Ceph Deep Dive A Matematica Forense Do Algoritmo Crush

Encontramos o sistema paralisado por latência. O culpado é a tabela de alocação central, onipresente em arquiteturas de armazenamento tradicionais. Cada operaçã...
Ceph Deep Dive A Matematica Forense Do Algoritmo Crush
A Cena do Crime: O Gargalo de Metadados
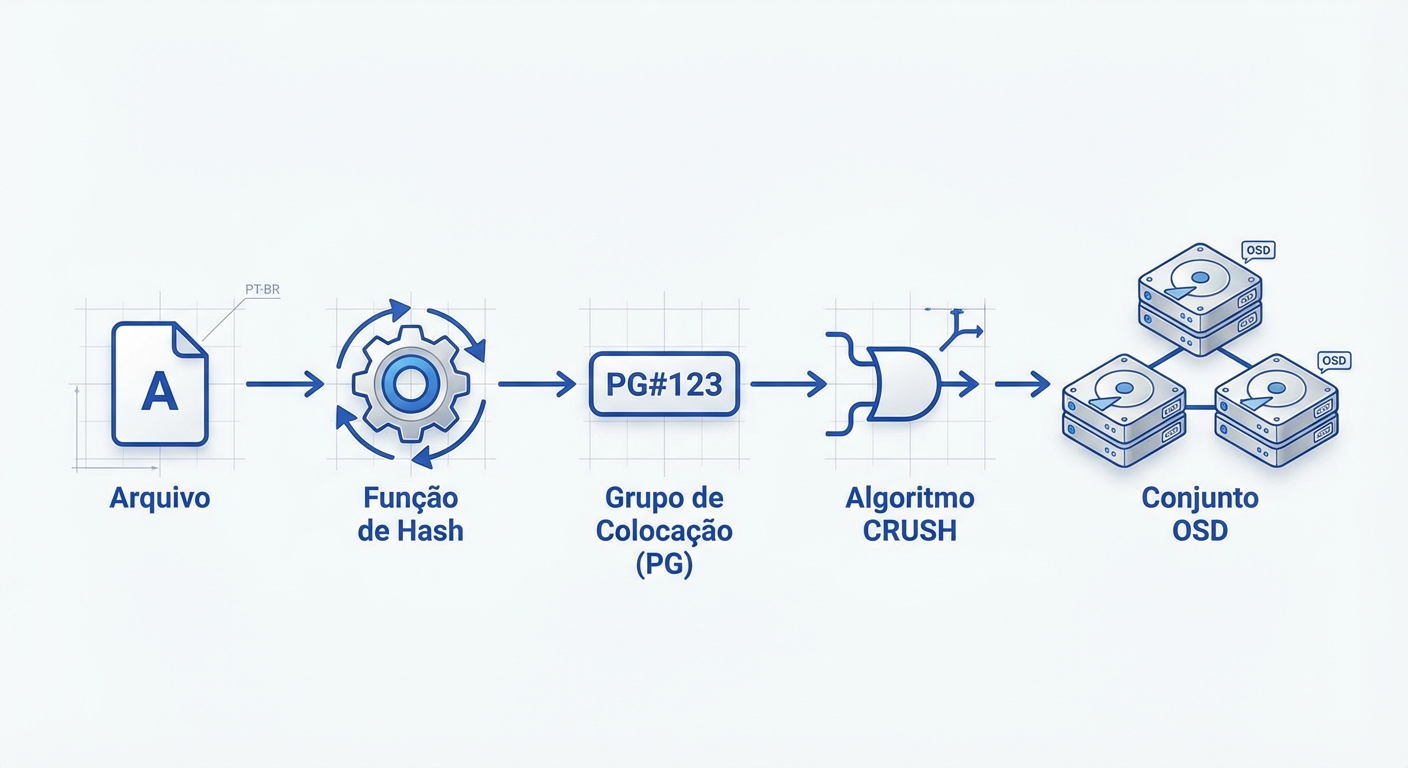
Encontramos o sistema paralisado por latência. O culpado é a tabela de alocação central, onipresente em arquiteturas de armazenamento tradicionais. Cada operação de leitura ou escrita exige uma consulta a este índice mestre para localizar blocos físicos. Em escala de Petabytes, esse ponto único de verdade cria um gargalo fatal, sufocando o throughput enquanto milhares de clientes formam filas apenas para perguntar "onde está meu arquivo?".
O Ceph elimina a necessidade de interrogar uma autoridade central. Em vez de consultar um banco de dados, o cliente utiliza o algoritmo CRUSH para computar a localização exata do objeto localmente. Ao transformar o problema de uma busca indexada em um cálculo determinístico puro, removemos a dependência de metadados e permitimos que o sistema escale linearmente sem restrições.
Análise Forense: O Fluxo de Cálculo (Object to OSD)
O rastro digital começa pela ausência de tráfego de metadados: o cliente não pergunta "onde", ele calcula. Inicialmente, o sistema submete o nome do objeto a uma função hash (geralmente Jenkins), aplicando uma máscara binária baseada no número de Placement Groups (PGs) do pool. Esta operação, PG = hash(objeto) & mask, isola logicamente o dado em um contêiner virtual antes de tocar qualquer hardware.
Na etapa seguinte, o algoritmo CRUSH ingere o ID deste PG e o Mapa do Cluster para determinar a topologia física. Através de um hashing pseudo-aleatório ponderado pela capacidade dos discos (pesos), o CRUSH gera a lista exata de OSDs alvo: CRUSH(PG, ClusterMap, Regra) -> [OSD.1, OSD.2, OSD.3]. Esta matemática garante que os dados respeitem domínios de falha (como racks distintos) e permite que qualquer nó verifique a integridade da localização independentemente.
