Ceph e Snapshots de VM: O Custo Invisível na Performance de Escrita (RBD)
Snapshots no Ceph não são de graça. Entenda a penalidade de Copy-on-Write (CoW), o impacto em latência de escrita e como medir o gargalo em volumes RBD.
Se você gerencia infraestrutura de virtualização sobre Ceph, já ouviu a promessa de vendas: "Snapshots são instantâneos e não ocupam espaço inicial". Isso é tecnicamente verdade, mas operacionalmente perigoso. O marketing esquece de mencionar que a conta chega depois, e ela é paga com a moeda mais cara do seu cluster: Latência de Escrita.
Muitos administradores percebem tarde demais que seus volumes RBD (RADOS Block Device) estão sofrendo de uma "hemorragia de IOPS" inexplicável. O culpado geralmente não é a rede, nem o disco, mas a lógica implacável de como o Ceph preserva o passado enquanto tenta gravar o futuro. Vamos dissecar o que acontece fisicamente nos seus discos quando você abusa dos snapshots.
O que é a Penalidade CoW no Ceph? O Copy-on-Write (CoW) no Ceph RBD impõe uma latência extra em volumes com snapshots. Para cada escrita em um bloco que possui um snapshot referenciado, o cluster deve primeiro ler o dado original, alocar espaço e copiá-lo para preservar o estado anterior, transformando uma simples operação de escrita (1 IO) em uma sequência pesada de leitura-alocação-escrita (3+ IOs), degradando severamente a performance.
A Ilusão do Snapshot Grátis e o Mecanismo Copy-on-Write (CoW)
Para entender o problema, precisamos abandonar a visão do sistema de arquivos do sistema operacional convidado (Guest OS) e olhar para o bloco. O Ceph não sabe o que é um arquivo "Excel"; ele vê objetos de 4MB (o padrão do RBD).
Quando você tira um snapshot, o Ceph simplesmente congela o mapa de ponteiros daquela imagem. Nada é copiado. O custo é zero. É aqui que o administrador novato sorri.
O problema começa no segundo seguinte, quando a VM tenta gravar dados. O Ceph opera sob o modelo Copy-on-Write (CoW) para snapshots RBD. Se a VM tenta sobrescrever um bloco que faz parte de um snapshot protegido, o OSD (Object Storage Daemon) diz: "Espere, eu preciso salvar a versão antiga antes de você tocar nisso".
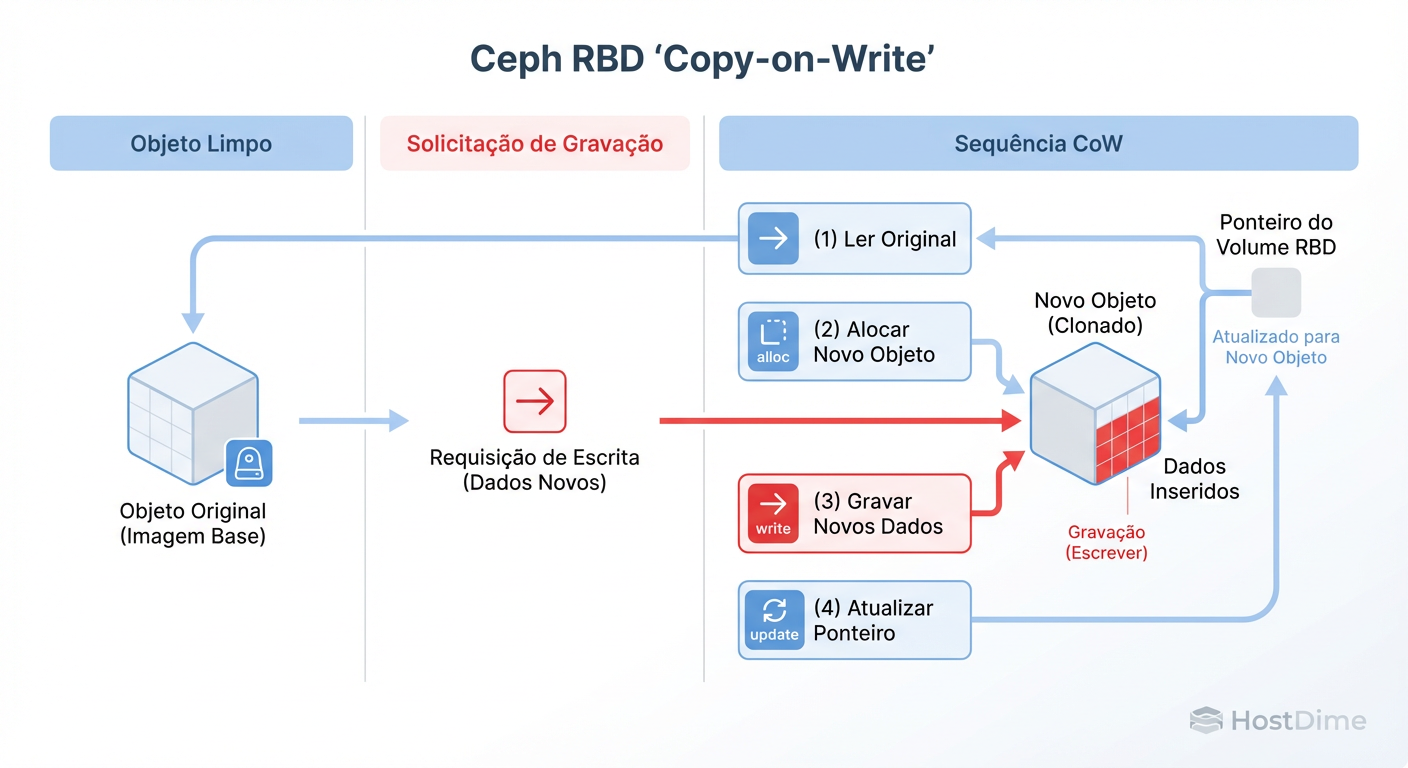 Figura: Diagrama de fluxo do Copy-on-Write (CoW) no Ceph RBD: Onde uma escrita se transforma em leitura + alocação + escrita.
