Ceph BlueStore Internals: A Anatomia do IOPS e o Layout de WAL/DB
Pare de adivinhar o tamanho do seu block.db. Entenda como o BlueStore realmente grava dados, o impacto do RocksDB no IOPS e como evitar o pesadelo do spillover.
Se você administra clusters Ceph, já ouviu a promessa: "BlueStore é mais rápido porque fala diretamente com o disco". Isso é verdade, mas é uma meia-verdade perigosa. Remover o sistema de arquivos intermediário (como o XFS no antigo FileStore) eliminou a penalidade de dupla escrita para alguns casos, mas introduziu uma complexidade brutal de gerenciamento de metadados e alocação.
Não existe mágica em storage, existe apenas o deslocamento de gargalos. No BlueStore, você trocou a complexidade do Journal do FileStore pela complexidade do LSM-Tree do RocksDB. Se você não entender como seus dados trafegam fisicamente entre o WAL, o DB e o Block device, você está apenas adivinhando a performance do seu cluster. Vamos dissecar a anatomia do IOPS e parar de tratar o Ceph como uma caixa preta.
O que é o Ceph BlueStore? O BlueStore é o backend de armazenamento de objetos padrão do Ceph, projetado para interagir diretamente com dispositivos de bloco brutos (raw block devices), eliminando a sobrecarga de sistemas de arquivos tradicionais POSIX. Ele utiliza um banco de dados RocksDB embarcado para gerenciar metadados de objetos (omap) e um sistema de arquivos minimalista chamado BlueFS para permitir que o RocksDB rode diretamente no disco, visando otimizar o caminho de I/O e a consistência dos dados.
O Modelo Conceitual do BlueStore: Adeus Sistema de Arquivos
Para operar o BlueStore corretamente, você precisa esquecer o conceito de arquivos e pastas. O OSD (Object Storage Daemon) agora é dono do disco inteiro. Ele não pede ao Kernel para "escrever este arquivo em /var/lib/ceph/...". Ele diz ao disco: "escreva estes bytes no setor X".
Isso significa que o Ceph agora é responsável por tudo o que o sistema de arquivos fazia: alocação de espaço, detecção de bad blocks e, crucialmente, o gerenciamento de metadados. Para fazer isso, o BlueStore divide o mundo em dois tipos de dados:
Dados do Objeto (Payload): O arquivo que o usuário enviou.
Metadados e Omap: Quem é o dono, onde está, atributos estendidos e chaves-valor.
Para gerenciar a parte 2, o Ceph engoliu o RocksDB. E é aqui que a maioria dos problemas de performance começa. O RocksDB é um banco de dados do tipo Log-Structured Merge-tree (LSM). Ele é fantástico para escritas rápidas, mas exige compactação constante (CPU) e amplificação de escrita.
O Caminho da Escrita no BlueStore e o Papel do RocksDB
Nem todo IOPS nasce igual. A maior falácia de planejamento em Ceph é tratar escritas sequenciais grandes da mesma forma que escritas aleatórias pequenas. O BlueStore bifurca esses caminhos drasticamente.
Big Writes (Assíncronos e Diretos)
Se você envia um objeto grande (por padrão, maior que 64KB, definido por bluestore_min_alloc_size_hdd), o BlueStore escreve os dados diretamente na área de dados do disco (block). Ele não passa pelo RocksDB para o payload. Apenas os metadados (ponteiros de onde o dado ficou) vão para o RocksDB. É eficiente e "zero-copy" na perspectiva do buffer.
Small Writes e Overwrites (Deferred Writes)
Se a escrita é menor que o tamanho mínimo de alocação (ex: 4KB), escrever diretamente no disco seria um desperdício colossal de espaço e IOPS (fragmentação). Neste caso, o BlueStore faz algo inteligente e perigoso: ele escreve os dados e os metadados dentro do WAL (Write Ahead Log) do RocksDB.
Isso transforma uma escrita aleatória lenta em uma escrita sequencial rápida no WAL. Posteriormente, o processo de "flush" move esses dados para o local definitivo no disco lento.
