Ceph em Multi-Datacenter: Latência, Split-Brain e os Limites da Física

Estender um cluster Ceph entre datacenters parece mágica, mas a latência não perdoa. Entenda os trade-offs reais entre Stretch Clusters e RBD Mirroring para evitar desastres de I/O.
O sintoma geralmente chega como um ticket vago: "O banco de dados está lento" ou "Tivemos um timeout na aplicação durante o backup". Ao investigar os logs do kernel e as métricas do Ceph, você não vê discos falhando. Você vê latência. Muita latência.
O arquiteto prometeu "Alta Disponibilidade Geográfica" e "RPO Zero" (Recovery Point Objective) estendendo o cluster Ceph entre dois datacenters separados por 50km. No papel, parece redundância perfeita. Na prática forense, é uma cena de crime onde a vítima foi a performance e o culpado é a velocidade da luz.
Vamos dissecar o que acontece quando tentamos esticar um sistema de armazenamento fortemente consistente através de links de fibra óptica e por que a física não negocia com seus SLAs.
O que é um Ceph Stretch Cluster?
Um Ceph Stretch Cluster é uma configuração onde os nós de armazenamento (OSDs) e monitores (MONs) são distribuídos entre diferentes localizações geográficas (datacenters), configurados para manter réplicas síncronas dos dados em ambos os sites. O objetivo é garantir que, se um datacenter inteiro ficar offline, o cluster continue operando sem perda de dados (RPO=0), aceitando como penalidade o aumento obrigatório na latência de gravação devido ao tempo de trânsito da rede (RTT).
A Ilusão da Replicação Síncrona e a Latência de Gravação
A maioria dos problemas de performance em clusters estendidos (Stretch Clusters) nasce de um mal-entendido fundamental sobre como o Ceph grava dados. O Ceph prioriza Consistência e Correção acima de velocidade.
Quando sua aplicação envia um bloco de dados para o Ceph, o cliente calcula onde esse objeto deve viver (via algoritmo CRUSH) e envia para o OSD Primário. Aqui está o problema: o OSD Primário não devolve o "OK" (ack) para o cliente imediatamente. Ele primeiro repassa esse dado para os OSDs Secundários e Terciários.
Em um cluster local, isso ocorre em microssegundos via backplane de 10Gb/25Gb/100Gb. Em um cenário Multi-Datacenter, se sua regra CRUSH exige uma réplica no "Site A" e outra no "Site B", o OSD Primário tem que esperar a luz viajar pela fibra até o outro prédio, o disco do outro lado gravar, e a confirmação voltar.
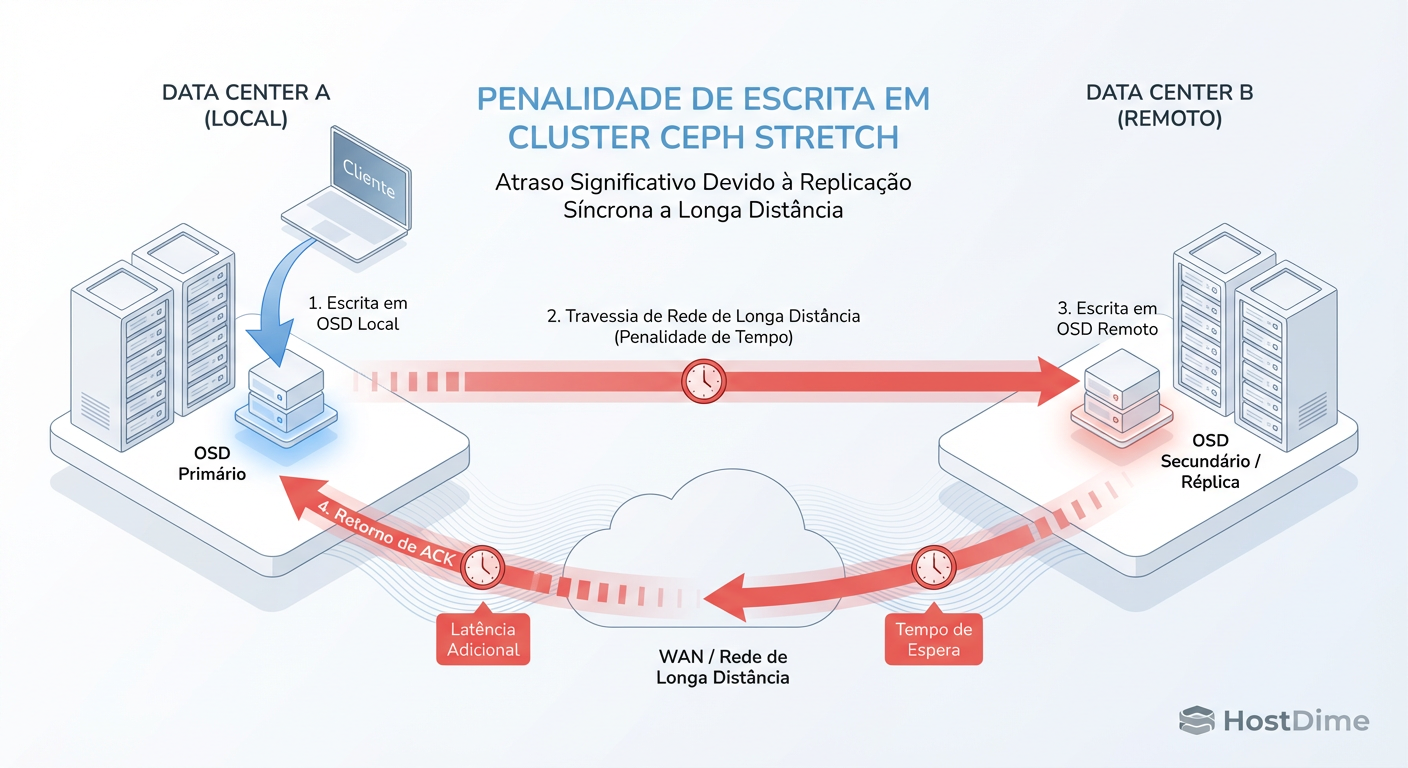 Figura: O Ciclo de Gravação no Ceph Stretch: O cliente só recebe o 'OK' depois que os dados viajam até o segundo datacenter e voltam.
Figura: O Ciclo de Gravação no Ceph Stretch: O cliente só recebe o 'OK' depois que os dados viajam até o segundo datacenter e voltam.
