Ceph Arquitetura Basica E Quando Usar

Vamos ser honestos sobre o porquê de estarmos aqui. Ninguém acorda de manhã querendo gerenciar um cluster Ceph porque é "divertido". Nós fazemos isso porque a a...
Ceph Arquitetura Basica E Quando Usar
TL;DR: O Ceph não é apenas "storage open source"; é um sistema distribuído massivo que troca latência crua por escalabilidade infinita e resiliência via software. O coração dessa troca é o algoritmo CRUSH: um mecanismo determinístico que elimina a necessidade de tabelas de metadados centralizadas, permitindo que clientes calculem onde os dados estão. O preço? Ciclos de CPU, consumo de RAM e uma penalidade de latência inerente à replicação síncrona via rede. Se você precisa de latência sub-milissegundo para um único banco de dados, use NVMe local ou SAN. Se você precisa de Petabytes que sobrevivem à falha de racks inteiros, bem-vindo ao Ceph.
O Problema da Escala e a Morte do Controller
Vamos ser honestos sobre o porquê de estarmos aqui. Ninguém acorda de manhã querendo gerenciar um cluster Ceph porque é "divertido". Nós fazemos isso porque a alternativa tradicional falhou.
No modelo clássico de SAN (Storage Area Network), você tem um chassi com dois controladores (Active/Active ou Active/Passive) e um monte de gavetas de disco. A inteligência está concentrada nesses controladores. Eles mantêm uma tabela de alocação (metadata map) que diz: "O bloco A está no disco 3, setor 400".
Isso funciona maravilhosamente bem até você atingir o limite de throughput desses controladores ou o limite de capacidade do chassi. Quando isso acontece, você compra outro storage array. Agora você tem dois silos. Depois três. De repente, você está gerenciando migrações de LUNs manualmente e pagando licenças de software que custam mais que o hardware.
