Bit Rot e Corrupção Silenciosa: Por Que o RAID Não Salva Seus Dados

Você confia no RAID para integridade de dados? Erro fatal. Entenda como o Bit Rot passa despercebido por controladores tradicionais e por que Checksumming é a única defesa real.
Você recebe um chamado às 3 da manhã. O servidor de banco de dados não caiu, o RAID está verde e brilhante, mas a aplicação financeira está reportando inconsistências de saldo. O backup restaurado ontem também falhou na validação. Nenhuma luz vermelha piscou no data center.
Bem-vindo à cena do crime da Corrupção Silenciosa de Dados (Silent Data Corruption).
Como investigador forense de sistemas, aprendi que o maior perigo não é o disco que pega fogo e para de girar; é o disco que mente. O administrador médio dorme tranquilo porque confia no RAID. O administrador experiente dorme mal porque sabe que o RAID tradicional protege a disponibilidade do disco, mas não dá a mínima para a integridade do bit que você gravou lá há seis meses.
Vamos dissecar o cadáver digital para entender por que seus dados estão apodrecendo agora mesmo e por que seu controlador de hardware é cúmplice desse crime.
O Que é Bit Rot e Corrupção Silenciosa?
Definição Forense: Bit Rot (apodrecimento de bits) ou Corrupção Silenciosa ocorre quando um ou mais bits em um meio de armazenamento são alterados espontaneamente sem notificação de erro pelo hardware ou sistema operacional. Diferente de uma falha catastrófica de disco, os dados são lidos com sucesso, mas o conteúdo entregue à aplicação é diferente do original.
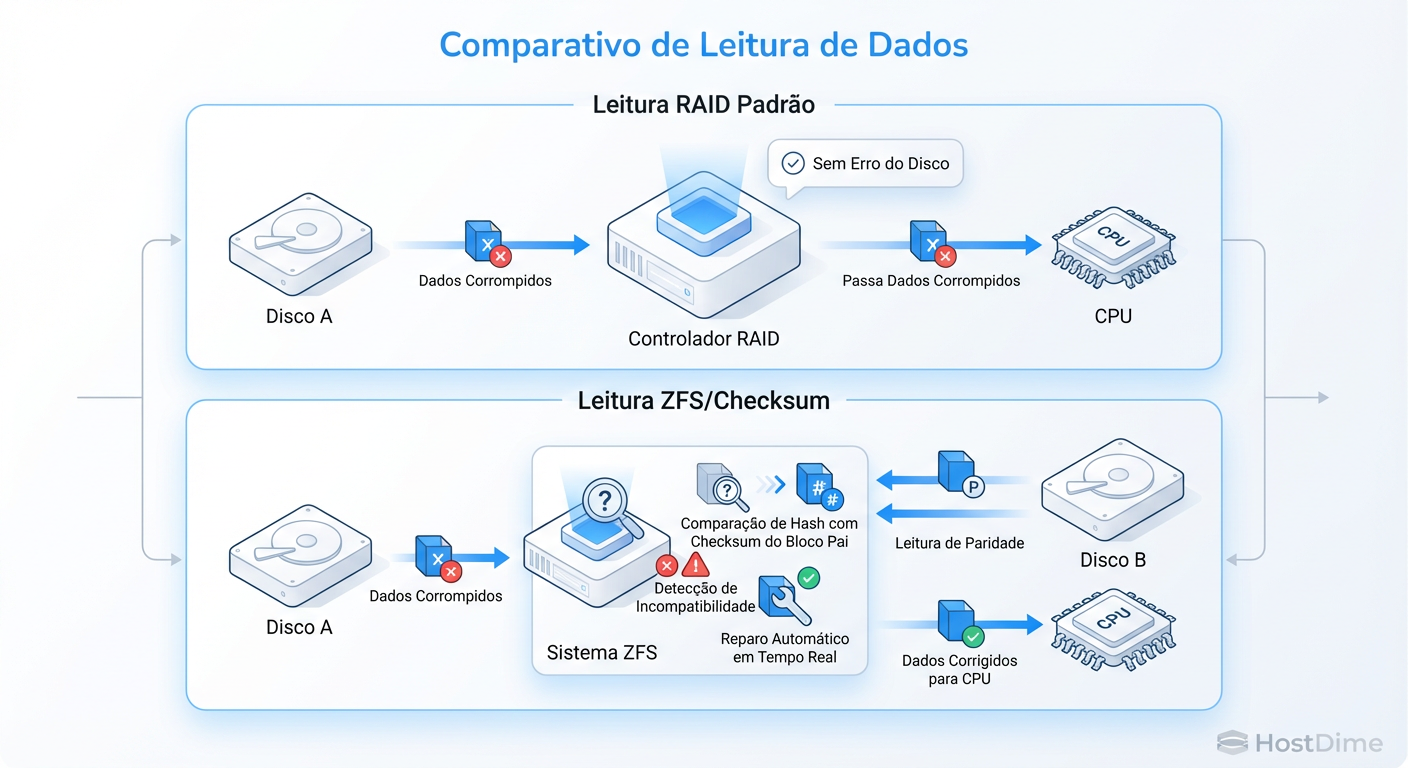 Figura: Diagrama de Fluxo de Confiança: RAID Tradicional vs. Filesystem com Checksum.
