Ceph All-Flash: Por que NVMe Rápido Pode Quebrar a Estabilidade do Cluster
Migrou para NVMe e o Ceph ficou instável? Entenda o paradoxo da baixa latência com alta instabilidade, gargalos de CPU e como tunar RocksDB e BlueStore.
Você comprou os drives NVMe mais rápidos do mercado. O datasheet prometia milhões de IOPS e latência na casa dos microssegundos. O orçamento foi aprovado com a promessa de que "a lentidão do storage acabou". Você montou o cluster Ceph, rodou o benchmark e... o desempenho oscila, OSDs (Object Storage Daemons) caem aleatoriamente e a latência de cauda (tail latency) está pior do que no seu antigo cluster de SSDs SATA.
Bem-vindo ao mundo real da arquitetura de storage de alto desempenho. O problema não é o hardware; é a física do sistema operacional e do software de armazenamento tentando beber de uma mangueira de incêndio.
Em arquiteturas Enterprise, adicionar velocidade bruta sem ajustar o caminho de dados (datapath) não resolve gargalos; apenas os move para lugares mais caros e difíceis de diagnosticar: a CPU e o Kernel.
O que é a Instabilidade em Ceph All-Flash NVMe?
A instabilidade em clusters Ceph All-Flash NVMe ocorre quando a velocidade da mídia de armazenamento excede a capacidade da CPU e do Kernel de processar interrupções e metadados. Diferente de HDDs, onde o disco é o gargalo, em NVMe o gargalo se desloca para o software (BlueStore/RocksDB) e para a gestão de filas do processador, gerando latência alta (stalls) e timeouts de OSDs durante picos de gravação.
O Paradoxo do All-Flash: Quando o Disco Deixa de Ser o Gargalo
Durante décadas, fomos treinados com um modelo mental simples: a CPU espera pelo disco. O processador enviava uma solicitação e ia "tomar um café" (milhares de ciclos de clock) até o prato magnético girar e a cabeça ler o setor.
Com NVMe, essa lógica inverteu. Um drive NVMe moderno responde tão rápido que a CPU não tem tempo de "descansar". Se você tem 10 ou 12 NVMes em um servidor, cada um bombardeando a CPU com interrupções e dados completados, o processador se torna o elo fraco.
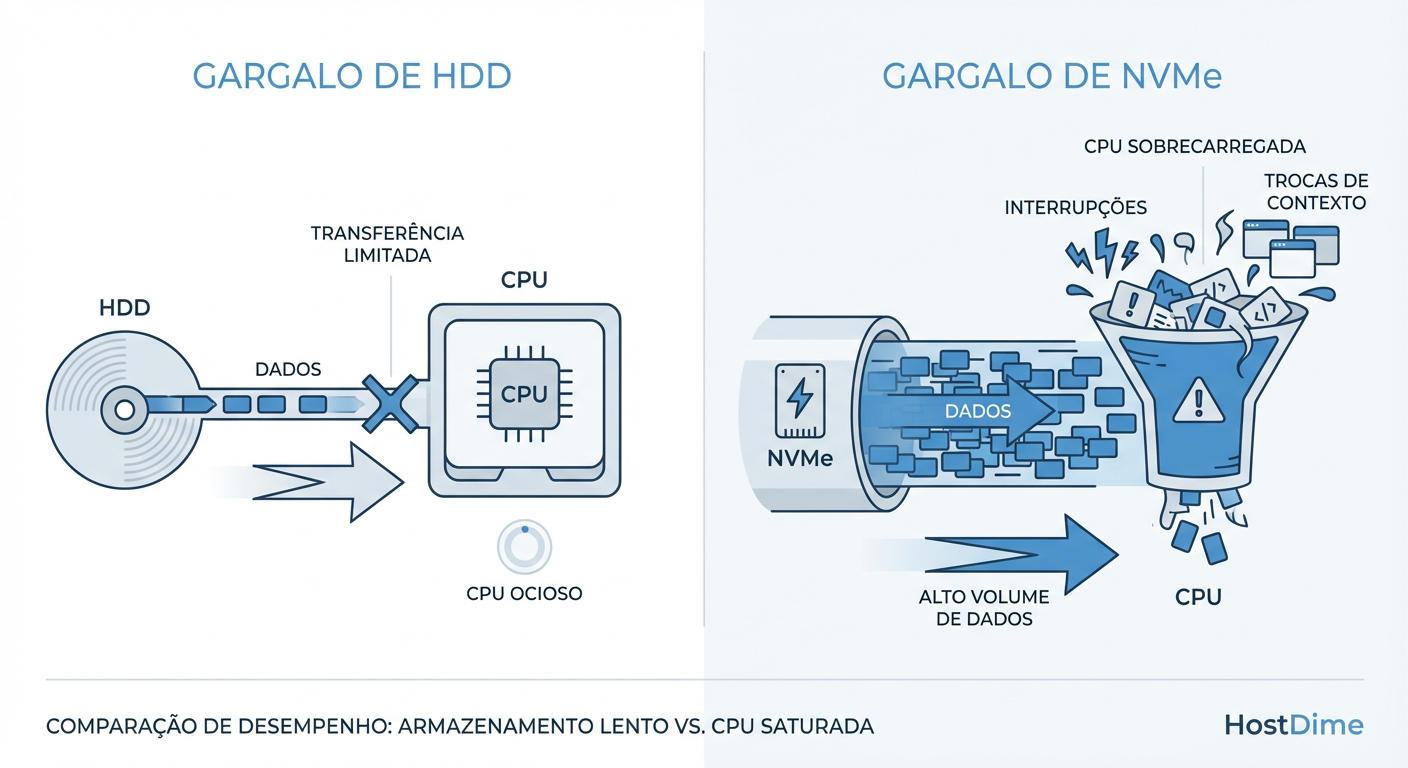 Figura: A Mudança de Gargalo: Em clusters NVMe, o disco espera pela CPU, e não o contrário.