O Ceph propõe uma arquitetura Shared-Nothing. Não há controladores centrais de dados. Não há um "cérebro" único que gargala o I/O. Todo nó é inteligente, todo disco (OSD) é independente. Mas como você localiza um arquivo em um cluster de 5.000 discos sem uma tabela central gigante consultada a cada leitura?
É aqui que entra a elegância matemática e a dor operacional.
A Arquitetura: O Que Você Está Realmente Rodando
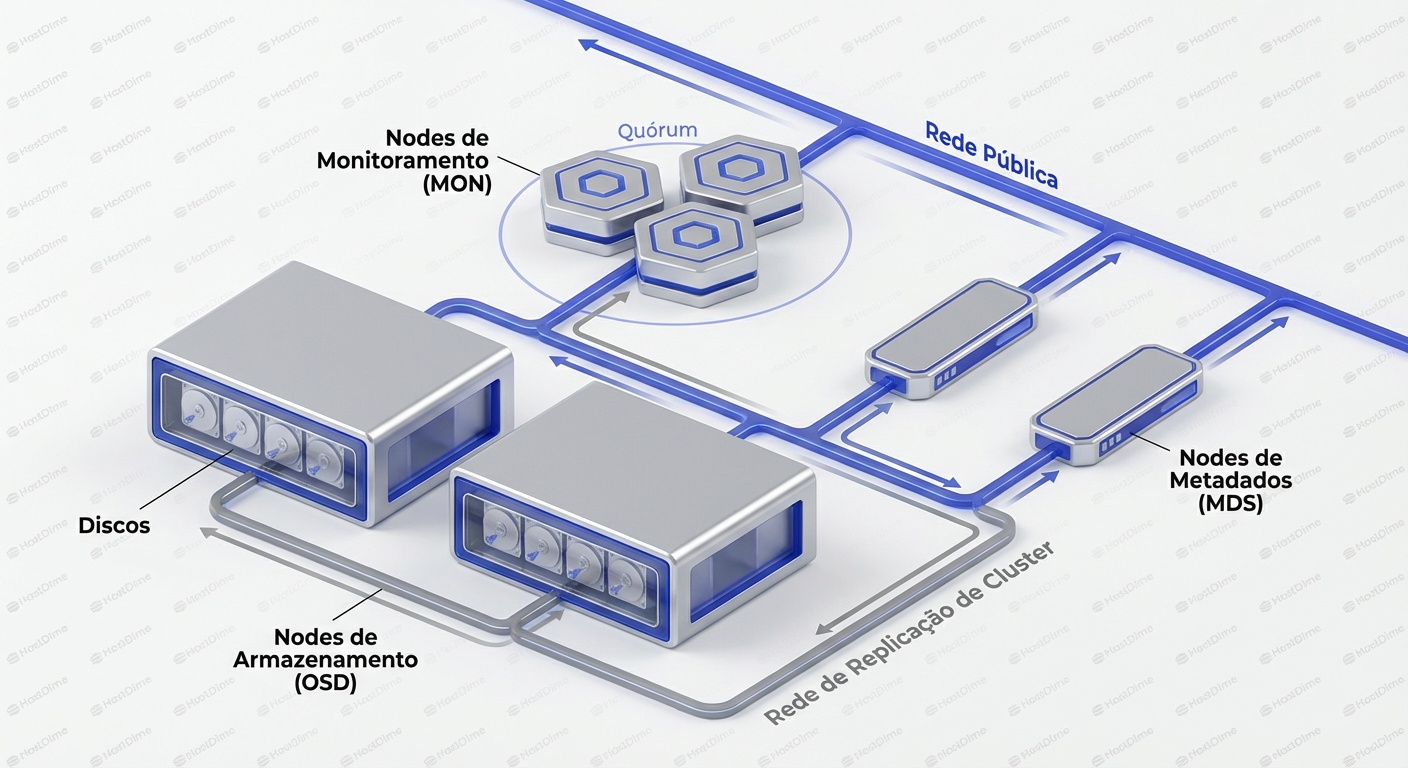
Antes de dissecarmos o algoritmo, precisamos alinhar o modelo mental sobre as peças do tabuleiro. O Ceph não é um bloco monolítico; é uma coleção de daemons que cooperam (e às vezes brigam) entre si.
1. OSD (Object Storage Daemon)
Esta é a unidade fundamental de armazenamento. Grosso modo, 1 Disco Físico = 1 Daemon OSD.
Se você tem um servidor com 24 slots de disco, você terá 24 processos ceph-osd rodando nele. O OSD é responsável por servir dados, replicá-los para outros OSDs, fazer scrub (verificação de integridade) e reportar seu estado aos Monitores.
Nota de campo: Antigamente, o OSD rodava sobre um sistema de arquivos (XFS/ext4) usando FileStore. Isso era lento (double write penalty). Hoje, o padrão é BlueStore, que escreve diretamente no dispositivo de bloco bruto, gerenciando seus próprios metadados no RocksDB.
2. MON (Monitor)
Os MONs não armazenam dados de usuário. Eles armazenam o Cluster Map. Eles são a autoridade da verdade sobre a topologia do cluster. Quem está vivo? Quem morreu? Qual é a versão atual do mapa CRUSH? Eles operam em quórum (Paxos). Você precisa de um número ímpar (geralmente 3 ou 5). Se você perder o quórum dos MONs, seu cluster congela para evitar split-brain.
3. MGR (Manager)
Introduzido nas versões mais recentes (Luminous+), o MGR removeu a carga de métricas e monitoramento dos MONs. Ele lida com o dashboard, métricas do Prometheus e orquestração.
4. RGW, RBD, CephFS (As Interfaces)
O Ceph, lá no fundo, só sabe falar "Objeto" via protocolo RADOS.
- RBD (RADOS Block Device): Pega esses objetos e finge ser um dispositivo de bloco (como um disco virtual) para o Linux ou KVM.
