Alua O Que E E Por Que Importa

Para entender o ALUA, primeiro precisamos destruir uma mentira confortável que o sistema operacional conta para si mesmo: a de que todos os cabos são iguais....
Alua O Que E E Por Que Importa
A Ilusão da Simetria
Para entender o ALUA, primeiro precisamos destruir uma mentira confortável que o sistema operacional conta para si mesmo: a de que todos os cabos são iguais.
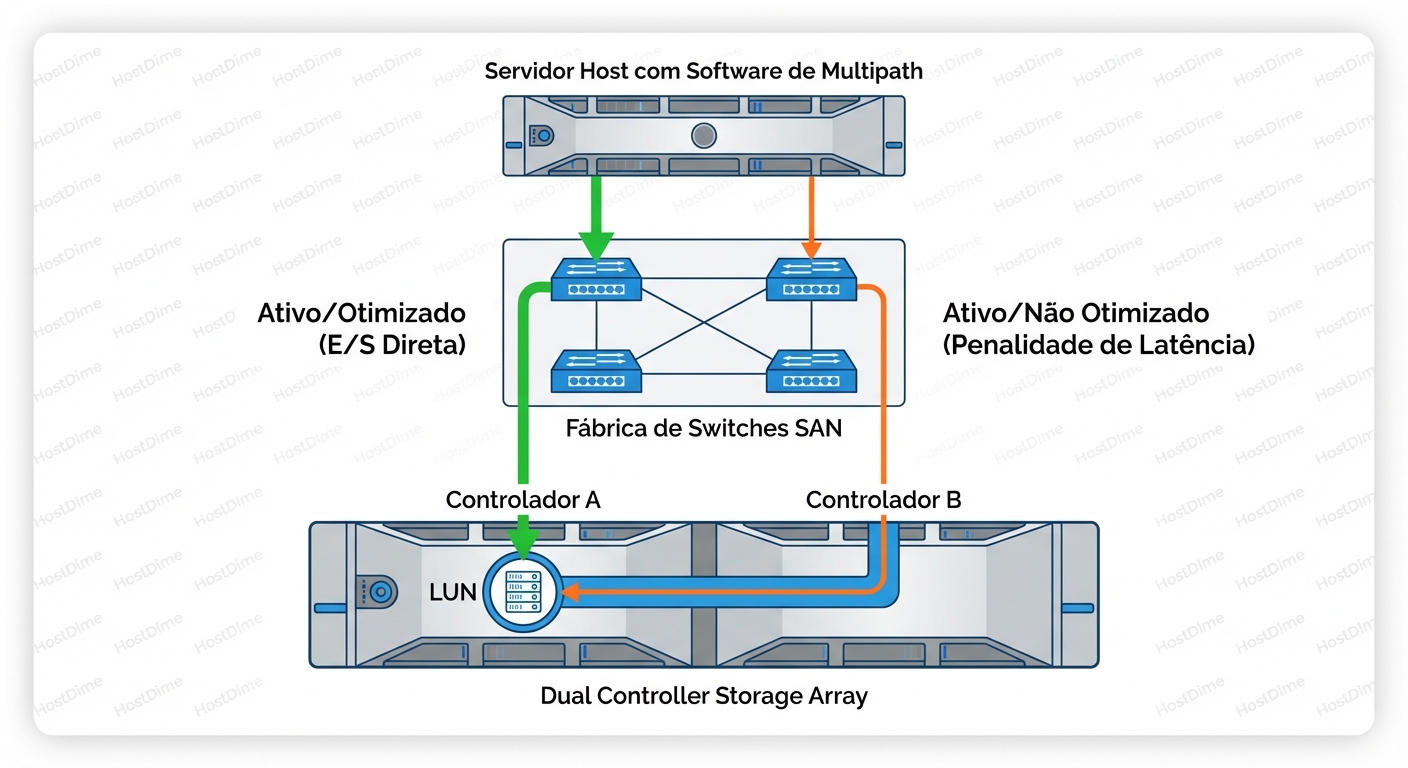
Quando você conecta um servidor a um Storage Array moderno (digamos, um Dell PowerStore, um HPE Nimble ou um NetApp), você geralmente conecta dois cabos HBA a dois switches, que se conectam a duas controladoras no storage (Controladora A e Controladora B). O seu software de multipath (DM-Multipath no Linux, MPIO no Windows, NMP no ESXi) vê quatro caminhos para o mesmo disco (LUN).
