Ceph MON e Quorum: O Assassino Silencioso de Clusters (Arquitetura e Debug)

Seus OSDs estão de pé, mas o IO parou? Entenda como falhas de quorum, latência no RocksDB e clock skews nos Monitores Ceph derrubam sua infraestrutura.
Você pode ter petabytes de armazenamento NVMe, uma rede de 100GbE e CPUs de última geração. Se os seus Monitores Ceph (MONs) não conseguirem chegar a um acordo sobre "que horas são" ou "quem está vivo", seu cluster de milhões de dólares se tornará um peso de papel extremamente caro e barulhento.
Muitos arquitetos tratam os MONs como cidadãos de segunda classe, jogando-os em hardware antigo ou virtualizando-os sem garantias de IOPS, sob a premissa de que "eles não armazenam dados de usuário". Isso é um erro fatal. O MON não guarda seus arquivos, mas guarda a verdade sobre o cluster.
Neste artigo, vamos dissecar a arquitetura de consenso do Ceph, por que a latência de disco nos MONs é o gargalo mais perigoso e como realizar uma cirurgia de coração aberto quando o quorum é perdido.
O que é o Quorum do Ceph MON?
O Quorum do Ceph Monitor (MON) é o estado de consenso distribuído necessário para que o cluster opere, baseado no algoritmo Paxos. Para que o cluster aceite leituras ou gravações, uma maioria estrita (N/2 + 1) dos monitores deve concordar com a versão atual do Mapa do Cluster (Cluster Map). Se o quorum for perdido, todo o IO é bloqueado instantaneamente para prevenir corrupção de dados (split-brain).
A Ilusão do Processo Ativo e a Arquitetura Paxos
O erro mais comum de um sysadmin júnior é olhar para o systemctl status ceph-mon@a e assumir que, porque o processo está verde (ativo), o serviço está funcional. Em sistemas distribuídos, estar rodando não significa estar participando.
O Ceph utiliza uma variante do algoritmo Paxos para garantir consistência forte. Diferente dos OSDs, que priorizam performance e throughput, os MONs priorizam consistência absoluta. Eles gerenciam os "Mapas" (OSD Map, MON Map, PG Map, CRUSH Map).
Mapas, Epochs e a Tirania da Maioria
O conceito central aqui não é apenas "votação", mas sim Epochs (épocas). Cada alteração no estado do cluster (um OSD caindo, um pool sendo criado) incrementa o número da Epoch.
