Ceph BlueStore vs. FileStore: Arquitetura de OSDs e Performance Real

Entenda a física por trás do armazenamento no Ceph. Compare BlueStore e FileStore, elimine a penalidade de dupla escrita e aprenda a dimensionar WAL/DB em NVMe.
Você chega no data center — ou abre o terminal remoto — e o sintoma é clássico: o cluster Ceph está engasgando. A latência de escrita está nas alturas, os discos estão gritando com 100% de utilização, mas o throughput real de dados é decepcionante. O iostat mostra uma atividade frenética que não corresponde à carga de trabalho da aplicação.
Se você está rodando uma versão antiga do Ceph ou herdou um cluster legado, a causa raiz provavelmente não é o disco, nem a rede, nem a CPU. O culpado é a arquitetura de armazenamento subjacente. Você está testemunhando a morte lenta do FileStore e a necessidade forense de entender por que o BlueStore se tornou o padrão.
Não vamos falar de "melhores práticas" aqui. Vamos dissecar a anatomia de um OSD (Object Storage Daemon) para entender onde os IOs estão sendo assassinados e como a mudança de arquitetura elimina o intermediário.
O que é Ceph BlueStore?
BlueStore é o backend de armazenamento padrão do Ceph (desde a versão Luminous) que gerencia dados diretamente em dispositivos de bloco bruto (raw block devices), eliminando a necessidade de um sistema de arquivos POSIX subjacente (como XFS ou ext4). Ao remover a camada do sistema de arquivos, o BlueStore evita a penalidade de dupla escrita, melhora a latência e permite um controle granular sobre o fluxo de I/O e metadados via RocksDB.
O Problema da Dupla Escrita no FileStore
Para entender por que o BlueStore é necessário, precisamos examinar o cadáver do FileStore. No modelo antigo, cada OSD do Ceph dependia de um sistema de arquivos convencional (geralmente XFS) para armazenar os objetos como arquivos no disco.
O problema forense aqui é a atomicidade. O Ceph precisa garantir que uma transação (escrita de objeto + atualização de metadados) seja atômica: ou tudo acontece, ou nada acontece. Sistemas de arquivos POSIX como XFS não oferecem essa garantia nativa para operações complexas de objetos distribuídos.
Para contornar isso, o FileStore introduziu o Journal.
O dado chega e é escrito sequencialmente no Journal (rápido).
O FileStore confirma a escrita para o cliente (Ack).
O FileStore lê do Journal e escreve o dado na partição de dados XFS (lento e aleatório).
O sistema de arquivos (XFS) faz seu próprio journaling interno.
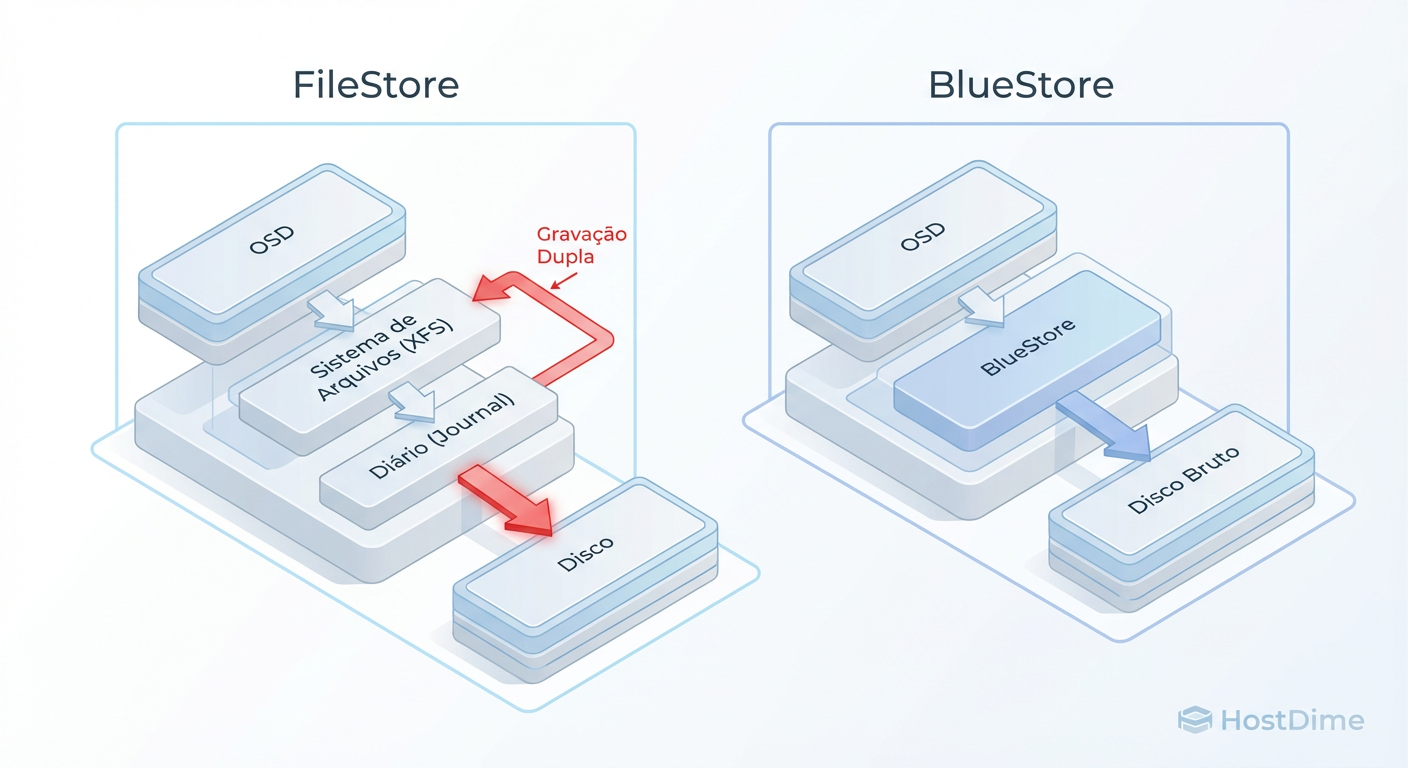 Figura: Fluxo de IO: A penalidade de dupla escrita do FileStore (esquerda) vs. o acesso direto do BlueStore (direita).
Figura: Fluxo de IO: A penalidade de dupla escrita do FileStore (esquerda) vs. o acesso direto do BlueStore (direita).
