A Tempestade Perfeita do Storage em 2026: Quando a IA Quebrou a Cadeia de Suprimentos de NAND e HDD
Análise técnica da escassez de armazenamento prevista para 2026. Entenda como o ciclo de treinamento de IA colidiu com a estagnação da produção de wafers e como preparar sua infraestrutura.
O mercado de tecnologia passou a última meia década obcecado com a capacidade de computação. Quantos TFLOPS sua GPU H100 entrega? Qual o tamanho da janela de contexto do seu modelo? Enquanto os olhos estavam fixos no processamento, o chão estava cedendo sob os pés do armazenamento.
Em 2026, não estamos enfrentando apenas um aumento de preço; estamos vivendo uma ruptura fundamental na física da cadeia de suprimentos. A narrativa de que "storage é barato e infinito" morreu. Para o engenheiro de performance, isso significa que a era do super-provisionamento acabou. Agora, a eficiência de I/O não é apenas uma questão de latência, é uma questão de viabilidade econômica e operacional.
A Crise de Abastecimento de Storage de 2026 é o fenômeno econômico e técnico resultante do descolamento entre a demanda exponencial de dados gerada por IA (Training Checkpoints e Vector Embeddings) e a capacidade linear de fabricação de Wafers de NAND e cabeças de gravação magnética. Caracteriza-se pelo fim da paridade de preço SSD/HDD, aumento drástico nos lead times e a necessidade de re-arquitetura de software para compressão e tiering agressivo.
A Anatomia do Colapso da Cadeia de Suprimentos de NAND
Para entender por que você não consegue comprar NVMe Enterprise com o mesmo lead time de 2023, precisamos olhar para a convergência de fatores que criou esta tempestade. Não foi um único evento, mas uma trindade de pressões.
Primeiro, a consolidação dos fabricantes. O mercado de NAND se tornou um oligopólio apertado. Com margens espremidas nos anos anteriores, o investimento em novas fábricas (FABs) foi conservador. Segundo, o Ciclo de Renovação Enterprise. Os datacenters que compraram storage em massa durante o boom de 2020-2021 entraram em ciclo de substituição simultaneamente.
Mas o fator crítico é a Física da Litografia. A transição para camadas acima de 300-layers em 3D NAND não é trivial. A complexidade de empilhamento vertical reduz o yield (aproveitamento) por wafer.
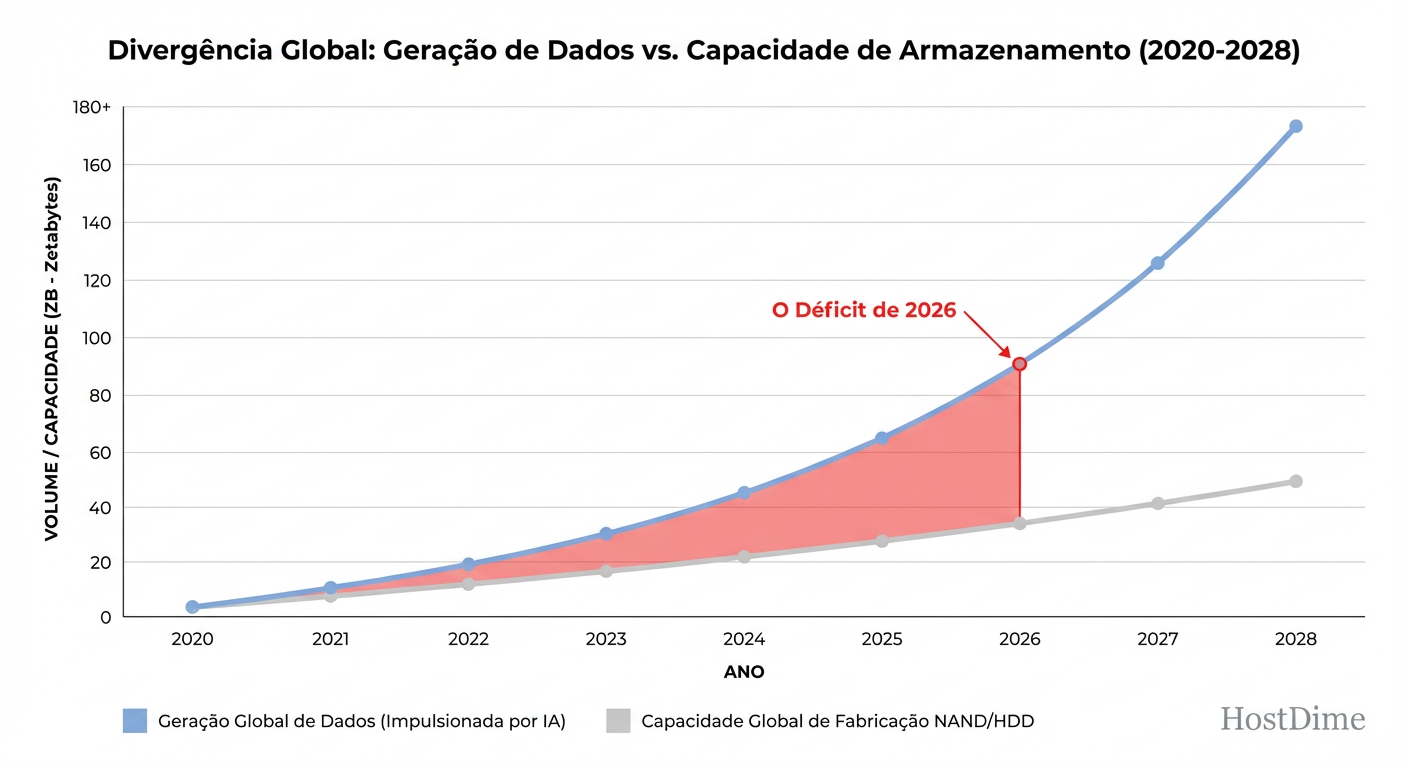 Figura: O Gap de Produção 2026: Onde a demanda exponencial da IA se descola da realidade física da fabricação de semicondutores.