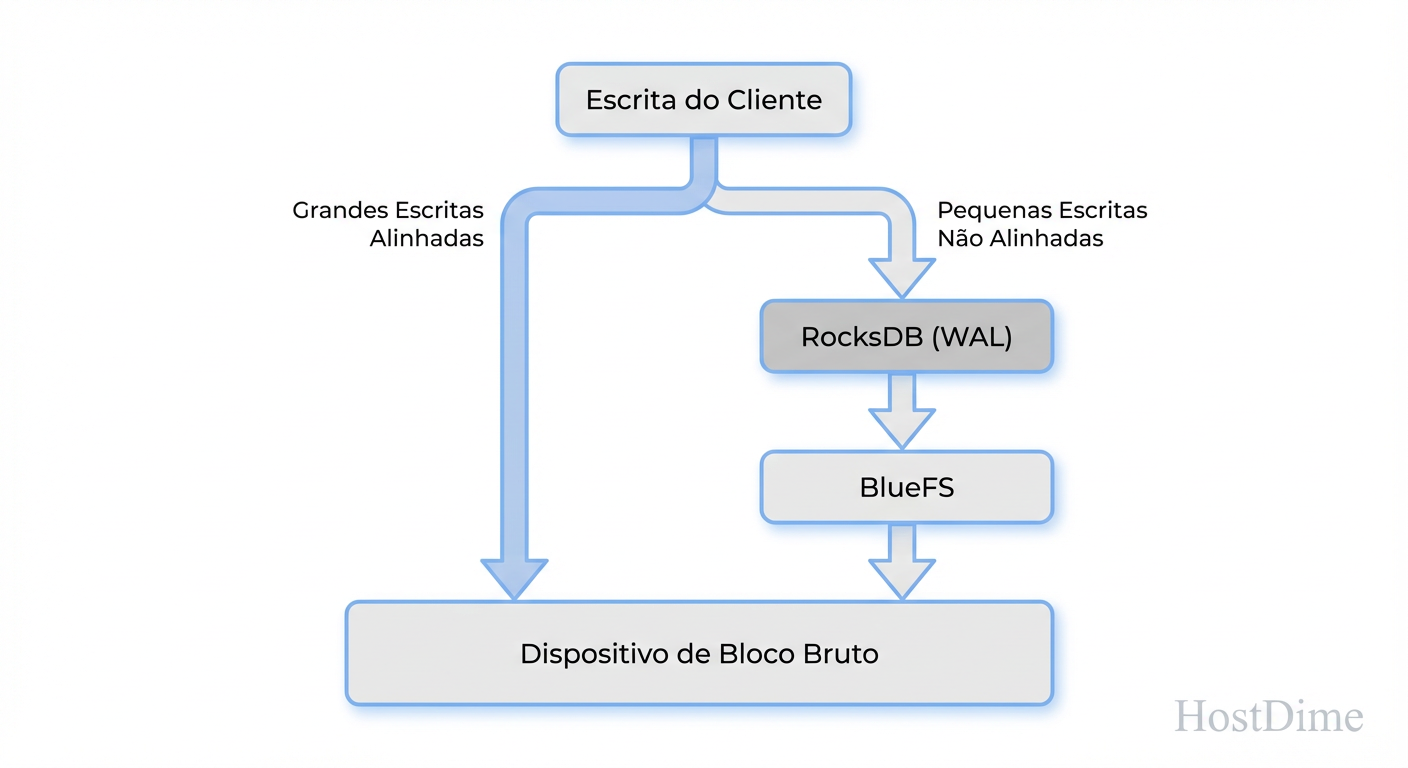 Figura: O Caminho da Escrita no BlueStore: Por que pequenas escritas randômicas dependem inteiramente da velocidade do seu dispositivo de DB/WAL.
Figura: O Caminho da Escrita no BlueStore: Por que pequenas escritas randômicas dependem inteiramente da velocidade do seu dispositivo de DB/WAL.
Isso significa que, para workloads de banco de dados (RBD com blocos de 4KB ou 8KB), a performance do seu cluster é ditada quase inteiramente pela velocidade do dispositivo onde reside o seu WAL/DB, não pelo disco de dados principal.
A Hierarquia Física: block, block.db e block.wal
Quando provisionamos um OSD BlueStore, lidamos com três partições lógicas. Entender a física por trás delas evita compras de hardware erradas.
block (Main Device):
- O que é: Onde vivem os dados frios e grandes.
- Hardware: Geralmente HDDs (em clusters híbridos) ou SSDs QLC/TLC de alta densidade.
- Função: Capacidade bruta.
block.db (RocksDB Metadata):
- O que é: Armazena os níveis (SST files) do RocksDB. Contém o mapa de onde estão os dados no
blocke chaves de omap. - Hardware: Deve ser NVMe ou SSD de alta resistência.
- Crítico: Se isso encher, o cluster degrada.
- O que é: Armazena os níveis (SST files) do RocksDB. Contém o mapa de onde estão os dados no
block.wal (Write Ahead Log):
- O que é: O journal de transações do RocksDB. A persistência imediata antes de qualquer coisa ser confirmada ao cliente.
