Ceph Failure Domains: Por que Rack-Aware não é suficiente (e o custo da paranóia)
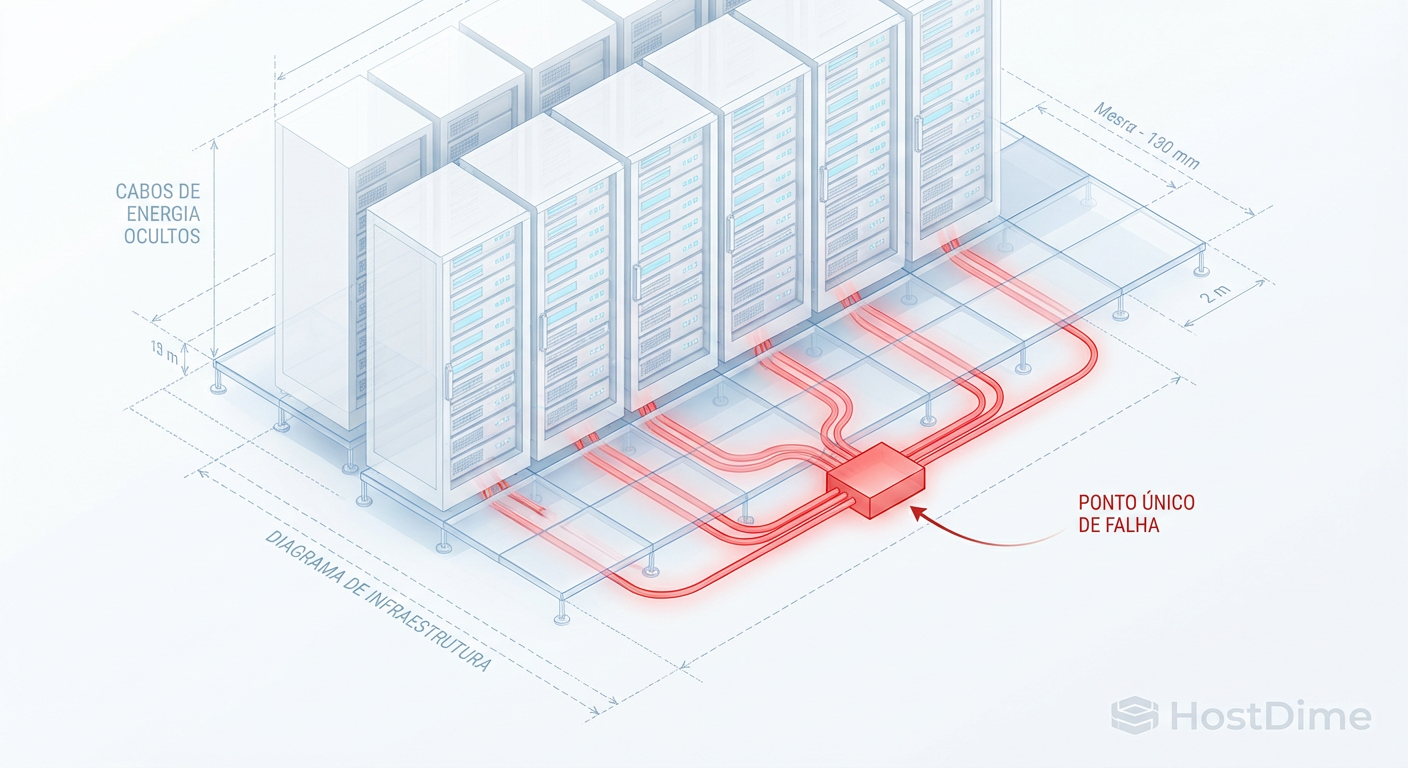
A redundância de rack no Ceph falha quando dependências invisíveis (PDU, Switch, Ar-condicionado) são compartilhadas. Aprenda a mapear riscos reais no CRUSH map.