Líder e Peons: Um MON é eleito líder. Os outros são seguidores (peons).
Proposta: O líder propõe uma atualização do mapa (ex: "Epoch 105: OSD.4 está down").
Aceitação: A maioria dos MONs deve gravar essa proposta em disco e confirmar ao líder.
Commit: Só então a alteração se torna "verdade" e é propagada para os clientes e OSDs.
Se você tem 3 MONs e 1 falha, você tem 2 (maioria). O cluster continua. Se você tem 3 MONs e 2 falham (ou ficam isolados por rede), sobra 1. Um não é maioria de 3. O cluster entra em pausa total. O IO congela.
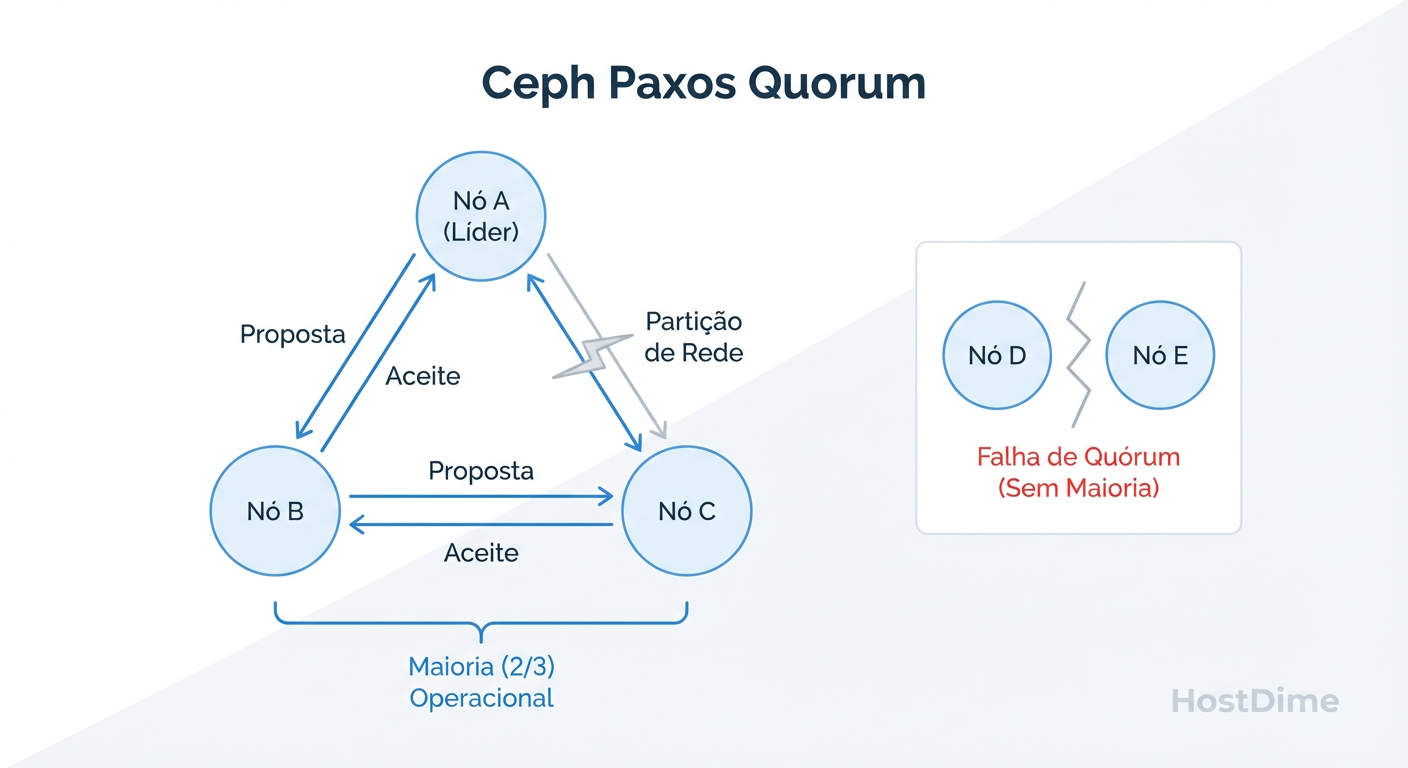 Figura: Diagrama de Consenso Paxos: Como a partição de rede afeta a maioria simples e por que números ímpares são matematicamente obrigatórios.
Figura: Diagrama de Consenso Paxos: Como a partição de rede afeta a maioria simples e por que números ímpares são matematicamente obrigatórios.
Este mecanismo protege seus dados. Se aquele MON isolado permitisse gravações, ele criaria uma linha do tempo divergente da realidade. O Ceph prefere a indisponibilidade à corrupção de dados.
O Gargalo Oculto: Latência de fsync e RocksDB
Aqui reside o "assassino silencioso". O banco de dados interno do MON (baseado em RocksDB/LevelDB) armazena o histórico dos mapas. O algoritmo Paxos exige que, antes de confirmar um voto, o dado esteja fisicamente persistido no disco.
Isso significa uma chamada de sistema fsync().
Se você colocar seus MONs em HDDs rotacionais, ou em SSDs baratos sem proteção contra perda de energia (que mentem sobre o sync ou são lentos no flush), você introduz uma latência mortal.
Por que HDDs nos MONs são Suicídio Arquitetural
Imagine que o Cluster está sob carga pesada. Os OSDs estão reportando estados, PGs estão mudando. O Líder MON propõe uma atualização.
O Líder espera os Peons gravarem no disco.
Um dos Peons está em um HDD compartilhado que está sofrendo com seek time.
O
fsync()leva 200ms em vez de 1ms.O Líder segura a transação.
Os OSDs não recebem o mapa atualizado.
Os clientes (block/object) ficam bloqueados esperando a confirmação do cluster.
O gráfico abaixo ilustra como picos de latência no disco do MON correlacionam-se diretamente com o bloqueio de IO do cliente, mesmo que os OSDs (onde os dados vivem) estejam ociosos.
