Btrfs vs ZFS: Análise Profunda de Checksums e Mecanismos de Self-Healing

Entenda como Btrfs e ZFS combatem o 'bit rot' silencioso. Uma comparação técnica dos algoritmos de checksum, árvores de Merkle e a realidade da autocorreção de dados.
Se você acredita que seu disco rígido é um dispositivo de armazenamento confiável, você já começou errado. Como engenheiro de performance, aprendi a tratar discos não como cofres, mas como consumíveis hostis que mentem. Eles mentem sobre terem gravado os dados (caching volátil) e mentem sobre o que estão lendo (bit rot).
A maioria dos administradores de sistemas confia em camadas de abstração como RAID de hardware para proteção. O problema é que o RAID tradicional protege apenas contra falhas catastróficas (o disco parou de girar). Ele é cego para a corrupção silenciosa, onde um bit vira de 0 para 1 devido a raios cósmicos, firmware bugado ou degradação magnética. ZFS e Btrfs não confiam no disco; eles confiam na matemática.
Self-Healing em Filesystems é a capacidade arquitetural de detectar corrupção de dados em tempo de leitura — comparando o dado lido com um checksum armazenado previamente — e reparar essa corrupção automaticamente usando uma cópia redundante (mirror ou paridade), sem intervenção humana e, idealmente, sem que a aplicação perceba a latência da recuperação.
A Falácia do Hardware: Por que RAID tradicional ignora corrupção silenciosa
Para entender a necessidade de ZFS ou Btrfs, precisamos dissecar o fracasso do RAID convencional.
Imagine que você tem um RAID 1 (espelhamento) via hardware ou mdadm. Você grava um arquivo. O controlador escreve os blocos no Disco A e no Disco B.
Seis meses depois, o setor 500 do Disco A sofre degradação magnética. Os bits mudam. O controlador do disco não sabe que mudou, pois o checksum interno do HDD (ECC) pode não detectar ou pode ter sido reescrito incorretamente pelo firmware.
Quando você pede para ler esse arquivo:
O controlador RAID escolhe ler do Disco A (balanceamento de carga).
O Disco A entrega dados corrompidos.
O controlador RAID entrega o lixo para o Sistema Operacional.
Sua aplicação falha ou seu banco de dados corrompe.
O RAID tradicional não valida o conteúdo. Ele valida a disponibilidade do dispositivo. Se o disco não retornar um erro de I/O explícito, o RAID assume que os dados são válidos. É aqui que entra a validação hierárquica.
 Figura: A diferença arquitetural: Enquanto o RAID tradicional confia cegamente no disco, Btrfs e ZFS usam validação hierárquica (Merkle Trees) para garantir integridade antes da entrega.
Figura: A diferença arquitetural: Enquanto o RAID tradicional confia cegamente no disco, Btrfs e ZFS usam validação hierárquica (Merkle Trees) para garantir integridade antes da entrega.
O Conceito da Árvore de Merkle: Validação da Verdade
Diferente de sistemas de arquivos tradicionais (ext4, XFS) que usam journaling apenas para metadados, ZFS e Btrfs garantem a integridade dos dados. Eles fazem isso através de uma estrutura lógica baseada em Árvores de Merkle (Merkle Trees).
A regra de ouro aqui é: O checksum nunca é armazenado junto com o dado que ele protege. Se você guardasse o checksum no mesmo bloco do dado, uma corrupção naquele setor destruiria ambos, ou pior, uma escrita fantasma (phantom write) poderia escrever dados errados com um checksum "válido" para o dado errado.
Em ambos os sistemas, o bloco "pai" segura o hash do bloco "filho". Isso cria uma cadeia de confiança que sobe até o topo da árvore (Uberblock no ZFS, Superblock no Btrfs). Você não consegue alterar um bit na base da árvore sem quebrar a validação em toda a cadeia ascendente.