Evidências na Prática: CRUSH Map e Buckets
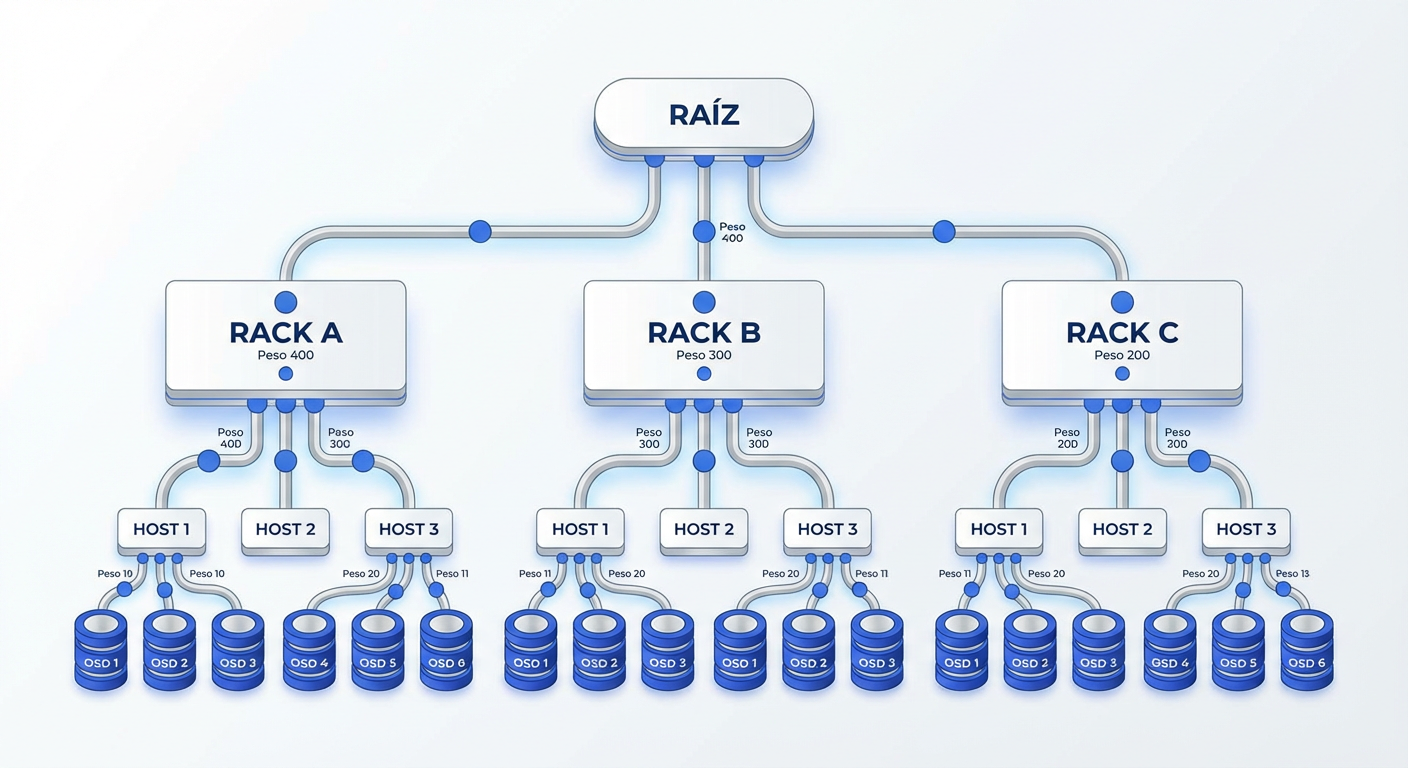
Detectamos o sintoma inicial: perda de dados catastrófica ou distribuição desigual após a falha de um único rack. A evidência aponta para o CRUSH Map, o artefato que traduz a topologia física (Datacenter > Rack > Host) em lógica de buckets. Ao configurar incorretamente o "Failure Domain", você instrui o algoritmo a armazenar réplicas no mesmo ponto de falha. O CRUSH utiliza essa hierarquia para garantir o isolamento físico dos dados.
A causa raiz da alocação reside na matemática dos buckets e seus pesos. O algoritmo straw2 domina este cenário por sua estabilidade, movendo apenas a quantidade mínima de dados necessária durante alterações de topologia. Manipulamos o fluxo de gravação ajustando os weights (geralmente baseados na capacidade do disco); um peso maior aumenta a probabilidade estatística de um OSD capturar o objeto. O cliente usa essas variáveis para calcular o destino exato, sem nunca consultar uma tabela central.
Veredito do Investigador
O exame dos sintomas confirma: a ausência de gargalos centrais deriva do cálculo determinístico feito pelo cliente, garantindo escalabilidade linear e self-healing. No entanto, a causa raiz de quedas bruscas de performance reside justamente nessa matemática; alterações na topologia exigem um rebalanceamento massivo que, sem controle, canibaliza a banda da rede de produção.
Para evitar a morte do I/O, projete seus domínios de falha para isolar riscos físicos e impedir a perda simultânea de réplicas.
Sempre limite a prioridade das operações de backfill e recovery. A regra é clara: uma recuperação agressiva restaura a redundância, mas mata a latência do cliente. Mantenha o mapa CRUSH otimizado para evitar a degradação silenciosa do sistema.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.