Ceph CRUSH Map e Placement Groups: A Matemática da Performance de Storage
Esqueça o controlador RAID. Aprenda a otimizar a distribuição de dados no Ceph ajustando CRUSH Maps e Placement Groups (PGs) para latência baixa e recuperação rápida.
Se você gerencia um cluster Ceph e trata o CRUSH Map como uma "caixa preta" que funciona por magia, você está operando às cegas. A diferença entre um cluster que entrega 100.000 IOPS consistentes e um que sofre com latência de cauda (tail latency) inexplicável reside quase sempre na matemática da distribuição de dados.
Não estamos aqui para discutir assistentes de instalação ou interfaces gráficas. Como engenheiros de performance, precisamos dissecar como o algoritmo de hashing determinístico do Ceph interage com a topologia física e como a escolha do número de Placement Groups (PGs) afeta diretamente o uso de CPU e a latência de gravação.
O Ceph não "sabe" onde seus dados estão armazenados em uma tabela gigante. Ele calcula onde eles deveriam estar. Entender essa distinção é o primeiro passo para parar de adivinhar e começar a medir.
O que é o CRUSH e Placement Groups?
O algoritmo CRUSH (Controlled Replication Under Scalable Hashing) é uma função pseudo-aleatória determinística que permite aos clientes e nós de armazenamento calcularem a localização dos dados sem depender de um servidor central de metadados (gargalo comum). Os Placement Groups (PGs) atuam como fragmentos lógicos (shards) que agrupam milhões de objetos antes de mapeá-los aos OSDs físicos, servindo como uma camada de indireção essencial para equilibrar a distribuição de carga e limitar o consumo de memória do cluster.
A Matemática do CRUSH: Uma Função, Não uma Tabela
A maioria dos sistemas de arquivos tradicionais ou SANs legadas opera com base em tabelas de alocação. Se você quer o arquivo X, o sistema consulta um índice que diz "O arquivo X está no Bloco Y do Disco Z". Isso escala mal. À medida que você adiciona petabytes, a tabela de metadados se torna o gargalo de performance e um ponto único de falha.
O Ceph elimina isso através de cálculo. Quando uma aplicação escreve um objeto, o cluster executa a seguinte lógica simplificada:
Hash do Objeto: O nome do objeto (ex:
video.mp4) passa por um hash.Módulo do PG: O resultado é dividido pelo número de PGs para determinar a qual grupo lógico ele pertence.
CRUSH Map: O algoritmo CRUSH pega esse ID do PG e, consultando o mapa da topologia atual (quais discos estão vivos, quais regras de replicação existem), determina a lista ordenada de OSDs (Object Storage Daemons) onde os dados serão gravados.
$$ OSDs = CRUSH( Hash(NomeDoObjeto) % NumeroDePGs, ClusterMap ) $$
Essa abordagem significa que o cliente sabe exatamente com qual disco falar sem perguntar a ninguém. No entanto, isso introduz um custo de CPU no cliente e nos nós de armazenamento. Se o seu mapa for complexo demais ou mal desenhado, o cálculo de roteamento adiciona latência antes mesmo do primeiro bit ser gravado no disco.
