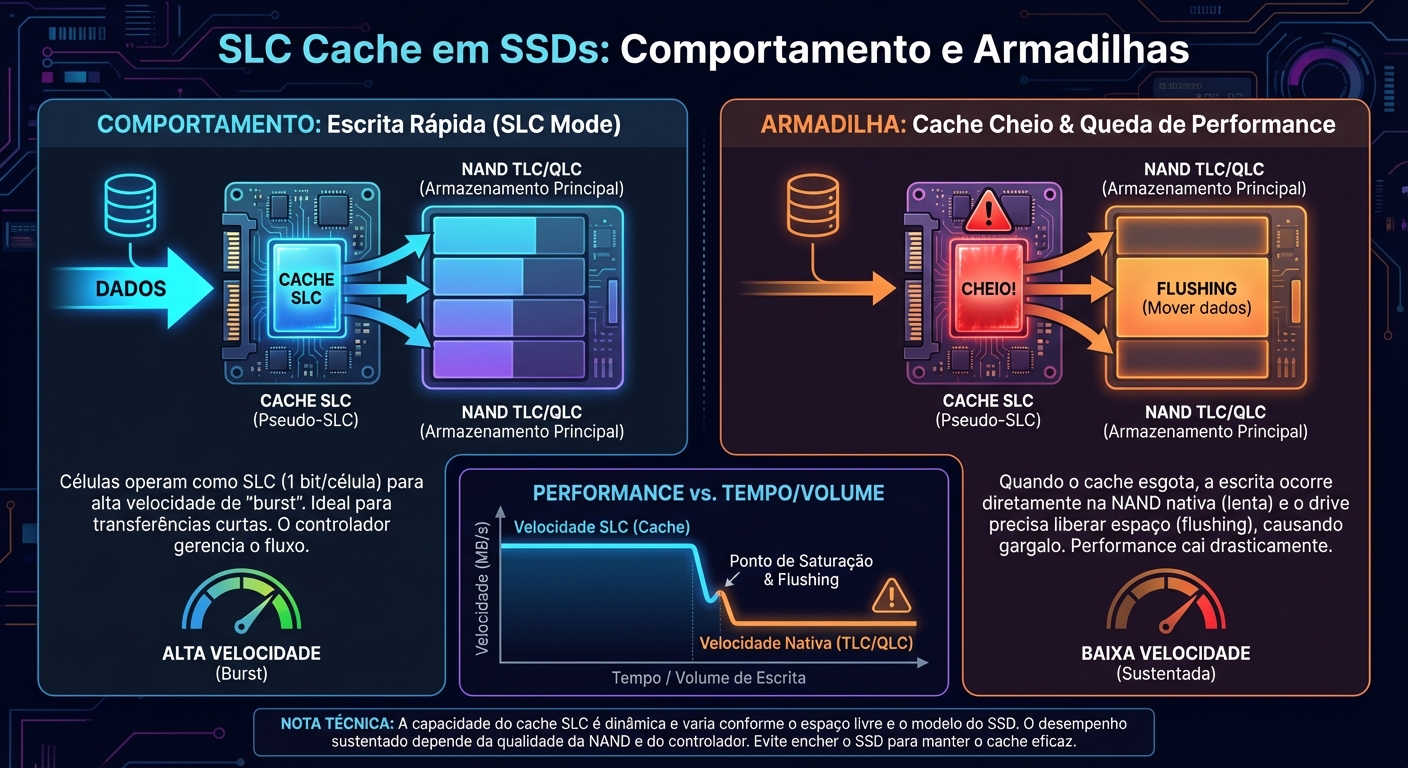
Cache SLC em SSDs: Comportamento e Armadilhas
SSDs (Solid State Drives) se tornaram onipresentes em data centers e estações de trabalho devido à sua velocidade, durabilidade e eficiência energética superior...

Rpo E Rto Como Definir Metas Realistas
Muitas empresas caem na armadilha de buscar RPO e RTO próximos de zero sem entender as implicações. Um RPO de zero significa que você não pode perder *nenhum* d...
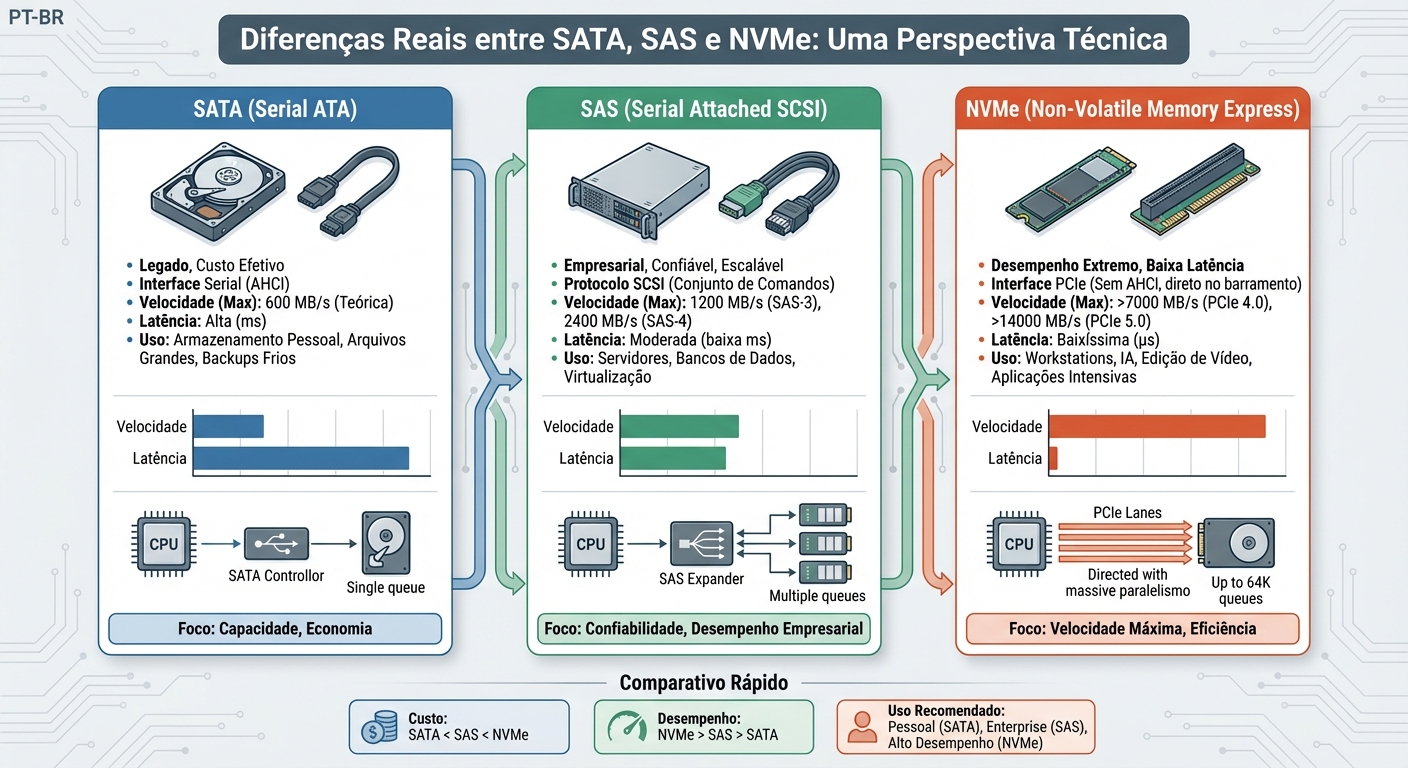
Diferencas Reais Entre Sata Sas E NVMe
Como sysadmins, frequentemente nos deparamos com a escolha de soluções de armazenamento para servidores, estações de trabalho e até mesmo laptops. SATA, SAS e N...

ZFS Recordsize O Guia Definitivo Para Bancos De Dados E Arquivos Grandes
A escolha do `recordsize` no ZFS não é trivial; é um equilíbrio delicado entre desempenho, utilização de espaço e a natureza dos dados armazenados. Optar por u...

Jbod Vs RAID Como Escolher Em 2025
Para entender por que estamos matando o RAID de hardware, precisamos visualizar o que ele realmente faz....