Na sua cabeça, e na configuração padrão "ingênua", esses quatro caminhos são idênticos. É como ter quatro portas para entrar no mesmo supermercado. Tanto faz por onde você entra, certo?
Errado.
A maioria dos arrays de armazenamento de médio porte não são verdadeiramente simétricos. Eles são Assimétricos.
Imagine que a LUN do seu banco de dados (os dados reais, os bits magnéticos ou flash) é "propriedade" da Controladora A. A Controladora A tem os mapas de memória, o cache de escrita e o controle direto sobre os SSDs para aquele volume específico.
Se você enviar uma solicitação de escrita para a Controladora A, o processo é:
- O dado chega na porta da Controladora A.
- A Controladora A escreve no cache.
- A Controladora A confirma para o host (ACK). Tempo total: 0.2ms.
Agora, o que acontece se o seu servidor, por uma política de balanceamento de carga "Round Robin" mal configurada, decidir enviar o próximo pacote de dados para a Controladora B?
A Controladora B recebe o dado. Mas ela não é a dona da LUN. Ela não pode escrever direto no disco sem corromper o estado que a Controladora A gerencia. Então o fluxo muda drasticamente:
- O dado chega na porta da Controladora B.
- A Controladora B percebe que não é a dona.
- A Controladora B empacota esse pedido e o envia através de um link interno (interconnect/backplane) para a Controladora A.
- A Controladora A processa.
- A Controladora A responde para a B.
- A Controladora B responde para o host.
Tempo total: 0.5ms a 5ms (dependendo da carga do interconnect).
Esse tráfego extra é o "Pedágio de Latência". E é aqui que o ALUA entra. O ALUA não é uma tecnologia de hardware, é o protocolo, a linguagem que permite ao storage dizer ao servidor: "Ei, eu sou a Controladora B. Eu posso aceitar seus dados, mas vai doer. Por favor, fale com a Controladora A."
O Vocabulário do SCSI: TPGS
Para o Sysadmin, "ALUA" é o conceito. Para o kernel do Linux ou Windows, ALUA é implementado através de algo chamado TPGS (Target Port Group Support).
Quando o servidor inicializa e faz o scan dos discos, ele envia comandos SCSI padrão (INQUIRY). Se o storage suporta ALUA, ele responde com um mapa muito específico. Ele agrupa suas portas em Target Port Groups (TPGs) e atribui um estado a cada grupo.
Não é binário (Up/Down). É um gradiente de preferência. Os estados mais comuns que você verá no diagnóstico são:
- Active/Optimized (AO): Este é o caminho dourado. A porta leva diretamente à controladora que possui a LUN. O desempenho é máximo.
- Active/Non-Optimized (ANO): A porta está funcional, o link está up, e I/O será aceito. Mas, ele terá que atravessar o interconnect interno do storage. Use apenas se todos os caminhos AO estiverem mortos.
- Standby: A porta não aceita I/O de leitura/escrita, apenas comandos de gerenciamento. Se você tentar enviar dados aqui, receberá um erro, forçando o host a fazer failover.
- Unavailable: O caminho está fisicamente conectado, mas logicamente inoperante por enquanto.