Figura: Diagrama de fluxo do Copy-on-Write (CoW) no Ceph RBD: Onde uma escrita se transforma em leitura + alocação + escrita.
A ilusão de "grátis" desaparece porque a escrita do cliente fica bloqueada até que todo esse malabarismo no backend seja concluído. O cliente (a VM) sente isso como iowait.
Anatomia de um Objeto RBD e o Impacto no Disco
Vamos descer ao nível do OSD. Imagine um volume RBD de 100GB. Ele é fatiado em objetos. Quando sua VM envia uma escrita aleatória de 4KB, ela cai dentro de um desses objetos.
Em um volume sem snapshots (limpo):
O cliente envia a escrita.
O OSD grava no WAL (Write Ahead Log) e na RocksDB (se usar BlueStore).
O OSD confirma a escrita (Ack).
O dado vai para o disco de dados assincronamente.
Em um volume com snapshots (sujo): Antes do passo 2, o OSD verifica se aquele objeto específico já foi "clonado" para o snapshot atual. Se não foi, ele precisa ler o objeto original, copiá-lo para uma nova área (ou marcar a referência interna) e só então permitir a nova escrita.
Isso gera o que chamamos de Amplificação de Escrita. Você pediu 1 IOPS de escrita, mas o disco físico teve que realizar uma leitura e múltiplas escritas de metadados e dados.
Tabela Comparativa: Volume Limpo vs. Volume com Snapshots
Abaixo, uma comparação direta do impacto esperado em um cenário de escritas aleatórias (Random Write 4k):
| Métrica | Volume RBD Limpo (No Snaps) | Volume RBD com Snapshots (CoW Ativo) | O que acontece fisicamente? |
|---|---|---|---|
| Latência de Escrita | Baixa (ex: 1-2ms em SSD) | Alta/Variável (ex: 5-15ms) | O OSD precisa verificar metadados e mover dados antigos. |
| IOPS Efetivos | Próximo ao limite do disco/rede | 30% a 50% de redução | O "teto" de IOPS baixa porque cada IO lógico custa mais IO físico. |
| Throughput | Estável | Instável ("Dente de serra") | Picos de latência causam engasgos na fila de IO da VM. |
| Custo de CPU no OSD | Moderado | Alto | Cálculo de checksums e gerenciamento de RocksDB intensos. |
O Pesadelo das Cadeias Longas e Fragmentação RBD
O cenário piora quando entramos no território de "Linked Clones" ou cadeias longas de snapshots. É comum em ambientes de VDI ou CI/CD: você tem uma imagem base, cria um clone para a VM A, tira um snapshot da VM A, e cria um clone para a VM B a partir desse snapshot.