O resultado é a Penalidade de Dupla Escrita (Double Write Penalty). Para cada megabyte de dado que você quer salvar, você paga o custo de IO de escrever esse dado duas vezes no disco. Em HDDs rotacionais, onde IOPS são moeda rara, isso é devastador. O FileStore transformava um disco de 100 IOPS em um disco de 50 IOPS efetivos para escritas.
Arquitetura BlueStore: O Caminho Curto ao Raw Block Device
O BlueStore foi uma reescrita completa da camada de persistência. A premissa investigativa foi: "E se o Ceph parasse de fingir que é um aplicativo rodando sobre um sistema de arquivos e agisse como o próprio sistema de arquivos?"
No BlueStore, o OSD toma posse exclusiva do disco (ou partição). Não há XFS, não há ext4. O Ceph escreve diretamente nos setores do disco (Raw Block Device).
Como o BlueStore elimina a dupla escrita
Ao controlar o dispositivo de bloco diretamente, o BlueStore sabe exatamente onde os dados estão.
Grandes Escritas (Writes > 64KB): O BlueStore escreve os dados diretamente no local final no disco e apenas atualiza os metadados no banco de dados. Custo de IO: 1x (mais uma pequena fração para metadados).
Pequenas Escritas (Deferred Writes): Para escritas muito pequenas (que causariam fragmentação severa) ou sobrescritas, o BlueStore ainda usa um mecanismo similar a um journal (o WAL - Write Ahead Log) para garantir atomicidade, mas isso é uma exceção otimizada, não a regra para todo o tráfego.
O Papel do RocksDB e BlueFS nos Metadados
Se removemos o sistema de arquivos (XFS), quem gerencia os metadados? Quem sabe que o objeto video_01 está nos setores 500 a 1500?
Aqui entra a complexidade elegante do BlueStore. Ele delega o gerenciamento de metadados internos (mapas de objetos, estatísticas, checksums) para o RocksDB, um banco de dados chave-valor de alta performance (criado pelo Facebook).
Mas há um problema recursivo: o RocksDB foi feito para rodar em cima de um sistema de arquivos. Ele espera abrir arquivos, não acessar blocos brutos.
A solução foi criar o BlueFS. O BlueFS é um sistema de arquivos mínimo, rodando em espaço de usuário (user space), que implementa apenas as chamadas de API que o RocksDB precisa. Ele serve como uma "camada de compatibilidade" ultra-leve entre o RocksDB e o dispositivo de bloco bruto.
O Fluxo de IO do BlueStore simplificado:
Dado chega.
Dado é escrito no espaço livre do disco (Block Device).
A localização e checksum desse dado são gravados no RocksDB.
O RocksDB persiste isso via BlueFS.
Estratégia Híbrida: Separando WAL e DB para NVMe
Como investigadores de performance, sabemos que misturar cargas de trabalho aleatórias (metadados/DB) com cargas sequenciais (dados brutos) em um HDD é pedir para ter latência alta.