Isso introduz o que chamo de Penalidade de Distância. A luz viaja a aproximadamente 200km/ms na fibra (devido à refração, é mais lenta que no vácuo). Se seus datacenters estão a 100km de distância (ida e volta = 200km), você adicionou no mínimo 1ms de latência pura de física, sem contar o tempo de processamento dos switches, roteadores e conversão de mídia.
Para um banco de dados transacional que faz milhares de pequenas gravações síncronas por segundo, adicionar 2ms a cada operação é catastrófico. O sintoma é um iowait alto na VM do banco de dados, enquanto o throughput da rede permanece baixo. O cano é largo, mas o tempo de viagem é longo.
O Teorema CAP no Ceph e o Dilema da Fibra Cortada
Como investigador, quando vejo um cluster travado, a primeira coisa que pergunto é: "Onde está a partição de rede?". O Teorema CAP (Consistency, Availability, Partition Tolerance) dita que, durante uma falha de rede (P), você deve escolher entre Consistência (C) ou Disponibilidade (A).
O Ceph é, por design, um sistema CP (Consistência + Tolerância a Partição).
Se o link de fibra entre seus dois datacenters for cortado, o Ceph não aceitará que ambos os lados continuem gravando. Se permitisse, teríamos dois históricos diferentes da verdade ("Split-Brain"), o que corromperia o sistema de arquivos.
O comportamento padrão do Ceph ao perder contato com os OSDs pares necessários para cumprir a política de replicação (min_size) é bloquear a I/O. O cluster congela para proteger os dados. Para o usuário final, o sistema caiu. Para o engenheiro de storage, o sistema funcionou exatamente como deveria: protegeu a integridade dos dados contra a corrupção.
Arquitetura de Monitores em Multi-Site e a Matemática do Quórum
Aqui é onde muitos projetos falham na fase de design. Para que o cluster tome decisões (como marcar um OSD como "down" ou eleger um líder), os Monitores (MONs) precisam de Quórum. Quórum exige maioria simples: (n/2) + 1.
Se você tem 2 datacenters e coloca 2 monitores no Site A e 2 monitores no Site B, você tem 4 monitores. Se o link cai:
Site A tem 2 de 4 (50%). Não tem maioria.
Site B tem 2 de 4 (50%). Não tem maioria.
Resultado: O cluster inteiro para. Ambos os lados entram em modo de leitura apenas ou bloqueiam totalmente, pois nenhum lado tem autoridade para liderar.
Para resolver isso, a matemática exige um número ímpar. Mas colocar 3 monitores no Site A e 2 no Site B significa que, se o Site A cair (incêndio, energia), o Site B (com apenas 2 de 5) não assume.
A solução forense correta é o Terceiro Site de Arbitragem (Tie-breaker). Um local neutro, isolado dos outros dois, rodando apenas um monitor "testemunha". Esse monitor não armazena dados de usuário, apenas participa da votação do mapa do cluster.