Figura: A Mudança de Gargalo: Em clusters NVMe, o disco espera pela CPU, e não o contrário.
No diagrama acima, vemos a inversão clássica. Em um cenário NVMe, o Ceph OSD thread está frequentemente competindo por tempo de CPU apenas para processar a chegada do dado, antes mesmo de começar a lógica de replicação ou erasure coding. Se a CPU satura, o NVMe fica ocioso esperando instruções. Você pagou por IOPS que não consegue usar porque sua CPU está engasgada.
A Ilusão da Latência Média vs. O Caos da Latência de Cauda
A maioria dos dashboards de monitoramento mente para você. Eles mostram a "Latência Média" (Average Latency). Em um cluster NVMe, a média pode ser linda: 0.5ms. Mas seus usuários reclamam que a aplicação "trava".
Isso acontece por causa da Tail Latency (Latência de Cauda) — o P99 ou P99.9.
Se você faz 10.000 operações por segundo:
Média: Tudo parece bem.
P99 (1% mais lento): Significa que 100 operações por segundo estão demorando 50ms, 100ms ou até 500ms.
Para um banco de dados transacional rodando sobre esse Ceph, esses 100 "soluços" por segundo são desastrosos. Eles causam locks na aplicação. Em All-Flash, a variância é o inimigo, não a velocidade absoluta. Se o cluster responde em 100us na maior parte do tempo, mas leva 200ms a cada poucos segundos, a percepção de performance é pior do que um sistema constante de 5ms.
O Assassino Silencioso: RocksDB Compaction e Write Stalls
O Ceph usa o BlueStore como backend de armazenamento, que por sua vez utiliza o RocksDB para gerenciar metadados (e dados pequenos, se configurado via bluestore_min_alloc_size_hdd). O RocksDB é baseado em LSM-Tree (Log-Structured Merge-tree).
O funcionamento básico é:
Gravações novas entram na memória (MemTable).
São despejadas para o disco em arquivos imutáveis (SSTables) no Nível 0 (L0).
Quando o L0 enche, o RocksDB funde e compacta esses arquivos para o Nível 1 (L1), e assim por diante.
Onde o NVMe quebra isso? O NVMe aceita gravações tão rápido que o RocksDB não consegue compactar o L0 para o L1 na mesma velocidade. O sistema entra em pânico. Para evitar que o disco encha de lixo não compactado, o RocksDB deliberadamente para as gravações (Write Stall) para dar tempo à CPU de realizar a compactação.
