A Tirania da Média: Por que seu Storage parece rápido mas trava a produção (e como o p99 resolve)
Pare de monitorar médias. Descubra como a latência de cauda (p99/p99.9) destrói a performance e aprenda a usar histogramas e heatmaps para ver a verdade.
O ticket chega às 03:00 da manhã. O alerta do Zabbix diz "High Application Latency". O DBA grita que o disco está lento. O desenvolvedor diz que a API está dando timeout.
Você loga no servidor, roda um iostat -x 1 e vê: r_await: 2.5ms. w_await: 1.8ms.
Você fecha o ticket: "Storage operando dentro dos parâmetros normais. Média de latência abaixo de 3ms. O problema é a aplicação."
Duas horas depois, o sistema cai.
Bem-vindo à cena do crime. Como investigador forense de sistemas, posso afirmar: a média aritmética é cúmplice desse assassinato. Ela não apenas esconde a verdade; ela fornece um álibi perfeito para discos que estão travando silenciosamente a sua operação.
Vamos dissecar por que seu monitoramento está mentindo para você e como encontrar a evidência real na cauda longa da distribuição.
O Crime da Média Aritmética
A intuição humana falha miseravelmente quando lidamos com I/O de disco porque tendemos a pensar que o comportamento do sistema é uniforme. Assumimos que, se a média é 2ms, a maioria das requisições levou algo perto de 2ms.
Isso é falso.
Imagine que, em um segundo, seu storage processou 100 requisições:
99 requisições foram servidas pelo cache do controlador: 0.1ms.
1 requisição teve que buscar dados em um bloco fragmentado num disco mecânico ou sofreu uma pausa de Garbage Collection num SSD: 200ms.
A matemática:
(99 * 0.1 + 200) / 100 = ~2.1ms
O dashboard mostra 2.1ms. Parece incrível. Mas para aquele usuário azarado (ou aquela thread de banco de dados segurando um lock), o sistema parou por 200ms. Se essa requisição lenta estiver segurando uma transação, todas as outras 99 requisições rápidas vão empilhar atrás dela na aplicação, não no disco.
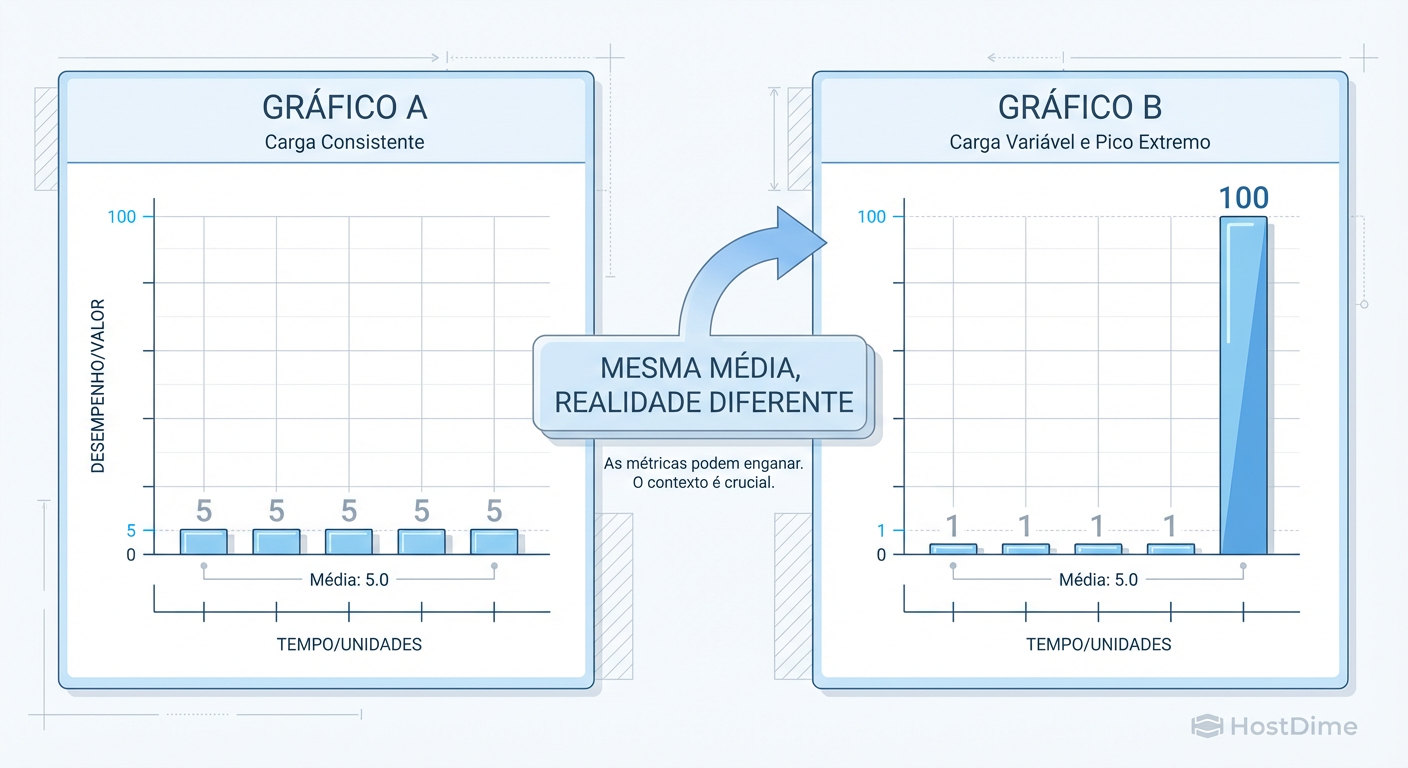 Figura: A ilusão estatística: Dois cenários com a mesma latência média, mas comportamentos operacionais opostos.
Figura: A ilusão estatística: Dois cenários com a mesma latência média, mas comportamentos operacionais opostos.
O monitoramento baseado em médias suaviza a realidade. Ele pega picos de latência que destroem a performance e os dilui num mar de operações rápidas, tornando o problema invisível até que seja tarde demais.