Figura: Diagrama de Fluxo de Confiança: RAID Tradicional vs. Filesystem com Checksum.
A Distinção Crítica entre Disponibilidade (RAID) e Integridade (Checksums)
O erro fundamental de julgamento na arquitetura de storage é confundir "manter o disco girando" com "manter o dado correto".
O RAID convencional (seja 1, 5, 6 ou 10) foi projetado na década de 80 para resolver um problema específico: o tempo de inatividade causado por falha mecânica. Se um disco morre, o RAID usa paridade ou espelhamento para reconstruir o que falta e manter o sistema online.
Aqui está a falha no modelo mental: O RAID assume implicitamente que, se o disco retornou um dado sem erro de I/O, aquele dado é verdadeiro.
Se um raio cósmico inverter um bit no prato magnético, ou se o firmware do SSD tiver um bug na tabela de tradução de páginas, o disco lerá o bloco corrompido e o entregará ao controlador RAID. O controlador, vendo que não houve erro de leitura (apenas o conteúdo mudou, não a legibilidade), repassa esse lixo para o sistema de arquivos (NTFS, EXT4, XFS). O sistema de arquivos entrega o lixo para sua aplicação.
Nesse cenário, o RAID não apenas falhou em proteger o dado; ele ajudou a propagar a mentira. Para combater isso, precisamos mudar o foco da redundância física para a validação matemática.
O Mecanismo Físico do Bit Rot e Degradação Magnética
Não precisamos de hackers para destruir dados; a entropia faz isso de graça. A corrupção silenciosa tem três suspeitos principais:
Degradação do Meio Físico: Em HDDs, os domínios magnéticos podem enfraquecer e virar (bit flip) devido a flutuações térmicas ou simplesmente tempo. Em SSDs, o vazamento de elétrons nas células NAND (cell leakage) pode alterar a tensão lida, mudando um 0 para 1, especialmente em drives que ficam muito tempo desligados (cold storage).
Raios Cósmicos e Interferência: Partículas de alta energia podem atingir chips de memória (DRAM ou cache do disco) e inverter um estado lógico. Se isso acontece no cache de gravação do disco antes de ser persistido, o dado é gravado corrompido, mas com CRC válido no nível do setor.
Firmware Bugado (O Assassino em Série): Discos modernos são computadores complexos. Bugs no firmware podem fazer com que gravações sejam silenciosamente descartadas (phantom writes) ou gravadas no local errado (misdirected writes).