O silêncio em um datacenter é o som mais alto que existe.
Na minha experiência investigando "mortes súbitas" de clusters de armazenamento, a cena do crime raramente aponta para o software em si. O Ceph é resiliente; ele é projetado para assumir que o hardware vai falhar. O problema surge quando a realidade física trai a configuração lógica.
Você configurou o failure_domain = rack. Você dorme tranquilo, acreditando que se o Rack A pegar fogo, o Rack B e C segurarão a carga. Mas quando o incidente acontece, o cluster trava em read-only ou, pior, corrompe dados por falta de quórum. A autópsia revela o culpado: Shared Fate (Destino Compartilhado). Seus racks eram distintos no CRUSH map, mas compartilhavam o mesmo disjuntor, a mesma régua de PDU ou o mesmo switch de agregação (Spine).
Este artigo é uma investigação forense sobre como alinhar a topologia lógica do Ceph com a implacável realidade da infraestrutura física.
O Domínio de Falha no Ceph é a unidade atômica de isolamento de risco definida no algoritmo CRUSH. Ele determina a fronteira física máxima que um incidente único pode derrubar sem afetar a disponibilidade dos dados, garantindo que as réplicas de um objeto nunca residam em dispositivos que compartilham o mesmo ponto único de falha (SPOF), como energia, refrigeração ou rede.
A Ilusão da Segurança Física e o "Rack-Aware" no Ceph
A configuração padrão de muitos administradores é definir o domínio de falha no nível do host ou do rack. É o "best practice" de manual. O problema é que manuais ignoram a arquitetura elétrica do seu prédio.
O conceito de Shared Fate dita que se dois componentes dependem de um terceiro recurso upstream, eles são, para fins de disponibilidade, a mesma entidade.
Imagine o seguinte cenário que presenciei em uma auditoria pós-incidente:
O administrador configurou 3 Racks no Ceph.
Regra CRUSH: 3 réplicas, uma por rack.
A Realidade: O Rack 1 e o Rack 2 eram alimentados pela mesma UPS A. O Rack 3 estava na UPS B.