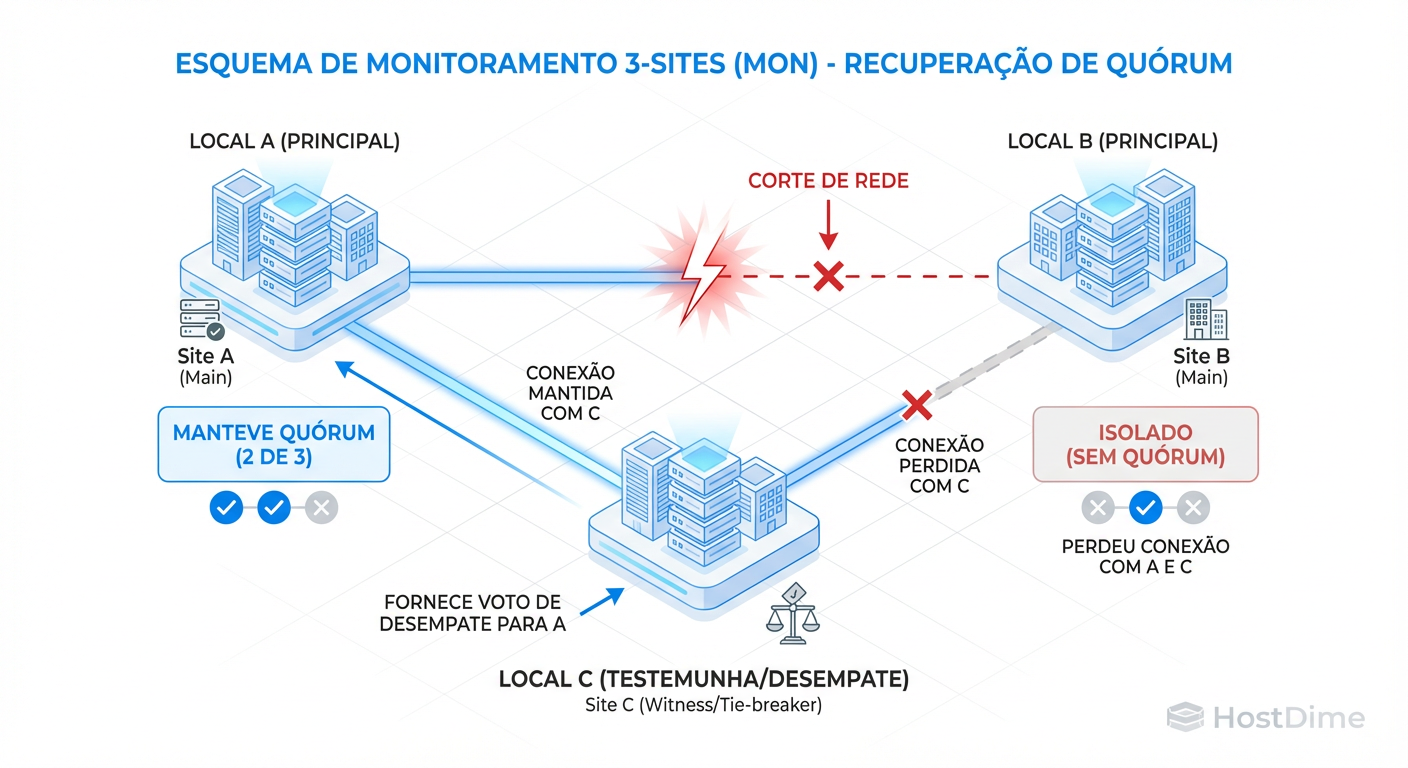 Figura: O Papel do Terceiro Site no Quórum: Como o monitor 'testemunha' impede o Split-Brain durante uma falha de link.
Figura: O Papel do Terceiro Site no Quórum: Como o monitor 'testemunha' impede o Split-Brain durante uma falha de link.
Com essa topologia (2 MONs no Site A, 2 MONs no Site B, 1 MON no Site C), se o Site A cair, o Site B + Site C formam maioria (3 de 5). O cluster sobrevive e continua servindo dados a partir do Site B.
Stretch Cluster vs. RBD Mirroring: Escolhendo a Estratégia de Replicação
Não existe "melhor", existe o trade-off que seu negócio aguenta. Frequentemente vejo administradores forçando um Stretch Cluster (síncrono) quando deveriam estar usando replicação assíncrona.
Use a tabela abaixo para confrontar as expectativas da gerência com a realidade técnica:
| Característica | Ceph Stretch Cluster (Síncrono) | RBD Mirroring (Assíncrono) |
|---|---|---|
| RPO (Perda de Dados) | Zero (Garantido). | > 0 (Depende do lag da rede/delta). |
| RTO (Tempo de Retorno) | Quase imediato (Automático). | Minutos (Requer promoção manual ou scriptada). |
| Latência de Escrita | Alta (Soma do RTT da rede + Discos locais). | Baixa (Velocidade do cluster local apenas). |
| Dependência de Link | Crítica. Alta largura de banda, baixíssima latência. | Tolerante. Lida bem com links instáveis ou lentos. |
| Distância Máxima | ~50-100km (Recomendado < 5ms RTT). | Global (Transatlântico, sem limite). |
| Custo | Exige fibra dedicada/escura (Dark Fiber). | Funciona sobre VPN/WAN padrão. |
Se a sua aplicação não suporta latência de escrita de 2-4ms, não use Stretch Cluster. Use dois clusters independentes e configure o RBD Mirroring (snapshot-based ou journaling). Você perde alguns segundos de dados em um desastre, mas ganha performance total no dia a dia.