A Dança do Failover
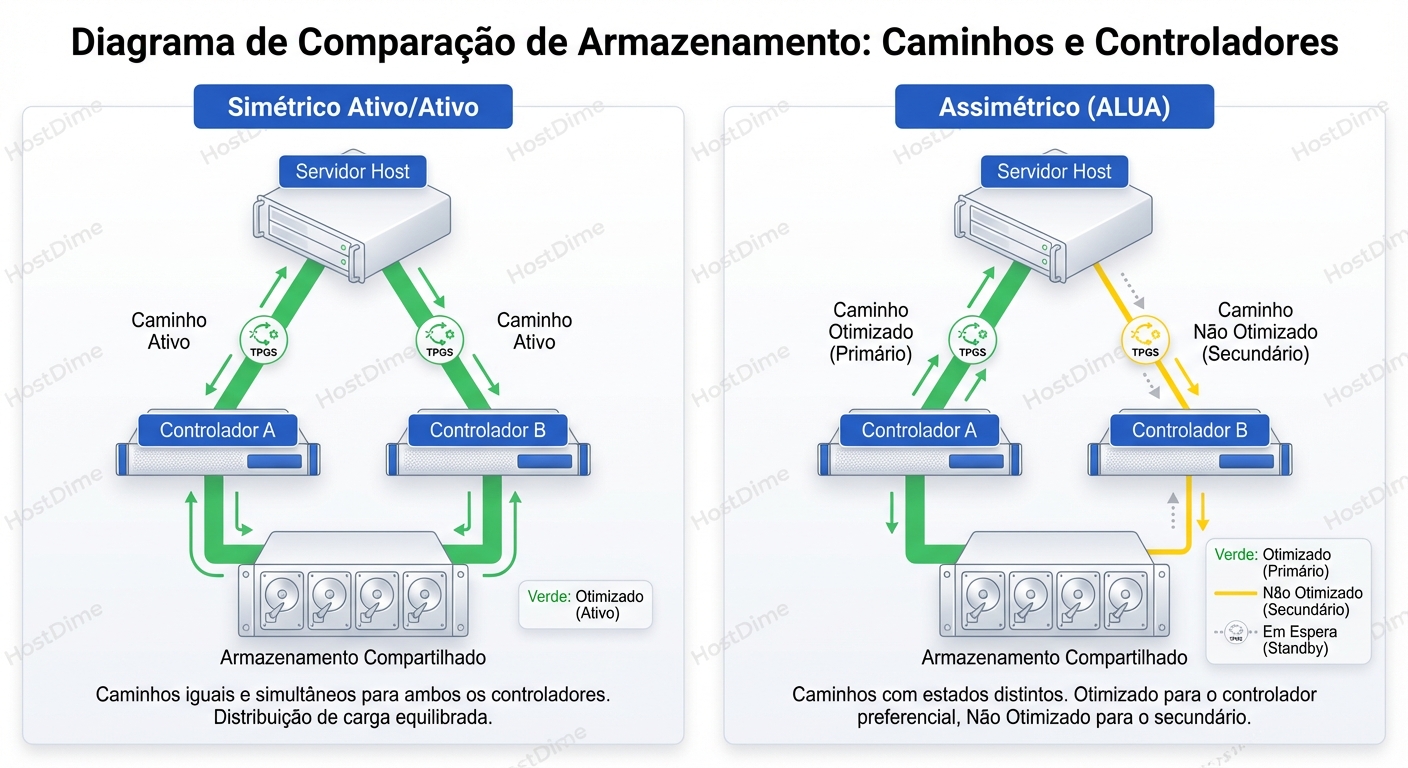
Aqui está a beleza (e o perigo) do sistema. Em um array puramente "Active/Passive" antigo, se você tentasse falar com a controladora passiva, tomaria um erro de I/O na cara. O caminho estaria morto até que um failover ocorresse.
Com ALUA (Asymmetric Active/Active), o caminho Non-Optimized está vivo. Isso é ótimo para redundância instantânea. Se alguém tropeçar no cabo de fibra da Controladora A, o I/O flui instantaneamente para a Controladora B sem erros de I/O para a aplicação. A latência sobe, mas o banco de dados não cai.
O problema surge quando o seu software de multipath não respeita esses estados e começa a fazer balanceamento de carga (Round Robin) entre um caminho AO e um caminho ANO. Você cria um padrão de desempenho "dente de serra": rápido, lento, rápido, lento.
Anatomia do "Path Thrashing"
Existe um cenário de pesadelo que todo SRE de storage enfrenta uma vez na vida: o Path Thrashing (ou Ping-Pong de LUN).
Isso acontece quando há uma divergência entre quem manda: o Host (Explicit ALUA) ou o Storage (Implicit ALUA).
- Implicit ALUA: O storage decide quem é o dono. Ele diz ao host: "A LUN 1 agora é da Controladora B". O host apenas obedece e atualiza sua tabela de roteamento.
- Explicit ALUA: O host tem permissão para enviar um comando (
SET TARGET PORT GROUPS) dizendo: "Eu quero que a Controladora B seja a dona agora". O storage obedece e move a LUN.
O Cenário do Desastre:
- O Storage (Implicit) move a LUN para a Controladora B para balancear sua carga interna de CPU.
- O Host (configurado incorretamente ou com um driver antigo) percebe que o caminho para a Controladora A ficou "Non-Optimized".
- O Host, tentando ser esperto (Explicit), envia um comando para tornar a Controladora A "Optimized" novamente, porque sua configuração diz "Prefira Caminho A".
