Ceph e Banco de Dados: Por que o Tuning Genérico Destrói a Performance
Workloads transacionais em Ceph exigem mais que largura de banda. Entenda a latência de gravação, os perigos do cache RBD e como ajustar o BlueStore e RocksDB para bancos de dados.
Todo mundo adora a ideia de hiperconvergência até o momento em que o banco de dados entra em produção. A promessa do Ceph é sedutora: armazenamento escalável, resiliente e "barato". Mas quando você joga um workload OLTP (Online Transaction Processing) pesado — como um PostgreSQL ou MySQL — em cima de um cluster Ceph configurado com padrões genéricos, o resultado não é apenas ruim; é catastrófico.
O problema não é o Ceph. O problema é a física e a expectativa. Sysadmins muitas vezes tratam o armazenamento distribuído como se fosse um SSD local ou uma SAN Fibre Channel dedicada. Não é. Se você não entender como cada write viaja pela rede e como o BlueStore interage com o disco físico, você estará lutando contra latências de commit de 20ms ou mais, enquanto seus desenvolvedores gritam que a aplicação "travou".
Vamos dissecar por que o tuning padrão falha e como arquitetar isso para a realidade, não para o marketing.
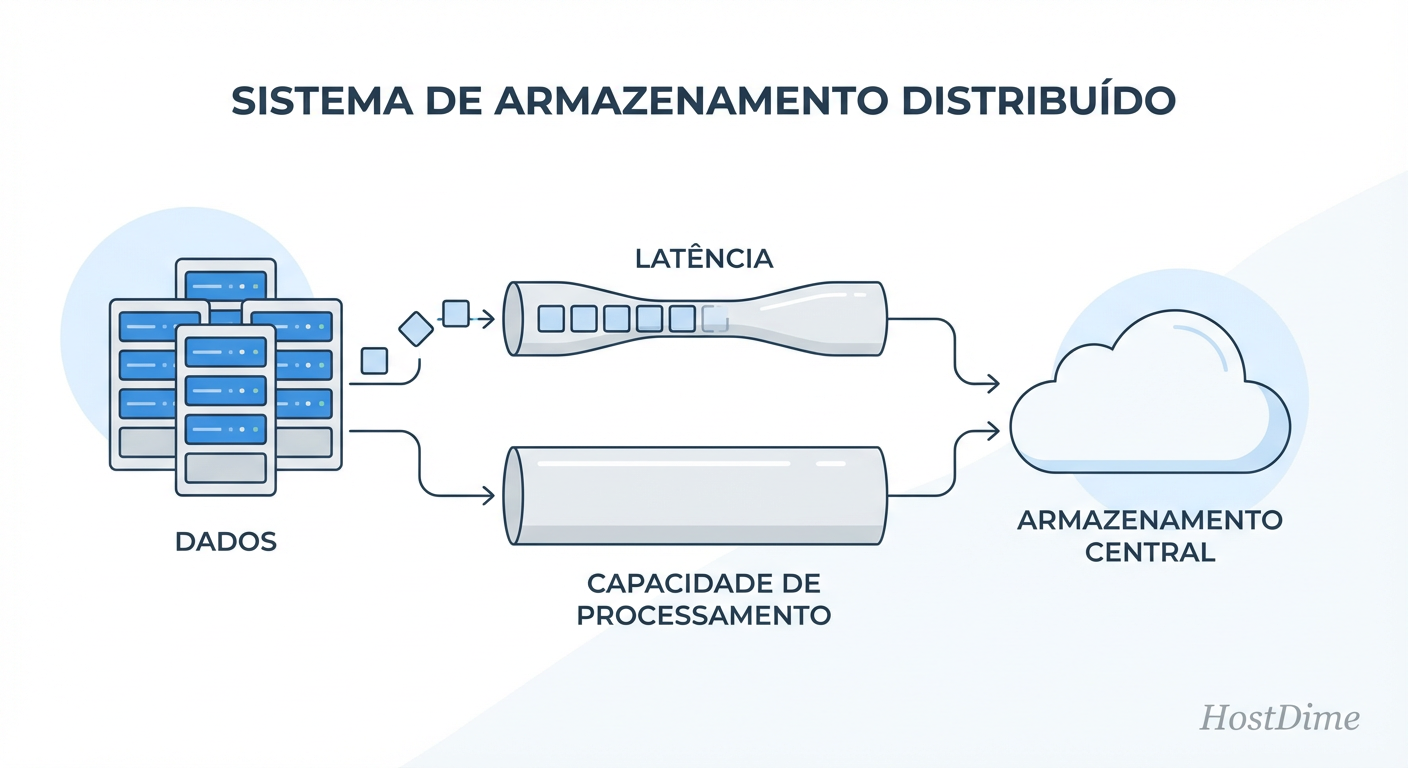
O que é Amplificação de Latência em Storage Distribuído?
