AIOps em Storage: A Realidade Técnica da Automação e Previsão de Falhas em 2026

Cansado de apagar incêndios? Descubra como o AIOps evoluiu de buzzword para necessidade técnica em 2026, automatizando tiering preditivo e análise de falhas sem o marketing vazio.
Vamos ser honestos: a promessa de uma infraestrutura que "se conserta sozinha" circula nos corredores de TI há décadas. Se você está na área há tempo suficiente, já viu ondas de marketing prometendo o nirvana e entregando apenas scripts de Perl glorificados. Mas estamos em 2026, e a paisagem mudou. O AIOps (Artificial Intelligence for IT Operations) em Storage deixou de ser um slide de PowerPoint para se tornar uma necessidade matemática.
Não porque a IA se tornou senciente, mas porque a densidade de dados e a complexidade das arquiteturas distribuídas ultrapassaram a capacidade cognitiva humana de correlacionar logs. Você não consegue mais analisar 5.000 drives NVMe individualmente. O foco aqui não é o hype, é a sobrevivência operacional. Vamos dissecar o que funciona, o que é fumaça e como medir a diferença.
O que é AIOps em Storage? AIOps em Storage é a aplicação de aprendizado de máquina sobre metadados de telemetria (latência, IOPS, temperatura, erros de paridade) para automatizar o tiering de dados, prever falhas de hardware antes dos alertas SMART e ajustar dinamicamente o QoS, transformando a administração de armazenamento de uma tarefa reativa de "apagar incêndios" para uma governança proativa baseada em padrões de comportamento.
O Fim do Administrador Reativo e a Nova Camada de Abstração
Até meados de 2020, o trabalho de um administrador de storage envolvia uma quantidade obscena de "babysitting" de LUNs. Você provisionava, monitorava o crescimento, expandia volumes manualmente e rezava para o controlador de cache não saturar durante o backup da madrugada.
A realidade técnica do AIOps em 2026 removeu a necessidade de microgerenciamento de spindles (ou células NAND). O sistema não olha mais para o disco como a unidade atômica de gerenciamento; ele olha para o SLA da aplicação.
A mudança fundamental aqui é a inversão do fluxo de trabalho. Em vez de você dizer ao storage "mova este volume para o SSD porque o banco de dados está lento", o storage diz a você: "Movi este volume para o SSD há 2 horas porque detectei um padrão de leitura sequencial que ocorre toda última sexta-feira do mês". Se você ainda está acordando às 3 da manhã para resolver problemas de performance que poderiam ter sido previstos, sua infraestrutura é burra, não importa quão caro foi o hardware.