RAID Nao E Backup Cenarios Reais De Perda De Dados
RAID (Redundant Array of Independent Disks) é uma tecnologia para combinar múltiplos discos físicos em uma única unidade lógica. Existem vários níveis de RAID ...
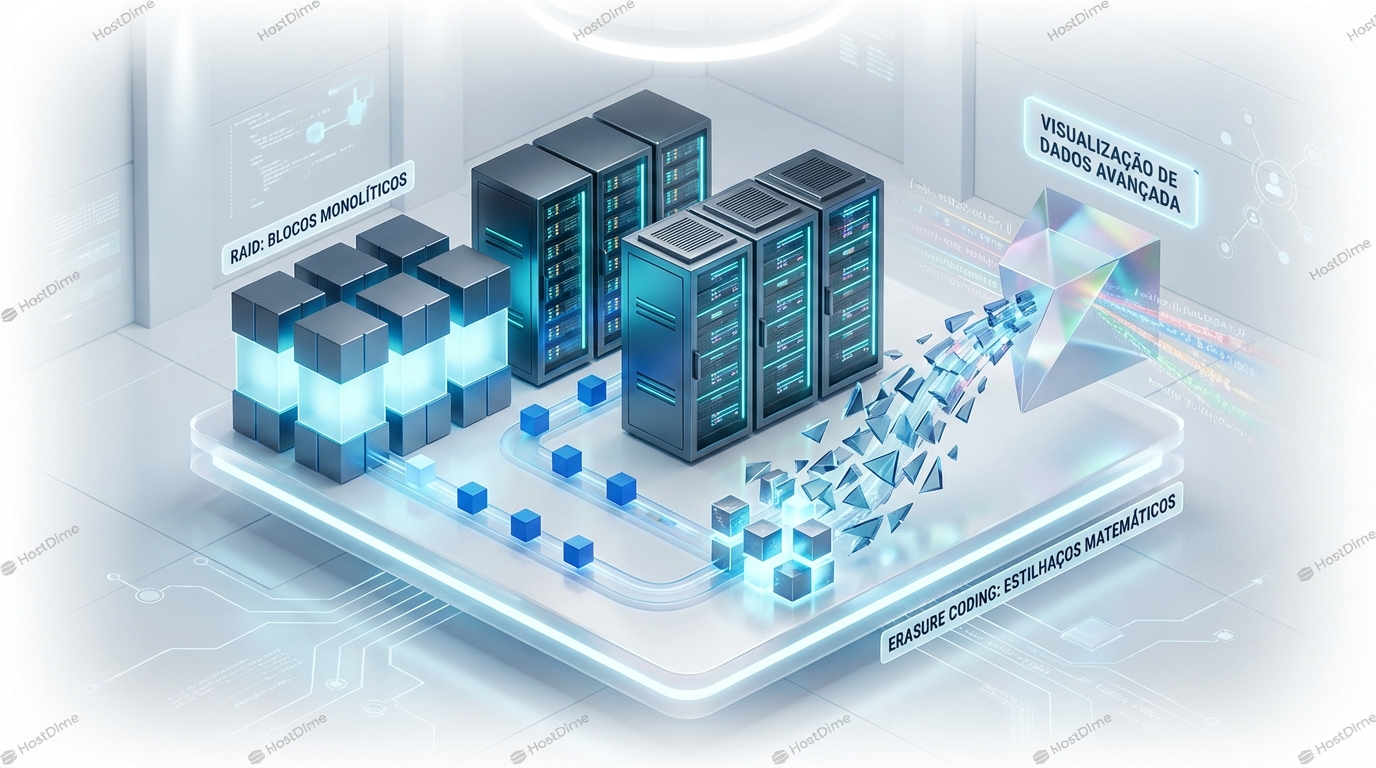
Erasure Coding Alternativa A RAID Conceitos E Trade Offs
São 03:00 da manhã de uma terça-feira. O PagerDuty grita. Um disco de 16TB falhou no seu array de armazenamento principal. O sistema, configurado em RAID 6, com...

Sshd Disco Hibrido Em 2025 Sucata Ou Salvacao
O SSHD nasceu por volta de 2010 como um curativo temporário: uma tentativa de colar um cache NAND minúsculo em pratos magnéticos lentos para contornar o custo p...

Tcp Tuning Para Iscsinvme Tcp O Que Ajustar
Antes de tocar em qualquer `sysctl`, você precisa visualizar o que acontece quando um bloco de dados sai da placa de rede (NIC) e tenta chegar ao disco virtual....

SSD Vs HDD
Se você está montando um servidor hoje, a pergunta não é "SSD ou HDD?", mas sim "Onde eu coloco cada um?". A era do HDD como drive de boot acabou, mas a era do ...

RAID 60 Vs RAID 50 Quando A Complexidade Vale A Pena
Para entender por que o RAID 50 está se tornando obsoleto para *bulk storage*, precisamos primeiro alinhar nosso modelo mental sobre o que "Nested RAID" (RAID A...

Mtu Mss E Fragmentacao Impacto Em Storage Na Rede
Para um Sysadmin Sênior, a rede não é um tubo contínuo de dados. É uma série de eventos discretos. Cada pacote que entra ou sai da interface de rede (NIC) é um ...

Thin Provisioning Beneficios E Riscos
**Thin Provisioning em Ambientes de Virtualização: Flexibilidade e Risco Amplificados**...
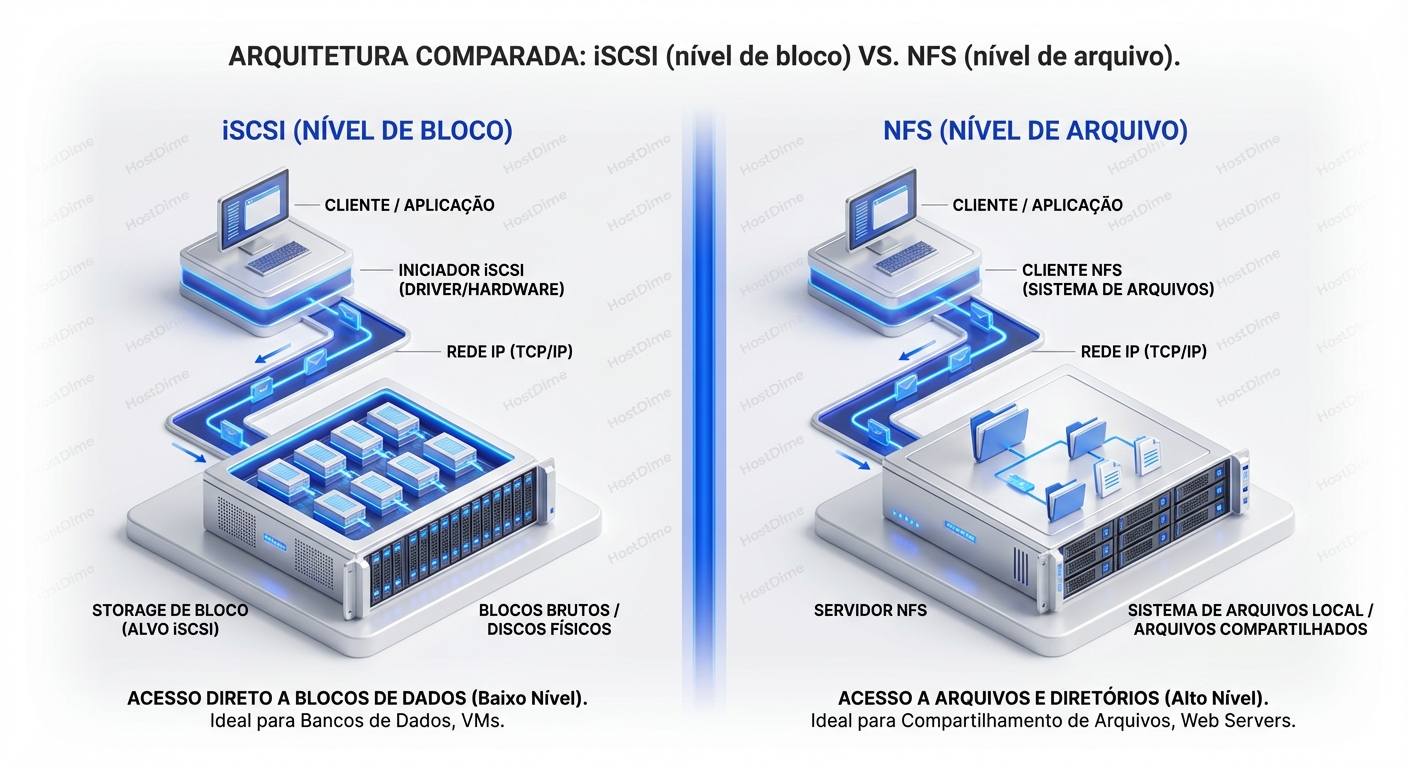
iSCSI Vs NFS Comparacao Pratica Por Workload
O pesadelo de todo SysAdmin: o storage gargala. VMs ficam lentas, o banco de dados trava, e os usuários reclamam da lentidão no acesso aos arquivos. A causa rai...