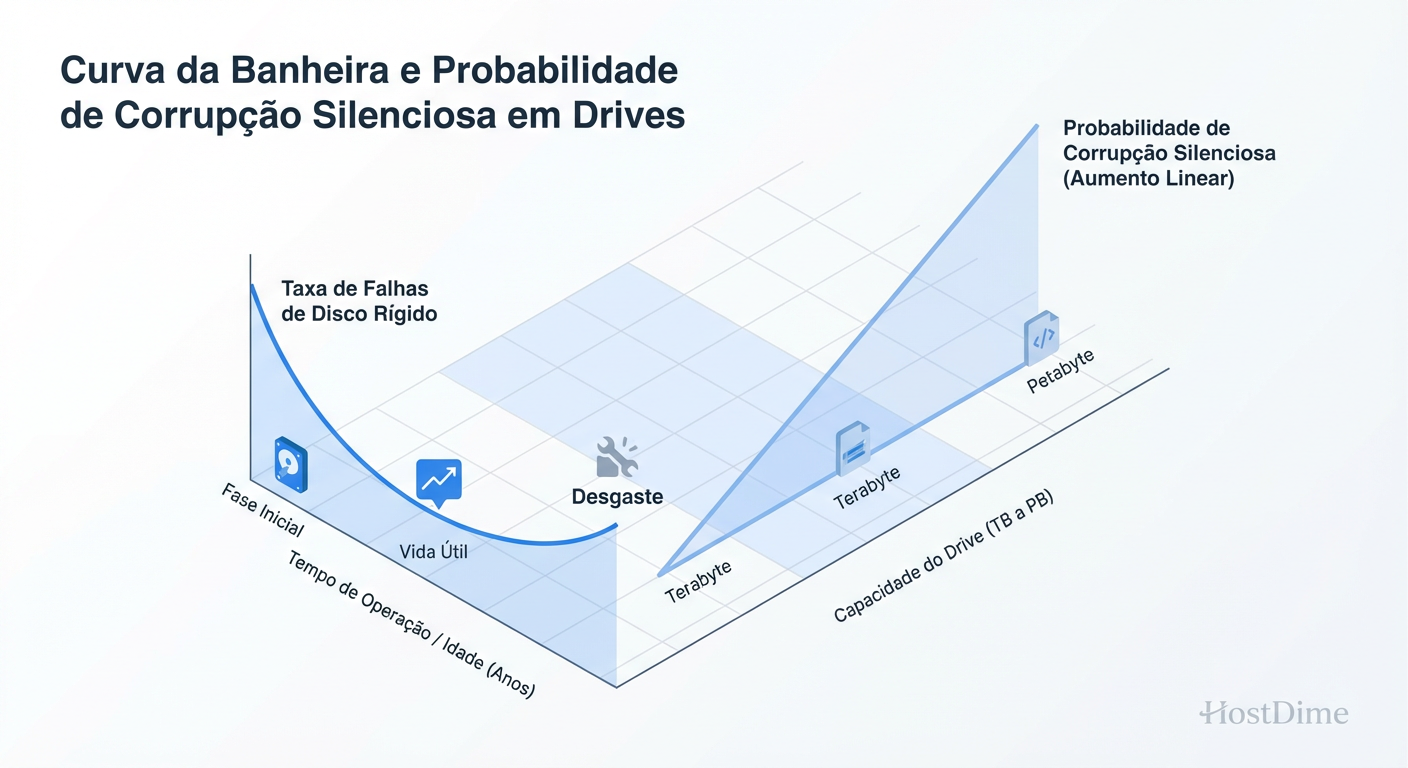 Figura: A Probabilidade de Corrupção Silenciosa aumenta linearmente com a capacidade de armazenamento.
Figura: A Probabilidade de Corrupção Silenciosa aumenta linearmente com a capacidade de armazenamento.
Quanto maior o volume de dados, maior a superfície de ataque para a estatística. Em escalas de Petabytes, a corrupção silenciosa deixa de ser uma possibilidade e torna-se uma certeza matemática.
Anatomia de uma Falha: Por Que o Controlador RAID Aceita Dados Corrompidos
Vamos isolar a variável: por que um controlador RAID de $1.000,00 não detecta isso?
A resposta está na camada de abstração. O controlador RAID opera no nível de bloco. Ele calcula a paridade (XOR) no momento da gravação.
Você grava
1010.O RAID calcula paridade e grava nos discos.
Meses depois, o disco 1 sofre bit rot e vira
1011.Você lê o arquivo.
O controlador lê
1011. O disco não reportou erro de leitura (o setor está legível).O controlador NÃO recalcula a paridade na leitura (em operações normais de leitura rápida) para verificar a integridade, a menos que encontre um erro de setor ilegível.
O sistema entrega
1011ao usuário.
O controlador RAID confia no hardware. Um investigador forense nunca confia em ninguém. É aqui que entram os sistemas de arquivos modernos.
A Solução Matemática: Árvores de Merkle e Checksums no ZFS
Para resolver o problema, precisamos que o sistema de arquivos desconfie do disco. Sistemas como ZFS e Btrfs utilizam uma estrutura de dados chamada Árvore de Merkle (Merkle Tree).
Diferente de sistemas legados (EXT4, NTFS) que apenas apontam onde o dado está, o ZFS armazena o checksum (a impressão digital matemática) do bloco de dados no ponteiro pai, não junto com o dado.
O fluxo de validação real:
O sistema de arquivos vai ler o Bloco A.
Antes de ler, ele olha para o ponteiro pai e vê: "O checksum SHA-256 do Bloco A deve ser
X".Ele lê o Bloco A do disco.
Ele calcula o checksum do que acabou de ler.
Se o cálculo der
Y, eY != X, o ZFS sabe matematicamente que o disco mentiu.
Neste momento, se houver redundância (RAID-Z ou Mirror gerido pelo ZFS), o sistema busca a cópia boa no outro disco, verifica o checksum dela, entrega o dado correto para a aplicação e, crucialmente, sobrescreve o dado podre no disco original com a versão correta. Isso é Self-Healing.