A Distribuição do I/O: Não é uma Curva de Sino
Se plotarmos a latência de disco num gráfico, esperamos ver uma Curva de Sino (Distribuição Normal), onde a maioria dos eventos acontece no meio.
Em Storage, a realidade é Multimodal. Geralmente temos dois ou três picos distintos:
Modo Rápido (Cache/DRAM): Respostas em microssegundos.
Modo Físico (NAND Flash/Platter): Respostas em milissegundos.
A Cauda Longa (Outliers): Respostas em centenas de milissegundos ou segundos (erros de CRC, retries de TCP no iSCSI, compactação do ZFS, wear leveling do SSD).
A "Média" tenta encontrar um ponto central entre o cache (rápido) e o disco (lento), resultando em um número que não representa nenhum dos dois cenários reais. É um número fantasma.
Investigação: Se o seu sistema tem cache (e todo sistema moderno tem, seja na RAM do SO, no controlador RAID ou no buffer do SSD), a média é matematicamente inútil para diagnóstico de performance.
A Matemática do Sofrimento: Entendendo Percentis
Para condenar o verdadeiro culpado, precisamos abandonar a média e usar Percentis. O percentil responde à pergunta: "Qual é a pior latência que X% dos meus usuários estão experimentando?"
Aqui está a tradução forense dos termos:
| Métrica | O que ela significa na prática | Quem se importa? |
|---|---|---|
| p50 (Mediana) | O caso típico. Metade das requisições são mais rápidas que isso. | O Marketing (para vender o produto). |
| p90 | 1 em cada 10 requisições é pior que isso. | O Gerente de Produto. |
| p99 | 1 em cada 100 requisições é pior que isso. | O Engenheiro de SRE / DBA. Aqui vivem os travamentos. |
| p99.99 | 1 em cada 10.000 requisições. A "Cauda Longa". | Sistemas de Alta Frequência (HFT) e Bancos de Dados críticos. |
Se o seu p50 é 1ms, mas seu p99 é 500ms, seu storage não é rápido. Ele é inconsistente. E em produção, consistência é mais importante que velocidade bruta. Um banco de dados prefere uma latência constante de 5ms do que uma que oscila entre 0.1ms e 500ms.
O Efeito Composto: O Assassino de Microserviços
"Ah, mas p99 é apenas 1% das requisições. Posso ignorar."
Não, não pode. Especialmente se você opera arquiteturas modernas. O p99 de um componente de infraestrutura se torna o p50 da experiência do usuário final devido à probabilidade composta.