Hot Spare Dedicado Vs Global Estrategia Correta
Imagine um incêndio no seu prédio. O alarme dispara, e cada segundo conta. No mundo do storage, um disco falhando é esse incêndio. O RAID te dá tempo para respi...
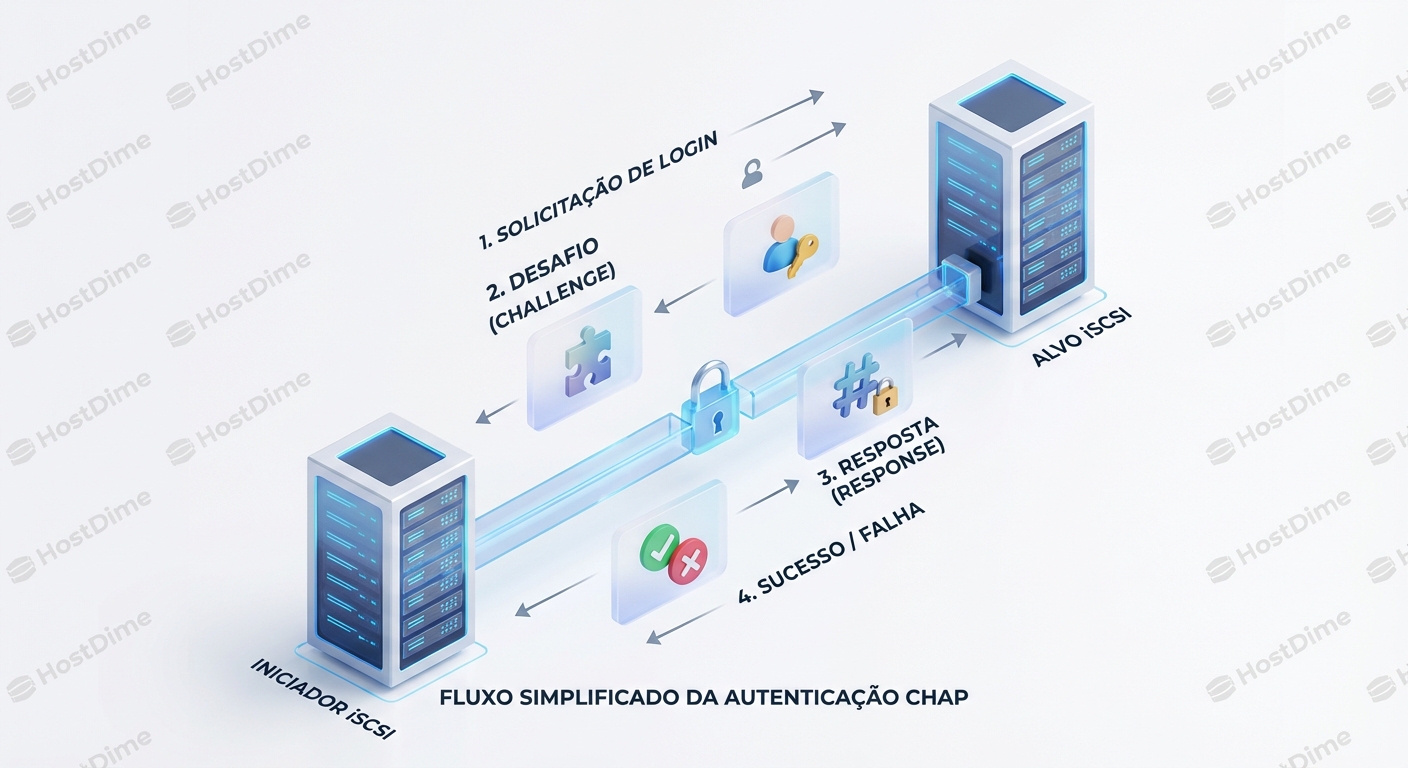
iSCSI Chap Autenticacao E Limitacoes
O iSCSI (Internet Small Computer Systems Interface) revolucionou o armazenamento em rede, permitindo que servidores acessem dispositivos de armazenamento remoto...

RAID 1 vs RAID 5 em 2024: O Duelo da Performance e Segurança
O pesadelo de todo sysadmin: o alarme dispara no meio da noite. Um disco pifou. A pergunta que não quer calar: seu sistema de armazenamento vai sobreviver, ou v...

Alinhamento de Partição: O Segredo Oculto da Performance de I/O
O alinhamento de partição é um daqueles detalhes de baixo nível que, quando negligenciado, pode causar dores de cabeça significativas em termos de performance d...

Replicacao Sincrona Vs Assincrona
**O Preço da Consistência: Latência e Disponibilidade**...
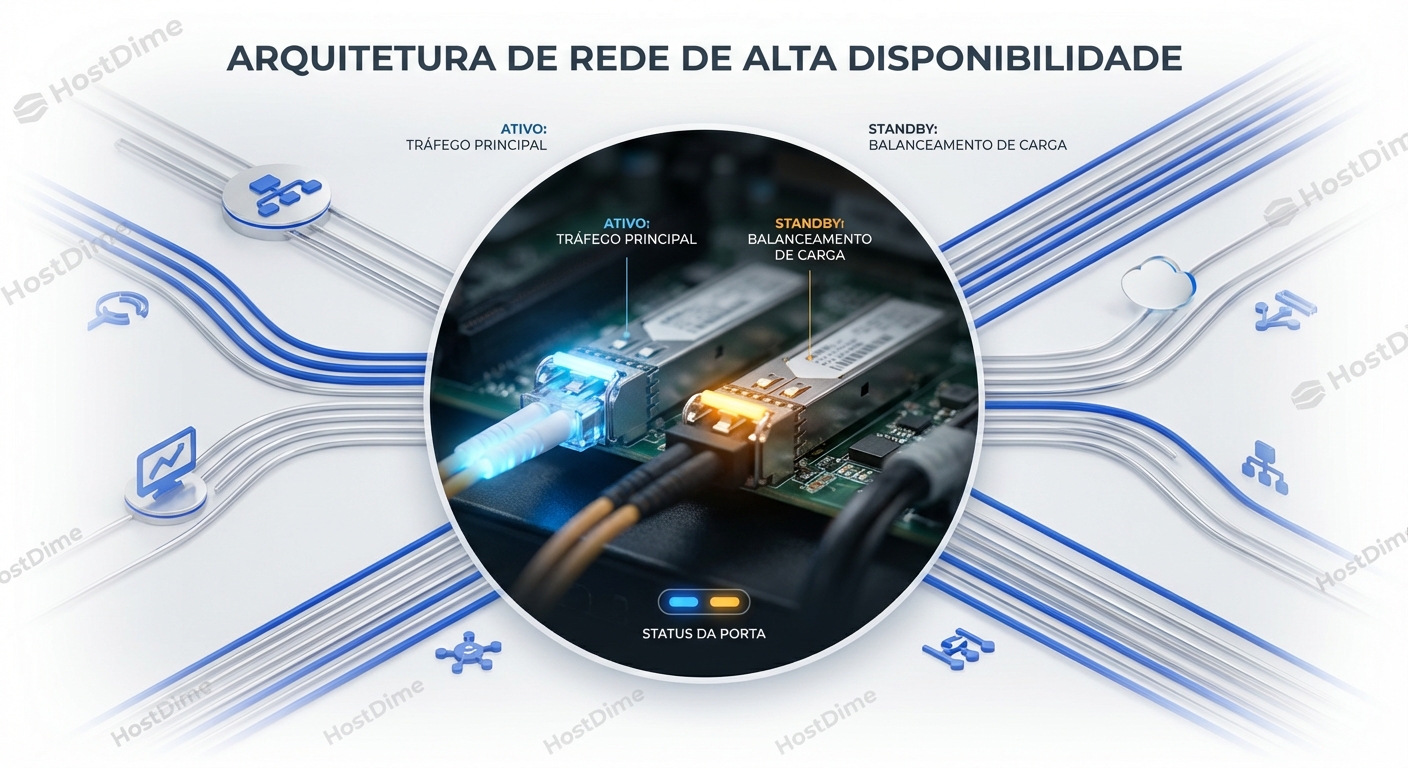
Paths Ativo Ativo Vs Ativo Passivo Implicacoes
Para entender o tráfego de I/O moderno, esqueça os diagramas de rede por um minuto. Vamos usar uma analogia de logística física....

