Ceph e Overcommit: Onde o Modelo Mental do Thin Provisioning Quebra

O Thin Provisioning no Ceph é uma aposta arriscada. Entenda a matemática real do overcommit, os perigos dos limites 'nearfull' e como evitar o travamento total do seu cluster de storage.
Vender Thin Provisioning para a gerência é fácil: "Vamos comprar menos disco agora e expandir depois". É a promessa do almoço grátis. No mundo do storage tradicional (SANs monolíticas), essa mentira é gerenciável. O controlador é centralizado, a inteligência é proprietária e, se o espaço acabar, o sistema geralmente trava uma LUN específica.
No Ceph, a história é diferente. O Ceph é um sistema distribuído que preza a consistência (CP no teorema CAP) acima da disponibilidade de escrita. Se você aplicar o modelo mental de "disco infinito" de uma SAN Dell ou NetApp em um cluster Ceph, você não vai apenas encher o disco. Você vai travar o cluster inteiro, corromper mapas de OSDs e passar o fim de semana tentando ressuscitar Placement Groups (PGs) manualmente.
O overcommit no Ceph não é uma configuração "set-and-forget". É uma dívida técnica que cobra juros compostos na forma de latência e risco operacional.
O Que é Overcommit no Ceph?
Overcommit (ou Thin Provisioning) no Ceph ocorre quando a capacidade lógica provisionada aos clientes (RBD, CephFS) excede a capacidade física bruta disponível no cluster. Diferente de sistemas tradicionais, o Ceph impõe limites globais de segurança (full_ratio) que bloqueiam a escrita em todo o pool muito antes do disco físico atingir 100%, tornando o cálculo de espaço "usável" dependente não só da geometria dos discos, mas da distribuição probabilística dos dados (CRUSH map).
A Ilusão do Disco Infinito no Ceph vs. Storage Tradicional
Para entender onde o thin provisioning quebra, você precisa abandonar a ideia de que está gravando em um "lugar" específico.
Em um storage de bloco tradicional, quando você cria um volume de 1TB com thin provisioning, o controlador mantém uma tabela de alocação. O SO convidado vê 1TB, mas o storage só aloca blocos quando há escrita. É linear.
No Ceph, não existe "o disco". Existe o algoritmo CRUSH. Quando um cliente escreve um objeto, o Ceph calcula um hash e determina em qual OSD (Object Storage Daemon) aquele dado deve viver.
O problema do overcommit aqui é a variância. Se você provisionar 100TB de discos virtuais em um cluster que só tem 50TB físicos, assumindo que os clientes usarão apenas 20%, você está jogando com a sorte. O Ceph assume que a distribuição de dados é pseudo-aleatória e uniforme. Mas a realidade não é uniforme.
Se um cliente decidir encher o disco dele, ou se o CRUSH map distribuir dados de forma desigual (o que sempre acontece em clusters pequenos ou heterogêneos), um único OSD pode encher enquanto outros estão vazios. O Ceph para de aceitar escritas quando o OSD mais cheio atinge o limite, não quando a média do cluster atinge o limite.
O seu modelo mental de "espaço total livre" é inútil. O que importa é o "espaço livre no OSD mais cheio".
A Matemática da Ruína no Planejamento de Capacidade
Vamos falar de números reais. O erro mais comum de novatos é olhar para a capacidade RAW e aplicar uma divisão simples.
"Tenho 10 discos de 10TB. Total 100TB."
"Uso réplica 3 (3x replication). Logo, tenho 33.3TB usáveis."
Errado. Se você planejar seu overcommit baseado em 33.3TB, você vai quebrar.
O espaço real é consumido por fantasmas que o df -h não mostra:
Overhead do BlueStore: O backend de armazenamento do Ceph precisa de espaço para metadados internos.
RocksDB & WAL: Se você não tiver SSDs dedicados para DB/WAL, isso come espaço no HDD principal.
Margem de Rebalanceamento: Se um disco falhar, os dados dele precisam ser copiados para os outros discos restantes. Se os discos restantes estiverem cheios, a recuperação falha (Backfill to Full).
Tabela: A Realidade do Espaço Usável (Cenário Hipotético)
| Atributo | Cálculo Ingênuo (Marketing) | Cálculo Sysadmin (Realidade) | Porquê? |
|---|---|---|---|
| Capacidade Raw | 100 TB | 100 TB | Física imutável. |
| Redundância | Réplica 3 (33% eficiência) | Réplica 3 + Overhead | Custo base. |
| Safety Margin | 0% (Usa até 100%) | 15% a 20% (Reserva) | Necessário para recuperação de falhas. |
| Threshold de Bloqueio | 100% | 85% - 90% | O cluster entra em Read-Only antes de encher. |
| Capacidade Efetiva | ~33.3 TB | ~22 TB a 25 TB | Onde o Overcommit mata o projeto. |
Se você vender 30TB de espaço "Thin" para seus clientes neste cluster, você já está operando na zona de perigo desde o dia 1.
