Ceph e Hypervisors: A Anatomia Forense dos Picos de Latência
Suas VMs travam aleatoriamente? Descubra a causa raiz dos latency spikes na interação entre KVM/QEMU e Ceph, do cache do disco ao penalty de replicação.
Você recebe o chamado às 3 da manhã. O banco de dados na VM principal travou, a aplicação web está dando timeout, mas o dashboard do Ceph está verde. "Tudo normal", diz o monitoramento. A latência média está em confortáveis 2ms.
Como investigador forense de sistemas, você sabe que a média é o álibi do culpado. Em armazenamento distribuído, especialmente quando acoplado a virtualização (KVM/Proxmox/OpenStack), a "média" esconde o crime. O que matou sua aplicação não foi a velocidade média do cluster, foi um único I/O que demorou 500ms para ser confirmado.
Vamos dissecar esse cenário. Não vamos falar de "melhores práticas" genéricas. Vamos rastrear o caminho do dado, isolar as variáveis e entender por que a combinação de Ceph e Hypervisors pode ser uma armadilha de latência se você não souber onde olhar.
Picos de latência em Ceph com Hypervisors ocorrem fundamentalmente quando a camada de virtualização (QEMU/KVM) exige confirmação síncrona de gravação (flush), mas o cluster Ceph enfrenta contenção em OSDs individuais, gargalos na serialização do RocksDB ou uso de SSDs sem proteção contra perda de energia (PLP), gerando uma "latência de cauda" (tail latency) que bloqueia a VM enquanto a média do cluster permanece baixa.
Por que a Latência Média do Ceph Esconde a Causa Raiz
A primeira regra da forense de storage é: ignore a média. A média dilui o sofrimento. Se 99 operações levam 1ms e 1 operação leva 1 segundo, sua média é ~11ms. Parece ótimo no gráfico do Grafana. Mas para o banco de dados que ficou esperando aquele 1 segundo, o mundo parou.
No contexto de Hypervisors, o sistema operacional convidado (Guest OS) muitas vezes bloqueia processos esperando a confirmação de que o dado está seguro no disco. Se o Ceph demora, a VM "congela".
 Figura: A Mentira da Média: Por que monitorar apenas a latência média esconde a causa raiz dos travamentos.
Figura: A Mentira da Média: Por que monitorar apenas a latência média esconde a causa raiz dos travamentos.
O gráfico acima ilustra o problema. O monitoramento padrão mostra a linha suave. A realidade, entretanto, é composta por picos violentos — a latência de cauda (Tail Latency). É no percentil 99 (P99) ou P99.9 que encontramos a evidência do crime. Se o seu P99 é 200ms, você tem um problema grave, mesmo que a média seja 2ms.
O Caminho de I/O no Ceph: Do KVM ao OSD
Para entender o atraso, precisamos percorrer a "Via Crucis" de um pacote de escrita. Diferente de um storage local, onde o caminho é curto (RAM -> Controlador SATA/NVMe -> Flash), no Ceph a jornada é longa e perigosa.
Quando uma VM executa um sync ou fsync (comum em bancos de dados como PostgreSQL ou MySQL), o processo é:
Guest OS: Envia comando de escrita.
VirtIO/QEMU: Intercepta e passa para o driver
librbdno host.Rede (Pública): O dado viaja até o OSD Primário.
OSD Primário: Recebe o dado, escreve no seu Journal/WAL (Write Ahead Log).
Replicação: O OSD Primário envia o dado para os OSDs Secundários (réplicas).
OSD Secundário: Escreve no Journal/WAL e envia o Ack (confirmação) de volta ao Primário.
Confirmação Final: Somente quando todas as réplicas confirmam a gravação, o OSD Primário diz ao QEMU "está salvo".
QEMU: Libera o Guest OS.