- RGW (RADOS Gateway): Traduz chamadas HTTP (S3/Swift) para objetos RADOS.
- CephFS: Um sistema de arquivos POSIX distribuído que usa o RADOS para dados e um pool separado para metadados.
CRUSH: O Gênio Matemático
Aqui está a mágica. Em um storage tradicional, quando eu quero ler o arquivo foto.jpg, o sistema consulta um índice: foto.jpg -> Endereço X.
No Ceph, não existe esse índice para a localização dos dados. O Ceph usa um algoritmo chamado CRUSH (Controlled Replication Under Scalable Hashing).
O processo é determinístico. Se você tem o nome do objeto e o mapa do cluster, você pode calcular onde ele está. Isso significa que o cliente (librados) faz a conta e fala diretamente com o OSD correto.
O Fluxo da Vida de um Dado
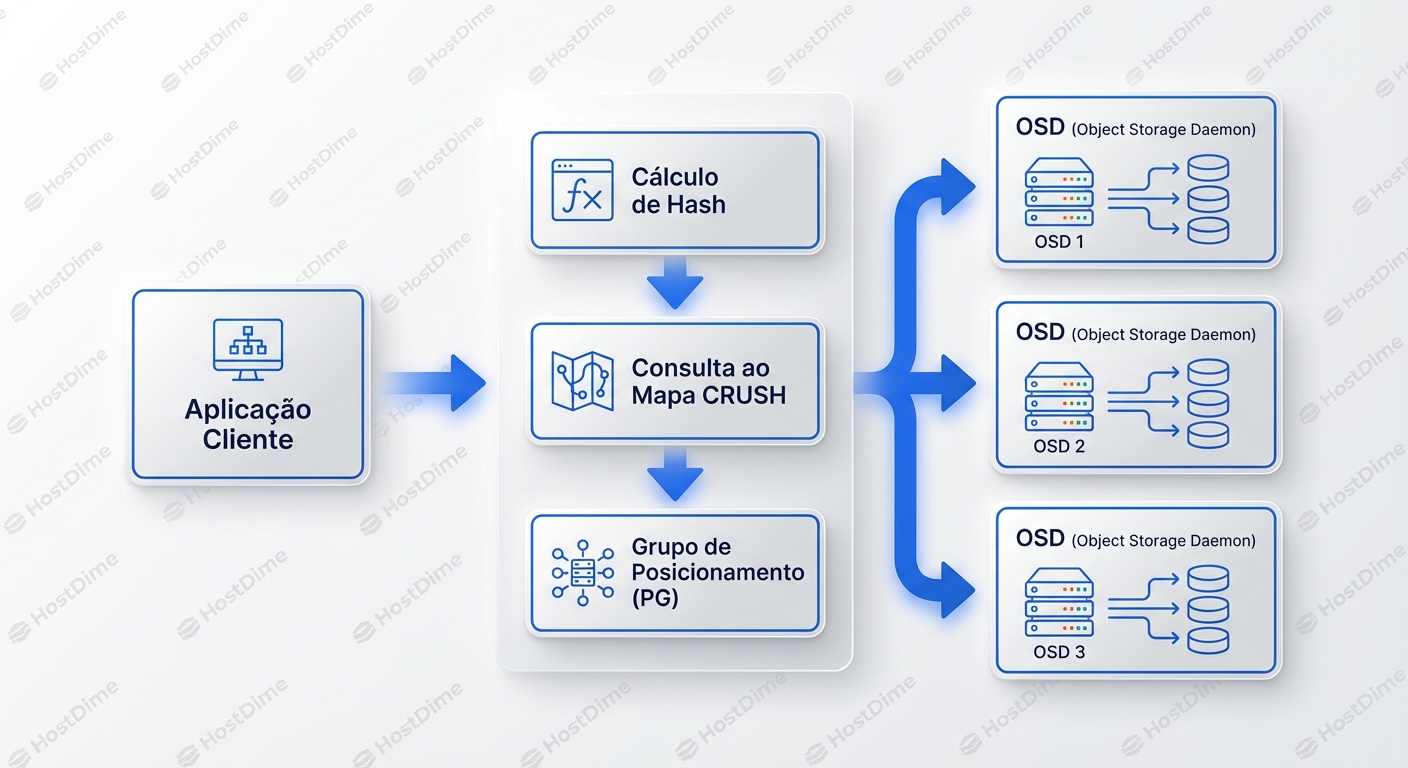
Vamos rastrear uma operação de escrita. Digamos que queremos escrever um objeto chamado my_data.