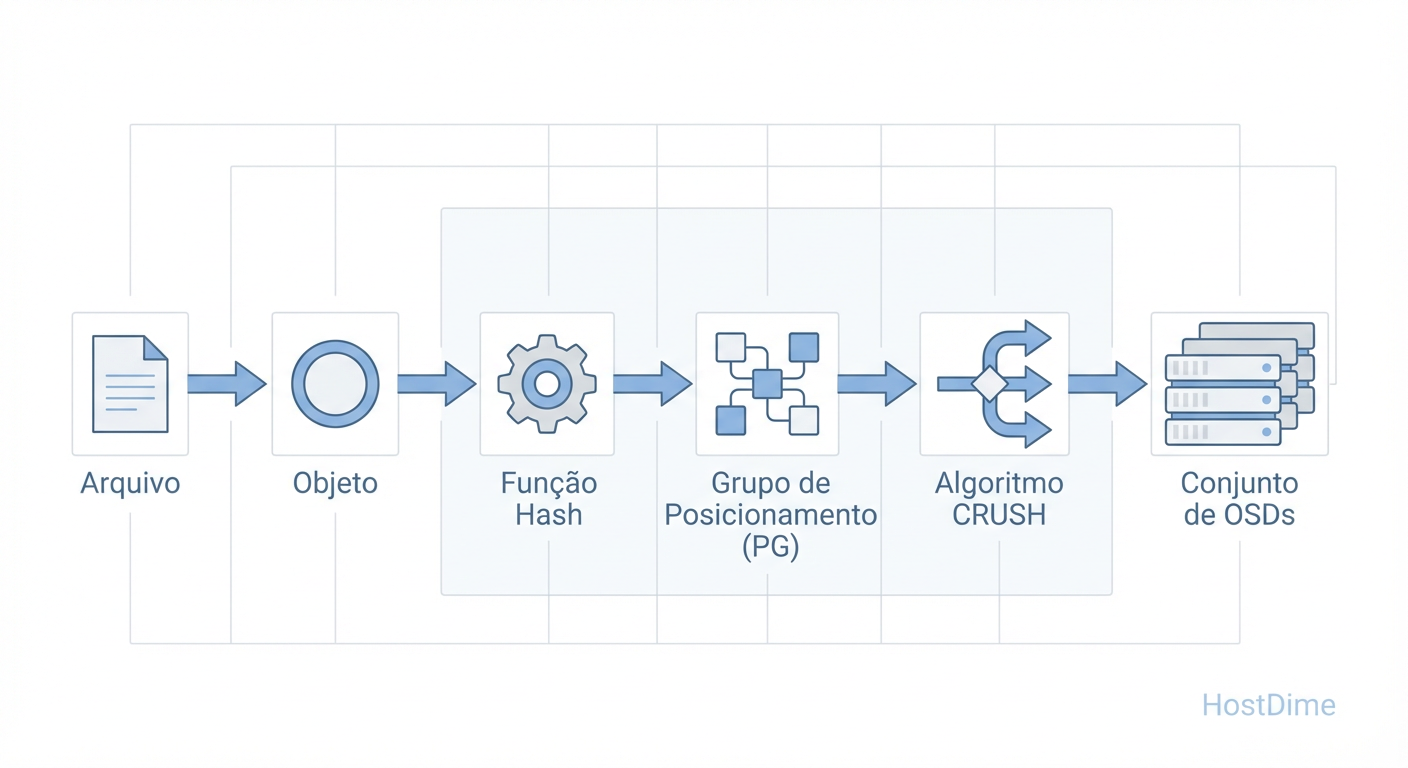 Figura: O Fluxo Lógico do Ceph: O Placement Group atua como a camada de indireção necessária para evitar que tabelas de alocação explodam em tamanho.
Figura: O Fluxo Lógico do Ceph: O Placement Group atua como a camada de indireção necessária para evitar que tabelas de alocação explodam em tamanho.
O Papel Crítico dos Placement Groups (PGs) na Latência
Por que não mapear o hash do objeto diretamente para o OSD? Por que precisamos dessa camada intermediária chamada Placement Group?
Se mapeássemos objetos diretamente para OSDs, qualquer alteração na topologia (um disco falhando ou sendo adicionado) exigiria recalcular o hash de milhões de objetos individuais para rebalancear o cluster. Isso seria catastrófico para a performance.
O PG agrupa esses objetos. Quando um disco falha, o Ceph não move arquivos; ele move PGs.
Do ponto de vista de performance, o PG é a unidade de concorrência e bloqueio.
Poucos PGs: Você cria "hotspots". Se você tem 1000 OSDs mas apenas 100 PGs, apenas uma fração dos seus discos estará ativa simultaneamente. Sua latência de gravação será limitada pela velocidade dos poucos discos ativos, enquanto o resto do cluster fica ocioso.
Muitos PGs: Cada PG consome memória no OSD e ciclos de CPU para processos de peering (verificação de consistência). O excesso de PGs fragmenta as gravações sequenciais em gravações aleatórias e pode derrubar OSDs por estouro de memória durante a recuperação de falhas.