A Matemática do Tiering Preditivo e a Obsolescência do LRU
Durante anos, vivemos sob a tirania do algoritmo LRU (Least Recently Used). A lógica era simples e computacionalmente barata: "Se você não usou este arquivo recentemente, ele vai para o disco lento".
O problema do LRU é que ele é cego ao contexto. Ele não sabe a diferença entre um scan de antivírus (que toca em tudo uma vez e nunca mais volta) e um relatório financeiro crítico que é acessado apenas uma vez por trimestre, mas exige latência zero quando solicitado.
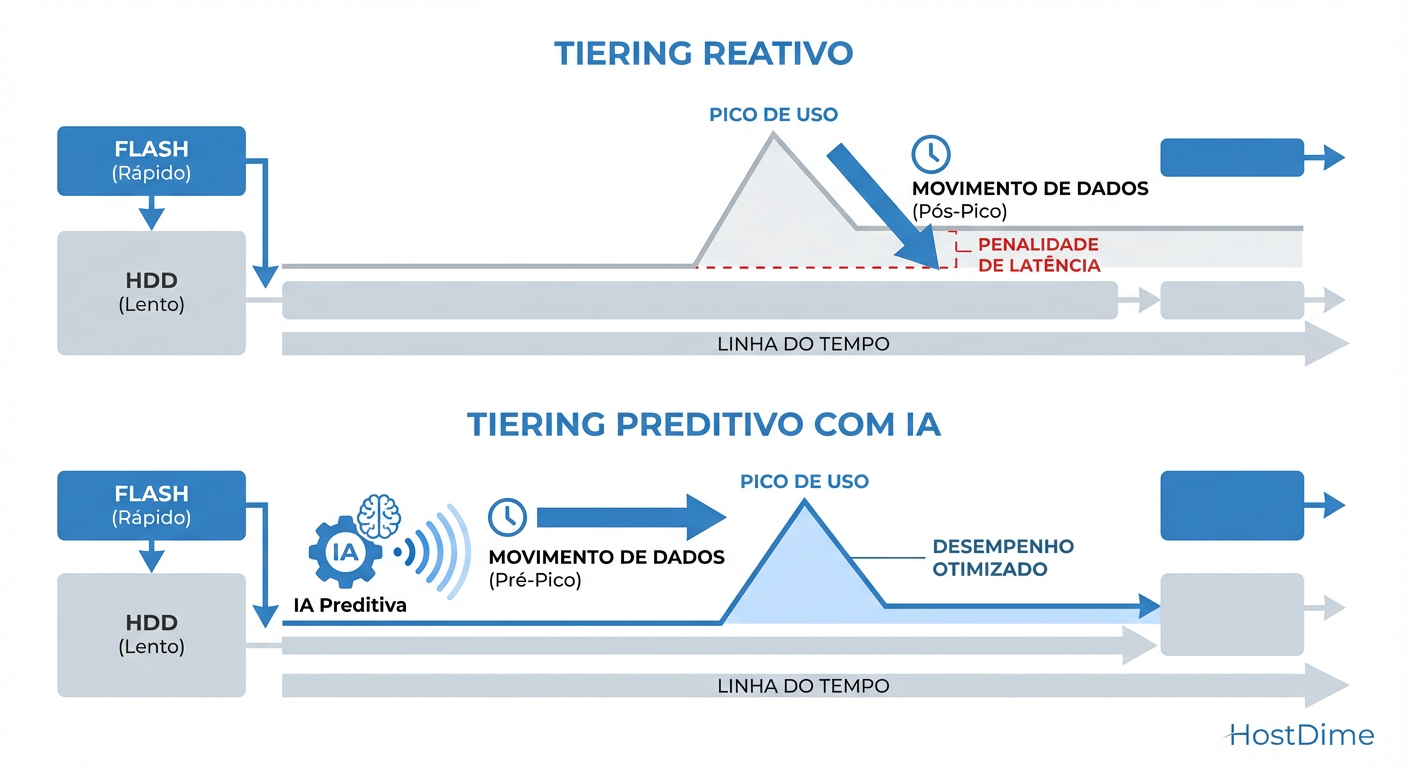 Figura: Tiering Reativo vs. Preditivo: A diferença entre sofrer latência e antecipar a demanda.
Figura: Tiering Reativo vs. Preditivo: A diferença entre sofrer latência e antecipar a demanda.
O Tiering Preditivo moderno utiliza modelos de regressão e redes neurais recorrentes (RNNs) para entender a sazonalidade e a intenção.
Como o Tiering Preditivo funciona na prática:
Impressão Digital de I/O: O sistema analisa o tamanho do bloco, a aleatoriedade (random vs. sequential) e a proporção de Leitura/Escrita.
Contextualização Temporal: Ele correlaciona esses dados com horários. O boot storm da VDI às 08:00 é previsível. O fechamento contábil é previsível.
Pré-aquecimento (Pre-fetching): O dado é movido para a camada de Performance (NVMe/SCM) antes da requisição ocorrer.
Se o seu storage espera a latência subir para então mover o dado (Tiering Reativo), você já falhou no SLA. A latência é o sintoma da doença; o tiering preditivo é a vacina.
Previsão de Falhas de Hardware em 2026: Correlação Multivariada
O protocolo SMART (Self-Monitoring, Analysis and Reporting Technology) serviu bem ao seu propósito, mas é fundamentalmente falho para a era moderna. O SMART é baseado em limiares estáticos. Se o número de setores realocados passar de X, ele grita. O problema é que, muitas vezes, quando o SMART dispara, a degradação de performance já está ocorrendo há semanas, ou o disco morre subitamente sem atingir o limiar "oficial".
A realidade técnica hoje exige Análise Multivariada. Um disco não falha isoladamente; ele emite sinais sutis em múltiplos vetores simultaneamente.