Implementação de Checksums no ZFS e Block Pointers
O ZFS trata o disco como um mar de objetos gerenciados por Block Pointers (BP). Um BP não é apenas um endereço de memória ("vá para o setor 500"); é uma estrutura rica que contém:
Endereço físico (VDEVs).
Tamanho do bloco (LSIZE/PSIZE).
O Checksum do dado apontado.
Quando o ZFS lê um bloco:
Ele lê o BP (que já foi validado pelo seu próprio pai).
Ele vê o checksum esperado (ex:
a1b2).Ele lê o dado no disco.
Ele calcula o hash do dado lido.
Se o cálculo der
a1b2, o dado sobe. Se derc3d4, o ZFS declara CHECKSUM ERROR.
A Rigidez do Fletcher4 vs SHA256
Por padrão, o ZFS usa Fletcher4. É um algoritmo extremamente rápido, desenhado para detectar erros de bit (bit rot), mas não é criptograficamente seguro (colisões são possíveis, embora raras em storage).
Você pode configurar set checksum=sha256, o que aumenta drasticamente a carga de CPU. Em testes de throughput, SHA256 pode reduzir a velocidade de escrita em 30-50% dependendo da CPU, enquanto Fletcher4 é praticamente invisível.
Mecânica de Validação no Btrfs: Csum Tree e Extensões
O Btrfs resolve o mesmo problema de forma ligeiramente diferente. Enquanto o ZFS coloca o checksum no ponteiro pai, o Btrfs mantém uma árvore dedicada chamada Checksum Tree (CSUM Tree).
O sistema aloca dados em "extents" (extensões).
Para cada bloco de dados (geralmente 4KiB), um checksum é calculado.
Esses checksums são armazenados de forma compactada na Csum Tree, indexados pelo endereço lógico.
O padrão do Btrfs é o CRC32c. Diferente do Fletcher4, o CRC32c possui instruções de hardware dedicadas na maioria das CPUs modernas (SSE4.2+), tornando-o excepcionalmente eficiente.
Callout de Engenharia: A separação da Csum Tree no Btrfs permite flexibilidade, mas cria um padrão de I/O diferente. Ler um arquivo exige consultar a árvore de metadados e a árvore de checksums. Em discos rotacionais (HDD), isso pode aumentar a latência de seek se a fragmentação for alta.