Imagine uma página web que, para carregar, precisa chamar 10 microserviços (ou fazer 10 queries no banco). Cada serviço depende do storage. Se o storage tem uma chance de 1% (p99) de ser lento:
A probabilidade de a página inteira ser rápida é:
0.99 * 0.99 * ... (10 vezes) ≈ 0.90
Isso significa que 10% de todos os carregamentos de página serão lentos. Se a página exigir 50 queries, 40% dos usuários sofrerão com a lentidão.
Em sistemas distribuídos, a latência da cauda (tail latency) determina a performance global. O p99 do disco dita a performance da aplicação.
Além do iostat: A Ilusão da Amostragem
Por que ferramentas clássicas como iostat ou sar falham nessa investigação? Porque elas trabalham com médias de intervalo.
Quando você roda iostat -x 1, o Linux coleta contadores do kernel a cada segundo e divide pelo tempo decorrido. Se um SSD trava por 250ms para fazer um garbage collection interno, mas processa milhares de requisições nos 750ms restantes, a média daquele segundo ainda parecerá aceitável.
O iostat nos dá uma visão de "baixa resolução". É como olhar para uma floresta de longe: você vê o verde (a média), mas não vê a árvore pegando fogo (o pico de latência).
Para ver a verdade, precisamos de Histogramas e Heatmaps.
 Figura: Heatmap de Latência: Onde o
Figura: Heatmap de Latência: Onde o iostat vê uma linha reta, o heatmap revela os outliers que causam timeouts.
O Heatmap de latência (acima) revela o que a média esconde. O eixo vertical é a latência, o horizontal é o tempo. As cores indicam a densidade de requisições.
A linha sólida na base? É o seu p50 (rápido).
Aquelas nuvens ou pontos no topo? São os p99 e p99.9 (lentos).
Onde o
iostatvê uma linha reta, o heatmap mostra a tempestade.
Como Medir a Verdade (Ferramentas)
Para sair do "achismo" e ir para a evidência, você precisa de ferramentas que capturem cada evento de I/O individualmente, classifiquem em "buckets" de latência e gerem um histograma.
Hoje, a melhor forma de fazer isso no Linux é usando eBPF (Extended Berkeley Packet Filter). Ferramentas baseadas em eBPF têm custo de performance quase nulo e visibilidade total.
A Ferramenta: biolatency / biosnoop
Parte do pacote bcc-tools ou iovisor.
Em vez de uma média, o biolatency captura a distribuição real do tempo que o disco leva para responder.
# Exemplo de investigação em tempo real (requer bcc-tools instalado)
# Medindo a latência de I/O de bloco por 10 segundos
sudo biolatency-bpfcc -m 10 1
A saída será um histograma textual:
msecs : count distribution
0 -> 1 : 1820 |************************************|
2 -> 3 : 40 | |
4 -> 7 : 2 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 5 | |
128 -> 255 : 12 |* |
Análise Forense:
Observe o exemplo acima. A maioria está abaixo de 1ms. Ótimo. Mas veja o final: temos 12 requisições entre 128ms e 255ms.
Se o iostat mostrasse a média, diria "1ms". O biolatency mostra: "Você teve 12 eventos que provavelmente causaram timeouts na aplicação".
Esses 12 eventos são a causa raiz. Agora você pode correlacionar o horário exato desses picos com os logs do banco de dados ou da aplicação.
Veredito: Definindo SLAs Reais
Como profissional de storage ou admin de sistemas, pare de prometer médias. A média é uma promessa que você não controla e que não reflete a dor do usuário.
A Nova Postura:
Monitore o p99 e p99.9: Configure seus alertas (Prometheus, Datadog, Zabbix) para disparar baseados em percentis, não em médias.
SLA de Consistência: Seu SLA de armazenamento deve ser: "99% das requisições serão servidas em menos de 10ms", e não "A latência média será de 2ms".
Investigue os Outliers: Quando a performance cair, não olhe para a linha base. Procure o que mudou na "cauda". Foi um backup? Um rebuild de RAID? Throttling do provedor de nuvem?
A estabilidade de um sistema não é definida por quão rápido ele é quando tudo vai bem, mas por quão pouco ele degrada quando as coisas ficam difíceis. Abandone a tirania da média. A verdade vive nos extremos.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.