RAID Hardware Vantagens Limitacoes E Custos
Imagine a seguinte situação: um dos discos do seu servidor de banco de dados falha em plena sexta-feira à noite. Se você implementou RAID, teoricamente, seus da...

Dcbpfcets Ethernet Sem Perdas E Controversias
Para entender o DCB e o PFC, precisamos primeiro ajustar nosso modelo mental sobre como redes funcionam....

Stripe Size Chunk Size Como Escolher Corretamente
Imagine a seguinte situação: você está configurando um novo servidor de banco de dados com um RAID 10 parrudo. Escolhe discos NVMe topo de linha, muita RAM, mas...

Minios3 Storage Objeto E Onde Encaixa
O alarme dispara às 3 da manhã: "MinIO inacessível! Aplicação crítica offline!". O pânico se instala. Onde começar?...

Storage Para Bancos De Dados Desmistificando A Escolha E O Layout Ideal Mysqlpostgres
Achar que CPU e RAM resolvem todos os problemas de performance de um banco de dados é o equivalente a acreditar em unicórnios. A verdade nua e crua é que, em 99...
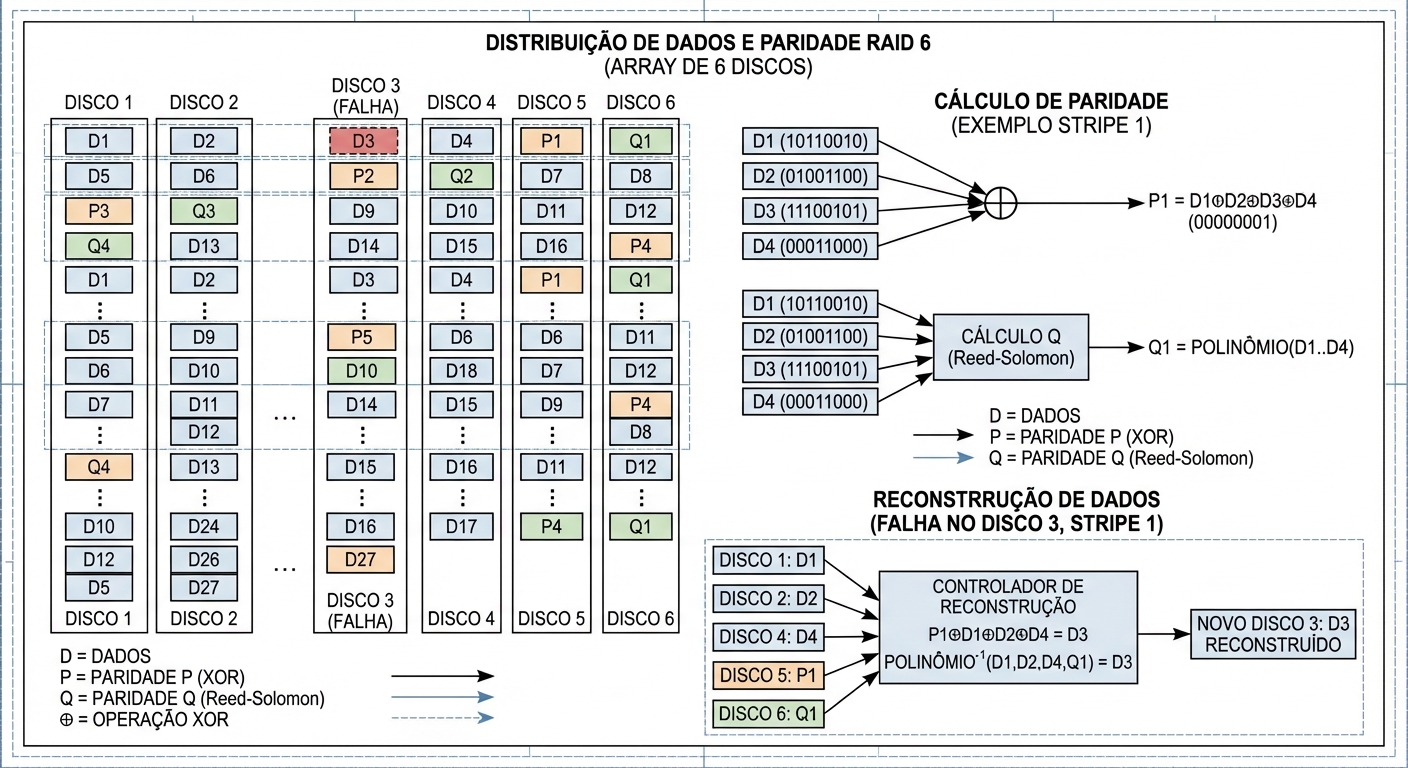
RAID 6 Custo De Paridade E Casos De Uso
Claro, aqui está um guia técnico sobre RAID 6 no estilo Julia Evans:...