O Fluxo do Self-Healing: O nanossegundo da falha
O que distingue esses sistemas não é apenas detectar o erro, mas o que fazem a seguir. O "Self-Healing" é uma operação de I/O corretiva disparada durante a leitura (Read-Time).
Este processo é transparente para a aplicação. O banco de dados (PostgreSQL, MySQL) pede um bloco. O filesystem percebe o erro, corrige e entrega o bloco limpo. A única evidência é um incremento nos contadores de erro e uma latência ligeiramente maior naquela operação específica.
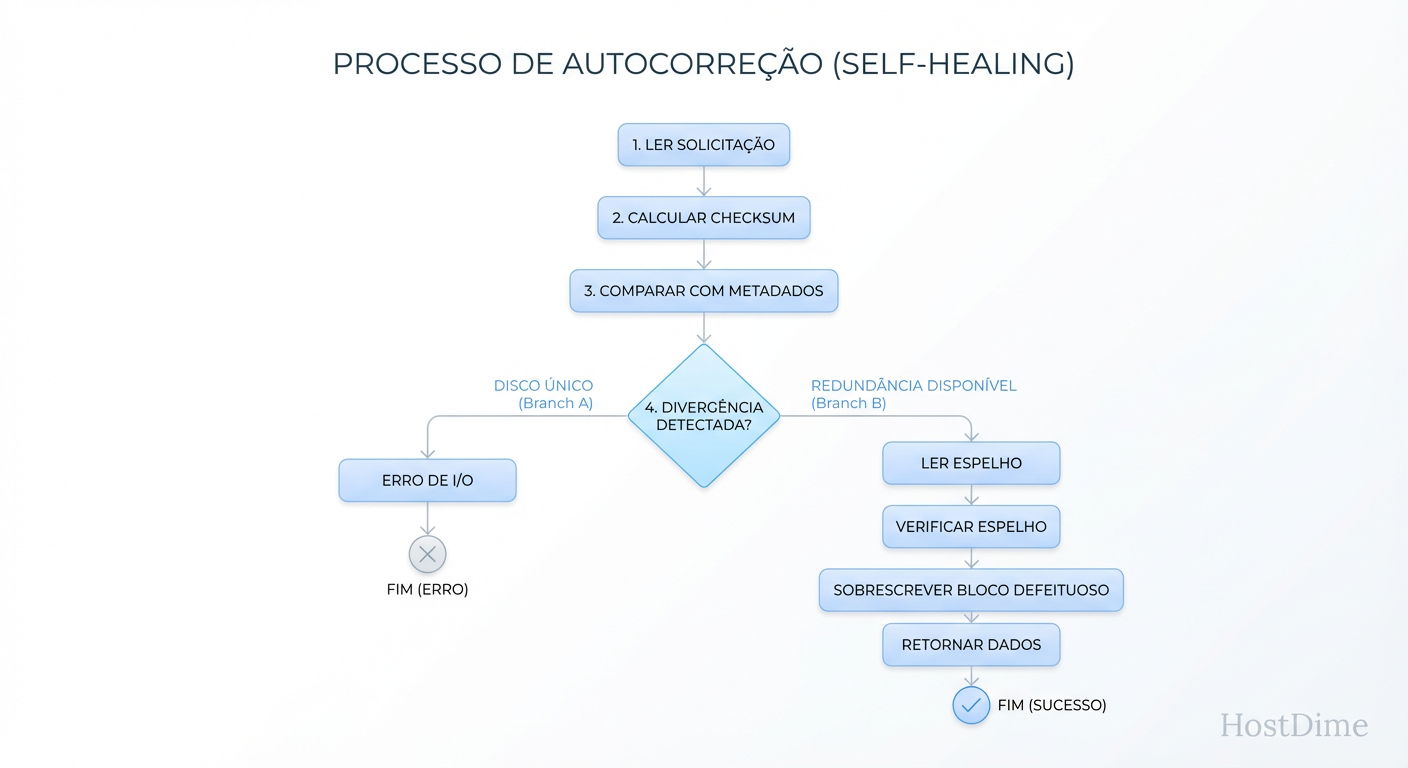 Figura: O ciclo de vida de uma leitura com falha: O processo de decisão interno que transforma uma corrupção de disco em uma correção transparente para o usuário.
Figura: O ciclo de vida de uma leitura com falha: O processo de decisão interno que transforma uma corrupção de disco em uma correção transparente para o usuário.
Se não houver redundância (ex: um único disco no pool), o self-healing é impossível. O sistema reportará erro de I/O para a aplicação (EIO), protegendo-a de processar lixo, mas falhando a operação. Sem redundância, você tem apenas detecção, não cura.
Trade-offs de Performance: Custo de CPU vs. Segurança de Dados
Não existe almoço grátis. Checksumming consome ciclos de CPU e largura de banda de memória.
O Custo da Escrita (Write Penalty)
Toda escrita gera um cálculo de hash.
ZFS (Fletcher4): Custo marginal. Em um Xeon moderno, o impacto é <1%.
Btrfs (CRC32c): Custo muito baixo (aceleração de hardware).
ZFS (SHA256): Custo alto. Use apenas se a integridade criptográfica for requisito (ex: conformidade legal).
O Custo da Leitura (Read Penalty)
Toda leitura gera um recálculo para verificação. Se você tem um workload de leitura aleatória intensa (ex: VM images ou OLTP), o gargalo geralmente será o disco (IOPS), não a CPU calculando checksums. No entanto, em arrays All-Flash NVMe de alta performance (GB/s de throughput), a CPU pode se tornar o gargalo se o algoritmo de hash for pesado.