Tabela Comparativa: RAID de Hardware vs. ZFS/Btrfs
| Característica | RAID de Hardware Tradicional | ZFS / Btrfs (Software RAID Moderno) |
|---|---|---|
| Modelo de Confiança | Confia cegamente no drive se não houver erro de I/O. | "Trust but Verify" (Confia, mas verifica cada leitura). |
| Detecção de Bit Rot | Inexistente em leituras normais. | Automática em cada leitura via Checksums. |
| Correção de Erros | Apenas se o disco falhar totalmente ou reportar erro de setor. | Correção granular de blocos corrompidos (Self-Healing). |
| Write Hole | Risco de corrupção se faltar luz durante a gravação. | Eliminado via Copy-on-Write (CoW) transacional. |
| Visibilidade | Caixa preta proprietária. | Transparente e auditável via logs do OS. |
Estratégias de Mitigação: Scrubbing de Dados e Hardware ECC
Ter um sistema de arquivos com checksums não é suficiente se você nunca ler os dados. Dados "frios" (arquivados e raramente acessados) são os mais propensos a apodrecer sem ninguém notar.
1. Scrubbing Regular (A Ronda Policial)
O Scrubbing é o processo de forçar a leitura de todos os dados do pool, recalcular os checksums e compará-los com os metadados. É uma auditoria completa.
- Recomendação Prática: Agende scrubs mensais em discos de consumo e quinzenais em discos empresariais. Sem isso, você pode acumular erros silenciosos em múltiplos discos até que a redundância seja excedida.
2. A Importância Crítica da Memória ECC
Aqui está um cenário de pesadelo forense: O dado está correto no disco. Você o lê para a RAM. Um raio cósmico inverte um bit na RAM. O ZFS calcula o checksum do dado agora corrompido na RAM e o grava de volta no disco com um novo checksum "válido" para o dado podre.
O ZFS (e qualquer filesystem) confia na memória RAM. Se a RAM mentir, o sistema grava a mentira de forma permanente. Para armazenamento sério, Memória ECC (Error Correcting Code) não é luxo, é requisito. Ela detecta e corrige erros de bit único na memória antes que o sistema de arquivos tome decisões baseadas neles.
Como Simular e Detectar Corrupção Silenciosa na Prática
Não acredite na minha palavra. Vamos para a evidência empírica. Se você usa Linux, pode simular corrupção e ver como diferentes sistemas reagem.
O teste abaixo cria um disco virtual, formata com ZFS, grava dados, e então usamos um editor hexadecimal para corromper fisicamente os bits no "disco", simulando Bit Rot.
truncate -s 1G disco_teste.img
# 2. Crie um pool ZFS (equivalente a formatar e montar)
zpool create tank $(pwd)/disco_teste.img
# 3. Escreva dados importantes
echo "DADOS CRÍTICOS: O saldo é 1.000.000" > /tank/segredo.txt
# Garanta que está no disco
zpool export tank && zpool import -d $(pwd) tank
# 4. O CRIME: Vamos corromper o disco diretamente, ignorando o filesystem
# Usamos 'dd' para escrever lixo em um local aleatório do arquivo de imagem
# (Em um cenário real, isso seria um bad block ou bit flip)
dd if=/dev/urandom of=disco_teste.img bs=1 count=512 seek=400000 conv=notrunc
# 5. A PROVA: Tente ler o arquivo
# O ZFS vai detectar que o checksum não bate com o dado lido.
cat /tank/segredo.txt
# Resultado esperado: Erro de I/O. O ZFS se recusa a entregar lixo.
Se você fizesse o mesmo teste com EXT4 sobre um RAID de hardware simples, o comando cat mostraria o conteúdo corrompido (caracteres estranhos ou números errados) sem nenhum aviso, pois o EXT4 confiaria no bloco lido.
Veredito Final
O RAID salva você de falhas de hardware; Checksums salvam você de mentiras do hardware. Em um mundo onde a densidade de armazenamento cresce mais rápido que a confiabilidade dos componentes, operar sem validação de integridade ponta-a-ponta não é administração de sistemas — é jogo de azar.
Referências & Leitura Complementar
Bonwick, J. & Moore, B. (2008). ZFS: The Last Word in File Systems. Sun Microsystems Whitepaper.
CERN Data Integrity Study (2007). Data integrity analysis of silent data corruption in High Energy Physics storage. (Estudo seminal sobre corrupção em escala de Petabytes).
Rosenthal, D. S. (2010). Bit Rot and the case for ECC Memory. Stanford University Libraries.
Btrfs Wiki. Btrfs Design & Data Structures: Checksums and Copy-on-Write. Kernel.org.
RFC 3720. Internet Small Computer Systems Interface (iSCSI). (Para entender como protocolos de bloco transportam, mas não necessariamente validam, a carga útil).

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.