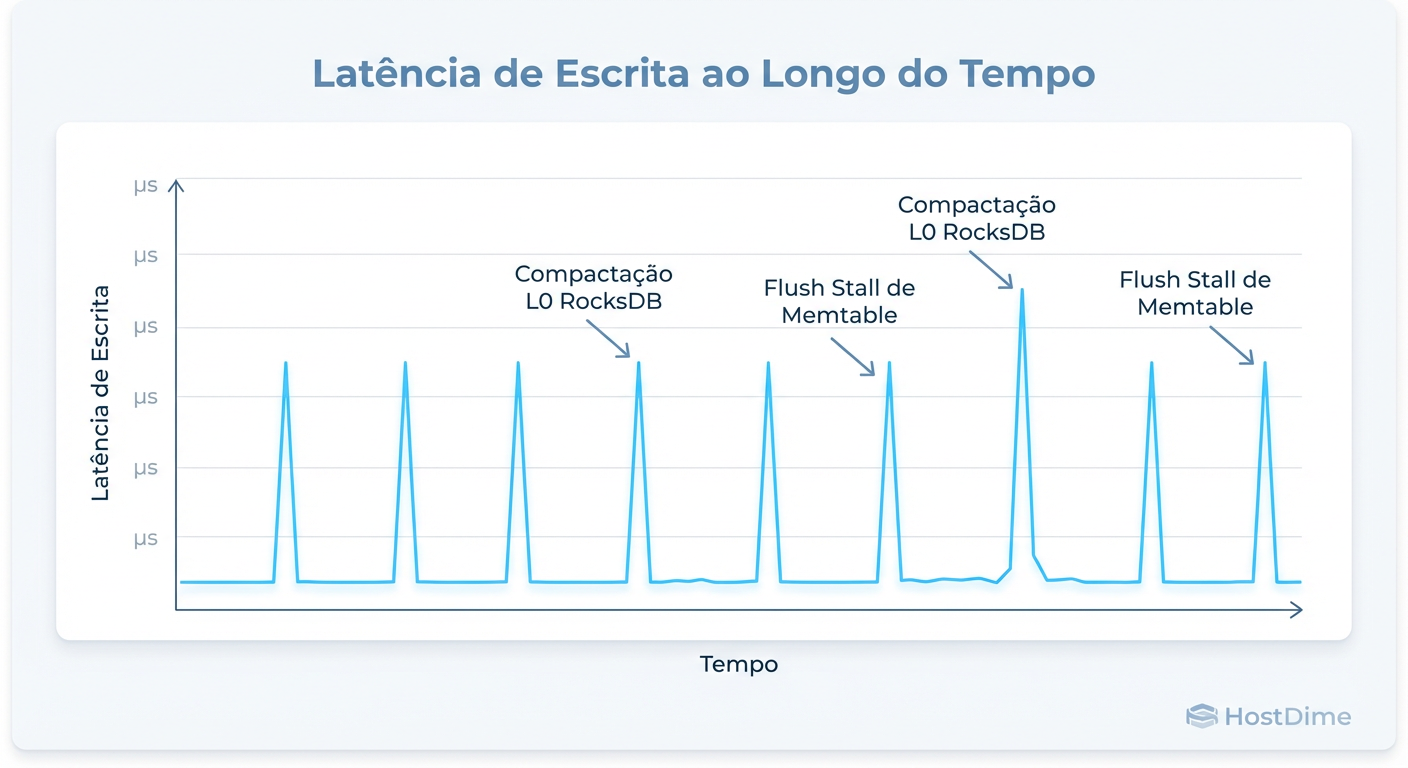 Figura: O efeito 'Dente de Serra': Latência média baixa mascarando stalls de compactação do RocksDB.
Figura: O efeito 'Dente de Serra': Latência média baixa mascarando stalls de compactação do RocksDB.
O gráfico "Dente de Serra" (Sawtooth) acima é a assinatura clássica desse problema. O desempenho é altíssimo, depois cai a quase zero (stall), e volta a subir. Para o Ceph, isso parece um disco "morto" por alguns segundos. Se o stall durar muito, os monitores do Ceph marcam o OSD como down, iniciam a recuperação (rebalance), saturam a rede e derrubam o cluster inteiro em efeito dominó.
Tabela Comparativa: Onde Está o Gargalo?
Para entender a magnitude da mudança, compare os gargalos primários em diferentes mídias no contexto do Ceph:
| Atributo | HDD (Spinning Rust) | SSD SATA (Flash) | NVMe (Gen4/Gen5) |
|---|---|---|---|
| Gargalo Primário | Mecânica do Disco (Seek Time) | Interface SATA / Controlador | CPU & Software Stack |
| Latência Típica | 5ms - 20ms | 0.5ms - 2ms | 20µs - 200µs |
| Custo de Interrupção | Baixo (poucas IOPS) | Médio | Crítico (Milhões de IOPS) |
| Risco de RocksDB Stall | Quase nulo | Moderado | Alto |
| Foco do Tuning | Cache de leitura, Seek optimization | Write cache, Trim | CPU Pinning, NUMA, Kernel Polling |
Gargalos de CPU e Interrupções: O Custo de Processar IOPS
Cada operação de I/O em um NVMe gera uma interrupção de hardware que a CPU precisa tratar. Em sistemas modernos com milhões de IOPS, estamos falando de milhões de interrupções por segundo.