Snapshots O Que Sao E Como Proteger Contra Erro Humano
Snapshots não são cópias físicas de dados, são tabelas de ponteiros congeladas no tempo. Enquanto o método legado *Copy-on-Write* (CoW) penaliza a escrita ao mover dados antigos antes de sobrescrever, o moderno *Redirect-on-Write* (RoW) elimina essa latência escrevendo novos dados em blocos livres. Eles são sua defesa primária contra `rm -rf` e erros lógicos, permitindo RPOs de segundos, mas lembre-se: se o storage array falhar, seus snapshots morrem junto — eles nunca substituem um backup real. --- Se você já sentiu o sangue gelar após digitar um `DROP TABLE` ou um `rm -rf` no diretório errado, você entende o valor do tempo. Nesses momentos, restaurar de um backup (que pode ter horas de idade e levar horas para ser copiado) é inaceitável. É aqui que entra o snapshot. Muitos administradores tratam snapshots como "mágica", mas entender a mecânica de I/O por trás deles — especificamente a diferença entre **Copy-on-Write (CoW)** e **Redirect-on-Write (RoW)** — é o que separa quem recupera o ambiente em 30 segundos de quem derruba a performance do storage inteiro tentando salvar o dia. ## O que é um Snapshot (Nível de Bloco) No nível mais fundamental, em um ambiente de [Block, File e Object Storage](/articles/tipos-de-armazenamento-block-file-object), um snapshot **não é uma cópia dos dados**. É uma cópia dos **metadados** (ponteiros) que mapeiam onde os dados residem fisicamente no disco naquele exato momento. Quando você tira um snapshot, o sistema congela o mapa de blocos. O volume continua operando, mas o comportamento de escrita muda drasticamente dependendo da tecnologia subjacente. ## Copy-on-Write (CoW): O Modelo Tradicional O método CoW (usado classicamente pelo LVM no Linux e snapshots antigos de SANs) é robusto, mas introduz uma penalidade de escrita severa. **O fluxo de uma escrita em um volume com Snapshot CoW:** 1. A aplicação envia uma solicitação de escrita para o Bloco A. 2. O storage detecta que o Bloco A é protegido por um snapshot e ainda não foi modificado. 3. **Leitura:** O storage lê o conteúdo original do Bloco A. 4. **Cópia:** O storage escreve esse conteúdo original em uma área reservada (Snapshot Reserve). 5. **Escrita:** O storage finalmente sobrescreve o Bloco A com o novo dado da aplicação. Isso transforma 1 I/O de escrita lógico em **3 operações físicas de I/O** (1 Leitura + 2 Escritas). Isso é conhecido como "Write Penalty". 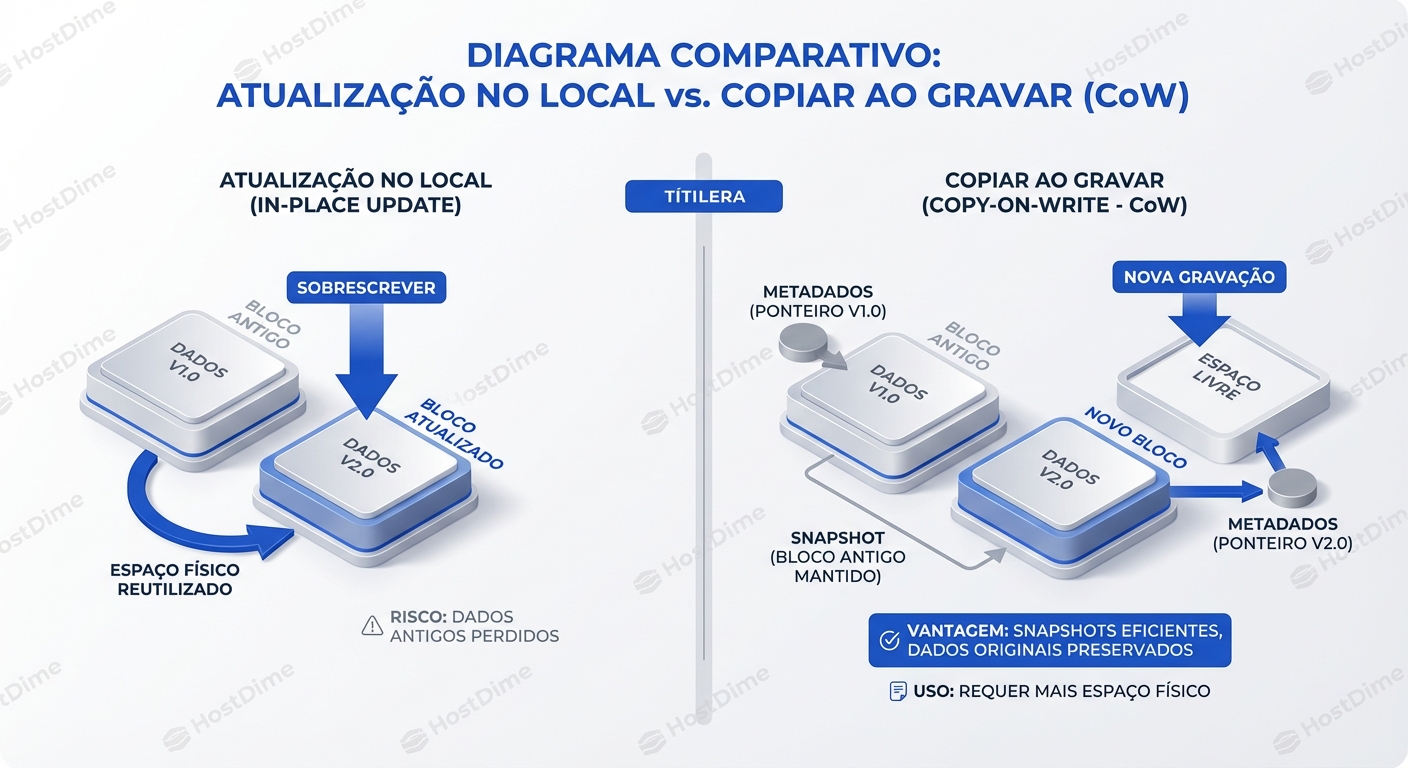 ### Exemplo Prático: LVM (Linux) No Linux, o LVM usa CoW. Se você criar um snapshot muito pequeno para um volume com alta taxa de alteração, o snapshot ficará inválido (corrompido) assim que a área reservada encher. ```bash # CUIDADO: Se as alterações no original excederem 1GB, o snapshot morre. lvcreate -L 1G -s -n lv_dados_snap /dev/vg01/lv_dados # Verificando o estado e preenchimento do snapshot lvs -o lv_name,snap_percent,origin ``` ## Redirect-on-Write (RoW): A Abordagem Moderna O RoW (usado por ZFS, NetApp WAFL, e storages modernos all-flash) resolve o problema da penalidade de escrita. **O fluxo de uma escrita em um volume com Snapshot RoW:** 1. A aplicação envia uma solicitação de escrita para o Bloco A. 2. O storage **não toca** no Bloco A original (ele permanece onde está, apontado pelo snapshot). 3. **Redirecionamento:** O storage escreve o novo dado em um **novo bloco livre** (Bloco B). 4. O ponteiro do volume ativo é atualizado para apontar para o Bloco B. Resultado: 1 I/O lógico = 1 I/O físico. Não há penalidade de leitura antes da escrita. A desvantagem histórica do RoW era a fragmentação (os dados ficam espalhados pelo disco), mas com a latência de busca quase nula dos SSDs/NVMe, isso se tornou irrelevante. ## Comparativo Técnico: CoW vs. RoW | Característica | Copy-on-Write (CoW) | Redirect-on-Write (RoW) | | :--- | :--- | :--- | | **Penalidade de Escrita** | Alta (3 I/Os por escrita). | Nula ou Mínima (1 I/O por escrita). | | **Performance de Leitura** | Alta no volume original (dados contíguos). | Pode degradar com o tempo (fragmentação), mitigado por SSDs. | | **Uso de Espaço** | Cresce conforme dados originais são alterados. | Cresce conforme novos dados são escritos. | | **Rollback (Reversão)** | Lento (precisa copiar dados de volta). | Instantâneo (apenas reverte ponteiros). | | **Exemplos** | LVM (Linux), VMware (VMFS), SANs Legadas. | ZFS, Btrfs, NetApp, Pure Storage, Ceph. | Como discutimos em [IOPS, Throughput e Latência: O Triângulo Mágico do Storage](/articles/iops-throughput-latencia-guia-completo), entender essas penalidades é vital para não saturar suas controladoras durante o horário de pico. ## A Mecânica do Rollback: Defesa Contra Erro Humano A principal função do snapshot para o Sysadmin é a reversão rápida. Diferente de um restore de backup que move terabytes de dados, o rollback de snapshot é uma operação de metadados. 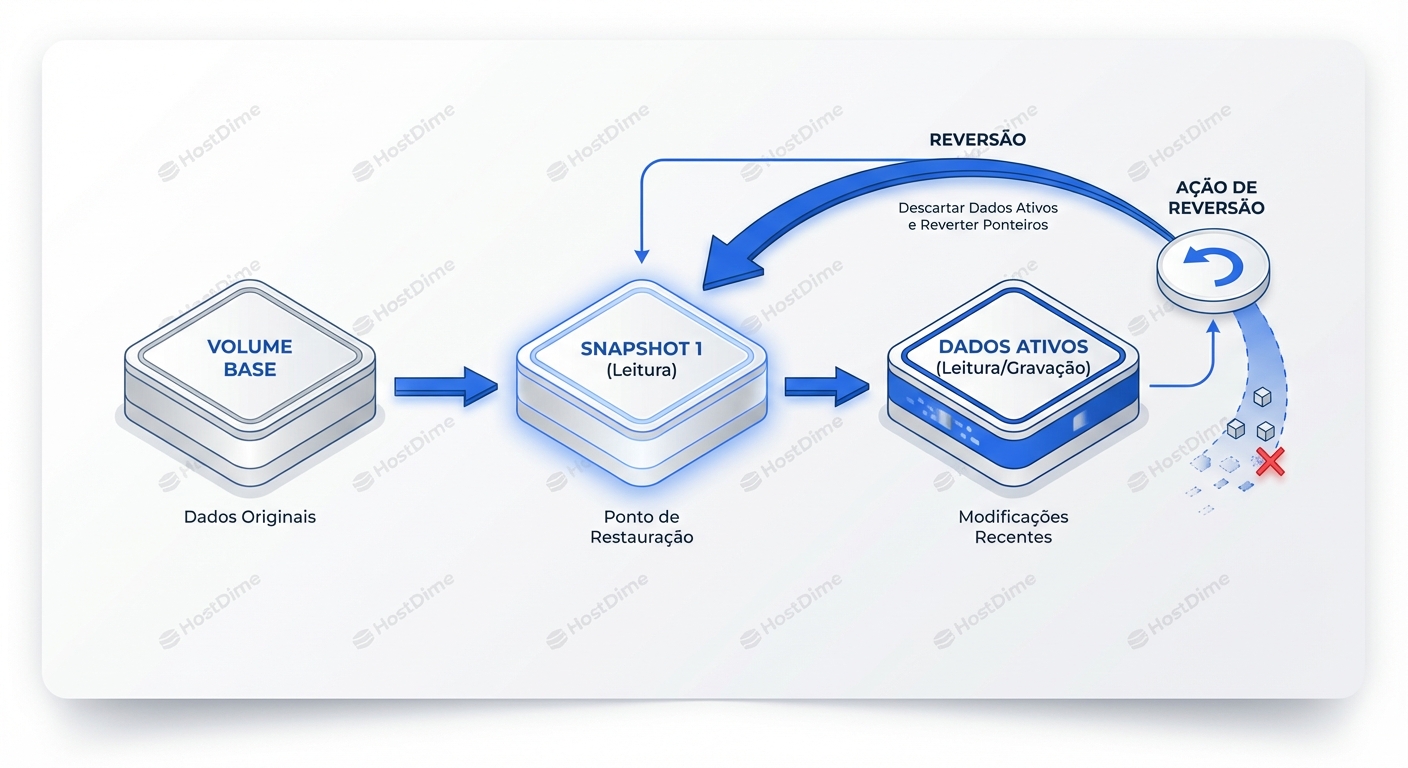 Quando você executa um rollback, você está dizendo ao sistema de arquivos: "Descarte todos os blocos escritos após o Timestamp X e faça o ponteiro mestre apontar para a árvore de blocos do Timestamp X". ### Cenário Real: ZFS Rollback Imagine que um desenvolvedor rodou uma migração de banco de dados que corrompeu dados críticos. Se você usa ZFS: ```bash # 1. Listar snapshots disponíveis zfs list -t snapshot # Saída: # NAME USED AVAIL REFER MOUNTPOINT # tank/db@2023-10-27-0800 150M - 100G - # tank/db@2023-10-27-0900 50M - 101G - # 2. O desastre ocorreu às 09:15. Revertendo para as 09:00. # AVISO: Isso destrói qualquer dado criado APÓS as 09:00. zfs rollback -r tank/db@2023-10-27-0900 ``` Essa operação leva menos de 1 segundo, independentemente se o volume tem 100GB ou 10TB. Isso permite definir [RPO e RTO](/articles/rpo-e-rto-como-definir-metas-realistas) extremamente agressivos para falhas lógicas. ## O Perigo: Snapshots não são Backup Este é o erro mais comum que vejo juniores cometerem. **Snapshots dependem da integridade dos blocos originais no storage.** Se você tem um storage com RAID 5 e perde 2 discos (falha catastrófica do array), você perdeu o volume **E** os snapshots. O snapshot reside na mesma estrutura física. Além disso, cadeias longas de snapshots (especialmente em modelos CoW como VMware) degradam a performance. Cada leitura de um bloco não modificado pode ter que percorrer uma cadeia de "delta files" para encontrar o dado correto. **Regra de Ouro:** Use snapshots para proteção operacional de curto prazo (horas/dias) e recuperação de erros lógicos. Use backups (em outro media/location) para proteção contra desastres e retenção de longo prazo. Veja mais sobre isso em [RAID não é backup: cenários reais de perda de dados](/articles/raid-nao-e-backup-cenarios-reais-de-perda-de-dados). ## Conclusão Para o Sysadmin Sênior, snapshots são ferramentas de precisão. 1. Prefira tecnologias **RoW** (como ZFS ou arrays modernos) para evitar impacto em produção. 2. Monitore o **consumo de espaço** (snapshots de volumes com alta taxa de escrita enchem o disco rapidamente). 3. Nunca confie neles como sua única cópia dos dados. Dominar essa mecânica permite que você ofereça à sua empresa uma "máquina do tempo" rápida e eficiente, transformando crises potenciais em meros inconvenientes de alguns minutos.