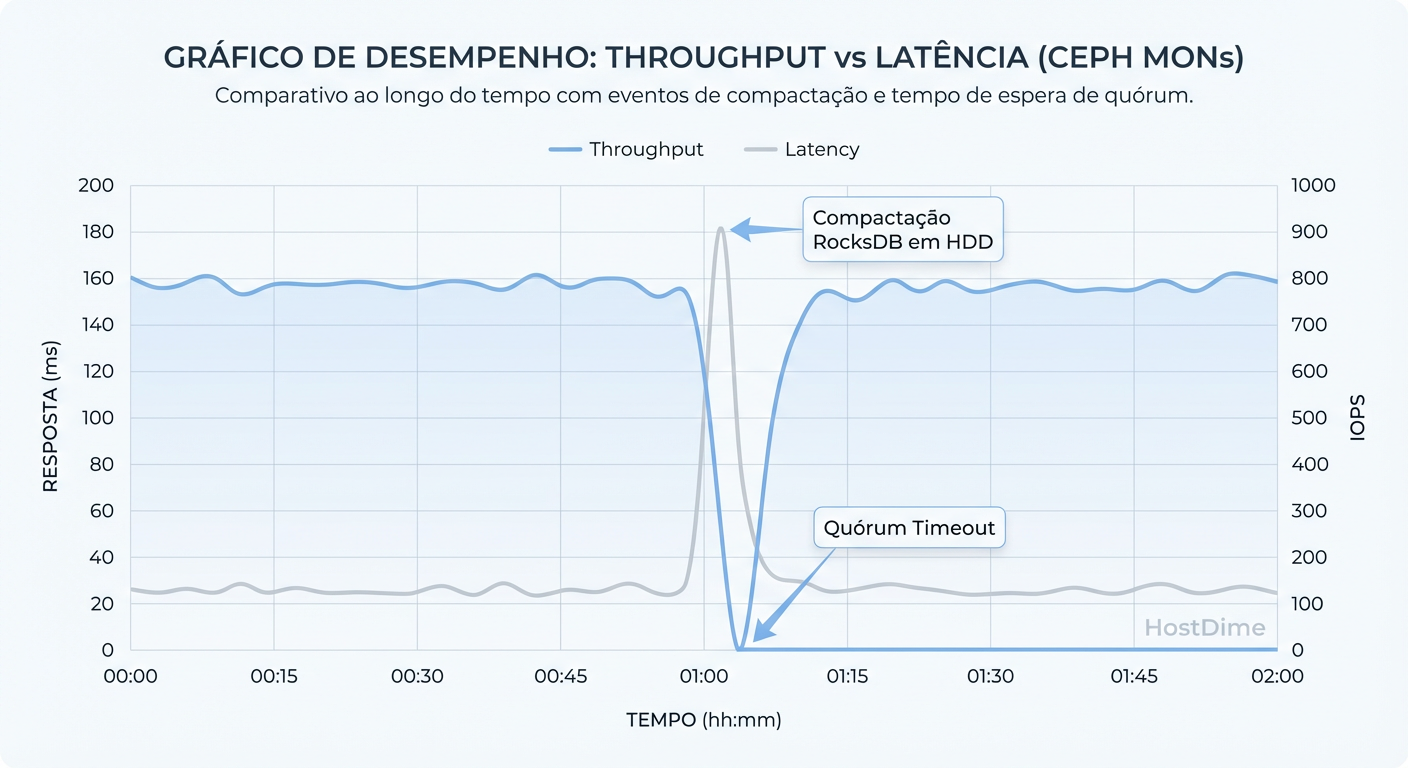 Figura: O Efeito da Latência no Quorum: Gráfico demonstrando como picos de latência de disco no MON bloqueiam o IO do cluster inteiro, mesmo sem falha de hardware.
Figura: O Efeito da Latência no Quorum: Gráfico demonstrando como picos de latência de disco no MON bloqueiam o IO do cluster inteiro, mesmo sem falha de hardware.
Comparativo de Storage para Ceph MONs
A tabela abaixo resume os trade-offs de hardware para a base de dados do MON. O custo de economizar aqui é desproporcional ao risco.
| Tipo de Mídia | Latência fsync (aprox.) | Risco de Perda de Quorum | Adequação Enterprise | Comentário do Arquiteto |
|---|---|---|---|---|
| NVMe Enterprise | < 0.1 ms | Mínimo | Ideal | Obrigatório para clusters com >100 OSDs ou All-Flash. |
| SSD SATA Ent. (PLP) | 0.5 - 2 ms | Baixo | Aceitável | O padrão da indústria. O capacitor (PLP) garante flush rápido. |
| SSD Consumer (QLC/TLC) | 5 - 50 ms (picos) | Alto | Inaceitável | Sem PLP, o SSD bloqueia o write buffer. Causa timeouts aleatórios. |
| HDD (7.2k/10k/15k) | 10 - 1000+ ms | Crítico | Proibido | O tempo de busca (seek) mata o Paxos. Nunca use em produção. |
Clock Skew: Quando o Tempo Destrói o Consenso
O Paxos e os leases (concessões) de liderança dependem de relógios sincronizados. O Ceph tolera uma pequena deriva (default 0.05s), mas em redes congestionadas ou virtualizadas, isso é facilmente ultrapassado.