Se você não configurar o CPU Affinity ou IRQ Balance corretamente, todas essas interrupções podem ser jogadas em um único núcleo (Core 0, geralmente). O resultado? Um núcleo em 100% de uso (softirq), enquanto os outros 63 núcleos estão dormindo. O NVMe espera, a latência sobe.
Além disso, temos o NUMA (Non-Uniform Memory Access). Se o drive NVMe está conectado fisicamente ao soquete da CPU 0, mas o processo do OSD está rodando na CPU 1, os dados precisam cruzar o barramento QPI/UPI (interconnect). Em velocidades NVMe, essa latência extra de travessia de memória é perceptível e degrada a performance.
Estratégias de Tuning Realista para Ceph NVMe
Não existe "bala de prata", mas existem configurações obrigatórias para mitigar esses riscos.
1. C-States e Power Management
Servidores modernos tentam economizar energia colocando a CPU para "dormir" (C-States profundos) quando ociosa. Acordar de um C-State profundo leva microssegundos — uma eternidade para um NVMe.
Ação: Em clusters de alta performance, a economia de energia é inimiga da latência. Trave a CPU em performance máxima.
cpupower frequency-info
# Forçar performance (exemplo em sistemas systemd/RedHat based)
tuned-adm profile latency-performance
# OU manualmente desativar C-States profundos na BIOS ou kernel line:
# intel_idle.max_cstate=1 processor.max_cstate=1
2. OSD Limitado por CPU (Core Ratio)
Uma regra prática antiga era "1 núcleo de CPU por OSD". Para NVMe, isso é suicídio. Um OSD NVMe pode consumir facilmente 4 a 6 threads/núcleos sob carga pesada devido à compactação do RocksDB e checksums.
Se você colocar 24 NVMes em um servidor com 32 núcleos, seus OSDs vão brigar por CPU (CPU Starvation), causando latência alta. Recomendação: Planeje arquiteturas com menos drives por nó ou CPUs com contagem massiva de núcleos. Para NVMe rápido, pense em 4 a 6 núcleos reais por OSD.
3. Tuning do RocksDB e BlueStore
Você precisa dizer ao RocksDB para não ser tão agressivo ou dar mais memória a ele para adiar a compactação.
Configurações críticas no ceph.conf ou Central Config:
bluestore_cache_size: Aumente isso. Memória RAM é o melhor cache para metadados.bluestore_rocksdb_options: Ajustar o paralelismo de compactação. Cuidado: aumentar o paralelismo consome mais CPU. É um trade-off.
# Exemplo de verificação de configuração de cache atual
ceph config get osd.0 bluestore_cache_autotune
ceph config get osd.0 osd_memory_target
Nota: O osd_memory_target é vital. Garanta que o Ceph tenha permissão para usar RAM suficiente (ex: 8GB+ por OSD NVMe) para manter os metadados do RocksDB "quentes".
4. Particionamento NUMA
Garanta que o processo do OSD rode no mesmo nó NUMA onde o cartão NVMe está espetado. Isso evita tráfego desnecessário no barramento entre processadores.
- Isso geralmente é feito via
systemdunit files do OSD comcpusetou usando a funcionalidade automática de NUMA do Ceph (disponível em versões recentes como Quincy/Reef, mas valide a eficácia).
Veredito Técnico: Velocidade Exige Controle
Migrar para Ceph All-Flash NVMe não é apenas uma atualização de hardware; é uma mudança de paradigma operacional. A estabilidade do cluster deixa de depender da rotação de um disco e passa a depender da eficiência com que seu kernel Linux e suas configurações de RocksDB lidam com o caos.
Se você busca baixa latência consistente, pare de olhar apenas para os IOPS no datasheet do fabricante. Comece a olhar para seus histogramas de latência, uso de softirq na CPU e métricas de compactação do RocksDB. A velocidade sem controle é apenas uma maneira mais rápida de travar seu cluster.
Referências & Leitura Complementar
RocksDB Tuning Guide (Facebook/Meta): Documentação oficial sobre Write Stalls e tuning de compactação para SSDs rápidos.
Ceph BlueStore Performance: Ceph Documentation. Detalhes sobre como o BlueStore interage com dispositivos de bloco.
Intel SDN/NFV Reference: Intel Application Note. "Zero Packet Loss" e tuning de C-States para latência determinística.
Brendan Gregg, "Systems Performance": Referência obrigatória para entender latência de cauda e metodologias de análise de desempenho (USE Method).

Bruno Azevedo
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.