- O Storage move a LUN de volta para A.
- O Storage detecta sobrecarga em A e move para B novamente.
- Repita ad infinitum.
Durante esse jogo de ping-pong, a LUN fica travada em estados de transição. O throughput cai a zero. A latência vai para o infinito.
Diagnóstico de Combate: Lendo os Sinais
Chega de teoria. Como você sabe se isso está acontecendo agora? Vamos olhar para o terminal. O segredo não é apenas ver se os caminhos estão "running", mas entender a Prioridade e o Status.
Linux: O Oráculo multipath -ll
No Linux, o Device Mapper Multipath (DM-Multipath) é quem gerencia isso. Execute multipath -ll.
Cenário Saudável (ALUA funcionando):
mpatha (360060160123456789abcdef01234567) dm-0 DGC,VRAID
size=100G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
|-+- policy='service-time 0' prio=50 status=active
| |- 1:0:0:1 sdb 8:16 active ready running
| `- 2:0:0:1 sdc 8:32 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
|- 1:0:1:1 sdd 8:48 active ready running
`- 2:0:1:1 sde 8:64 active ready running
Como ler isso como um SRE:
hwhandler='1 alua': O Linux detectou corretamente que este array fala ALUA. Se você veremcourdacaqui em um array moderno, verifique seumultipath.conf, você pode estar forçando um handler legado.- Os Grupos de Caminho: Note que existem dois grupos (iniciados por
|-+-e`-+-). prio=50vsprio=10: AQUI ESTÁ A CHAVE. O Linux calculou (via ALUA) que o primeiro grupo é "melhor".prio=50= Active/Optimized.prio=10= Active/Non-Optimized.
status=activevsstatus=enabled:active: I/O está fluindo aqui.enabled: O caminho está pronto, mas em reserva. O kernel não está enviando I/O aqui a menos que o grupoactivefalhe.
Cenário de Perigo (Configuração Errada):
Se você vir algo assim:
mpatha ...
policy='multibus 0' prio=1 status=active
|- 1:0:0:1 sdb ... active ready running
|- 2:0:0:1 sdc ... active ready running
|- 1:0:1:1 sdd ... active ready running
`- 2:0:1:1 sde ... active ready running
Análise: Todos os caminhos estão no mesmo grupo. A política é multibus (envia para todos). O Linux está tratando caminhos otimizados e não-otimizados igualmente. Isso causará latência errática. Você está forçando o I/O através do interconnect do storage em 50% das requisições.
VMware ESXi: A Linha de Comando esxcli
No mundo VMware, a lógica é a mesma, mas os comandos mudam. Você quer ver o Storage Array Type Plugin (SATP) e o Path Selection Policy (PSP).
esxcli storage nmp device list -d naa.60060160...
Saída esperada (resumida):
Device Display Name: DGC Fibre Channel Disk ...
Storage Array Type: VMW_SATP_ALUA
Path Selection Policy: VMW_PSP_RR
...
Working Paths: vmhba1:C0:T0:L1, vmhba2:C0:T0:L1
O que procurar:
VMW_SATP_ALUA: O ESXi reconheceu que deve usar ALUA.Working Paths: Devem listar apenas os caminhos para a controladora dona. Se você listar todos os caminhos aqui, verifique se o PSP está configurado para usar caminhos "Unoptimized" (geralmente não deveria).
Para ver o estado ALUA cru no ESXi:
esxcli storage core path list -d naa.60060160...
Procure por TPGN (Target Port Group Number) e State. Você verá Active vs Active (unoptimized).
Windows Server: PowerShell MPIO
No Windows, o MPIO é muitas vezes uma caixa preta, mas o PowerShell abre a tampa.
Get-MSIDsmLunLengthy -PathId ...
mpclaim -s -d
No mpclaim, verifique a coluna "TPG_State".
AO= Active/OptimizedAN= Active/Non-Optimized
Se o seu Load Balance Policy estiver em "Round Robin" e você ver tráfego fluindo em caminhos AN, você tem um problema de latência latente.
A Física do Interconnect: Por que dói tanto?
Você pode se perguntar: "Estamos em 2024. Os backplanes são PCIe Gen4 ou NVMe. Por que atravessar de uma controladora para outra é tão ruim?"
Não é apenas a largura de banda (bandwidth). É a contenda e a coerência de cache.