Amplificação de Latência ocorre quando uma única operação de gravação lógica (iniciada pelo banco de dados) exige múltiplas operações físicas síncronas através da rede antes de ser confirmada. No Ceph, isso é ditado pelo fator de replicação: um
fsyncdo banco de dados não retorna sucesso até que os dados sejam gravados no OSD Primário e replicados/confirmados por todos os OSDs Secundários através da rede, tornando a latência da rede e do disco mais lento o piso da sua performance.
O Conflito Fundamental: Throughput vs. Latência em Workloads OLTP
Para consertar a performance, você precisa alinhar o modelo mental do armazenamento com o do banco de dados. O Ceph, por design, prioriza consistência e throughput (vazão). Ele é excelente para gravar grandes objetos ou fazer streaming de vídeo.
Um banco de dados transacional (OLTP), por outro lado, vive e morre pela latência. Ele não se importa se você consegue mover 10GB/s se cada transação individual demora 50ms para ser confirmada no disco (WAL - Write Ahead Log).
O conflito surge porque o tuning padrão do Linux e do Ceph tenta agrupar operações para aumentar a vazão total. Mas o banco de dados, ao fazer um COMMIT, emite uma chamada de sistema fsync() ou fdatasync(). Isso diz ao sistema operacional: "Pare tudo, grave isso no disco físico agora e não volte até terminar". O Ceph é obrigado a honrar isso, desmontando todas as otimizações de cache de gravação (write-back) que você achou que tinha.
Anatomia de uma Gravação no Ceph: Onde os milissegundos morrem
Você precisa visualizar o caminho do pacote. Quando seu banco de dados envia um bloco de 4KB para ser gravado, ele não vai simplesmente para um disco. Ele entra em uma jornada tortuosa.
Cliente (RBD): Envia o dado para o OSD Primário.
Rede Pública: Primeira latência de rede.
OSD Primário: Recebe, processa e repassa para os OSDs Secundários (réplicas).
Rede de Cluster: Segunda latência de rede (multiplicada pelo número de réplicas).
Discos (BlueStore): Todos os OSDs (Primário e Secundários) devem gravar no Journal/WAL.
Confirmação (Ack): Os Secundários confirmam ao Primário.