Figura: O Gap de Produção 2026: Onde a demanda exponencial da IA se descola da realidade física da fabricação de semicondutores.
Como engenheiros, tendemos a pensar na nuvem como elástica. Mas a elasticidade de software é suportada pela rigidez do hardware. Construir uma nova FAB de semicondutores leva de 24 a 36 meses. A demanda de IA explodiu em 6 meses. Esse gap temporal é onde a escassez vive.
O "Data Gravity" da IA e o I/O Pattern Assassino
Há um erro comum ao tratar workloads de IA como se fossem bancos de dados transacionais (OLTP) ou analíticos (OLAP). Eles não são nenhum dos dois.
Em grandes modelos de linguagem (LLMs), o padrão de I/O mais destrutivo não é a ingestão de dados, mas o Checkpointing. Durante o treinamento, o estado do modelo precisa ser salvo frequentemente para evitar a perda de semanas de processamento em caso de falha da GPU.
Por que o Checkpoint mata o Storage
Imagine escrever o conteúdo inteiro da RAM de milhares de GPUs para o disco simultaneamente, a cada 10 ou 20 minutos. Isso gera um padrão de escrita sequencial massivo, saturando a largura de banda (Throughput) e, crucialmente, consumindo a vida útil (Endurance/DWPD) dos SSDs muito mais rápido do que cargas de trabalho tradicionais.
Além disso, temos o RAG (Retrieval-Augmented Generation). Bancos de dados vetoriais exigem leituras aleatórias de baixa latência em datasets que não cabem mais na RAM.
 Figura: O Ciclo de Vida do Dado na IA: Como o Checkpointing massivo destrói a durabilidade do NAND e infla a necessidade de HDDs.
Figura: O Ciclo de Vida do Dado na IA: Como o Checkpointing massivo destrói a durabilidade do NAND e infla a necessidade de HDDs.
Se você monitorar apenas IOPS, perderá a visão real do problema. O gargalo aqui é o sustained write throughput e a latência de cauda (p99) durante esses bursts de escrita.
A Ilusão da Elasticidade e a Realidade dos Wafers
Acreditar que a cadeia de suprimentos vai se ajustar "em breve" é ignorar a física. A produção de Wafers de silício e, especificamente, a fabricação de cabeças de leitura para HDDs de alta densidade (tecnologias HAMR/MAMR), são processos de precisão atômica.
Não se pode simplesmente "acelerar" a linha de produção. Aumentar a densidade de bits por polegada quadrada (areal density) em HDDs exige novos materiais magnéticos e lasers térmicos nas cabeças de gravação. A taxa de falha na produção dessas novas tecnologias ainda é alta, mantendo a oferta restrita.
Para o engenheiro de performance, a lição é clara: o hardware que você tem hoje é o hardware que você deve otimizar. Esperar que o procurement resolva o problema de capacidade comprando mais discos é uma estratégia de alto risco.
HDD vs SSD no Cenário de 2026: O Retorno do Cold Storage
Por anos, analistas preveram o "crossover point" onde o preço do SSD por TB cairia abaixo do HDD, matando o disco mecânico. Em 2026, essa previsão falhou espetacularmente. A demanda voraz por NAND para dispositivos de borda e cache de IA manteve os preços dos SSDs altos.