Isso cria uma árvore de dependência. Para ler um bloco que não foi modificado na ponta da cadeia, o Ceph precisa percorrer a árvore para trás até encontrar a versão autoritativa do dado.
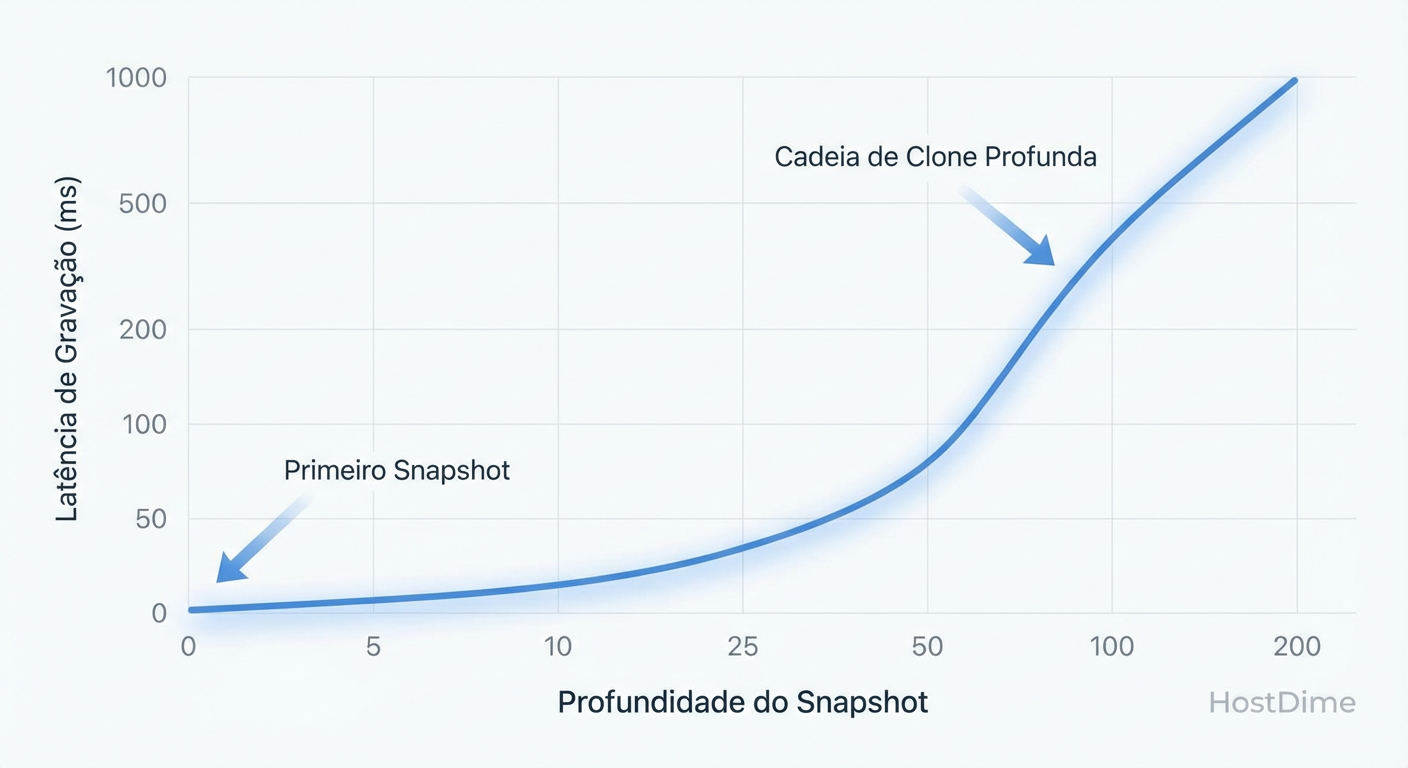 Figura: Correlação entre profundidade de snapshots e latência de escrita em volumes RBD sob carga aleatória.
Figura: Correlação entre profundidade de snapshots e latência de escrita em volumes RBD sob carga aleatória.