O Evento: Falha na UPS A.
O Resultado: 66% das OSDs caíram instantaneamente. O cluster perdeu o quórum (min_size não atendido).
IO Blocked.
O CRUSH map é um mapa lógico. Ele não tem sensores. Se você diz a ele que o Rack A e o Rack B são independentes, ele acredita. Ele colocará a Réplica 1 no Rack A e a Réplica 2 no Rack B. Quando a energia cai, você perde duas cópias do mesmo dado simultaneamente.
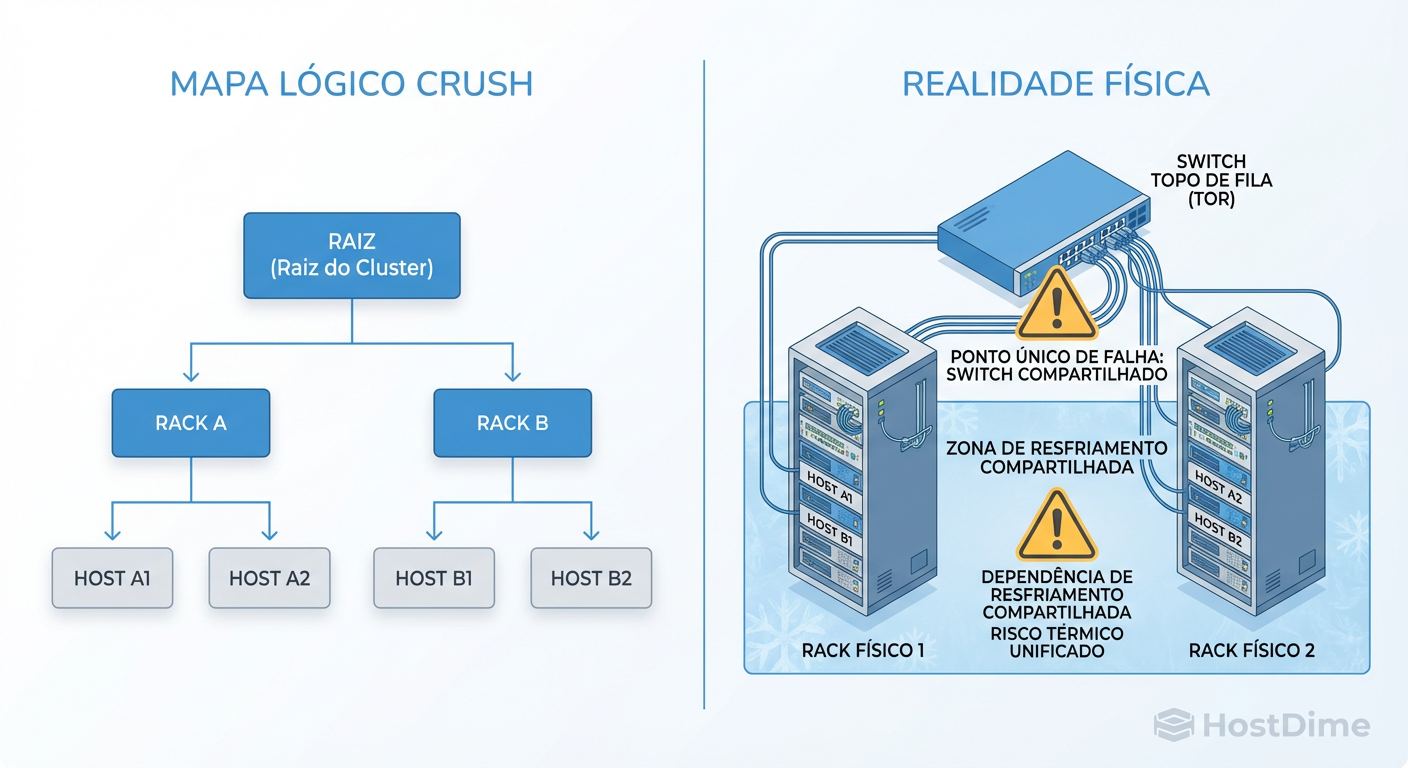 Figura: Mapa Lógico vs. Realidade Física: O CRUSH map só protege contra o que ele conhece. Dependências ocultas (switch de agregação, disjuntores) criam domínios de falha compartilhados.
Figura: Mapa Lógico vs. Realidade Física: O CRUSH map só protege contra o que ele conhece. Dependências ocultas (switch de agregação, disjuntores) criam domínios de falha compartilhados.
A imagem acima ilustra exatamente essa desconexão. O mapa lógico oferece uma falsa sensação de segurança, enquanto a dependência oculta (o switch de agregação ou a PDU) cria um domínio de falha único e massivo.
Anatomia do CRUSH Map: Entendendo Buckets além do padrão
Para evitar esse cenário, precisamos dissecar como o Ceph entende a localização. O algoritmo CRUSH (Controlled Replication Under Scalable Hashing) não grava dados em discos; ele grava em Buckets.
Um bucket é simplesmente um contêiner lógico. A hierarquia padrão geralmente é:
OSD → Host → Chassis → Rack → Row → PDU → Pod → Room → Datacenter → Region → Root.
O erro comum é parar no Rack. Para um investigador forense, o mapa padrão é insuficiente. Você precisa mapear a infraestrutura de suporte.
O Mapa não é o Território
Seus buckets devem refletir os pontos de estrangulamento, não apenas a posição do metal no chão. Se três racks compartilham um switch Spine, o seu domínio de falha real é o Spine, não o Rack.
Se você não modelar isso, o Ceph continuará distribuindo réplicas entre racks que morrerão juntos.