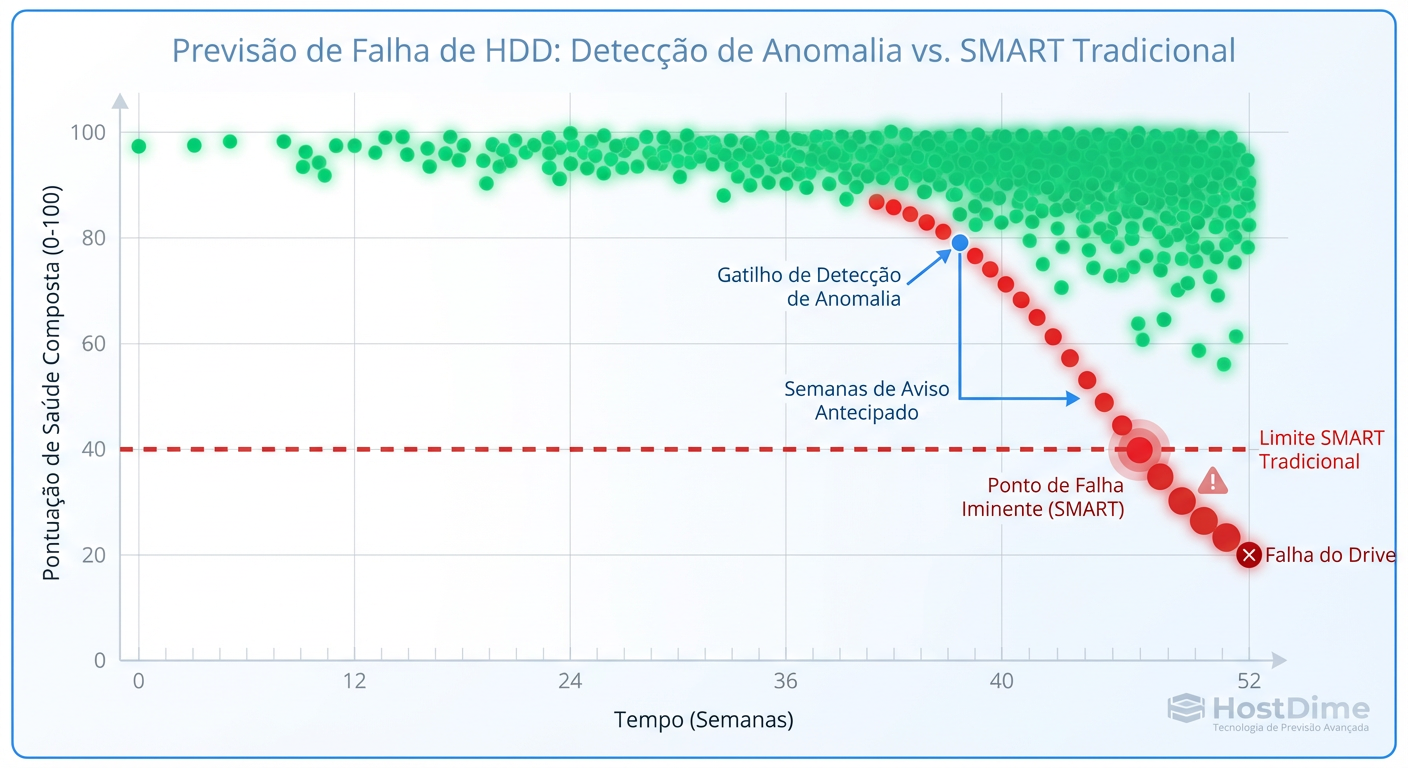 Figura: Análise Multivariada: Detectando a degradação silenciosa antes que o SMART dispare o alerta crítico.
Figura: Análise Multivariada: Detectando a degradação silenciosa antes que o SMART dispare o alerta crítico.
Tabela Comparativa: Monitoramento Tradicional vs. AIOps Preditivo
| Característica | Monitoramento Tradicional (SMART/SNMP) | AIOps Preditivo (Machine Learning) |
|---|---|---|
| Gatilho de Alerta | Limiar estático (ex: Temp > 50°C) | Desvio de padrão (Anomalia) |
| Variáveis Analisadas | Isoladas (Uma métrica por vez) | Correlacionadas (Temp + Latência + Erros CRC) |
| Tempo de Reação | Pós-incidente ou Iminente | Semanas antes da falha catastrófica |
| Falsos Positivos | Baixos, mas com muitos "Falsos Negativos" | Requer treinamento para evitar ruído |
| Detecção de "Gray Failures" | Quase nula (Hardware funciona, mas lento) | Alta (Detecta degradação de performance) |
As "Gray Failures" (Falhas Cinzentas) são o pesadelo do Sysadmin. O componente não está "morto", mas está lento o suficiente para derrubar a aplicação, e o sistema de HA (Alta Disponibilidade) não faz o failover porque o componente ainda responde ao ping. AIOps detecta a correlação entre o aumento de micro-latência e pequenas flutuações de voltagem, isolando o componente antes que ele contamine o cluster.
Otimização de QoS e Latência em Tempo Real via Algoritmos
Humanos são péssimos em gerenciar QoS (Quality of Service) dinâmico. Nós configuramos limites estáticos ("App X tem limite de 1000 IOPS") e esquecemos. O resultado? Capacidade ociosa desperdiçada ou gargalos artificiais.