Embora o Ceph tenha otimizações (como o object map) para mitigar leituras, a escrita continua sofrendo. Quanto mais profunda a cadeia (Depth), maior a sobrecarga de metadados para determinar "quem é dono desse bloco agora?" e "para onde devo copiar o dado antigo?".
Diagnóstico Prático com rbd perf image iotop e Métricas
Não confie no seu instinto. Se o usuário reclama de lentidão, prove que é o Ceph (ou prove que não é).
O primeiro passo não é olhar o htop da VM, mas sim interrogar o cluster. A ferramenta rbd possui comandos nativos de performance que muitos ignoram.
Para visualizar a latência em tempo real por imagem:
# Habilita o monitoramento de performance (se não estiver ativo)
ceph config set client.rbd rbd_perf_tool_enable true
# Observa o topo das imagens com maior latência/IOPS
rbd perf image iotop --sort write_latency
O que procurar:
Write Latency alta: Se estiver consistentemente acima de 10-20ms em flash, você tem um problema.
Write Ops vs. Write Bytes: Muitas operações pequenas (4k) com alta latência são o cenário clássico de penalidade de CoW.
Além disso, verifique a saúde dos OSDs. Se apenas os OSDs que hospedam os objetos daquela VM específica estão lentos, verifique a compactação do RocksDB. Snapshots geram muita atividade de metadados (tombstones e overwrites) no RocksDB do BlueStore.
Estratégias de Mitigação: Flattening e Políticas de Retenção
Você diagnosticou o problema. O volume tem 50 snapshots diários e a performance está no chão. Colocar SSDs NVMe vai mascarar o problema, mas não vai resolvê-lo (e vai custar caro). A solução é arquitetural e operacional.
1. Flattening (Aplainar a Imagem)
Se você usa clones (ex: criou uma VM a partir de um Template), a nova VM mantém um vínculo com o pai. O comando flatten quebra esse vínculo, copiando todos os dados do pai para o filho.
# Verifica se há parent
rbd info pool_vms/vm-100-disk-0 | grep parent
# Remove a dependência (CUIDADO: Gera IO intenso durante o processo)
rbd flatten pool_vms/vm-100-disk-0
Risco: O flatten é uma operação de cópia massiva. Execute fora do horário de pico.
2. Política de Retenção Agressiva
Não guarde lixo. Snapshots de VM não são backup de longo prazo; são pontos de recuperação rápida.
Use ferramentas como
ceph-rbd-snapshot-retentionou scripts simples para podar snapshots antigos.Regra de Ouro: Mantenha a profundidade (depth) baixa. Idealmente, menos de 7 snapshots ativos por imagem de alta performance.
3. Camada de Cache (Tiering) - Cuidado
Adicionar um cache tier de SSD na frente de HDDs pode piorar a situação com snapshots se o algoritmo de flushing não for eficiente. Em cargas de trabalho modernas com Ceph BlueStore, é preferível usar SSDs/NVMe diretamente como pool principal ou usar a função de DB/WAL em dispositivos rápidos, deixando o spinning rust (HDD) apenas para dados frios (Object Storage/S3), não para RBD de alta performance.
Veredito Técnico: O Preço da Conveniência
Snapshots são uma ferramenta funcional, não mágica. O modelo mental correto para operar Ceph RBD é entender que cada snapshot é uma dívida técnica contraída contra a performance futura de escrita.
Se sua aplicação exige latência de escrita ultrabaixa (bancos de dados transacionais), evite snapshots frequentes ou use replicação a nível de aplicação (log shipping, replicas de DB) em vez de depender do armazenamento. Se precisar usar, monitore a latência de commit e mantenha suas cadeias curtas. No storage distribuído, a física sempre ganha.
Referências & Leitura Complementar
Ceph Documentation: "RBD Snapshots and Clones" - Documentação oficial sobre a arquitetura de provisionamento.
Sage Weil (Ceph Creator): "RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters" (Paper original, útil para entender a distribuição de objetos).
RocksDB Tuning Guide for Ceph: Entendendo como a compactação do LSM-tree afeta a latência em cenários de alta escrita de metadados.
RFC 3720 (iSCSI): Para entender comparativos de latência de bloco em protocolos tradicionais vs. distribuídos.

Felipe Guimarães
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.