Os Domínios Invisíveis: Energia, Rede e Refrigeração
Ao desenhar sua topologia, você deve auditar três camadas invisíveis. Se você não consegue responder "sim" para a independência dessas camadas entre seus domínios, você tem um problema de Shared Fate.
1. O Domínio de Energia (A Causa Raiz #1)
A energia é binária. Ou tem, ou não tem.
PDU/Circuito: Racks vizinhos frequentemente compartilham circuitos.
UPS: Em datacenters menores, uma única UPS pode segurar metade da sala.
Gerador: Se todo o seu cluster depende de um único gerador sem redundância N+1 real, seu domínio de falha é "o prédio".
2. O Domínio de Rede (Spine/Leaf)
Topologias Spine-Leaf são ótimas para largura de banda, mas perigosas se mal mapeadas.
- Se o Rack A e B estão em switches ToR (Leaf) diferentes, mas ambos sobem para o mesmo par de Spines, e esse par de Spines falha (bug de firmware, erro de config), ambos os racks somem.
3. O Domínio Térmico (Refrigeração)
Raramente considerado, mas letal. Em corredores confinados, a falha de uma unidade CRAC (Computer Room Air Conditioning) pode elevar a temperatura de uma fileira (Row) inteira a níveis de desligamento térmico em minutos.
Configurando Custom Buckets no Ceph: Do conceito à CLI
Não aceite a hierarquia padrão. Se a sua restrição principal é a energia, crie um bucket chamado power-circuit. Se é o switch, crie switch-group.
Vamos operar. Suponha que temos 4 racks, mas eles estão divididos em 2 circuitos de energia (A e B). Queremos garantir que nenhuma réplica seja duplicada dentro do mesmo circuito.
Passo 1: Criar o novo tipo de bucket
Primeiro, precisamos dizer ao CRUSH que existe algo chamado "circuit". O comando padrão não traz isso. Na verdade, podemos usar tipos existentes ou criar novos se o mapa permitir, mas frequentemente reutilizamos row ou room se a semântica encaixar. Vamos ser puristas e adicionar um tipo se necessário, ou usar a hierarquia lógica.
Vamos assumir que vamos agrupar racks em "Rows" que representam nossos circuitos elétricos.
Passo 2: Mover os Racks para os Circuitos (Rows)
A estrutura atual é Root -> Rack -> Host.
A nova estrutura será Root -> Row (Circuito) -> Rack -> Host.
ceph osd crush add-bucket circuito-A row
ceph osd crush add-bucket circuito-B row
# 2. Mova os buckets para a raiz (default)
ceph osd crush move circuito-A root=default
ceph osd crush move circuito-B root=default
# 3. Mova os Racks existentes para dentro dos circuitos corretos
# Supondo que rack1 e rack2 estão na energia A
ceph osd crush move rack1 row=circuito-A
ceph osd crush move rack2 row=circuito-A
# Supondo que rack3 e rack4 estão na energia B
ceph osd crush move rack3 row=circuito-B
ceph osd crush move rack4 row=circuito-B
Passo 3: Criar a Regra CRUSH
Agora, o passo crítico. Você precisa de uma regra que escolha o row (circuito) como o primeiro passo da separação, não o rack.
# Criar uma regra para pool replicado que isola no nível de ROW (nosso circuito)
ceph osd crush rule create-replicated regra-energia default row host
Tradução do comando: "Crie uma regra chamada regra-energia, começando na raiz default, escolha buckets do tipo row para isolar falhas, e dentro deles, escolha host para alocar as OSDs (leafs)."
Agora, se o circuito-A cair (levando rack1 e rack2), o Ceph garante que as réplicas 2 e 3 estarão seguras no circuito-B.
O Trade-off de Latência: Quando a distância mata a performance
Aqui entra o "Custo da Paranóia". Quanto mais seguro você quer estar, mais longe você afasta seus domínios de falha. E a distância é inimiga da latência de gravação.