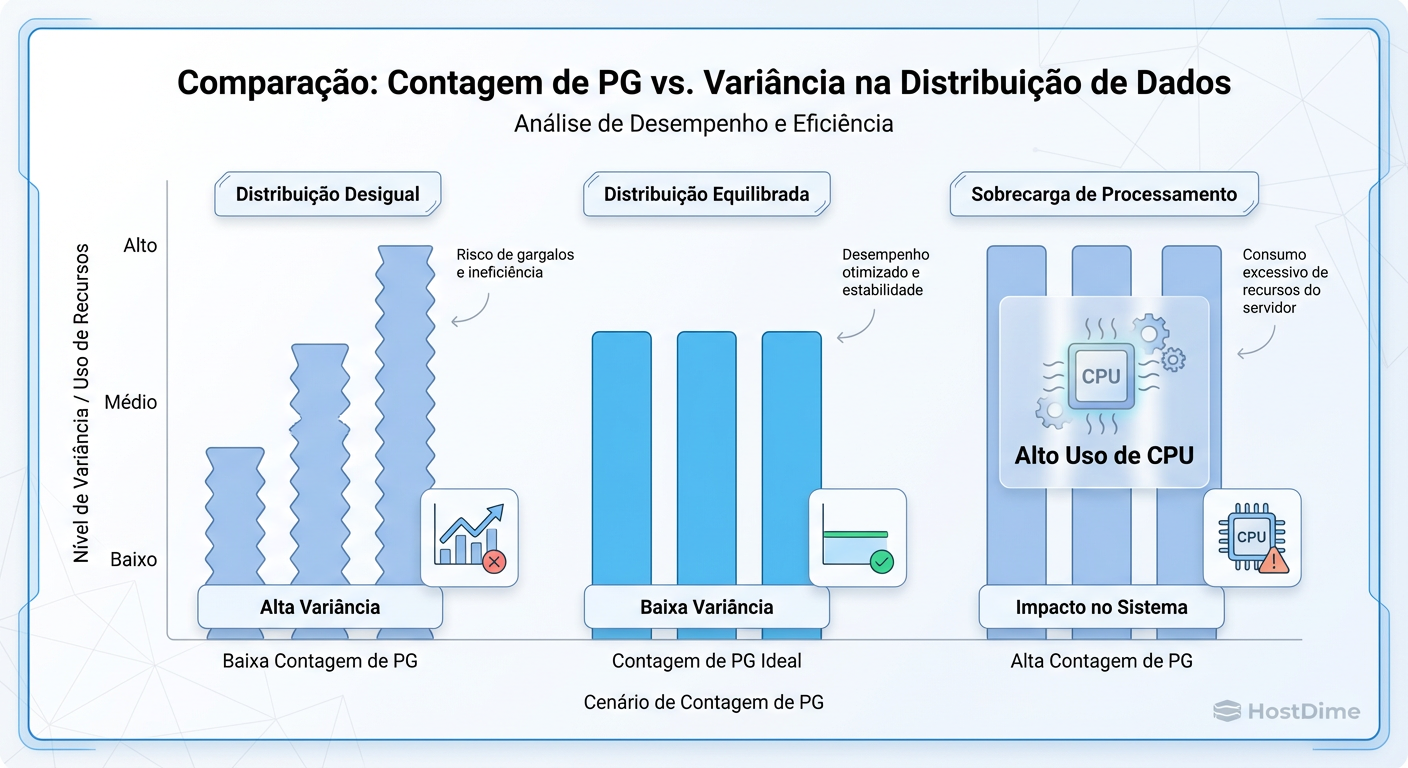 Figura: O Trade-off dos PGs: Poucos grupos geram OSDs cheios e vazios (desperdício). Muitos grupos matam a CPU em processos de peering.
Figura: O Trade-off dos PGs: Poucos grupos geram OSDs cheios e vazios (desperdício). Muitos grupos matam a CPU em processos de peering.
Trade-offs de Performance na Contagem de PGs
A decisão do número de PGs (pg_num) é o trade-off clássico de engenharia: Granularidade de Distribuição vs. Overhead de Recursos.