- Hashing: O Ceph aplica um hash no nome do objeto.
Pool_ID + Hash('my_data') -> Placement Group (PG) - O Papel do PG: O objeto é mapeado para um Placement Group. Pense no PG como um "balde virtual". O cluster tem milhares desses baldes.
- CRUSH Map: Agora, o algoritmo CRUSH pega esse PG ID e consulta o mapa da topologia física (Racks, Hosts, Discos).
- Cálculo de Destino: O CRUSH aplica regras (ex: "Quero 3 cópias, em hosts diferentes").
CRUSH(PG_ID) -> [OSD.5, OSD.12, OSD.44] - Ação: O cliente envia os dados para o OSD.5 (o Primário).
Por que isso é genial?
- Escalabilidade: Como não há lookup table central, não há gargalo de metadados. Milhares de clientes podem calcular destinos simultaneamente sem saturar um servidor mestre.
- Awareness de Topologia: O CRUSH entende sua infraestrutura. Você pode configurar regras como "Uma réplica no Rack 1, outra no Rack 2 e outra no Datacenter B". Se um rack pegar fogo, o CRUSH sabe exatamente quais dados precisam ser recuperados e para onde.
A Dor: O Custo da Abstração
Toda mágica tem um preço. No Ceph, o preço é pago em latência e complexidade cognitiva.
1. A Latência da Rede é Tudo
Diferente de um RAID local, onde a latência é a velocidade do barramento SAS/NVMe, no Ceph uma escrita só é confirmada quando todas as réplicas estão seguras (por padrão).
Se você escreve no OSD.5:
- Cliente envia para OSD.5.
- OSD.5 escreve no seu Journal/WAL.
- OSD.5 envia simultaneamente para OSD.12 e OSD.44.
- OSD.12 e OSD.44 escrevem e confirmam para OSD.5.
- OSD.5 confirma para o Cliente.
Sua latência de escrita é ditada pelo disco mais lento ou pelo link de rede mais congestionado no grupo. Se você não tem uma rede de baixa latência (esqueça 1GbE, estamos falando de 10GbE+ com baixa latência de switch), o Ceph vai parecer lento.
Leitura Relacionada: Entenda como a rede impacta o armazenamento no artigo NIC Offloads: When TSO and LRO Sabotage Storage Latency. O offloading errado pode destruir sua latência de Ceph.
2. O Pesadelo dos Placement Groups (PGs)
A decisão de design mais controversa e confusa do Ceph é o gerenciamento de PGs.
- Poucos PGs: Seus dados não se distribuem uniformemente. Um OSD fica cheio enquanto outro fica vazio. O desempenho de recuperação é ruim.
- Muitos PGs: Cada PG consome recursos de CPU e RAM nos OSDs e nos MONs. Excesso de PGs causa overhead de peering e pode derrubar os MONs por excesso de atualizações de mapa.
Existe uma "regra de ouro" (aproximadamente 100 PGs por OSD), mas ela varia. O Ceph moderno tem um auto-scaler de PGs, mas ele não é infalível. Calcular PGs errados é a maneira #1 de matar a performance de um cluster novo.
3. A Penalidade de CPU (Checksums e RocksDB)
O BlueStore (backend atual do OSD) é incrível, mas pesado. Ele faz checksum de tudo para garantir integridade (diferente de muitos RAIDs de hardware que confiam cegamente no disco).