O Ceph é fortemente consistente. Uma gravação (write) só é confirmada ao cliente (ack) quando todas as réplicas ativas confirmaram a gravação no journal/WAL.
Se você define seu domínio de falha como "Datacenter" (para sobreviver a um incêndio) e seus DCs estão a 5ms de distância (ida e volta - RTT):
Cliente envia Write.
Primary OSD grava.
Primary envia para Secondary OSD (outro DC, +5ms).
Secondary grava e confirma (+5ms).
Primary confirma ao cliente.
Sua latência de disco NVMe de 0.05ms agora é irrelevante. Sua latência de gravação é determinada pela velocidade da luz na fibra ótica.
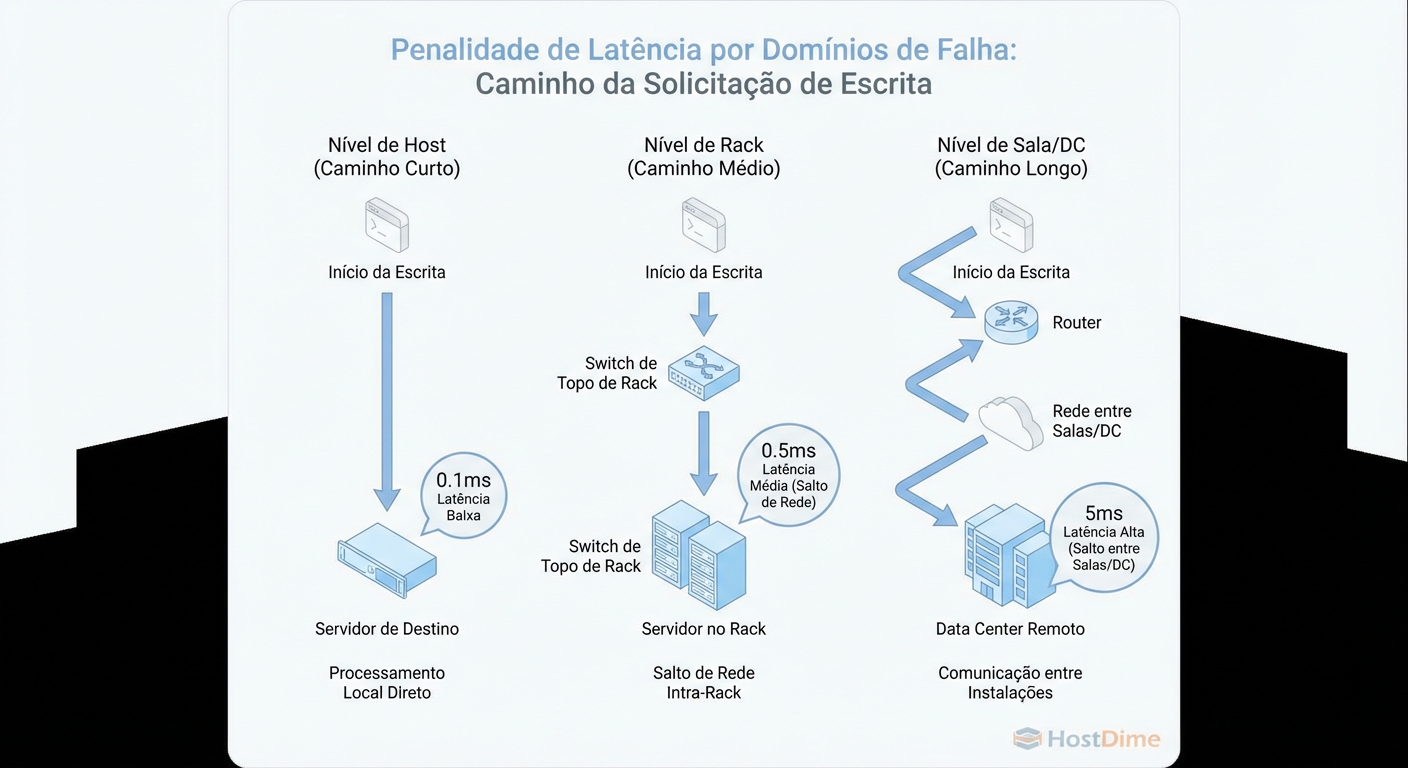 Figura: O Custo da Distância: Quanto maior o domínio de falha, maior a latência de gravação. A física é implacável.