Desvendando o Tamanho do Bloco: Por Que 4K, 8K ou 128K Importam (e Como Escolher)
O tamanho do bloco é um dos segredos mais mal compreendidos no mundo do armazenamento. Ignorá-lo pode levar a gargalos de performance severos, mesmo com hardwar...

Linux Multipath Dm Multipath Conceitos Essenciais
Para entender o DM-Multipath, você precisa entender a filosofia do Device Mapper (DM) no Linux. O DM é, essencialmente, um framework de mentiras organizadas....
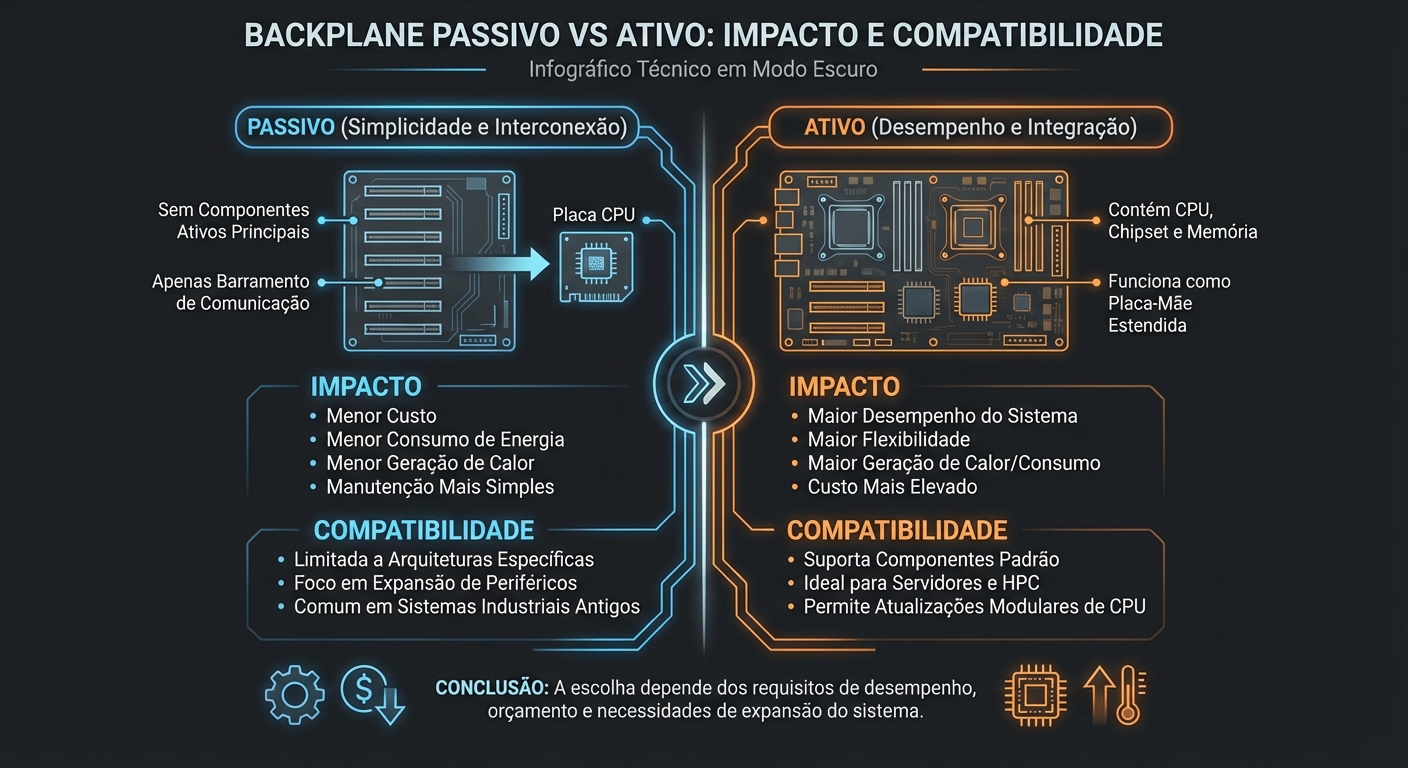
Backplane Passivo vs. Ativo: Impacto e Compatibilidade
O objetivo deste guia é fornecer aos sysadmins um entendimento profundo das diferenças entre backplanes passivos e ativos, suas implicações práticas e considera...
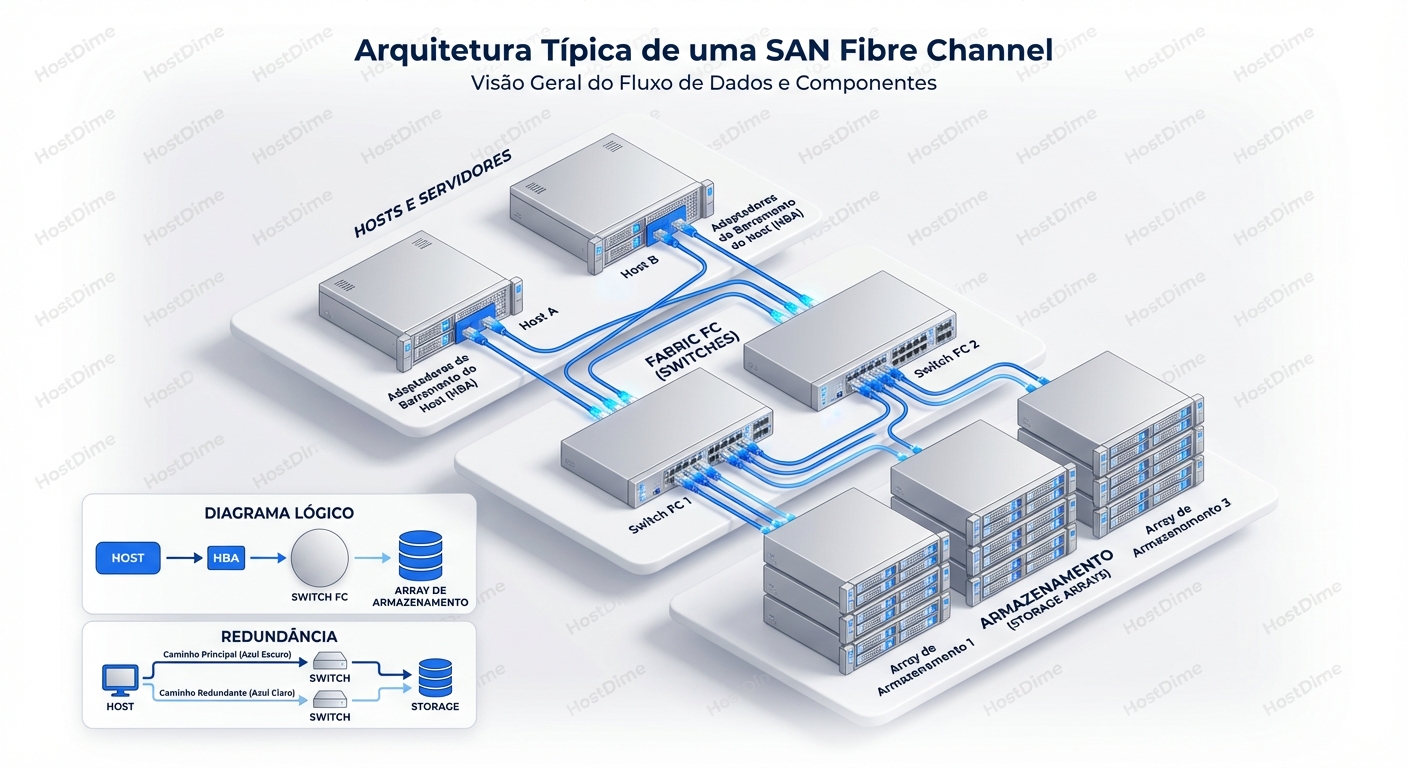
Fibre Channel Conceitos Zoning E Melhores Praticas
Fibre Channel (FC) não é exatamente "fibra" no sentido de internet residencial. Apesar de usar cabos de fibra óptica para transmitir dados, o protocolo FC é mui...