- Mito: Você raramente precisa de um dispositivo separado para isso.
- Realidade: O WAL é apenas o arquivo de log mais recente do RocksDB. Por padrão, ele vive dentro da partição
block.db. Separar o WAL do DB só faz sentido se você tiver um dispositivo de latência ultra-baixa (ex: Intel Optane) e um DB em SSD convencional. Se ambos forem NVMe, separar é adicionar pontos de falha sem ganho de performance.
Regra de Ouro: O
block.waldeve ser o dispositivo mais rápido do sistema. Oblock.dbdeve ser tão rápido quanto o WAL ou ligeiramente inferior. Oblockpode ser lento.
O Assassino de Performance: Spillover do RocksDB
Aqui reside o maior risco operacional do BlueStore. O RocksDB tem níveis (L0, L1, L2...). Quando o nível L0 enche na memória, ele é "flushado" para o disco (block.db). Quando o block.db enche, ocorre a compactação.
Mas o que acontece se a partição que você criou para o block.db (digamos, 30GB no seu NVMe) ficar cheia? O RocksDB não para. Ele começa a escrever os novos arquivos SST na partição block principal.
Se o seu block principal é um HDD mecânico (spinning rust), você acabou de forçar seu banco de dados de metadados de alta performance a competir por IOPS com a leitura de dados frios em um disco de 7200 RPM.
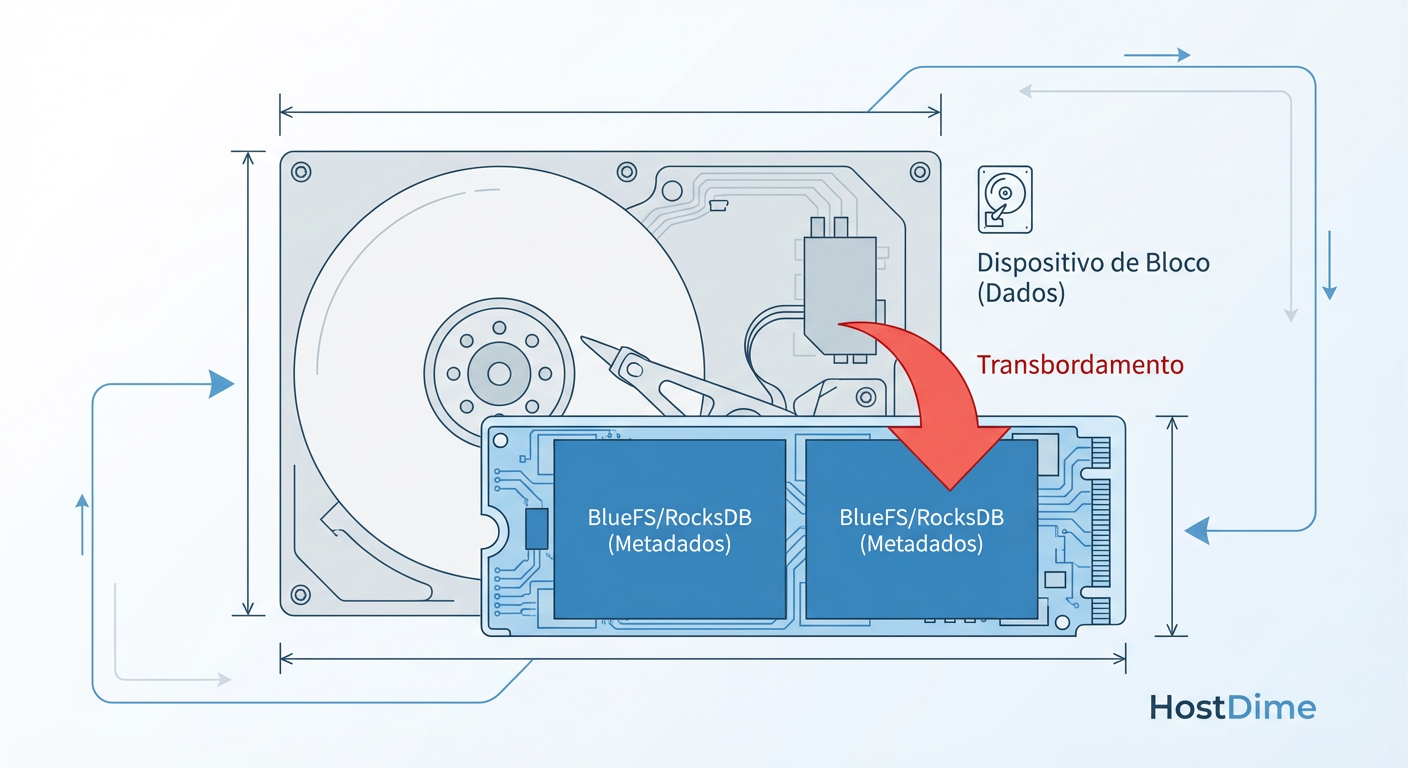 Figura: O Fenômeno do Spillover: O momento exato em que seu cluster NVMe híbrido passa a ter performance de HDD puro.