Retorno: O Primário confirma ao Cliente.
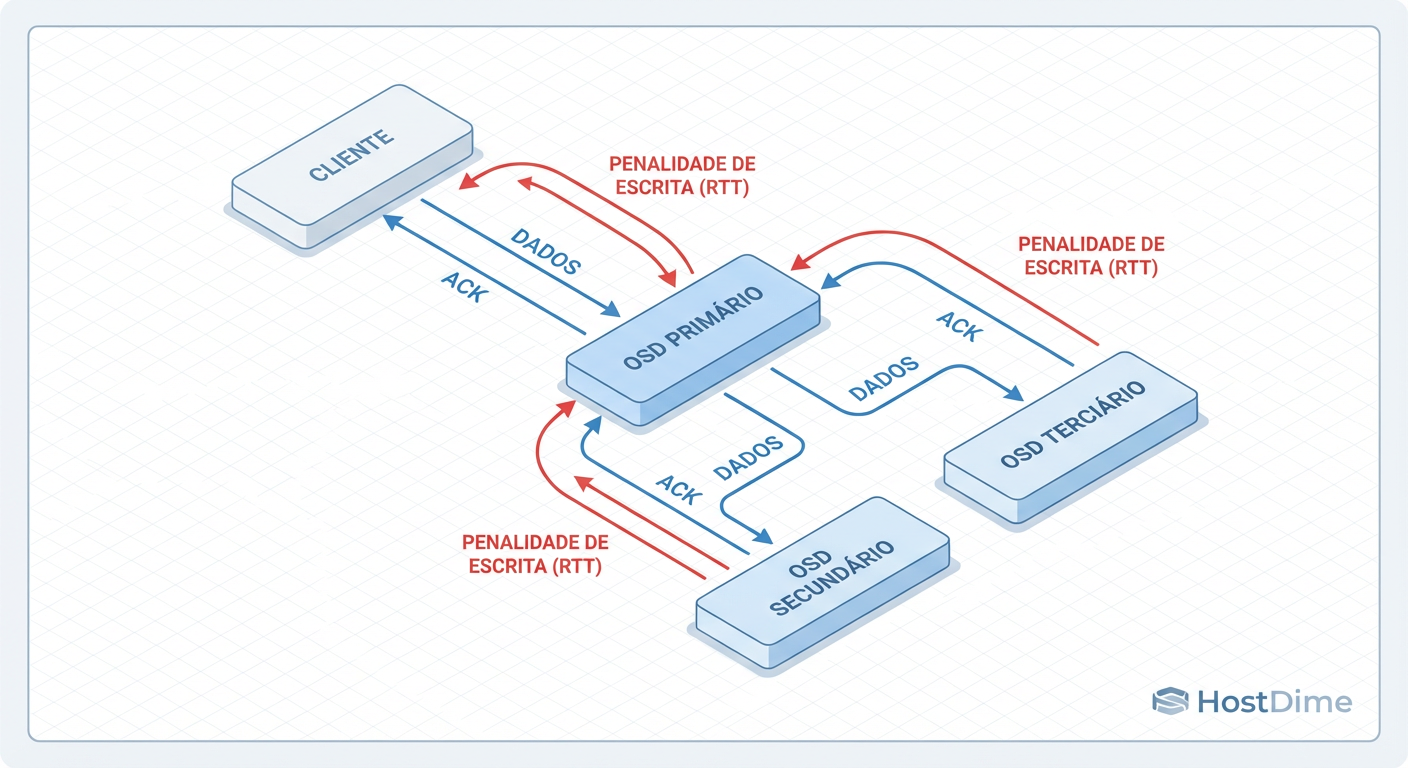 Figura: O Ciclo de Gravação do Ceph: Sua latência é definida pelo OSD mais lento e pela viagem de rede mais longa.
Figura: O Ciclo de Gravação do Ceph: Sua latência é definida pelo OSD mais lento e pela viagem de rede mais longa.
Se a sua rede tem jitter ou se um dos discos no conjunto de réplicas estiver lento (o famoso "straggler"), toda a transação espera. A latência de gravação do seu banco de dados é efetivamente a latência do disco mais lento do grupo somada a, pelo menos, duas viagens de rede (ida e volta).
A Ilusão do Cache RBD: Por que desativá-lo melhora a consistência
Existe um mito persistente de que ativar o cache do cliente RBD (rbd cache = true) resolve problemas de lentidão. Para bancos de dados, isso é frequentemente falso e perigoso.
O cache RBD é um cache em RAM no lado do cliente (onde a VM do banco roda). Quando o banco de dados emite um fsync (o que ele faz o tempo todo para garantir ACID), o cache RBD é obrigado a ser despejado (flushed) imediatamente para o cluster Ceph.
O resultado? Você adicionou overhead de gerenciamento de memória e CPU para gerenciar um cache que é invalidado a cada milissegundo. Pior: em cenários de falha de energia na VM, dados no cache que o SO achava que estavam seguros (se não usou fsync corretamente) somem.
A recomendação pragmática:
Para volumes que hospedam diretórios de dados de DB (especialmente WAL/Redo Logs), configure no seu ceph.conf ou na definição da libvirt:
rbd cache = false
Deixe o banco de dados gerenciar seu próprio cache (Buffer Pool). Ele sabe fazer isso melhor que o driver de bloco.
Hardware para Banco de Dados no Ceph: O papel crítico do WAL e DB no NVMe
Não existe tuning de software que corrija hardware inadequado. Se você está rodando OSDs em HDDs (Spinning Rust) e espera performance de banco de dados, você já perdeu. No entanto, clusters "All-Flash" são caros.
O meio-termo viável é entender a arquitetura BlueStore. O BlueStore grava dados em duas etapas principais: metadados/WAL (pequeno, rápido) e dados do objeto (grande).