Tabela Comparativa: ZFS vs Btrfs em Integridade
| Característica | ZFS (OpenZFS) | Btrfs | Impacto Prático |
|---|---|---|---|
| Local do Checksum | Block Pointer (Pai) | Csum Tree (Dedicada) | ZFS tem localidade de metadados mais rígida; Btrfs é mais flexível. |
| Algoritmo Padrão | Fletcher4 | CRC32c | CRC32c é mais robusto contra colisões que Fletcher4, mas ambos são rápidos. |
| Granularidade | Variável (recordsize) | 4KiB (padrão) | ZFS ajustável para bancos de dados (ex: 16k para Postgres) evita overhead. |
| Self-Healing RAID 5/6 | Robusto (RAIDZ1/2/3) | Instável (Write Hole) | Cuidado: RAID 5/6 no Btrfs ainda é considerado arriscado em produção. |
| Validação de Metadados | Sim (Ditto Blocks) | Sim (Duplicado por padrão) | Ambos protegem metadados agressivamente (2 cópias mesmo em single disk). |
Armadilhas Operacionais e Monitoramento
Como operar isso em produção sem ser pego de surpresa?
1. O Perigo do NODATACOW no Btrfs
Em Btrfs, é comum desativar o Copy-on-Write (CoW) para arquivos de banco de dados ou imagens de VM para evitar fragmentação, usando o atributo +C (chattr +C).
O Risco: Ao ativar NODATACOW, você desativa o checksumming para esses arquivos. Você volta a operar "às cegas", como no ext4.
Solução: Mantenha CoW, mas use pré-alocação ou desfragmente periodicamente. Ou aceite o risco sabendo que o banco de dados tem seus próprios checksums de página (ex: page checksums do SQL Server/Postgres).
2. Scrubbing: A Manutenção Preventiva
O Self-Healing reage à leitura. Se você tem dados frios (arquivos que ninguém lê há anos), eles podem estar apodrecendo silenciosamente. Se dois discos falharem no mesmo setor em momentos diferentes, você perde dados. Você deve agendar um "Scrub" periódico. O Scrub lê todos os dados, valida os checksums e repara erros latentes.
zpool status -v
# ZFS: Iniciar scrub
zpool scrub tank
# Btrfs: Verificar erros acumulados
btrfs device stats /mnt/btrfs
# Btrfs: Iniciar scrub
btrfs scrub start /mnt/btrfs
3. A Ilusão da Recuperação sem Redundância
Muitos usuários ativam copies=2 no ZFS em um único disco, achando que isso substitui o RAID. Isso protege contra bad sectors (setores defeituosos), mas se o disco morrer completamente, seus dados se vão. Self-healing exige diversidade física.
Veredito Técnico
Btrfs e ZFS elevaram o padrão de armazenamento. A era de confiar cegamente que o que foi gravado será lido acabou.
Para ambientes de produção crítica:
Use ZFS se precisar de RAID 5/6 (RAIDZ) robusto e estiver disposto a lidar com o consumo de RAM do ARC. A rigidez do ZFS é sua maior virtude em segurança.
Use Btrfs (em RAID 1 ou 10) se precisar de flexibilidade para adicionar discos de tamanhos diferentes ou se estiver em ambientes Linux onde o ZFS é complexo de manter (kernel modules).
Mas lembre-se: Checksums não substituem backups. Eles apenas garantem que o dado que você está fazendo backup é o dado que você acha que é.
Referências & Leitura Complementar
Bonwick, J. & Moore, B. (2008). ZFS: The Last Word in File Systems. Sun Microsystems. (Whitepaper fundamental sobre a arquitetura de Block Pointers).
Rodeh, O., Bacik, J., & Mason, C. (2013). BTRFS: The Linux B-Tree Filesystem. ACM Transactions on Storage. (Detalhes sobre Csum Trees e B-Trees).
OpenZFS Documentation. Checksums and the Fletcher-4 Algorithm.
Btrfs Wiki. RAID56 Status and The Write Hole Problem.

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.