Além disso, o BlueStore usa o RocksDB (banco chave-valor) para gerenciar metadados internos (onde estão os pedaços do objeto no disco). O RocksDB adora compactação. Compactação custa CPU. Se você colocar o WAL/DB do RocksDB no mesmo disco giratório (HDD) que os dados, a latência de seek do HDD vai destruir sua performance.
Regra de Ouro: Se usar HDDs para dados, sempre coloque o WAL/DB em SSDs/NVMe dedicados. A diferença é noite e dia.
Under the Hood: Diagnosticando Performance
Você é um Sysadmin. O cliente reclama que "o disco está lento". Como você prova que não é o Ceph (ou descobre que é)?
Verificando a Saúde Básica
O comando ceph -s é seu melhor amigo, mas ele engana. "HEALTH_OK" não significa "Performance OK".
ceph -s
# Verificando a distribuição de dados e uso
ceph osd df tree
Olhe para a coluna VAR no ceph osd df. Se um OSD tem 1.0 (100%) da utilização média, ótimo. Se você vê OSDs com 0.5 e outros com 1.5, sua distribuição CRUSH está desbalanceada (provavelmente contagem de PGs errada).
Caçando OSDs Lentos
Um único OSD lento arrasta todo o cluster para baixo (lembre-se da replicação síncrona).
# Mostra latências de commit (disco) e apply (fs/journal)
ceph osd perf
Procure por outliers. Se a média de commit_latency_ms é 2ms e um OSD está mostrando 50ms ou 100ms, esse disco está morrendo ou sobrecarregado. O Ceph não ejeta discos "lentos" automaticamente, apenas discos "mortos". Você precisa intervir.
Observando o I/O em Tempo Real
# Top-like para o cluster
ceph -w
Isso mostra as operações correntes. Se você ver a velocidade de recuperação (recovery) competindo com o I/O de cliente, você tem um problema de priorização.
O Gargalo do RocksDB
Se você usa HDDs e está vendo latências altas de apply_latency, verifique se sua partição de DB não está cheia ou sofrendo spillover.
ceph daemon osd.X perf dump | grep bluefs
Se slow_used_bytes for maior que zero em um setup híbrido, significa que seus metadados (que deveriam estar no SSD) transbordaram para o HDD lento. O desempenho vai cair drasticamente.
Ceph vs. RAID/ZFS: Uma Comparação Brutal
Muitos administradores tentam usar Ceph onde deveriam usar ZFS, ou vice-versa.
| Característica | RAID Hardware / Software | ZFS | Ceph |
|---|---|---|---|
| Escopo | Single Host | Single Host (geralmente) | Cluster Distribuído |
| Latência | Baixíssima (Microsegundos) | Baixa (depende do ARC/L2ARC) | Média/Alta (Milissegundos) |
| Throughput | Limitado pelo barramento/controladora | Limitado pela CPU/RAM do host | Escala linearmente com nós |
| Ponto Único de Falha | Controladora / Backplane | Host / HBA | Nenhum (se bem arquitetado) |
| Complexidade | Baixa | Média | Insana |
| Custo de Entrada | Baixo | Médio (precisa de RAM ECC) | Alto (mínimo 3 nós, rede 10G) |
Leitura Relacionada: Para entender as alternativas locais, veja ZFS vs RAID: Uma Análise Detalhada das Diferenças e RAID por Software (mdadm): Desempenho, Custos e Limitações.
Cenários de Uso: Quando o Ceph Brilha (e quando falha)
Onde o Ceph é Rei
- OpenStack / Nuvem Privada: É o padrão de fato. O suporte a Cinder (Block) e Glance (Images) é nativo e robusto. O recurso de Copy-on-Write permite subir 100 VMs a partir da mesma imagem base em segundos.