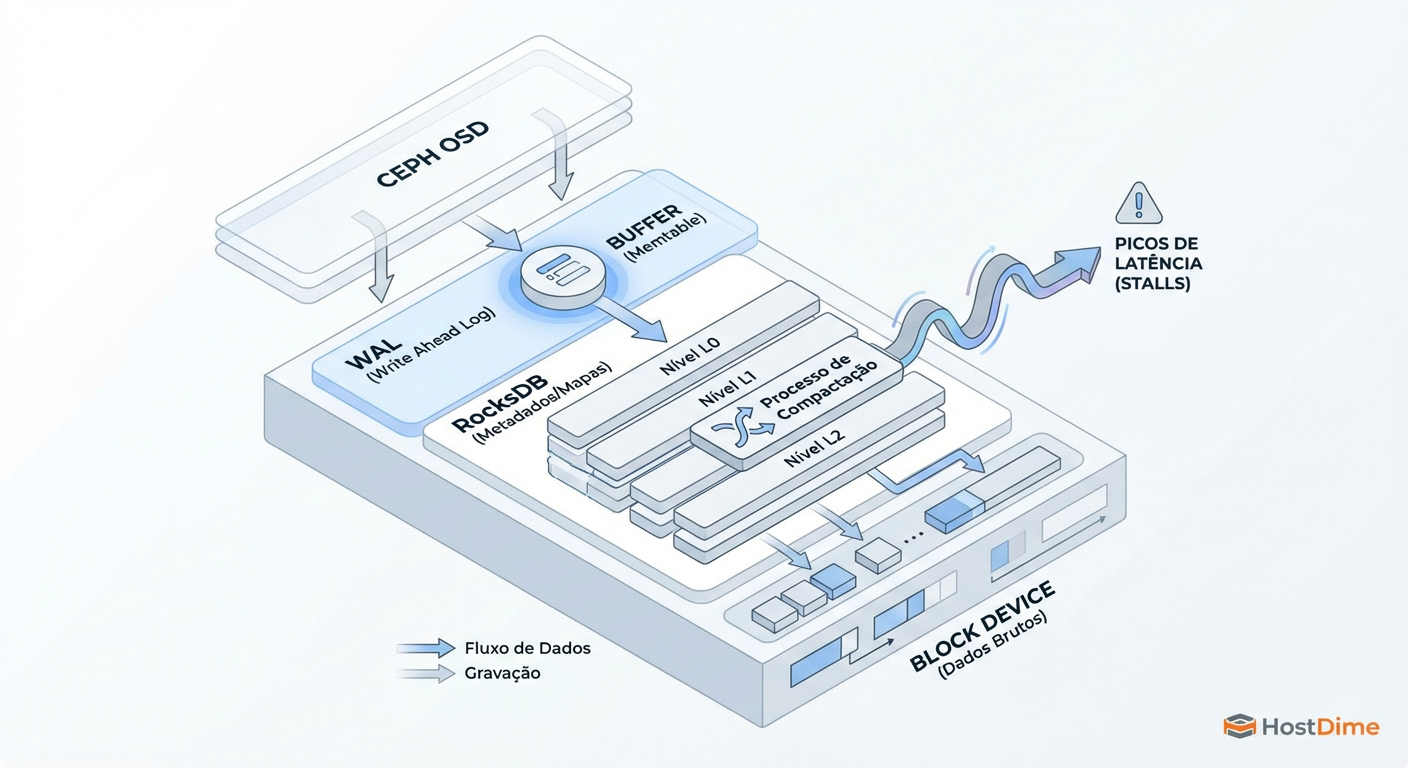 Figura: Arquitetura BlueStore: Onde o RocksDB e o WAL impactam diretamente o desempenho de IOPS transacionais.
Figura: Arquitetura BlueStore: Onde o RocksDB e o WAL impactam diretamente o desempenho de IOPS transacionais.
Se você usar HDDs para os dados (Data), você DEVE colocar o RocksDB (DB) e o WAL em mídia NVMe de nível empresarial. Se o RocksDB compartilhar o mesmo eixo mecânico que os dados, a compactação do banco de dados interno do Ceph vai competir por IOPS com a gravação do seu banco de dados SQL. O resultado é latência instável (spikes).
Comparativo de Impacto no Armazenamento de Metadados (RocksDB/WAL)
| Tipo de Mídia (Metadados) | Latência Média de Commit | Risco Operacional | Custo |
|---|---|---|---|
| HDD (SATA/SAS) | > 20ms (Inviável para OLTP) | Crítico. Compactações travam o cluster. | Baixo |
| SSD SATA (Consumer) | 2-5ms | Alto. Baixa durabilidade (DWPD) causa falha prematura. | Médio |
| SSD SATA (Enterprise) | 1-2ms | Baixo. Bom para clusters de entrada. | Médio/Alto |
| NVMe (Enterprise) | < 0.5ms | Mínimo. Remove o gargalo de serialização do OSD. | Alto |
Ajustes Finos no BlueStore e RocksDB: Indo além do ceph.conf padrão
Assumindo que seu hardware está correto (ou pelo menos decente), o tuning genérico do Ceph ainda pode matar sua performance. O padrão é conservador.