Io Queue Depth Performance
Imagine uma lanchonete. Clientes chegam (requisições de I/O), fazem seus pedidos (leitura ou escrita de dados) e esperam (tempo de latência) até que seus hambúr...

Vm Storage Performance Desmistificando O Mito Dos Padroes Aleatorios
A verdade inconveniente é que, no mundo da virtualização, a aleatoriedade deixou de ser uma exceção para se tornar a regra. Esqueça os contos de fadas sobre I/O...

RAID 5 Vs RAID 6 O Veredito Forense Da Integridade
O sintoma é inconfundível: **luzes âmbar piscando no chassi** e o silêncio pesado de um volume desmontado. O array está degradado. O que deveria ser um repositó...
Btrfs RAID Estado Atual Pros E Contras
O Btrfs (pronuncia-se "Butter FS") é um sistema de arquivos copy-on-write moderno, projetado para lidar com grandes volumes de dados, tolerância a falhas e fáci...

RAID Software Mdadm Vantagens Limitacoes E Custos
Seu servidor está lento? Antes de culpar a rede ou a aplicação, investigue o RAID. RAID por software, especialmente com mdadm, é uma solução popular pela flexib...

Read-ahead e Write Buffering: Quando Ajudam e Quando Atrapalham
A performance de I/O é frequentemente o gargalo em sistemas de computação. Discos mecânicos (HDDs) são inerentemente lentos em comparação com a memória RAM e a ...

Deduplicacao Quando Vale E Quando E Cilada
A deduplicação é uma técnica tentadora: a promessa de espremer mais dados no mesmo espaço físico, reduzindo custos e simplificando o gerenciamento. Mas a implem...
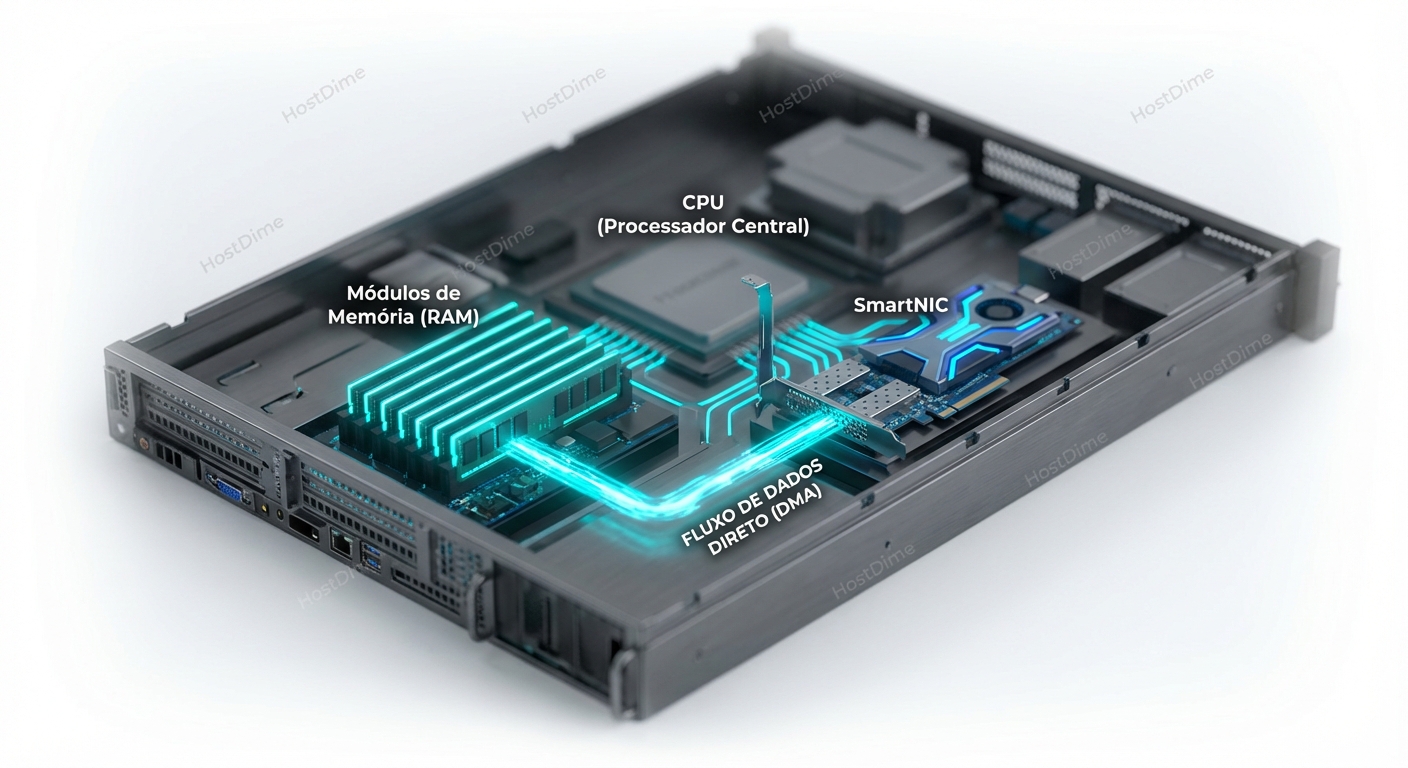
Rdma O Que E E Quando Faz Sentido
Para entender por que precisamos do RDMA, precisamos primeiro dissecar a ineficiência brutal de uma transferência de rede convencional....

ZFS Cache Arc L2Arc E Slog Explicados Sem Mitos
Esqueça o que você aprendeu com EXT4 ou NTFS. O ZFS não é apenas um sistema de arquivos; é um **gerenciador de memória agressivo** que, por acaso, grava dados e...

Mpio No Windows Como Planejar Caminhos Corretamente
Antes de falarmos de drivers e registros, precisamos alinhar o modelo mental....