O Abismo dos 85%: Entendendo os Thresholds Críticos do Ceph
O Ceph possui mecanismos de autodefesa agressivos. Ele prefere negar serviço a corromper dados por falta de espaço para journaling. Você precisa monitorar três cavaleiros do apocalipse na configuração do OSD map.
 Figura: As Zonas da Morte do Ceph: Entenda os thresholds que bloqueiam seu cluster muito antes do disco encher.
Figura: As Zonas da Morte do Ceph: Entenda os thresholds que bloqueiam seu cluster muito antes do disco encher.
nearfull_ratio(Padrão ~85%): É o aviso amarelo. O cluster começa a gritar nos logs. Se você usa overcommit agressivo, você viverá aqui constantemente, ignorando alertas até que seja tarde demais.backfillfull_ratio(Padrão ~90%): Aqui é onde a operação morre. O Ceph impede que novos dados sejam movidos para OSDs que atingiram esse nível. Se um disco falha e o rebalanceamento tenta mover dados para um OSD que está em 90%, o rebalanceamento para. Você perde a redundância. O cluster fica em estadoHEALTH_WARNouERRe não se cura.full_ratio(Padrão ~95%): O jogo acabou. O cluster pausa todas as operações de I/O de escrita. Todas as VMs congelam. Bancos de dados param. Para sair daqui, você não pode simplesmente "apagar dados", porque apagar dados gera metadados e logs que exigem... espaço. Muitas vezes, a única saída é adicionar hardware físico emergencialmente ou aumentar artificialmente ofull_ratio(arriscado) apenas para deletar arquivos.
Callout de Risco: Nunca aumente o
full_ratiocomo solução permanente. Se o disco encher 100% fisicamente, o processo do OSD trava (segfault ou corrupção do RocksDB), e você pode perder o OSD inteiro.
O Custo Oculto de Performance e a Fragmentação no BlueStore
Thin Provisioning não é apenas um risco de capacidade; é um assassino de latência.
Quando você aloca espaço dinamicamente (Thin), o Ceph grava os dados onde há espaço livre naquele momento. Em um cluster vazio, isso é sequencial e rápido. Em um cluster com 70% de ocupação e anos de uso, o espaço livre está espalhado em pequenos buracos ao longo do disco.
O backend BlueStore melhorou muito isso em relação ao antigo FileStore, mas não faz milagres.
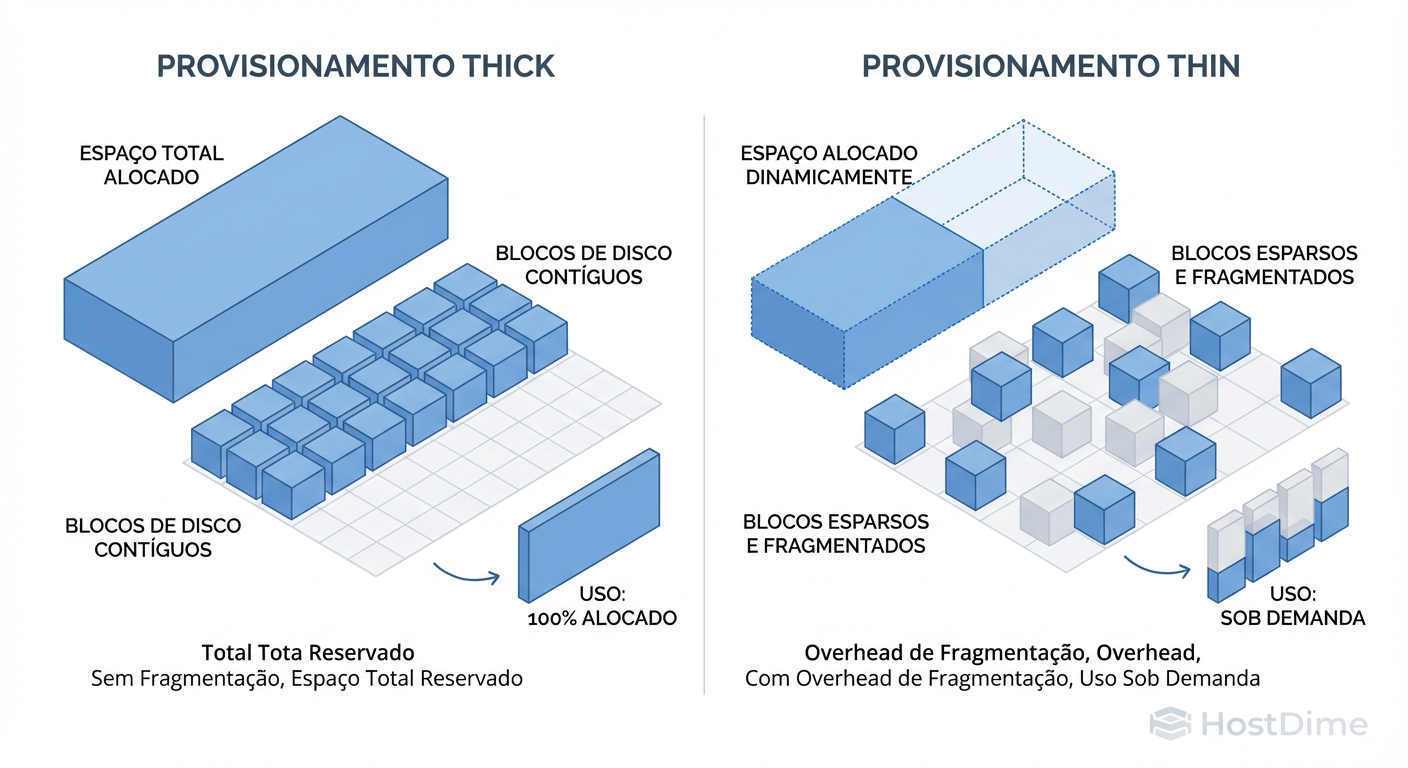 Figura: Fragmentação no BlueStore: O preço de performance pago pela flexibilidade do Thin Provisioning.