Quando a Controladora B recebe uma escrita para uma LUN da Controladora A:
- Ela não pode apenas passar os dados.
- Ela precisa garantir que os dados sejam espelhados no cache de ambas as controladoras para proteção contra falhas (write mirroring).
- Em um caminho Otimizado, o espelhamento acontece em paralelo ou como parte do fluxo de destaging.
- Em um caminho Não-Otimizado, o dado entra na B, viaja para A, A confirma, B confirma. Você adiciona "hops" na jornada do pacote.
Além disso, o link entre controladoras (ICL - Inter-Controller Link) é usado para muitas coisas: heartbeats, sincronização de metadados, destaging de cache. Se você entupir esse link com I/O de leitura/escrita regular que poderia ter ido direto, você arrisca desestabilizar o cluster de armazenamento inteiro. Eu já vi arrays reiniciarem controladoras porque o link de heartbeat ficou saturado com I/O "Non-Optimized" mal roteado.
Comparativo Tático: Arquiteturas de Storage
Para consolidar o modelo mental, vamos comparar como diferentes arquiteturas lidam com o roteamento.
| Característica | Active/Passive (Legado) | Symmetric Active/Active (High-End) | Asymmetric Active/Active (ALUA - Padrão Moderno) |
|---|---|---|---|
| Acesso aos Caminhos | Caminho secundário rejeita I/O (Erro). | Todos os caminhos aceitam I/O com performance igual. | Todos aceitam I/O, mas performance desigual. |
| Custo de Hardware | Baixo (desperdício de recursos). | Altíssimo (requer cache global complexo e interconnects massivos). | Médio (eficiente, usa software para inteligência). |
| Comportamento de Falha | Pausa no I/O (segundos) para trespass. | Transparente. | Transparente (mas latência aumenta se não corrigir). |
| Exemplos Típicos | Arrays SAS antigos. | VMAX, DS8000 (Mainframe class). | Unity, Nimble, PowerStore, Compellent, NetApp (SAN). |
| Risco Principal | Downtime durante failover. | Custo. | Configuração errada de multipath (Path Thrashing). |
Armadilhas e "Gotchas" na Produção
Como Sysadmin, você não é pago para saber como funciona quando tudo está bem. Você é pago pelas exceções. Aqui estão as armadilhas do ALUA:
- O Driver Errado: Se você configurar o Linux para usar o handler
rdac(para arrays LSI antigos) em um array que esperaalua, o host nunca lerá os grupos TPG corretamente. Ele tratará tudo como Active/Active ou falhará. Sempre verifique a HCL (Hardware Compatibility List) do vendor. - Timeout de Transição: Quando uma controladora reinicia (upgrade de firmware), os caminhos mudam de estado. Às vezes, o array reporta
TRANSITIONING(Código SCSI 0x04/0x0A). Se omultipath.conftiver um timeout muito curto (no_path_retry fail), sua aplicação pode falhar antes que o array termine a transição. Usequeueouqueue_if_no_path. - A Ilusão do "Round Robin": Muitos admins configuram
path_selector "round-robin 0"e acham que isso significa "usar todos os cabos". No contexto de ALUA, o Round Robin deve ser aplicado apenas dentro do grupo de prioridade mais alta. Certifique-se de quepath_grouping_policyestá definido comogroup_by_prio. Se estivermultibus, você anulou a inteligência do ALUA.
O Veredito: É sobre Comunicação, não Cabos
O ALUA importa porque ele transforma a rede de armazenamento de um encanamento burro para um sistema de roteamento inteligente. Ele permite que o hardware diga ao software onde a eficiência está.
Seus sistemas estão lentos e você não sabe por quê? Pare de olhar para o top ou htop. Vá fundo na camada de bloco. Verifique se o seu I/O está fluindo pelo caminho dourado ou se está pegando o desvio esburacado através do backplane do storage.
Para aprofundamento: O futuro está chegando com o NVMe-oF (NVMe over Fabrics). O conceito de ALUA evolui lá para ANA (Asymmetric Namespace Access). A lógica é idêntica (caminhos otimizados vs. não otimizados), mas a velocidade é ordens de magnitude maior e o protocolo é mais leve. Se você entende ALUA hoje, entenderá ANA amanhã. Se não, o NVMe será apenas uma maneira mais rápida de saturar a controladora errada.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.