1. Tamanho de Alocação Mínima (Allocation Size)
O padrão antigo do BlueStore para HDDs era 64K. Para SSDs, 16K ou 4K. Bancos de dados geralmente escrevem páginas de 8K ou 16K.
Se o bluestore_min_alloc_size_hdd for muito grande, você terá uma amplificação de escrita massiva (Read-Modify-Write) para pequenas alterações do DB. Se for muito pequeno em HDDs, você fragmenta o disco e perde performance de leitura sequencial depois.
- Ajuste: Para SSDs/NVMe puros, alinhe com o tamanho da página do DB (ex: 16K ou 4K).
2. Tuning do RocksDB
O OSD usa o RocksDB internamente. Se o RocksDB engasgar fazendo compactação, o OSD para de responder.
- Atenção: Aumentar caches do RocksDB (
bluestore_rocksdb_options) consome RAM do OSD. Se o OSD for morto pelo OOM Killer do Linux, você causa um "flap", rebalanceamento e degradação total do cluster. Só altere se tiver RAM sobrando (recomendo 4GB+ RAM por TB de disco).
3. CPU Power States
Parece trivial, mas é frequentemente ignorado. Servidores modernos tentam economizar energia reduzindo o clock da CPU (C-states). No caminho crítico de latência do Ceph, a CPU precisa "acordar" milhares de vezes por segundo.
- Ação: Configure a BIOS para "Performance" e o governor do Linux para
performance. A latência de "acordar" a CPU pode adicionar 50-100 microssegundos por operação. Em um caminho com 6 hops, isso soma.
Como medir a latência real de commit (fsync) com FIO
Pare de usar dd ou hdparm. Eles medem throughput sequencial, que é irrelevante para saber se seu PostgreSQL vai travar na Black Friday. Você precisa simular o padrão de IO de um banco de dados: escritas aleatórias, pequenas, síncronas.
Use o fio (Flexible I/O Tester). O comando abaixo simula uma carga pesada de WAL (escrita síncrona):
# CUIDADO: Isso destrói dados no arquivo alvo. Use em um volume de teste.
fio --name=db_wal_test \
--ioengine=libaio \
--rw=randwrite \
--bs=4k \
--direct=1 \
--fsync=1 \
--iodepth=1 \
--numjobs=1 \
--runtime=60 \
--time_based \
--filename=/mnt/meu_volume_ceph/testfile
O que procurar na saída:
fdatasync/sync lat (usec): Olhe o percentil 99th (
clat percentiles).Média: Se a média for > 5ms (5000 usec) em flash, há algo errado. Se o 99th percentil for > 50ms, seu banco de dados terá "stalls" perceptíveis pelo usuário.
Se você remover o --fsync=1 e usar apenas cache, verá números maravilhosos (e falsos). O --fsync=1 força a realidade da rede e do disco a aparecerem.
Veredito Técnico: Não lute contra a gravidade
Rodar bancos de dados em Ceph é um trade-off clássico. Você ganha resiliência e perde latência crua. Não tente "tunar" o Ceph para se comportar como um NVMe local; ele nunca será. O segredo está em garantir que a rede seja de baixa latência (25GbE+ recomendado), que os metadados (WAL/DB) estejam em mídia rápida e que você não esteja mentindo para si mesmo com caches ativados incorretamente.
Se os números do fio com fsync não forem aceitáveis para sua aplicação, nenhuma flag no ceph.conf vai salvar o dia. Mova o DB para armazenamento local ou aceite os limites físicos da distribuição.
Referências & Leitura Complementar
Ceph Documentation: BlueStore Configuration Reference - Detalhes sobre alocação e RocksDB.
RocksDB Tuning Guide: GitHub Wiki - Entendendo Write Stalls e Compaction.
PostgreSQL Documentation: Reliability and the Write-Ahead Log - Por que fsync é inegociável.
RFC 3720: iSCSI (Internet Small Computer Systems Interface) - Conceitos de transporte de bloco sobre IP (comparativo).

Eduardo Nogueira
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ele diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.