| Cenário | Contagem de PGs | Impacto na Memória (RAM) | Distribuição de Dados (Skew) | Impacto no Peering/Recovery |
|---|---|---|---|---|
| Subdimensionado | Baixa (< 30 por OSD) | Baixo | Alto Risco (Ruim). OSDs cheios e vazios. Hotspots de IOPS. | Rápido, mas move blocos de dados gigantescos, saturando a rede. |
| Ideal | Equilibrada (~100 por OSD) | Moderado | Uniforme. A variância de uso entre discos é baixa. | Equilibrado. |
| Superdimensionado | Alta (> 300 por OSD) | Crítico. Alto consumo por daemon. | Muito Uniforme (Diminuição dos retornos). | Lento. CPU spike massivo durante boot ou falha, causando timeout em I/O. |
Medindo o 'Data Skew': Como detectar OSDs sobrecarregados
Em um mundo perfeito, o CRUSH distribuiria os dados de forma perfeitamente igualitária. No mundo real, a aleatoriedade gera aglomerados. Se um OSD estiver 95% cheio enquanto outros estão em 50%, a latência de escrita de todo o cluster será ditada por esse único disco lento (o princípio do "straggler").
Para um engenheiro de performance, a métrica chave aqui é a VAR (Variância) na saída do comando de utilização.
Não confie apenas no painel do Dashboard. Vá ao terminal:
ceph osd df tree
Analise a coluna VAR.
1.0: Perfeitamente na média.
> 1.2: OSD com 20% mais dados que a média (Atenção).
> 1.5: OSD sobrecarregado. Risco iminente de
nearfulle latência de cauda.
Se você encontrar alta variância, seu pg_num provavelmente está muito baixo para o tamanho do cluster, ou seus pesos (weights) no CRUSH map estão incorretos para a capacidade dos discos.
Hierarquia de Falhas: Desenhando Buckets no CRUSH Map
O CRUSH Map não é apenas uma lista de discos; é uma árvore que representa sua infraestrutura física. A performance de leitura e escrita é drasticamente afetada por como você define seus "Buckets" (baldes) de falha.
Por padrão, o Ceph replica dados ao nível de host.
Vantagem: Baixa latência (rede local, switch Top-of-Rack).
Risco: Se o rack perder energia, você perde todas as réplicas daquele rack.
Para mitigar isso, configuramos o CRUSH para replicar por rack ou row.
O Custo da Resiliência:
Ao forçar o CRUSH a separar réplicas em racks diferentes, você introduz a latência dos switches de agregação ou core no caminho crítico da escrita (write path). O client só recebe o ACK de escrita quando todas as réplicas forem persistidas.
Se a latência de rede entre racks for de 0.5ms e dentro do rack for 0.05ms, mudar a regra CRUSH de host para rack aumentará sua latência base de gravação significativamente, independentemente da velocidade do disco. Meça a latência de rede entre seus domínios de falha com iperf ou ping antes de desenhar o mapa.