Figura: O Fenômeno do Spillover: O momento exato em que seu cluster NVMe híbrido passa a ter performance de HDD puro.
O resultado é catastrófico. A latência de commit sobe de sub-milissegundos para centenas de milissegundos. O cluster não cai, mas a aplicação sente como se tivesse caído. Isso é o Spillover.
Tabela: O Custo do Spillover e Layouts
| Cenário de Layout | Latência Média (Small Write) | Risco Operacional | Custo |
|---|---|---|---|
| Colocated (Tudo no HDD) | Alta (~10-20ms) | Baixo (Simples) | Baixo |
| Híbrido (DB/WAL em NVMe) | Baixa (~0.5ms) | Médio (Dimensionamento do DB) | Médio |
| Híbrido com Spillover (DB Cheio) | Imprevisível (10ms - 500ms+) | Crítico (Performance Cliff) | Médio (Mal utilizado) |
| All-Flash (Tudo SSD/NVMe) | Muito Baixa (<0.3ms) | Baixo | Alto |
Dimensionamento Pragmático: A Regra dos 4% vs. Realidade
A documentação do Ceph historicamente sugeria: "Dimensione seu block.db com 4% da capacidade do block principal". Se você tem um HDD de 10TB, precisaria de 400GB de NVMe.
Por que ser cético com isso?
Workload Dependente: Se você usa RGW (Object Gateway) para armazenar vídeos de 5GB, seus metadados são minúsculos. Você precisará de muito menos que 1%.
RBD Fragmentado: Se você usa RBD para volumes de VM com muita escrita aleatória e snapshots, o RocksDB incha. Você pode precisar de mais de 4%.
Compactação: O RocksDB compacta dados. O espaço usado varia.
A abordagem pragmática: Não tente acertar o byte exato. Armazenamento NVMe é barato o suficiente hoje.
Para HDDs de até 8TB: Aloque pelo menos 60GB-100GB para DB.
Para HDDs de 14TB+: Aloque 300GB se possível.
Nunca aloque menos que 30GB, ou o RocksDB passará a vida fazendo compactação agressiva, queimando CPU do OSD.
Diagnóstico e Evidência: O Que Medir
Não confie no "acho". Verifique se seus OSDs estão sofrendo de spillover ou compactação lenta.
1. Verificando Spillover (BlueFS)
O comando abaixo interroga o OSD para ver onde o BlueFS (sistema de arquivos do DB) está alocando espaço.
# Execute no host do OSD
ceph daemon osd.0 bluefs stats
Procure na saída JSON por slow_dev_total_bytes_written. Se este número for maior que zero e estiver crescendo, seus metadados transbordaram para o disco lento. Você tem um problema de dimensionamento.
2. Monitorando a Latência de Commit
Se o WAL estiver lento, o commit_latency_ms dispara.
ceph daemon osd.0 perf dump | grep -A 5 "op_w_latency"
Compare op_w_latency (latência total vista pelo cliente) com op_w_process_latency. Se a diferença for enorme, o tempo está sendo gasto esperando o disco (WAL/DB) confirmar a gravação.
3. Compactação do RocksDB
Se a CPU do OSD estiver em 100% mas o IOPS estiver baixo, o RocksDB pode estar em um "compaction storm".
ceph daemon osd.0 perf dump | grep "compact"
Valores altos em compact_queue_len indicam que o OSD não está conseguindo organizar os metadados rápido o suficiente, provavelmente porque o dispositivo block.db é lento demais ou pequeno demais.
Referências & Leitura Complementar
Para aprofundar, vá direto à fonte. Evite tutoriais genéricos de 2018.
BlueStore Internals (Ceph Docs): Documentação oficial da arquitetura de objetos e alocação.
RocksDB Tuning Guide (Facebook/Meta): Entender como memtables e SST files funcionam é essencial para tunar o Ceph.
Ceph Performance Benchmarking (CERN Tech Blog): Estudos de caso reais sobre o impacto de separar WAL/DB em clusters de petabytes.
SPDK e NVMe Drivers: Para entender como o BlueStore evoluiu para suportar SPDK (Storage Performance Development Kit) e evitar syscalls do kernel.

Marcelo Furtado
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.