Configurando Failure Domains no CRUSH Map para Sobrevivência de Datacenter
Para que o Ceph entenda a topologia física, não basta nomear os hosts. Você precisa editar o mapa CRUSH. O padrão do Ceph é distribuir dados para evitar falha de host. Em multi-site, precisamos evitar falha de datacenter.
Você deve definir uma regra que obrigue o Ceph a colocar cópias em buckets do tipo datacenter diferentes.
Um exemplo prático de verificação. Se você rodar ceph osd tree e vir uma estrutura plana, está errado. A estrutura deve refletir a hierarquia física:
ID CLASS WEIGHT TYPE NAME
-1 60.00000 root default
-9 30.00000 datacenter site-a
-3 10.00000 host server-a1
0 ssd 5.00000 osd.0
1 ssd 5.00000 osd.1
...
-10 30.00000 datacenter site-b
-5 10.00000 host server-b1
6 ssd 5.00000 osd.6
Se o CRUSH map não tiver essa separação explícita e uma regra como step chooseleaf firstn 0 type datacenter, o Ceph pode, por acaso, colocar todas as 3 réplicas no Site A. Se o Site A queimar, seus dados somem, mesmo tendo um Site B ativo.
Callout de Risco: Em modo Stretch, ative o modo min_size 1 com extremo cuidado ou utilize a funcionalidade específica de "stretch mode" do Ceph (introduzida no release Octopus), que gerencia o min_size dinamicamente para permitir escritas degradadas se, e somente se, o site sobrevivente tiver quórum com o monitor árbitro.
Métricas de Rede Críticas para Validação de Storage Distribuído
Antes de aprovar a arquitetura, você precisa de evidências. O ping é insuficiente porque ele usa pacotes ICMP minúsculos que não sofrem com MTU ou buffer bloat da mesma forma que um payload de armazenamento de 4MB.
O que você deve medir para provar se a rede aguenta:
RTT sob Carga (Jitter): A latência média é irrelevante se o desvio padrão for alto. Storage odeia jitter.
Bandwidth Delay Product (BDP): A quantidade de dados que "cabem" no fio. Em longas distâncias, o TCP Window Scaling é vital.
Perda de Pacotes: O Ceph é agressivo. 0.1% de perda de pacotes pode derrubar a performance de TCP drasticamente devido a retransmissões.
Use o iperf3 para simular o tráfego real antes de instalar o Ceph:
iperf3 -s
# No Site A (Cliente) - Teste de TCP com janela grande
iperf3 -c <IP_SITE_B> -t 30 -P 4 -w 4M
Se a banda atingida for muito menor que a capacidade do link, ou se houver muitas retransmissões (Retr na saída do iperf), o link não está pronto para replicação síncrona. Resolver isso na camada de rede é pré-requisito. Tentar ajustar timeouts do Ceph (osd_op_thread_timeout) para compensar uma rede ruim é a receita para instabilidade crônica.
Veredito Técnico Forense
Operar Ceph em múltiplos datacenters não é apenas uma configuração de software; é um exercício de arquitetura de restrições. A latência não é um bug, é física. O Split-Brain não é um erro, é proteção matemática.
Se você precisa de performance local absoluta, use replicação assíncrona. Se precisa de RPO zero absoluto, pague o preço da latência e garanta o terceiro site para o quórum. Tentar enganar esses princípios resultará, invariavelmente, em um cluster que não grava rápido o suficiente ou que para completamente quando você mais precisa dele.
Referências & Leitura Complementar
Ceph Documentation - Stretch Clusters: Detalhes oficiais sobre o modo stretch introduzido no Ceph Octopus.
RFC 5905 (NTP): Essencial, pois relógios dessincronizados entre datacenters matam MONs instantaneamente.
The Raft Consensus Algorithm: Para entender profundamente como a eleição de líderes e quórum funcionam (alternativa ao Paxos usada em sistemas modernos).
Ceph CRUSH Map Syntax: Documentação técnica sobre a linguagem de configuração do mapa CRUSH.

Vinícius Rocha
Enterprise Storage Consultant
Consultor para Fortune 500. Traduz 'economês' para 'técniquês' e ajuda empresas a não gastarem milhões em SANs desnecessárias.