Se o relógio do MON a estiver 100ms à frente do MON b:
aacha que o lease do líder expirou.aconvoca uma nova eleição.brejeita, pois para ele o líder ainda é válido.O cluster entra em um loop de eleições (flapping), derrubando a performance.
Solução: Use chrony em vez de ntpd (converge mais rápido) e garanta que seus MONs estejam no mesmo switch ou com latência de rede determinística entre eles.
Sintomas e Diagnóstico Avançado
Quando o cluster para, o comando ceph -s geralmente trava ou retorna timeout. Isso é o sintoma clássico de perda de quorum. Não confie apenas na CLI principal. Você precisa ir direto ao daemon.
1. Verificando o estado do socket local
Acesse o servidor onde o MON roda e interpele o daemon diretamente via admin socket. Isso ignora a rede do cluster.
ceph daemon mon.$(hostname) mon_status
O que procurar na saída JSON:
state: Deve ser "leader" ou "peon". Se for "probing", "electing" ou "synchronizing" por muito tempo, há problemas.quorum: A lista de inteiros dos MONs participantes. Se a lista for menor que a maioria, você está sem quorum.
2. Analisando a Latência de Commit
Se o cluster está lento, mas com quorum, verifique os logs do Ceph (/var/log/ceph/ceph-mon.*.log) procurando por avisos de "slow ops" ou latência de disco.
# Procurar por eventos de compactação lenta do RocksDB
grep -i "compact" /var/log/ceph/ceph-mon*.log | grep "ms"
Se você vir compactações levando segundos, seu disco não está aguentando a carga de metadados.
Cirurgia de Emergência: Recuperando o Quorum Manualmente
Imagine o cenário de desastre: Você tem 3 MONs (A, B, C). O Data Center sofreu um corte de energia. O disco do MON A corrompeu. O MON B não sobe por erro de sistema de arquivos. Só o MON C está vivo. O Ceph não funcionará com 1 de 3. Você precisa dizer ao MON C: "Esqueça os outros, agora você é o rei".
Isso envolve editar o Monmap manualmente. É uma operação arriscada, mas necessária em DR (Disaster Recovery).
O Procedimento "Monmap Injection"
Aviso: Pare o serviço do monitor antes de executar isso. Faça backup do diretório /var/lib/ceph/mon/....
Extrair o mapa atual do MON sobrevivente:
ceph-mon -i c --extract-monmap /tmp/monmapImprimir o conteúdo (para verificar):
monmaptool --print /tmp/monmapVocê verá os 3 monitores listados (A, B, C).
Remover os monitores mortos do mapa:
monmaptool /tmp/monmap --rm a monmaptool /tmp/monmap --rm bInjetar o mapa alterado de volta no MON C:
ceph-mon -i c --inject-monmap /tmp/monmapIniciar o serviço: Agora, ao iniciar o MON C, ele verá um mapa onde ele é o único membro (1 de 1). Ele formará quorum sozinho e permitirá que o cluster (e os dados) fiquem acessíveis novamente. Depois, você pode adicionar novos MONs limpos para restaurar a redundância.
Veredito Técnico e Call-to-Action
O Ceph é robusto, mas sua robustez depende da integridade do trio (ou quinteto) de Monitores. O "assassino silencioso" não é um bug de software, mas sim a negligência na camada física e arquitetural dos MONs.
Resumo para o Arquiteto:
Nunca virtualize MONs em infraestrutura com oversubscription de IOPS.
Use SSDs Enterprise com PLP ou NVMe. HDDs são proibidos.
Monitore a latência de fsync especificamente nos hosts de monitoramento.
Tenha um plano de recuperação de monmap testado.
Não espere o ceph -s travar para descobrir que seu disco de log tem 500ms de latência. Meça agora.
Referências & Leitura Complementar
Paxos Made Simple - Leslie Lamport (O paper fundamental sobre o algoritmo de consenso).
Ceph Documentation: Monitor Config Reference - Parâmetros críticos de
mon_osd_down_out_intervalemon_lease.RocksDB Tuning Guide - Compreendendo Write Stalls e Compaction em cargas de trabalho de metadados.
RFC 5905 (NTPv4) - Importância da sincronização de tempo em sistemas distribuídos.

André Bastos
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.