Latência p95/p99: Por que a Média Engana
A latência média mente. Se você está gerenciando sistemas distribu�ídos, confiando apenas na latência média, está construindo sobre areia movediça. A latência mé...
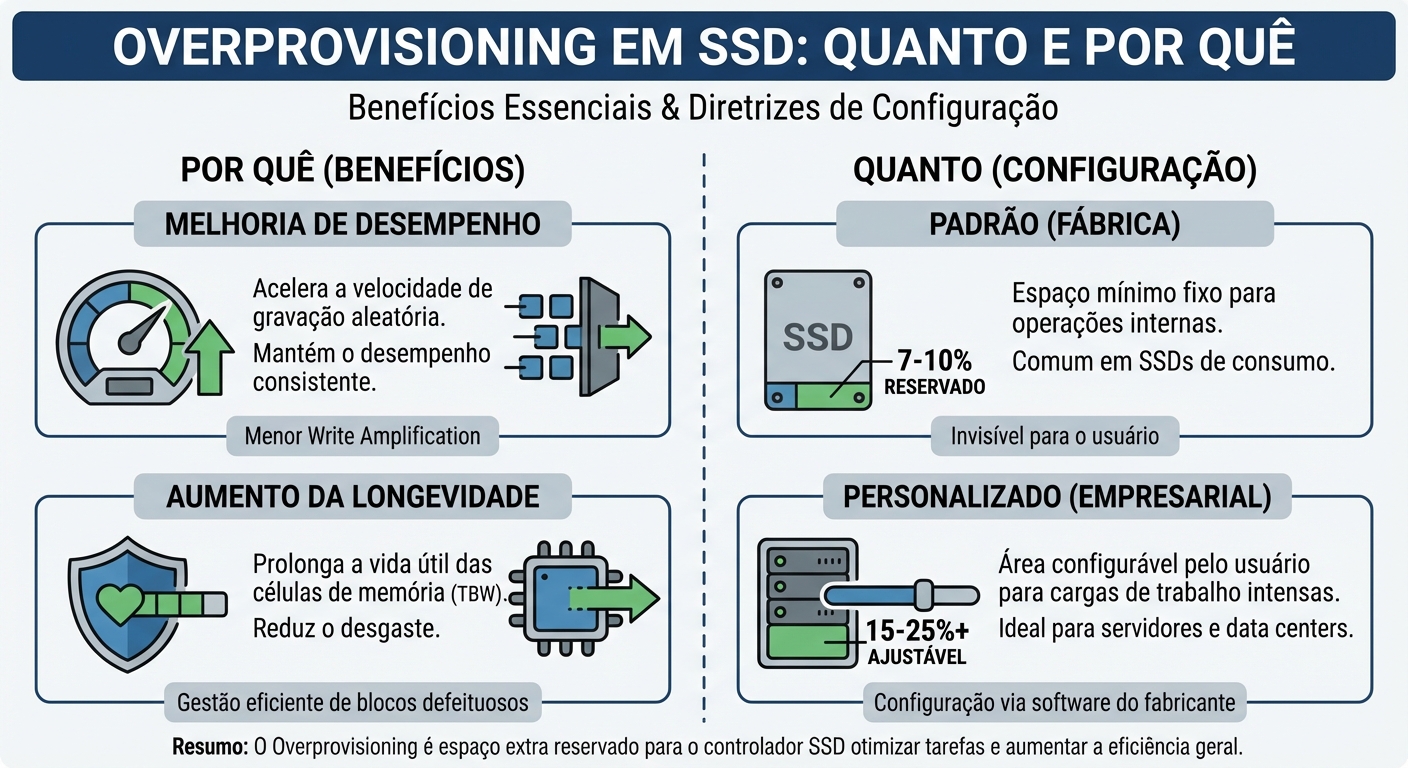
Overprovisioning em SSD: quanto e por quê
O problema: SSDs precisam de espaço livre para funcionar de forma eficiente e ter uma vida útil longa. Este espaço extra, não exposto ao utilizador, é chamado d...

RAID 10: Por que ele é o "Queridinho" em Produção
RAID 10, também conhecido como RAID 1+0, é um nível RAID que combina *striping* (RAID 0) e *mirroring* (RAID 1) para fornecer tanto alta performance quanto redu...

DAS vs NAS vs SAN vs SDS: O Guia Definitivo para Armazenamento de Dados
Como sysadmins, SREs e engenheiros de infraestrutura, uma das decisões mais cruciais que tomamos é: onde guardar os dados? Parece simples, mas a escolha da arqu...
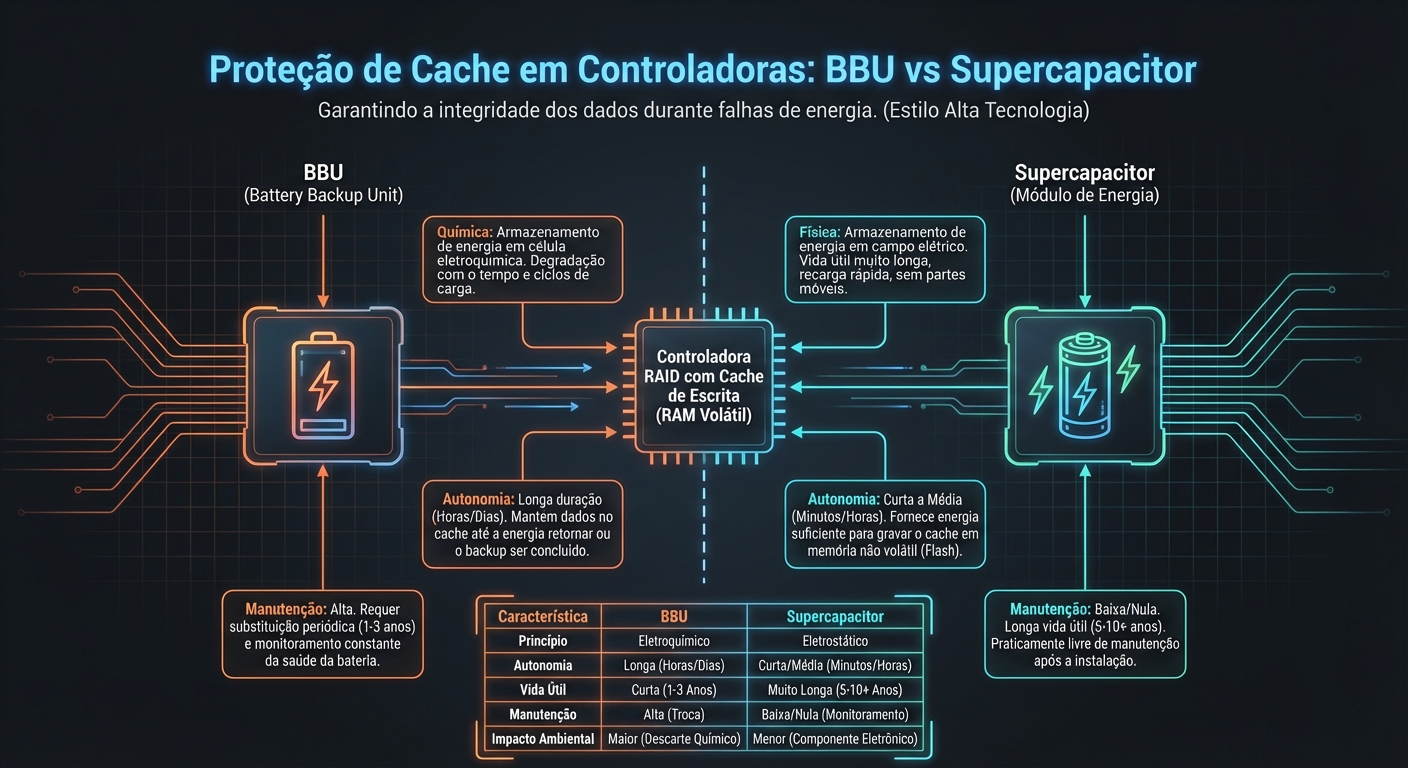
Bbu Vs Supercapacitor Protecao De Cache Em Controladoras
A proteção de cache em controladoras RAID é crucial para garantir a integridade dos dados em caso de falha de energia inesperada. Sem proteção, dados em cache ...

Ceph Deep Dive A Matematica Forense Do Algoritmo Crush
Encontramos o sistema paralisado por latência. O culpado é a tabela de alocação central, onipresente em arquiteturas de armazenamento tradicionais. Cada operaçã...