Isso forçou uma bifurcação no design de infraestrutura:
| Característica | SSD NVMe Enterprise (2026) | HDD High-Capacity (22TB+ HAMR) |
|---|---|---|
| Custo/TB | Alto (Premium) | Baixo (Ainda a base da pirâmide) |
| Latência | Microsegundos (< 100µs) | Milisegundos (mecânica) |
| Caso de Uso IA | Hot Cache, Vector Index, Checkpointing Buffer | Data Lake, Raw Training Data, Archival |
| Risco Principal | Endurance (DWPD esgotado rápido) | Rebuild Time (RAID rebuilds de dias) |
| Disponibilidade | Escassa (Lead times de meses) | Moderada |
O HDD não morreu; ele se tornou a única opção viável para a escala de Petabytes que a IA exige, desde que você tenha uma camada de tiering inteligente na frente dele.
Métricas de Sobrevivência: O que Medir Agora
Esqueça as métricas de "folha de especificações". O fabricante diz que o disco faz 1 milhão de IOPS. Isso é em 4k random read, queue depth 128. Seu workload faz isso? Provavelmente não.
Para sobreviver à tempestade de 2026, você precisa medir a realidade:
Latência de Entrega (Lead Time): Monitore isso como uma métrica de infraestrutura. Se o lead time subir de 2 para 12 semanas, sua política de retenção de dados precisa mudar hoje, não quando o disco encher.
DWPD Real vs. Marketing: Use ferramentas como
smartctlpara monitorar o desgaste real dos SSDs. Workloads de IA queimam células NAND.Sustained Write Throughput: Muitos SSDs têm um cache SLC rápido. Quando ele enche, a performance cai para velocidades de HDD.
Como testar a realidade (Bash)
Não confie no throughput de pico. Teste o estado estável (steady state) após o cache encher.
# CUIDADO: Isso escreve dados reais e desgasta o disco. Não rode em produção.
fio --name=write_stress \
--filename=/dev/nvme0n1 \
--ioengine=libaio \
--rw=write \
--bs=1M \
--direct=1 \
--numjobs=4 \
--size=100G \
--runtime=300 \
--group_reporting
Observe se a velocidade cai drasticamente após os primeiros 30-60 segundos. Esse é o seu throughput real.
Estratégias de Mitigação: Engenharia acima de Compras
Se você não pode comprar mais, deve usar melhor. A mitigação em 2026 é puramente engenharia de software e sistemas de arquivos.
1. Compressão Agressiva (Zstd)
CPU é (relativamente) mais abundante que I/O rápido. Utilize algoritmos de compressão modernos como Zstd em nível de filesystem (ZFS, Btrfs) ou aplicação. O Zstd oferece taxas de compressão próximas ao xz com performance de descompressão próxima ao lz4.
Em datasets de texto para treinamento de LLM, taxas de compressão de 3:1 ou 4:1 são comuns. Isso triplica seu storage efetivo sem comprar um único disco.
# Exemplo: Habilitando compressão Zstd no ZFS
zfs set compression=zstd-3 tank/ai-dataset
2. Tiering Inteligente
Mova dados agressivamente. Dados de treinamento que não foram acessados nas últimas 48 horas não devem estar em NVMe. Use ferramentas ou políticas de Lifecycle (S3, Ceph) para mover dados frios para HDDs ou Cold Storage imediatamente.
3. Reavaliação de Políticas de Retenção
A pergunta difícil: "Precisamos mesmo guardar todos os checkpoints intermediários?". A resposta técnica muitas vezes é não. Reter apenas os checkpoints convergentes e descartar os estados intermediários pode reduzir o consumo de storage em 60-70%.
Veredito Técnico: O Novo Normal
A tempestade de storage de 2026 não é passageira. É um reequilíbrio estrutural. A era do armazenamento barato mascarou códigos ineficientes e arquiteturas preguiçosas. Agora, com a IA pressionando a cadeia de suprimentos física, o valor do engenheiro de performance que entende o caminho do dado — do transistor NAND ao filesystem — nunca foi tão alto.
Pense no custo do bit. Meça o I/O sustentado. Decida com base na física, não no hype.
Referências & Leitura Complementar
OCP (Open Compute Project) Storage Specifications: Para entender os padrões de hardware hyperscale.
SNIA (Storage Networking Industry Association) Solid State Storage Performance Test Specification (PTS): Metodologia padrão ouro para testes de SSD.
"Systems Performance: Enterprise and the Cloud" (Brendan Gregg): A bíblia para metodologias de análise de performance.
Zstandard (Zstd) Benchmark Data: Documentação oficial do Facebook/Meta sobre o algoritmo de compressão.
Datasheets de Fabricantes (Micron/Seagate/WD): Procure especificamente por whitepapers sobre "HAMR technology" e "3D NAND layer stacking challenges".

Thomas 'Raid0' Wright
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.