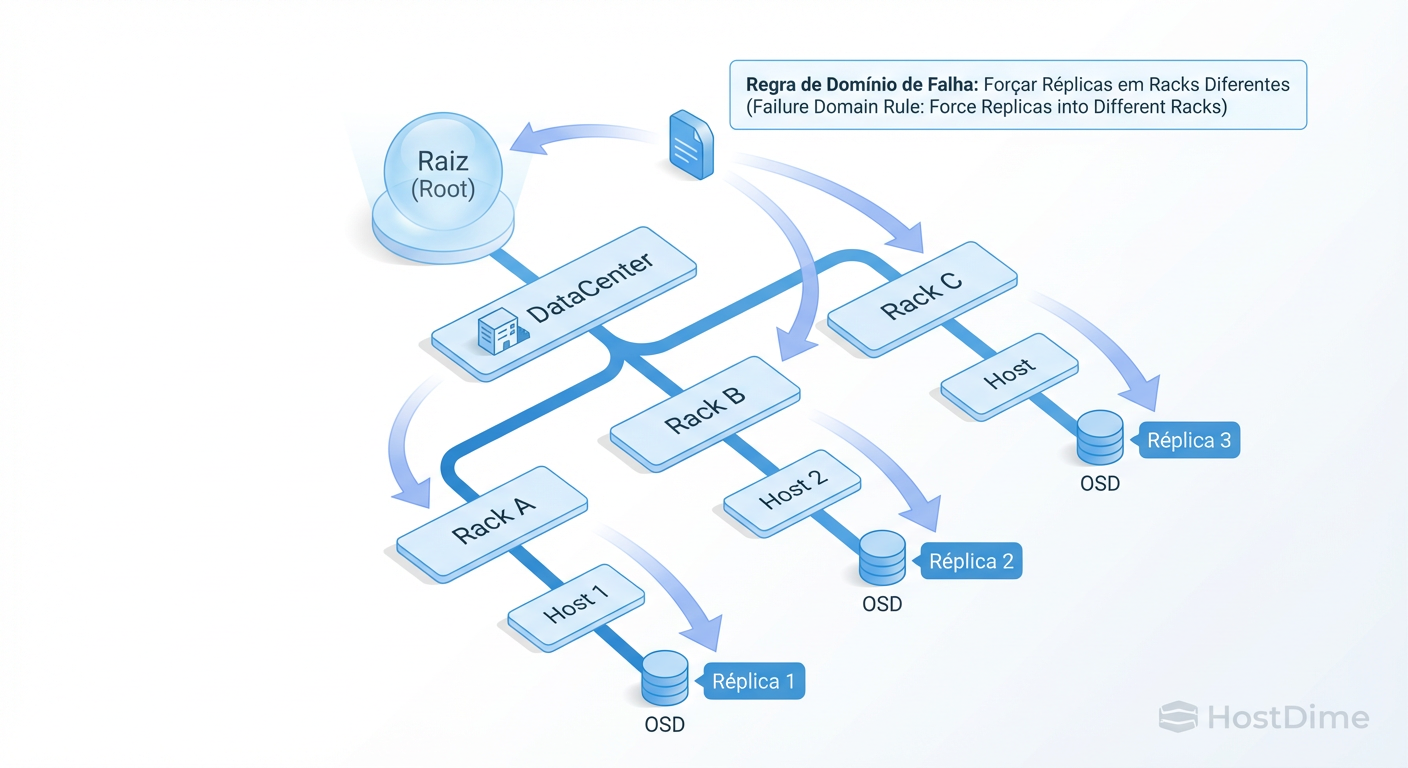 Figura: Desenhando Domínios de Falha: O CRUSH Map permite simular a robustez de um RAID distribuído geograficamente ou por rack físico.
Figura: Desenhando Domínios de Falha: O CRUSH Map permite simular a robustez de um RAID distribuído geograficamente ou por rack físico.
Ajustando CRUSH Rules para SSDs e Erasure Coding
Não misture tipos de mídia na mesma regra de alocação se você se importa com consistência. O Ceph permite criar "Device Classes" (hdd, ssd, nvme).
Um erro comum em performance é permitir que o CRUSH use HDDs para pools que exigem baixa latência. Você deve criar regras específicas que restrinjam a seleção de OSDs.
O Impacto do Erasure Coding (EC) na CPU: Enquanto a replicação (3x) gasta disco e rede, o Erasure Coding (ex: 4+2) gasta CPU. O cálculo de paridade acontece no cliente ou no OSD primário. Em testes de carga, monitore o steal time e a utilização de user CPU nos nós OSD. Se você usar EC com algoritmos complexos em CPUs antigas, o gargalo não será o disco nem a rede, mas a matemática do CRUSH calculando os fragmentos de paridade.
Para workloads de alta performance (bancos de dados, VM disks), a latência introduzida pelo cálculo do EC e a penalidade de "read-modify-write" em small blocks geralmente tornam o EC proibitivo, a menos que você tenha um cache tier de NVMe muito bem dimensionado na frente.
Veredito Técnico: Evidência sobre Intuição
O CRUSH Map é a ferramenta mais poderosa do Ceph, mas também a mais perigosa se mal compreendida. Não aceite os padrões de instalação cegamente.
Verifique se seus PGs estão equilibrados (
ceph osd df).Monitore a latência de commit dos OSDs (
ceph osd perf).Simule falhas. Remova um OSD e meça o impacto na latência do cliente durante o rebalancing.
Performance em sistemas distribuídos não é sobre velocidade máxima teórica; é sobre previsibilidade sob carga. O CRUSH bem ajustado é o que garante essa previsibilidade.
Referências & Leitura Complementar
Sage A. Weil (2007). Ceph: A Scalable, High-Performance Distributed File System. (A tese original, leitura obrigatória para entender a matemática base).
Ceph Documentation. CRUSH Maps / Placement Groups. (Documentação oficial para sintaxe atualizada de comandos).
Red Hat Performance Tuning Guide. Ceph Storage Strategies. (Whitepapers focados em otimização de hardware e topologia).

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.