Figura: Fragmentação no BlueStore: O preço de performance pago pela flexibilidade do Thin Provisioning.
O problema se agrava com snapshots e clones (comuns em ambientes virtualizados). O Ceph usa Copy-on-Write. Cada escrita em um volume clonado fragmenta ainda mais o objeto original.
O resultado? Seus HDDs, que deveriam entregar 150 IOPS, começam a entregar 40 IOPS porque a cabeça de leitura está buscando pedaços de dados espalhados pelo prato magnético. O overcommit transformou sua carga de trabalho sequencial em randômica.
Métricas e Evidência: Usando ceph df para Prever o Desastre
Não confie na GUI do Proxmox ou no Dashboard do Ceph cegamente. Vá para o terminal. O comando que separa os amadores dos veteranos não é o ceph status, é o detalhamento dos OSDs.
Você precisa identificar o desbalanceamento.
ceph osd df tree | sort -nk 7
Olhe para a coluna %USE e VAR.
%USE: A ocupação real.
VAR (Variância): Se este número for muito maior que 1.0, seu cluster está desbalanceado.
Cenário de Exemplo:
Você tem 10 OSDs. A média de uso é 50%.
Mas o osd.5 está com 88% de uso (VAR alto).
Para o Ceph, o seu cluster está prestes a entrar em backfillfull. O espaço livre nos outros 9 discos é irrelevante para a segurança imediata do osd.5.
Se você opera com overcommit, você deve rodar o rebalanceador (ceph osd reweight-by-utilization) frequentemente, mas saiba que isso custa I/O e performance. É o preço que se paga pela eficiência de espaço.
Estratégias de Sobrevivência com TRIM e Thick Provisioning
Como não ser demitido operando Ceph com Overcommit?
1. O TRIM/Discard é Obrigatório
Se você usa Thin Provisioning, o Ceph precisa saber quando o dado foi deletado dentro da VM. Sem o comando TRIM/Discard, o sistema de arquivos da VM marca o bloco como livre, mas o Ceph continua achando que o bloco está ocupado. O disco virtual cresce e nunca encolhe.
Em VMs Linux: Habilite
discardnas opções de montagem ou usefstrimvia cron.No driver RBD (libvirt/QEMU): Certifique-se de que a flag
discardedetect-zeroesestão ativas na definição do disco.
2. Thick Provisioning para Latência Crítica
Para bancos de dados de alta performance, pare de ser mesquinho com disco. Use Thick Provisioning (alocação completa inicial). Embora o Ceph RBD seja nativamente thin, você pode forçar a escrita de zeros ou usar ferramentas para "inflar" a imagem.
Vantagem: Você evita a penalidade de alocação de metadados durante a escrita (primeiro write penalty).
Vantagem: Você garante que, se o cluster aceitou o volume, o espaço é seu. Você não compete por espaço livre futuro com o estagiário que subiu 50 VMs de teste.
3. Monitore a Derivada
Não monitore apenas o uso atual (%). Monitore a taxa de crescimento (GB/dia). O overcommit é seguro se o crescimento for lento e previsível. Se você tiver picos de ingestão (ex: restauração de backup, log flood), o overcommit vai te pegar de calças curtas antes que o fornecedor consiga entregar discos novos.
Referências & Leitura Complementar
Ceph Documentation - Operations: "Full OSDs and Nearfull ratios". Explicação oficial sobre como o CRUSH lida com discos cheios.
BlueStore Internals: Sage Weil (Red Hat). Apresentações técnicas sobre a estrutura do RocksDB e alocação de blocos no BlueStore.
RFC 3720 (iSCSI) vs RBD: Comparativos de arquitetura de protocolo de bloco para entender as diferenças de overhead.
SAGE WEIL et al. "CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data". O paper original que explica a matemática probabilística que torna o "disco infinito" uma aposta estatística.

Thiago Moreira
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.