Figura: O Custo da Distância: Quanto maior o domínio de falha, maior a latência de gravação. A física é implacável.
Tabela de Impacto: Segurança vs. Latência
| Nível do Domínio de Falha | Risco Mitigado | Custo de Latência (Network RTT) | Custo de Infraestrutura |
|---|---|---|---|
| OSD / Host | Falha de Disco/Servidor | Baixo (< 0.1ms intra-rack) | Baixo (Switch ToR) |
| Rack | Falha de ToR Switch / Cabo | Médio (< 0.2ms inter-rack) | Médio (Spine/Core) |
| Row / PDU | Disjuntor / PDU de fileira | Médio (< 0.3ms) | Alto (Redundância elétrica) |
| Room / Datacenter | Incêndio / Falha Geral de Energia | Crítico (1ms - 10ms+) | Muito Alto (Dark Fiber/DWDM) |
O Veredito Forense: Não escale seu domínio de falha para "Datacenter" a menos que sua aplicação suporte a latência ou você esteja usando replicação assíncrona (RBD Mirroring), que é outra conversa. Para clusters síncronos, o limite saudável geralmente é "Sala" ou "Zona de Fogo" dentro do mesmo campus.
Validação Forense: Como simular e medir o impacto
Não espere o desastre para testar sua teoria. Você deve validar se o CRUSH map está realmente distribuindo os dados como você planejou.
1. Verificação Estática (Dry-Run)
Use o peering simulado para ver onde o Ceph colocaria os dados.
# Teste onde o CRUSH colocaria um grupo de placement (PG) usando a regra criada
ceph osd crush rule create-replicated teste_regra default row
ceph osd test-crush-rule --rule=teste_regra --num-rep=3 --show-mappings
A saída deve mostrar conjuntos de OSDs como [12, 45, 89]. Verifique manualmente: A OSD 12 está no Circuito A? A 45 está no Circuito B? Se todas as 3 estiverem no Circuito A, sua regra falhou.
2. O Teste de "Scream" (Cuidado: Produção)
Se você tem um ambiente de staging, a única validação real é física.
Inicie uma carga de trabalho de escrita (ex:
fio).Desligue fisicamente o switch de agregação de um domínio (ou o disjuntor de um rack).
Observe o
ceph -w.
O que deve acontecer:
O cluster entra em estado
degraded(pois perdeu réplicas).O I/O NÃO deve pausar (blocked).
Se o I/O pausar, significa que alguns PGs tinham todas as suas réplicas ou a maioria delas (quorum) dentro do domínio que falhou.
Checklist de Investigação de Falhas
Os domínios definidos no CRUSH correspondem à fiação elétrica real?
Existe algum switch central que conecta todos os domínios definidos?
A latência de rede entre os domínios mais distantes suporta o SLA de escrita?
A paranóia custa dinheiro e latência, mas a ignorância custa seus dados. Escolha seu veneno com sabedoria.
Referências & Leitura Complementar
Ceph Documentation: CRUSH Maps - The definitive guide on editing the map.
Weil, S. A., et al. (2006): "CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data" - O paper original que explica a matemática dos buckets.
RFC 7938: Use of BGP for Routing in Large-Scale Data Centers - Entendendo topologias Spine-Leaf e domínios de falha de rede.
Gregg, Brendan: Systems Performance: Enterprise and the Cloud - Para metodologias de medição de latência.

Eduardo Nogueira
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ele diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.