- Kubernetes (Rook): O operador Rook torna o Ceph gerenciável dentro do K8s. Ele fornece PVCs (Persistent Volume Claims) dinâmicos para Pods.
- Object Storage (S3 on-prem): Se você precisa de um S3 local para conformidade ou velocidade, o RGW do Ceph é excelente e escala para Petabytes.
- Data Lake / Archival: Discos baratos, Erasure Coding (em vez de replicação 3x) para economizar espaço, e você tem um storage frio resiliente.
Onde o Ceph é uma Armadilha
- Bancos de Dados OLTP de Alta Performance: Tentar rodar um Oracle ou PostgreSQL de alta frequência diretamente sobre RBD sem um tuning agressivo (ou hardware All-Flash) vai te frustrar. A latência de rede mata as transações.
Leitura Relacionada: Veja IOPS, Throughput e Latência: O Triângulo Mágico do Storage para entender por que IOPS alto não salva você de latência alta.
- Clusters Pequenos (2-3 Nós): O Ceph precisa de quórum. Com 2 nós, você não tem quórum em falha. Com 3 nós, se um cai e o outro tem um bad block durante a recuperação, você perde dados. O "sweet spot" começa em 5+ nós.
- Windows Clients: O suporte nativo a RBD no Windows é recente e ainda menos maduro que no Linux. Geralmente requer gateways iSCSI intermediários, o que adiciona mais um ponto de falha e latência.
A Realidade do Hardware: Não Economize Aqui
Se você decidir implementar Ceph, não trate o hardware como lixo.
- Rede: Separe a rede de Cluster (replicação backend) da rede de Public (clientes). Se o rebalanceamento de dados saturar sua rede, seus clientes vão sofrer timeout. Use LACP ou Bonding com sabedoria.
Leitura Relacionada: LACP e Bonding: O Mito da Velocidade e o Gargalo do Single-Stream.
- Controladoras de Disco: JAMAIS use RAID de hardware para os discos OSD. O Ceph precisa falar diretamente com o disco para gerenciar erros. Coloque suas controladoras em modo HBA / IT Mode / Passthrough. Se o Ceph não conseguir ver os dados SMART do disco, você está voando às cegas.
- Memória: O Ceph consome cerca de 1GB de RAM por TB de dados brutos (regra prática antiga, mas ainda válida para dimensionamento seguro). O BlueStore cache adora RAM.
Veredito
O Ceph é uma maravilha da engenharia de software. O algoritmo CRUSH resolve um dos problemas mais difíceis da computação distribuída: como localizar dados sem um coordenador central. Isso permite que o Ceph escale para exabytes de dados e sobreviva a catástrofes de hardware que destruiriam SANs tradicionais.
No entanto, essa resiliência não é gratuita. O Ceph transforma problemas de hardware em problemas de software e rede. Ele exige administradores que entendam não apenas de armazenamento, mas de redes Linux, kernel tuning e sistemas distribuídos.
Use o Ceph se: Você precisa de escala horizontal, integração com APIs de nuvem (OpenStack/K8s) e resiliência a prova de balas, e está disposto a pagar o custo em latência e complexidade.
Evite o Ceph se: Você tem 10TB de dados, precisa de latência de NVMe local, tem uma equipe pequena ou infraestrutura de rede de 1GbE. Nesse caso, um servidor robusto com ZFS ou um SAN tradicional será mais barato, mais rápido e mais fácil de manter.
Próximos Passos
Se você vai entrar nessa toca do coelho:
- Comece com o
ceph-deployoucephadmem máquinas virtuais para entender o conceito. - Estude profundamente o CRUSH Map. Saber editar esse mapa manualmente é o que separa os usuários de Ceph dos administradores de Ceph.
- Planeje sua estratégia de Failure Domain. Você quer sobreviver à perda de um disco, de um host ou de um rack inteiro? O CRUSH permite escolher, mas você precisa ter o hardware físico para suportar a escolha.

David Ross
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.