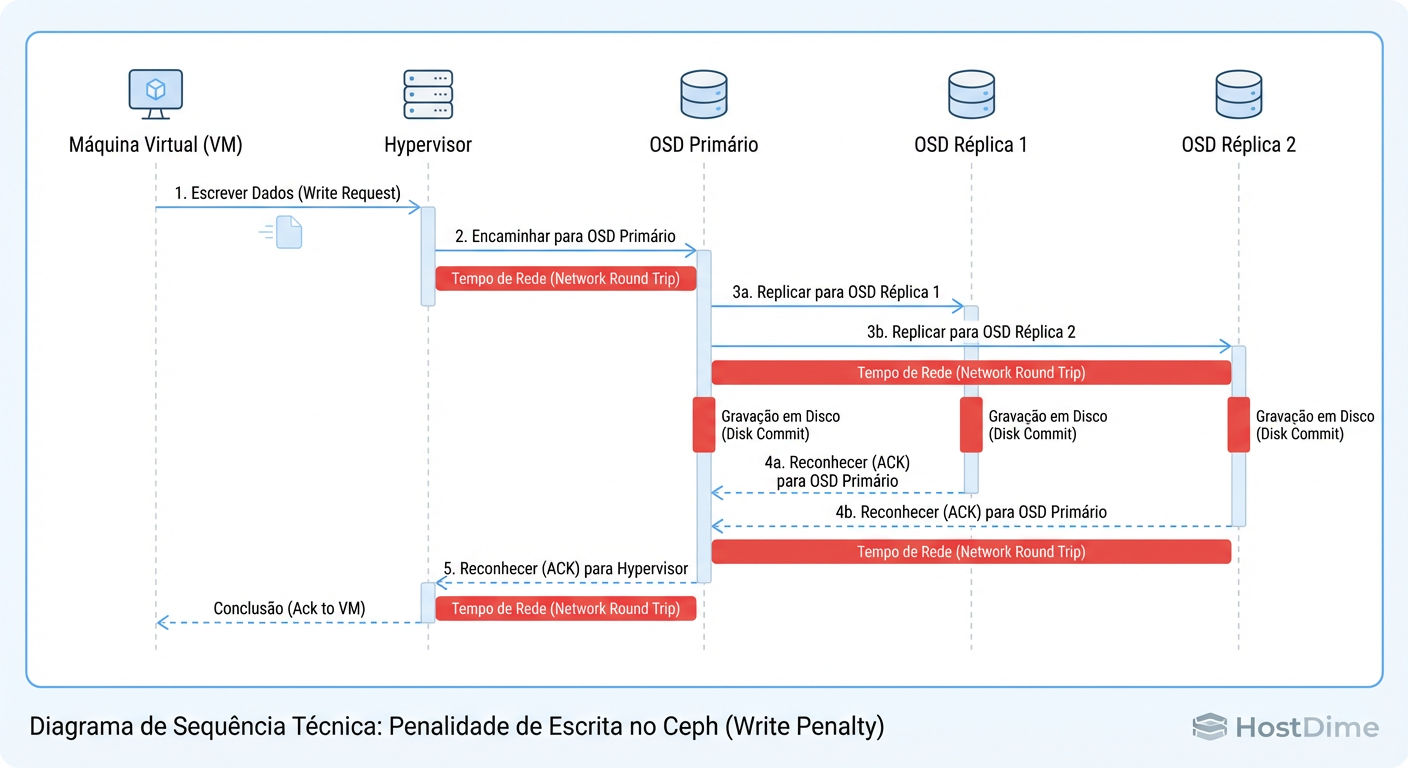 Figura: O Ciclo da Escrita Síncrona: A latência final da VM é ditada pelo OSD mais lento da cadeia de replicação.
Figura: O Ciclo da Escrita Síncrona: A latência final da VM é ditada pelo OSD mais lento da cadeia de replicação.
Aqui está o ponto crítico: A latência de escrita da sua VM é ditada pelo disco mais lento do cluster naquele momento. Se um único SSD de uma réplica estiver fazendo Garbage Collection ou sofrendo com Thermal Throttling, toda a operação para. O cluster é tão rápido quanto seu OSD mais lento.
Configuração de Cache QEMU e o Impacto no RBD
Muitos administradores tentam "resolver" a latência alterando o cache no Hypervisor, criando uma falsa sensação de segurança ou piorando o desempenho. O QEMU oferece modos de cache que mudam drasticamente como o flush é tratado.
Abaixo, uma análise forense dos modos de cache e seus riscos reais:
| Modo de Cache (KVM) | Comportamento de Escrita | Segurança de Dados | Impacto na Latência | Veredito Forense |
|---|---|---|---|---|
| Writeback | Reporta sucesso à VM assim que o dado chega na RAM do Host. O flush real para o Ceph ocorre depois. | Risco Alto: Se o Host cair antes do flush, adeus dados. | Baixa (Artificial). | Perigoso. Bom para testes, suicídio para DBs em produção sem bateria no controller. |
| None (Direct) | O I/O ignora o page cache do Host e vai direto para o librbd. |
Alta: O que a VM "vê" como gravado, está no Ceph. | Real (mostra a verdade). | Recomendado. Evita cache duplo e sobrecarga de gerenciamento de memória. |
| Writethrough | Escreve no cache e no disco simultaneamente. | Alta. | Alta (Soma das latências). | Ineficiente para a maioria dos casos de uso RBD. |
CALLOUT DE RISCO: Usar
cache=writebackem clusters Ceph sem entender as implicações é a causa número 1 de corrupção de sistemas de arquivos em caso de falha de energia no nó compute. O Ceph é seguro, mas o dado nunca chegou a ele.
Para verificar como suas VMs estão rodando, não confie na interface web. Verifique o processo real no host:
ps aux | grep qemu | grep "cache="
# Procure por cache=none ou cache=writeback na string de comando
SSDs de Consumo e a Saturação do RocksDB/WAL
Você isolou o problema: a latência vem do OSD. Mas por quê?