O BlueStore permite isolar fisicamente essas cargas. Essa é a configuração "Gold Standard" para clusters de custo-benefício (HDDs para capacidade, NVMe para velocidade).
Um OSD BlueStore pode ser fatiado em três componentes lógicos:
Block (Slow): Onde os dados do usuário vivem (HDD grande).
Block.DB (Fast): Onde o RocksDB vive (metadados).
Block.WAL (Fastest): Write Ahead Log do RocksDB.
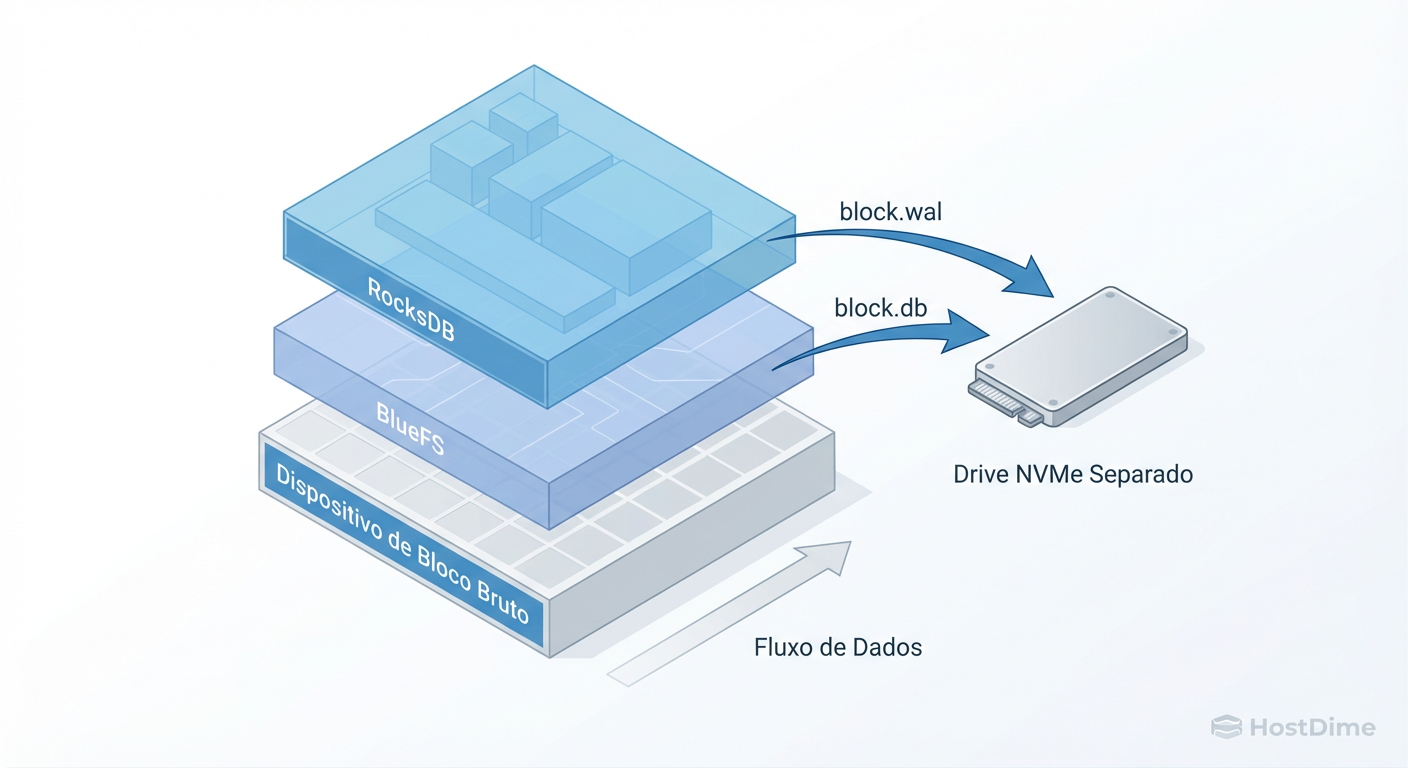 Figura: Anatomia de um OSD BlueStore Híbrido: Separando metadados (RocksDB) dos dados brutos.
Figura: Anatomia de um OSD BlueStore Híbrido: Separando metadados (RocksDB) dos dados brutos.
O Risco do Dimensionamento (Spillover)
Se você alocar uma partição muito pequena para o block.db no seu NVMe, o RocksDB vai encher. Quando isso acontece, o BlueStore não para; ele começa a despejar (spillover) os metadados no HDD lento (block).