Em 2026, o controle de fluxo é algorítmico. O sistema de storage deve ser capaz de identificar um "vizinho barulhento" (ex: um job de backup mal configurado) e aplicar throttling nele em milissegundos para proteger a latência do banco de dados de produção, liberando a banda assim que o pico de produção passar.
Isso não é feito via regras if-then-else simples. É um problema de otimização contínua. O sistema avalia: "Se eu der mais 10% de fila para a VM 'A', qual é a probabilidade da latência da VM 'B' exceder 5ms?". Se a resposta for alta, a VM 'A' espera.
Os Riscos de Privacidade de Telemetria e Vendor Lock-in
Aqui entra o ceticismo necessário. Para que o AIOps funcione, ele precisa de dados. Muitos dados. A maioria dos vendors modernos (seja Pure, NetApp, Dell, HPE) exige que seus arrays enviem telemetria constante para a nuvem do fabricante (Phone Home turbinado).
O argumento é válido: eles usam dados anonimizados de milhares de clientes para treinar o modelo global. Se um lote de SSDs falha na Ásia devido a um firmware específico, o sistema aprende e alerta você no Brasil para atualizar o firmware antes que falhe. Isso é o "Efeito de Rede".
Mas existe um custo oculto:
Vazamento de Metadados: Mesmo anonimizados, padrões de acesso podem revelar volumes de negócios ou horários críticos de operação.
O Derradeiro Lock-in: A inteligência não está no seu hardware, está na nuvem do vendor. Se você decidir trocar de fabricante, você não perde apenas o "ferro", você perde anos de histórico de aprendizado sobre sua carga de trabalho. O novo storage começará "burro".
Dependência de Conectividade: Alguns recursos de otimização dependem da comunicação com a nuvem de controle. Em ambientes air-gapped (isolados da internet), o AIOps muitas vezes se torna um "dumb script".
Como Validar Ferramentas de AIOps com Métricas Reais
Não confie no dashboard do fabricante que diz "Economizei 100 horas do seu tempo". Isso é métrica de vaidade. Para validar se a automação está funcionando, você precisa medir o resultado na ponta da aplicação.
Checklist de Validação Técnica:
Consistência de Latência (Jitter): A média de latência importa pouco. O que mata a aplicação é o desvio padrão (P99). O AIOps deve "achatar" a curva de latência, eliminando picos.
Taxa de Intervenção Humana: Quantos tickets de performance de storage você abriu nos últimos 6 meses comparado ao período anterior? Se o número é o mesmo, a ferramenta é inútil.
Teste de "Vizinho Barulhento": Crie um cenário de estresse controlado e veja se o sistema protege a carga de trabalho crítica sem sua intervenção.
Se você tiver acesso a um ambiente de homologação, use ferramentas como fio para gerar carga e medir se o QoS dinâmico realmente atua.
Exemplo conceitual de teste de estresse (O que observar): Não basta rodar o comando. Você deve rodar uma carga crítica (simulada) e, em paralelo, iniciar uma carga agressiva de escrita sequencial.
# NÃO execute em produção. Apenas para ilustração de lógica de teste.
# Carga "Agressora" (Vizinho Barulhento)
fio --name=agressor --rw=write --bs=1M --size=10G --numjobs=4 --iodepth=32 ...
# O que medir na Carga "Vítima" (Aplicação Crítica):
# O AIOps deve detectar o "agressor" e aumentar a latência DELE,
# mantendo a "vítima" estável.
Se o storage permitir que a latência da sua aplicação crítica dobre durante o teste, a "Inteligência Artificial" falhou na sua única tarefa real: arbitragem de recursos escassos.
Veredito Técnico
O AIOps em storage não é mágica, é estatística aplicada em escala industrial. Ele permite operar infraestruturas massivas com equipes enxutas, mas exige que você abandone o controle microscópico em troca de supervisão de políticas. Abrace a tecnologia para dormir melhor à noite, mas mantenha um olho cético nos dados que saem da sua rede e outro nas métricas de latência do lado do cliente. Confie, mas verifique.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): "Artificial Intelligence and Machine Learning in Storage" - Whitepapers sobre definições de taxonomia.
Google Research: "Failures in Large-Scale Storage Systems" - Estudos seminais sobre correlação de falhas de disco (precursores do AIOps moderno).
USENIX FAST (File and Storage Technologies): Proceedings anuais sobre avanços em algoritmos de tiering e predição de falhas.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.