O Ceph (via BlueStore) usa o RocksDB para metadados e um WAL (Write Ahead Log) para garantir atomicidade. Toda pequena escrita síncrona precisa ser persistida no WAL antes de qualquer outra coisa.
Aqui entra o "serial killer" de performance: SSDs de Consumo (Consumer Grade) sem PLP (Power Loss Protection).
SSDs corporativos possuem capacitores que permitem que eles confirmem uma gravação assim que ela atinge a DRAM interna do disco, pois eles têm energia suficiente para salvar essa DRAM na Flash se a força cair. SSDs de consumo não têm isso.
Quando o Ceph pede um flush (obrigatório para integridade), um SSD de consumo entra em pânico. Ele não pode usar sua DRAM. Ele precisa forçar a gravação nas células NAND, o que é lento.
Sintoma clássico:
IOPS baixo (ex: 500 IOPS em um disco que promete 50.000).
iowaitalto no nó OSD.Latência de commit explodindo.
Se você está rodando Ceph em SSDs "Gamer" ou "Pro" de consumo, você não tem um problema de configuração; você tem um problema de física.
O Efeito "Thundering Herd": Scrubs e Rebalanceamento
Às vezes, o hardware é bom, a configuração está certa (cache=none), mas a latência dispara aleatoriamente às 14:00 de domingo.
O Ceph possui processos de manutenção de "vida": Scrubbing (verificação de integridade) e Recovery/Rebalance (quando um OSD cai ou volta).
Por padrão, o Ceph tenta ser gentil, mas um Deep Scrub lê todos os dados do disco e compara checksums. Isso compete diretamente por IOPS com sua VM. Em discos rotacionais (HDD) ou SSDs SATA saturados, o Scrub pode elevar a latência de 5ms para 500ms.
Ação Corretiva: Não desative o Scrub (isso é negligência). Agende-o para janelas de baixa operação ou limite sua prioridade severamente.
# Exemplo: Limitando a prioridade de operação do OSD
ceph config set osd osd_scrub_begin_hour 22
ceph config set osd osd_scrub_end_hour 6
ceph config set osd osd_scrub_sleep 0.1
O osd_scrub_sleep injeta pausas artificiais no processo de scrub, liberando o disco para o I/O da VM "respirar".
Diagnóstico Forense: Medindo commit_latency e apply_latency
Para provar a culpa, precisamos de métricas granulares. O comando ceph -s é inútil aqui. Precisamos interrogar os OSDs.
O Ceph distingue dois tipos de latência no OSD:
commit_latency (Journal/WAL Latency): Tempo para gravar no Journal. Se isso está alto, seu disco físico (ou a partição WAL) é o gargalo. É aqui que SSDs ruins morrem.
apply_latency (Store Latency): Tempo para flush no disco de dados e tornar disponível para leitura. Geralmente maior, mas menos crítico para a confirmação de escrita síncrona imediata.
Para encontrar o OSD assassino em tempo real:
# Mostra latências em tempo real (commit e apply)
ceph osd perf
Procure por outliers. Se 10 OSDs mostram commit_ms de 2ms e um mostra 50ms, isole esse disco. Verifique o SMART, verifique se ele não está sendo estrangulado termicamente.
Para um teste de estresse controlado (simulando uma VM) e validar a teoria do "Sync Write", use o fio dentro da VM suspeita:
# Simula escrita síncrona de banco de dados (o pior cenário)
fio --name=forensic_test --ioengine=libaio --rw=randwrite \
--bs=4k --numjobs=1 --iodepth=1 --fsync=1 --runtime=60 --time_based
Se este comando retornar IOPS ridículos (ex: 50 IOPS) em um cluster All-Flash, seu problema é a falta de PLP nos SSDs ou latência de rede extrema entre os nós.
Veredito Técnico do Investigador
A latência em ambientes Ceph + Hypervisor não é magia negra. É uma cadeia de eventos físicos.
Duvide da média. Olhe para o P99.
Verifique a física. SSDs sem PLP não servem para Ceph em produção.
Audite o caminho. Cache QEMU deve ser
nonepara consistência, e a rede deve ser robusta.Monitore o commit_latency. É lá que o gargalo se esconde.
Resolva a camada física e a configuração de cache, e os "fantasmas" da latência desaparecerão.
Referências & Leitura Complementar
Ceph Documentation: BlueStore Configuration Reference - Detalhes sobre o funcionamento do RocksDB e WAL.
QEMU Documentation: Caching Modes - Explicação técnica sobre
O_DIRECTeO_DSYNCno host.Sebastien Han (Red Hat): Ceph and RocksDB performance - Análises seminais sobre o impacto de hardware no BlueStore.
RFC 3720: iSCSI - Para comparações de latência de bloco sobre IP (embora RBD seja diferente, os princípios de latência de rede se aplicam).

André Bastos
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.