Sintoma: O cluster voa por meses, e de repente, a performance cai para níveis de FileStore. Causa: O DB vazou para o HDD. O braço do disco agora está competindo entre ler dados de 4MB e buscar chaves de 4KB do RocksDB.
Callout de Risco: Em cenários híbridos, a perda do dispositivo NVMe que segura o
block.dbresulta na perda de todos os OSDs associados a ele. Se um NVMe segura o DB de 4 HDDs e o NVMe morre, você perdeu 4 OSDs instantaneamente. Planeje seu domínio de falha (failure domain) de acordo.
Migração e Operação: O Processo Destrutivo
Muitos administradores hesitam aqui. Não existe "upgrade in-place" de FileStore para BlueStore. Como o FileStore usa XFS e o BlueStore usa Raw Block, a estrutura de disco é incompatível.
A migração é um processo de destruição e recriação.
O Ciclo de Vida da Migração
Para converter um OSD, você deve:
Marcar o OSD como
outdo cluster (o Ceph vai rebalancear os dados para outros OSDs - isso gera tráfego de rede intenso).Esperar a saúde do cluster voltar a
HEALTH_OK.Parar o daemon do OSD.
Destruir o OSD e limpar o disco (zap).
Criar um novo OSD BlueStore no mesmo disco.
# 1. Tirar o OSD antigo (FileStore)
ceph osd out osd.12
# ... aguarde a recuperação dos dados ...
# 2. Parar e destruir
systemctl stop ceph-osd@12
ceph osd crush remove osd.12
ceph auth del osd.12
ceph osd rm 12
# 3. Limpar o disco (CUIDADO: Isso apaga tudo)
ceph-volume lvm zap /dev/sdX
# 4. Criar novo OSD BlueStore (com DB em um dispositivo dedicado, opcional)
ceph-volume lvm create --bluestore --data /dev/sdX --block.db /dev/nvme0n1p1
Métricas que Importam: Latência de Commit vs. Apply
No FileStore, monitorávamos obsessivamente a latência do journal. No BlueStore, as métricas mudaram. Ao usar ceph daemon osd.X perf dump, foque nestes indicadores para provar a performance:
state_kv_committing: Quanto tempo o sistema gasta esperando o RocksDB comitar a transação. Se isso estiver alto, seu NVMe de DB está engargalado ou o DB vazou para o HDD.state_deferred_cleanup: Indica quanto trabalho de limpeza de escritas diferidas está pendente.Latência de Leitura (Read Latency): O BlueStore geralmente não melhora a leitura drasticamente comparado ao FileStore (ambos leem do disco), mas evita o overhead de stat do sistema de arquivos.
Tabela Comparativa: FileStore vs. BlueStore
| Característica | FileStore (Legado) | BlueStore (Moderno) |
|---|---|---|
| Backend | Sistema de Arquivos (XFS/ext4) | Raw Block Device |
| Caminho de Escrita | Journal -> Filesystem (Dupla Escrita) | Direto no Bloco (Maioria) + WAL (Pequenas) |
| Penalidade de IO | ~2x (100% overhead) | ~1.1x (Overhead mínimo) |
| Metadados | Atributos estendidos (XATTRs) do FS | RocksDB (Key-Value Store) |
| Uso de CPU | Alto (Context switch do Kernel/FS) | Otimizado (Menos syscalls de FS) |
| Recuperação | Lenta (Fsck no XFS pode demorar horas) | Rápida (Replay do RocksDB/WAL) |
Veredito Forense
A evidência é clara. O FileStore sofre de ineficiência estrutural devido à imposição de uma camada POSIX onde ela não é necessária. O BlueStore remove essa camada, tratando o disco pelo que ele é: um meio de armazenamento de blocos.
Para operadores de storage, a migração não é opcional se você busca performance e longevidade do hardware. A redução na amplificação de escrita (write amplification) não apenas acelera o cluster, mas literalmente estende a vida útil dos seus SSDs e HDDs ao escrever menos dados fisicamente.
Pense no BlueStore não como uma "nova feature", mas como a remoção de um "bug" arquitetural de 20 anos chamado sistema de arquivos de uso geral.
Referências & Leitura Complementar
Ceph Documentation: BlueStore Architecture and Configuration. Documentação oficial detalhando parâmetros de tuning do RocksDB.
Sage Weil (Ceph Creator): BlueStore: A New Storage Backend for Ceph. Paper acadêmico apresentando a arquitetura de bloco direto.
RocksDB Tuning Guide: Wiki do GitHub do Facebook/Meta sobre como ajustar a compactação e memtables para cargas de trabalho de escrita pesada.
RFC 3720 (iSCSI): Contexto sobre protocolos de bloco, útil para entender como o Ceph se comporta quando exposto via RBD.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.